Présentation
De nos jours, la haute disponibilité est une exigence pour de nombreux systèmes, quelle que soit la technologie que vous utilisez. Ceci est particulièrement important pour les bases de données, car elles stockent les données sur lesquelles reposent les applications et les systèmes critiques. La stratégie la plus courante pour obtenir une haute disponibilité est la réplication. Il existe différentes manières de répliquer des données sur plusieurs serveurs et de basculer le trafic lorsque, par exemple, un serveur principal cesse de répondre.
Architecture haute disponibilité pour PostgreSQL
Il existe plusieurs architectures pour implémenter la haute disponibilité dans PostgreSQL, mais les architectures de base sont les architectures Primaire-Secours et Primaire-Primaire.
Architectures primaires de secours
Primary-Standby peut être l'architecture HA la plus basique que vous puissiez configurer et, souvent, la plus facile à mettre en œuvre et à entretenir. Il est basé sur une base de données principale avec un ou plusieurs serveurs de secours. Ces bases de données Standby resteront synchronisées (ou presque synchronisées) avec le nœud Primaire, selon que la réplication est synchrone ou asynchrone. Si le serveur principal tombe en panne, le serveur de secours contient presque toutes les données du serveur principal et peut rapidement être transformé en nouveau serveur de base de données principal.
Vous pouvez implémenter deux types de bases de données de secours, en fonction de la nature de la réplication :
- Logical Standbys – La réplication entre le primaire et le standby est effectuée via des instructions SQL.
- Physical Standbys - La réplication entre Primary et Standby s'effectue via les modifications internes de la structure des données.
Dans le cas de PostgreSQL, un flux d'enregistrements de journal à écriture anticipée (WAL) est utilisé pour maintenir la synchronisation des bases de données de secours. Cela peut être synchrone ou asynchrone, et l'intégralité du serveur de base de données est répliquée.
Depuis la version 10, PostgreSQL inclut une option intégrée pour configurer la réplication logique, qui construit un flux de modifications de données logiques à partir des informations du journal d'écriture anticipée. Cette méthode de réplication permet de répliquer les modifications de données des tables individuelles sans qu'il soit nécessaire de désigner un serveur principal. Il permet également aux données de circuler dans plusieurs directions.
Malheureusement, une configuration primaire-de secours n'est pas suffisante pour garantir efficacement une haute disponibilité, car vous devez également gérer les pannes. Pour gérer les pannes, vous devez être capable de les détecter. Une fois que vous savez qu'il y a une panne, par exemple, des erreurs sur le nœud principal ou le nœud qui ne répond pas, vous pouvez sélectionner un nœud de secours pour remplacer le nœud défaillant avec le moins de retard possible. Ce processus doit être le plus efficace possible pour restaurer toutes les fonctionnalités des applications. PostgreSQL lui-même n'inclut pas de mécanisme de basculement automatique, cela nécessitera donc un script personnalisé ou des outils tiers pour cette automatisation.
Après un basculement, votre application doit être notifiée en conséquence pour commencer à utiliser le nouveau principal. Vous devez également évaluer l'état de votre architecture après le basculement, car vous pouvez vous retrouver dans une situation où seul le nouveau nœud principal est en cours d'exécution (par exemple, vous aviez un nœud principal et un seul nœud de secours avant le problème). Dans ce cas, vous devrez ajouter un nœud de secours pour recréer la configuration principale de secours que vous aviez initialement pour la haute disponibilité.
Architectures primaires-primaires
L'architecture primaire-primaire permet de minimiser l'impact d'une erreur sur l'un des nœuds, car les autres nœuds peuvent prendre en charge tout le trafic, n'affectant que légèrement les performances mais sans jamais perdre de fonctionnalité. L'architecture primaire-primaire est souvent utilisée dans le double but de créer un environnement à haute disponibilité et d'évoluer horizontalement (par rapport au concept d'évolutivité verticale où vous ajoutez plus de ressources à un serveur).
PostgreSQL ne supporte pas encore cette architecture "nativement", vous devrez donc vous référer à des outils et implémentations tiers. Lorsque vous choisissez une solution, vous devez garder à l'esprit qu'il existe de nombreux projets/outils, mais que certains d'entre eux ne sont plus pris en charge, tandis que d'autres sont nouveaux et pourraient ne pas être testés en production.
Équilibrage de charge
Les équilibreurs de charge sont des outils qui peuvent être utilisés pour gérer le trafic de votre application afin de tirer le meilleur parti de votre architecture de base de données.
Ces outils sont non seulement utiles pour équilibrer la charge de vos bases de données, mais ils aident également les applications à être redirigées vers les nœuds disponibles/sains et même à spécifier des ports avec des rôles différents.
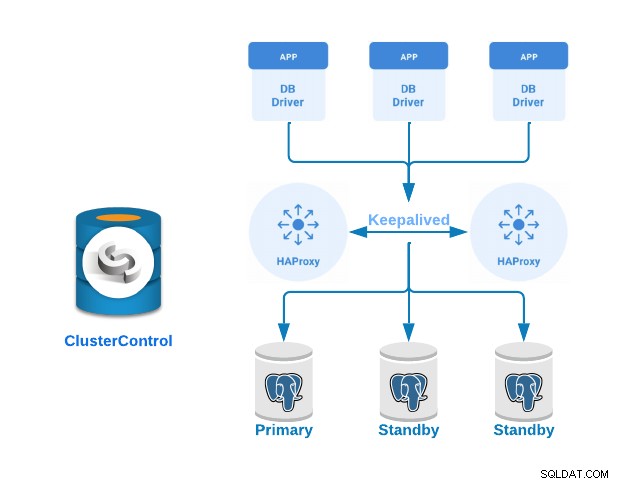
HAProxy est un équilibreur de charge qui répartit le trafic d'une origine vers une ou plusieurs destinations et peut définir des règles et/ou des protocoles spécifiques pour cette tâche. Si l'une des destinations cesse de répondre, elle est marquée comme étant hors ligne et le trafic est envoyé vers le reste des destinations disponibles.
Keepalived est un service qui vous permet de configurer une adresse IP virtuelle au sein d'un groupe de serveurs actifs/passifs. Cette adresse IP virtuelle est attribuée à un serveur actif. Si ce serveur tombe en panne, l'adresse IP est automatiquement migrée vers le serveur passif "Secondaire", lui permettant de continuer à fonctionner avec la même adresse IP de manière transparente pour les systèmes.
Voyons maintenant comment implémenter un cluster PostgreSQL principal de secours avec des serveurs d'équilibrage de charge et keepalived configurés entre eux. Nous allons le démontrer à l'aide de l'interface conviviale de ClusterControl.
Pour cet exemple, nous allons créer :
- 3 serveurs PostgreSQL (un principal et deux de secours).
- 2 équilibreurs de charge HAProxy.
- Keepalived configuré entre les serveurs d'équilibrage de charge.
Déploiement de la base de données
Pour déployer une base de données à l'aide de ClusterControl, sélectionnez simplement l'option "Déployer" et suivez les instructions qui s'affichent.
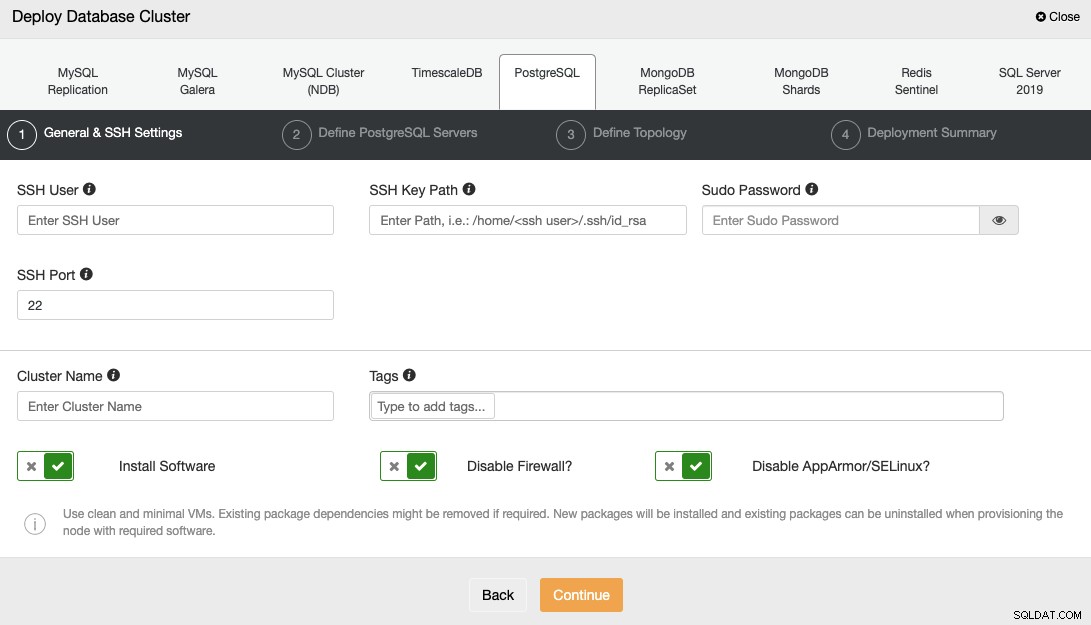
Lorsque vous sélectionnez PostgreSQL, vous devez spécifier l'utilisateur, la clé ou le mot de passe, et Port pour se connecter en SSH à vos serveurs. Vous avez également besoin du nom de votre nouveau cluster et choisissez si vous souhaitez que ClusterControl installe le logiciel et les configurations correspondants pour vous.
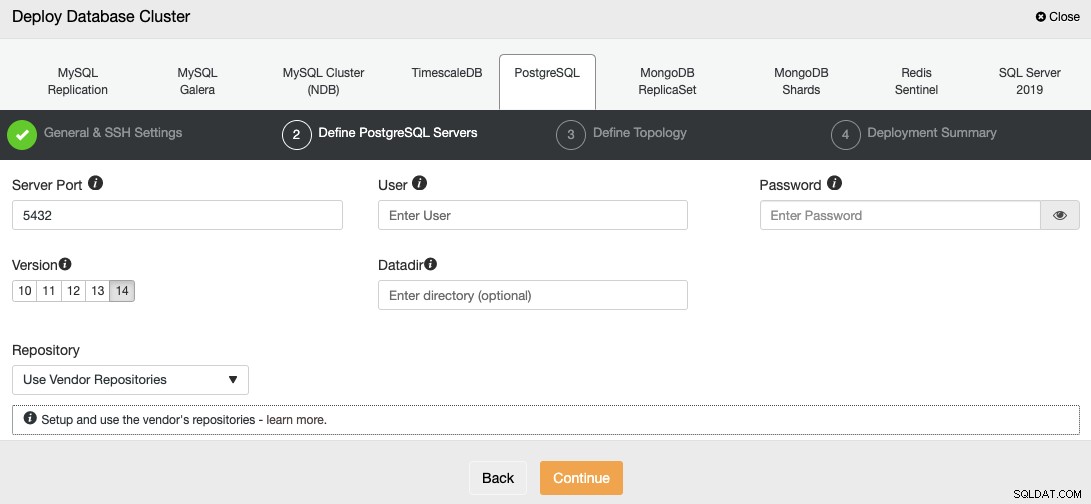
Après avoir configuré les informations d'accès SSH, vous devez définir l'utilisateur de la base de données, version et datadir (facultatif). Vous pouvez également spécifier le référentiel à utiliser ; le référentiel officiel du fournisseur sera utilisé par défaut.
À l'étape suivante, vous devez ajouter vos serveurs au cluster que vous allez créer.
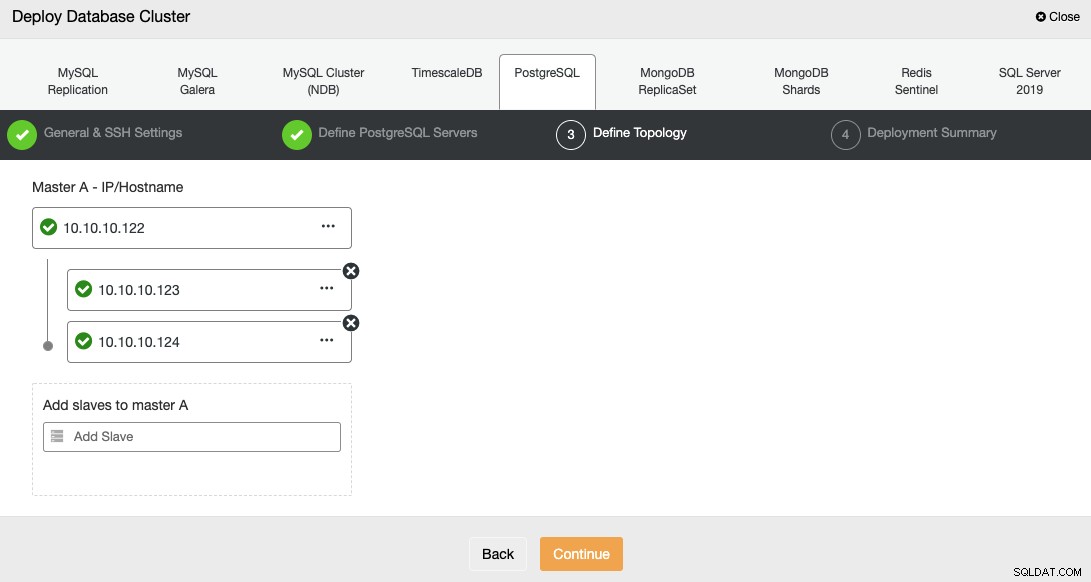
Lors de l'ajout de vos serveurs, vous pouvez entrer l'IP ou le nom d'hôte.
Dans la dernière étape, vous pouvez choisir si votre réplication sera synchrone ou asynchrone.
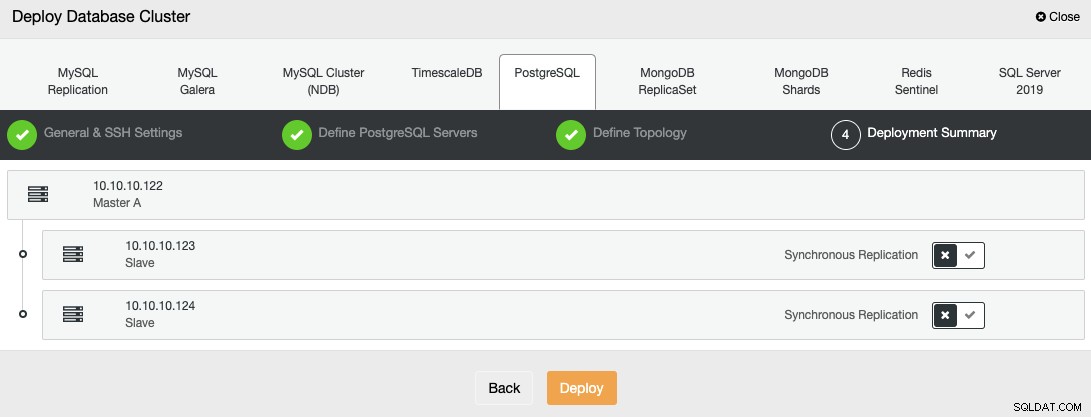
Vous pouvez surveiller l'état de la création de votre nouveau cluster à partir du ClusterControl moniteur d'activité.
Une fois la tâche terminée, vous pouvez voir votre cluster dans le ClusterControl principal écran.
Une fois votre cluster créé, vous pouvez effectuer plusieurs tâches, comme ajouter un équilibreur de charge (HAProxy) ou un nouveau réplica.
Déploiement de l'équilibreur de charge
Pour effectuer un déploiement d'équilibreur de charge, sélectionnez l'option "Ajouter un équilibreur de charge" dans les actions du cluster et remplissez les informations demandées.
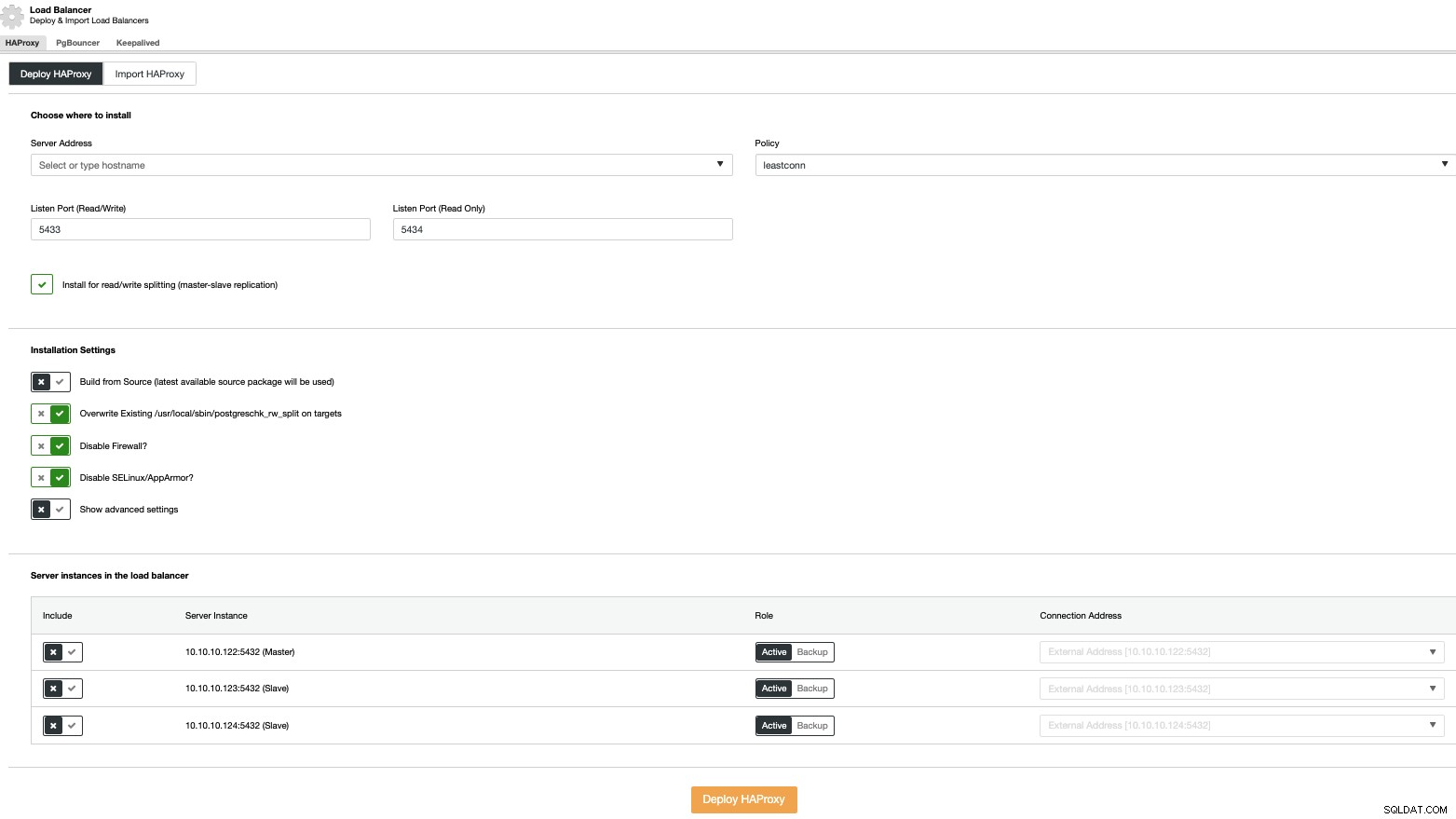
Il vous suffit d'ajouter l'adresse IP ou le nom d'hôte, le port, la stratégie, et les nœuds que vous configurerez dans vos équilibreurs de charge.
Déploiement Keepalive
Pour effectuer un déploiement keepalived, sélectionnez le cluster, accédez au menu "Gérer" et à la section "Load Balancer", puis sélectionnez l'option "Keepalived".
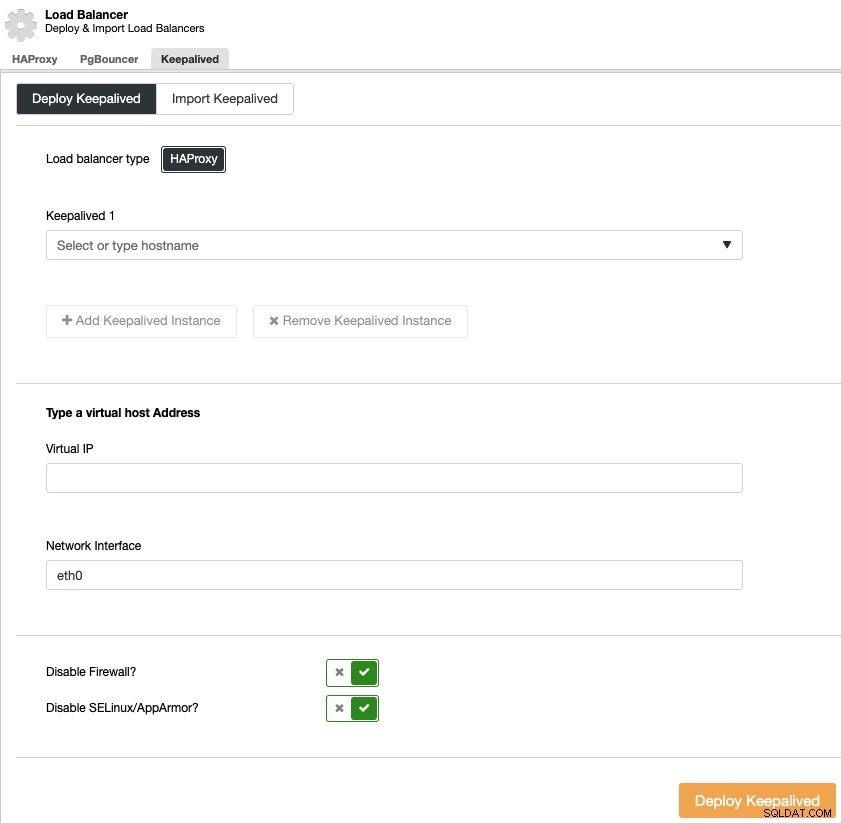
Vous devez sélectionner les serveurs d'équilibrage de charge et l'adresse IP virtuelle pour votre haute environnement de disponibilité.
Keepalived utilise l'adresse IP virtuelle et la migre d'un équilibreur de charge à un autre en cas de panne, afin que vos systèmes puissent continuer à fonctionner normalement.
Si vous avez suivi les étapes précédentes, vous devriez avoir la topologie suivante :
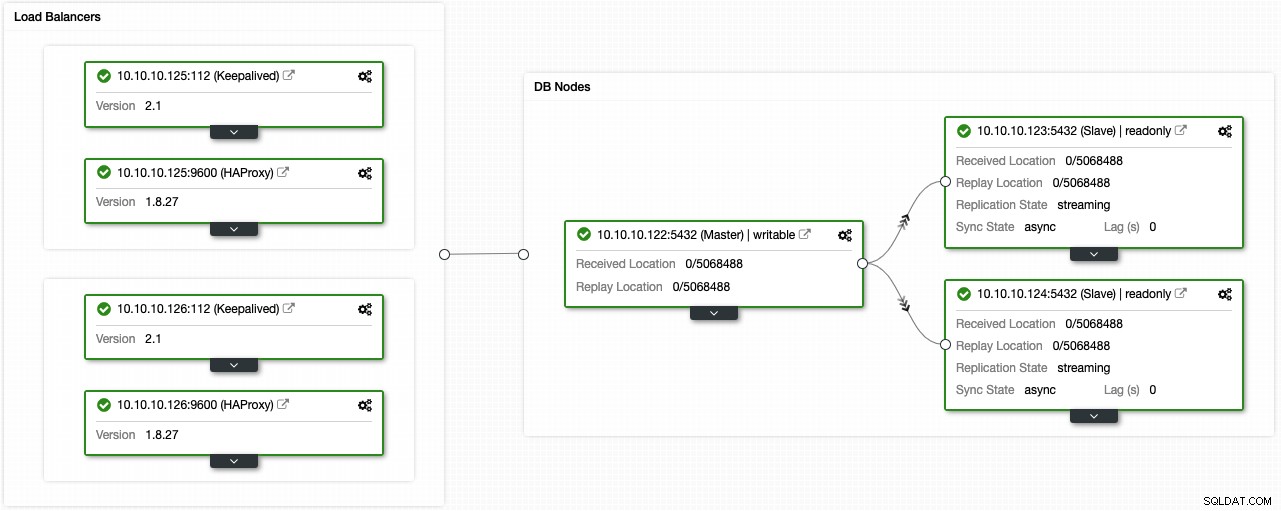
Vous pouvez améliorer cet environnement de haute disponibilité en ajoutant un pooler de connexion comme PgBouncer. Ce n'est pas indispensable, mais cela pourrait être utile pour améliorer les performances et gérer les connexions actives en cas d'échec, et la meilleure chose est que vous pouvez également le déployer en utilisant ClusterControl.
Basculement de contrôle de cluster
Supposons que l'option "Récupération automatique" est activée sur votre serveur ClusterControl. En cas de défaillance du primaire, ClusterControl promouvra le standby le plus avancé (s'il n'est pas sur la liste noire) en primaire, et vous informera du problème. Il basculera également le reste des nœuds de secours pour répliquer à partir du nouveau nœud principal.
HAProxy est configuré par défaut avec deux ports différents ; ports en lecture-écriture et en lecture seule.
Dans votre port de lecture-écriture, vous avez votre serveur principal en ligne et le reste de vos nœuds hors ligne, et dans le port en lecture seule, vous avez à la fois le serveur principal et le serveur de secours en ligne.
Lorsque HAProxy détecte que l'un de vos nœuds, qu'il soit principal ou de secours, n'est pas accessible, il le marque automatiquement comme étant hors ligne. Il ne le prend pas en compte pour lui envoyer du trafic. La détection est effectuée par des scripts de vérification de l'état que ClusterControl configure au moment du déploiement. Ceux-ci vérifient si les instances sont actives, si elles sont en cours de récupération ou sont en lecture seule.
Lorsque ClusterControl promeut un Standby en Primary, votre HAProxy marque l'ancien Primary comme étant hors ligne pour les deux ports et met le nœud promu en ligne dans le port en lecture-écriture.
Si votre HAProxy actif, qui a attribué l'adresse IP virtuelle à laquelle vos systèmes se connectent, échoue, Keepalived migre automatiquement cette adresse IP vers votre HAProxy passif. Cela signifie que vos systèmes peuvent alors continuer à fonctionner normalement.
De cette façon, vos systèmes continuent de fonctionner comme prévu et sans votre intervention manuelle.
Considérations
Si vous parvenez à récupérer votre ancien nœud principal défaillant, il ne sera PAS réintroduit automatiquement dans le cluster par défaut. Vous devez le faire manuellement. L'une des raisons en est que si votre réplica a été retardé au moment de l'échec et que ClusterControl ajoute l'ancien primaire au cluster, cela entraînerait une perte d'informations ou une incohérence des données entre les nœuds. Vous pouvez également analyser le problème en détail. Si ClusterControl venait de réintroduire le nœud défaillant dans le cluster, vous risqueriez de perdre des informations de diagnostic.
En outre, si le basculement échoue, aucune autre tentative n'est effectuée. Une intervention manuelle est nécessaire pour analyser le problème et effectuer les actions correspondantes. Ceci afin d'éviter la situation où ClusterControl, en tant que gestionnaire de haute disponibilité, essaie de promouvoir le prochain Standby et le suivant. Il y a peut-être un problème et vous devrez le vérifier.
Sécurité
Une chose importante que vous ne pouvez pas oublier avant de passer en production avec votre environnement à haute disponibilité est d'assurer sa sécurité.
Plusieurs aspects de sécurité à prendre en compte incluent le chiffrement, la gestion des rôles et la restriction d'accès par adresse IP, que nous avons abordés en détail dans un blog précédent.
Dans votre base de données PostgreSQL, vous avez le fichier pg_hba.conf, qui gère l'authentification du client. Vous pouvez limiter le type de connexion, l'adresse IP source ou le réseau, la base de données à laquelle vous pouvez vous connecter et avec quels utilisateurs. Par conséquent, ce fichier est un élément critique pour la sécurité de PostgreSQL.
Vous pouvez configurer votre base de données PostgreSQL à partir du fichier postgresql.conf, afin qu'elle n'écoute que sur une interface réseau spécifique et un port différent de celui par défaut (5432), évitant ainsi les tentatives de connexion de base provenant de sources indésirables .
Une bonne gestion des utilisateurs, soit en utilisant des mots de passe sécurisés, soit en limitant l'accès et les privilèges, est un autre élément essentiel de vos paramètres de sécurité. Il est recommandé d'attribuer le moins de privilèges possible à tous les utilisateurs et de spécifier, si possible, la source de la connexion.
Vous pouvez également activer le chiffrement des données, en transit ou au repos, en évitant l'accès aux informations à des personnes non autorisées.
Un journal d'audit est utile pour comprendre ce qui se passe ou s'est passé dans votre base de données. PostgreSQL vous permet de configurer plusieurs paramètres pour la journalisation ou même d'utiliser l'extension pgAudit pour cette tâche.
Enfin, il est recommandé de maintenir votre base de données et vos serveurs à jour avec les derniers correctifs pour éviter les risques de sécurité. Pour cela, ClusterControl vous permet de générer des rapports opérationnels pour vérifier si vous avez des mises à jour disponibles et même vous aider à mettre à jour vos serveurs de base de données.
Conclusion
Les déploiements à haute disponibilité peuvent sembler difficiles à réaliser, notamment lorsqu'il s'agit de comprendre les différentes architectures et les composants nécessaires pour les configurer correctement.
Si vous gérez la haute disponibilité manuellement, assurez-vous de consulter Effectuer des changements de topologie de réplication pour PostgreSQL. Beaucoup rechercheront des outils tels que ClusterControl pour aider à gérer le déploiement, les équilibreurs de charge, le basculement, la sécurité, etc., pour un environnement complet à haute disponibilité. Vous pouvez télécharger gratuitement ClusterControl pendant 30 jours pour voir comment il peut alléger le fardeau de la gestion d'une infrastructure de base de données à haute disponibilité.
Quelle que soit la façon dont vous choisissez de gérer vos bases de données PostgreSQL à haute disponibilité, assurez-vous de nous suivre sur Twitter ou LinkedIn, ou abonnez-vous à notre newsletter pour obtenir les dernières mises à jour et les meilleures pratiques pour gérer vos configurations de base de données.