Remarque :Cet article a été initialement publié uniquement dans notre eBook, Techniques de haute performance pour SQL Server, Volume 2. Vous pouvez en savoir plus sur nos eBooks ici.
Résumé :Cet article examine certains comportements surprenants des déclencheurs INSTEAD OF et révèle un sérieux bogue d'estimation de cardinalité dans SQL Server 2014.
Déclencheurs et gestion des versions de ligne
Seuls les déclencheurs DML AFTER utilisent la gestion des versions de lignes (à partir de SQL Server 2005) pour fournir le insert et supprimé pseudo-tables à l'intérieur d'une procédure de déclenchement. Ce point n'est pas clairement établi dans une grande partie de la documentation officielle. Dans la plupart des endroits, la documentation indique simplement que la gestion des versions de ligne est utilisée pour construire le insert et supprimé tables dans les déclencheurs sans qualification (exemples ci-dessous) :
Utilisation des ressources de gestion des versions de ligne
Comprendre les niveaux d'isolement basés sur la gestion des versions de ligne
Contrôle de l'exécution des déclencheurs lors de l'importation en bloc de données
Vraisemblablement, les versions originales de ces entrées ont été écrites avant que les déclencheurs INSTEAD OF ne soient ajoutés au produit, et jamais mises à jour. Soit ça, soit c'est un simple oubli (mais répété).
Quoi qu'il en soit, le fonctionnement de la gestion des versions de ligne avec les déclencheurs AFTER est assez intuitif. Ces déclencheurs se déclenchent après les modifications en question ont été effectuées, il est donc facile de voir comment le maintien des versions des lignes modifiées permet au moteur de base de données de fournir le insert et supprimé pseudo-tables. Le supprimé la pseudo-table est construite à partir des versions des lignes affectées avant que les modifications n'aient eu lieu ; le inséré la pseudo-table est formée à partir des versions des lignes affectées au moment où la procédure de déclenchement a démarré.
Au lieu de déclencheurs
Les déclencheurs INSTEAD OF sont différents car ce type de déclencheur DML remplace complètement l'action déclenchée. Le inséré et supprimé les pseudo-tables représentent maintenant les changements qui auraient été faite, si l'instruction déclenchante avait été réellement exécutée. La gestion des versions de ligne ne peut pas être utilisée pour ces déclencheurs car aucune modification n'a eu lieu, par définition. Donc, si vous n'utilisez pas de versions de ligne, comment fait SQL Server ?
La réponse est que SQL Server modifie le plan d'exécution de l'instruction DML de déclenchement lorsqu'un déclencheur INSTEAD OF existe. Plutôt que de modifier directement les tables affectées, le plan d'exécution écrit des informations sur les modifications dans une table de travail masquée. Cette table de travail contient toutes les données nécessaires pour effectuer les modifications d'origine, le type de modification à effectuer sur chaque ligne (suppression ou insertion), ainsi que toute information nécessaire dans le déclencheur d'une clause OUTPUT.
Plan d'exécution sans déclencheur
Pour voir tout cela en action, nous allons d'abord exécuter un test simple sans qu'un déclencheur INSTEAD OF soit présent :
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Le plan d'exécution de la suppression est très simple :
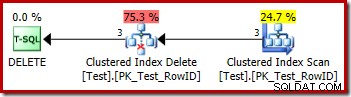
Chaque ligne qualifiée est transmise directement à un opérateur Clustered Index Delete, qui la supprime. Facile.
Plan d'exécution avec un déclencheur INSTEAD OF
Modifions maintenant le test pour inclure un déclencheur INSTEAD OF DELETE (un déclencheur qui effectue simplement la même action de suppression pour plus de simplicité) :
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Le plan d'exécution de la DELETE est désormais assez différent :
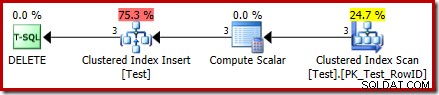
L'opérateur Clustered Index Delete a été remplacé par un clustered Index Insert . Il s'agit de l'insertion dans la table de travail masquée, qui est renommée (dans la représentation du plan d'exécution public) avec le nom de la table de base affectée par la suppression. Le changement de nom se produit lorsque le plan d'affichage XML est généré à partir de la représentation du plan d'exécution interne, il n'existe donc aucun moyen documenté de voir la table de travail masquée.
Suite à ce changement, le plan semble donc effectuer un insert à la table de base afin de supprimer rangées de celui-ci. C'est déroutant, mais cela révèle au moins la présence d'un déclencheur INSTEAD OF. Remplacer l'opérateur Insérer par un Supprimer peut être encore plus déroutant. Peut-être que l'idéal serait une nouvelle icône graphique pour une table de travail de déclenchement INSTEAD OF ? Quoi qu'il en soit, c'est ce que c'est.
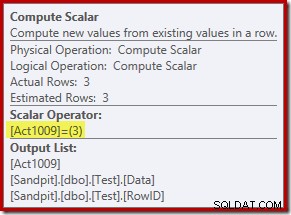
Le nouvel opérateur Compute Scalar définit le type d'action effectuée sur chaque ligne. Ce code d'action est un entier, avec les significations suivantes :
- 3 =SUPPRIMER
- 4 =INSÉRER
- 259 =SUPPRIMER dans un plan MERGE
- 260 =INSÉRER dans un plan de FUSION
Pour cette requête, l'action est une constante 3, ce qui signifie que chaque ligne doit être supprimée :
Actions de mise à jour
Soit dit en passant, un plan d'exécution INSTEAD OF UPDATE remplace un seul opérateur Update par deux Insertions d'index clusterisées dans la même table de travail masquée - une pour les insérés lignes de pseudo-table, et une pour les lignes supprimées lignes de pseudo-table. Un exemple de plan d'exécution :

Un MERGE qui effectue un UPDATE produit également un plan d'exécution avec deux insertions dans la même table de base pour des raisons similaires :

Le plan d'exécution du déclencheur
Le plan d'exécution du corps du déclencheur présente également des fonctionnalités intéressantes :
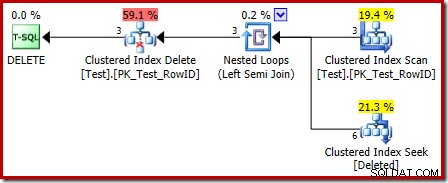
La première chose à remarquer est que l'icône graphique utilisée pour la table supprimée n'est pas la même que l'icône utilisée dans les plans de déclenchement APRÈS :
La représentation dans le plan de déclenchement INSTEAD OF est une recherche d'index clusterisé. L'objet sous-jacent est la même table de travail interne que nous avons vue précédemment, bien qu'ici il soit nommé supprimé au lieu de recevoir le nom de la table de base, probablement pour une sorte de cohérence avec les déclencheurs AFTER.
L'opération de recherche sur le supprimé table peut ne pas correspondre à ce que vous attendiez (si vous vous attendiez à une recherche sur RowID) :
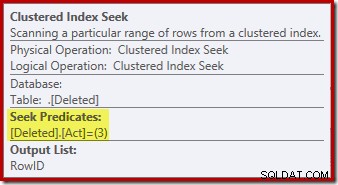
Cette "recherche" renvoie toutes les lignes de la table de travail qui ont un code d'action de 3 (supprimer), ce qui en fait exactement l'équivalent de l'analyse supprimée opérateur vu dans les plans de déclenchement AFTER. La même table de travail interne est utilisée pour contenir les lignes pour les deux insérées et supprimé pseudo-tables dans les triggers INSTEAD OF. L'équivalent d'un scan inséré est une recherche sur le code d'action 4 (ce qui est possible dans un supprimer déclencheur, mais le résultat sera toujours vide). Il n'y a pas d'index sur la table de travail interne à part l'index clusterisé non unique sur l'action colonne seule. De plus, aucune statistique n'est associée à cet index interne.
Jusqu'à présent, l'analyse peut vous amener à vous demander où la jointure entre les colonnes RowID est effectuée. Cette comparaison se produit au niveau de l'opérateur Nested Loops Left Semi Join en tant que prédicat résiduel :
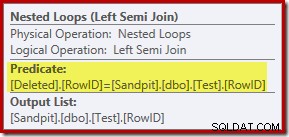
Maintenant que nous savons que la "recherche" est en fait une analyse complète des éléments supprimés table, le plan d'exécution choisi par l'optimiseur de requête semble assez inefficace. Le flux global du plan d'exécution est que chaque ligne de la table de test est potentiellement comparée à l'ensemble des éléments supprimés lignes, ce qui ressemble beaucoup à un produit cartésien.
La grâce salvatrice est que la jointure est une semi-jointure, ce qui signifie que le processus de comparaison s'arrête pour une ligne de test donnée dès que le premier supprimé row satisfait le prédicat résiduel. Néanmoins, la stratégie semble curieuse. Peut-être que le plan d'exécution serait meilleur si la table Test contenait plus de lignes ?
Test de déclenchement avec 1 000 lignes
Le script suivant peut être utilisé pour tester le déclencheur avec un plus grand nombre de lignes. Nous allons commencer avec 1 000 :
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Le plan d'exécution pour le corps du déclencheur est maintenant :
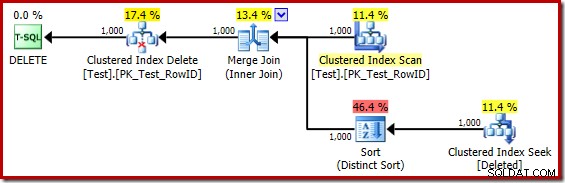
En remplaçant mentalement la recherche d'index clusterisée (trompeuse) par une analyse supprimée, le plan semble généralement assez bon. L'optimiseur a choisi une jointure de fusion un-à-plusieurs au lieu d'une semi-jointure de boucles imbriquées, ce qui semble raisonnable. Le tri distinct est cependant un ajout curieux :
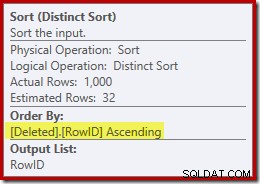
Ce tri remplit deux fonctions. Tout d'abord, il fournit à la jointure de fusion l'entrée triée dont elle a besoin, ce qui est assez juste car il n'y a pas d'index sur la table de travail interne pour fournir l'ordre nécessaire. La deuxième chose que fait le tri est de distinguer sur RowID. Cela peut sembler étrange, car RowID est la clé primaire de la table de base.
Le problème est que les lignes dans le supprimé table sont simplement des lignes candidates identifiées par la requête DELETE d'origine. Contrairement à un déclencheur AFTER, ces lignes n'ont pas encore été vérifiées pour les violations de contrainte ou de clé, de sorte que le processeur de requêtes n'a aucune garantie qu'elles sont en fait uniques.
Généralement, c'est un point très important à garder à l'esprit avec les déclencheurs INSTEAD OF :il n'y a aucune garantie que les lignes fournies respectent l'une des contraintes de la table de base (y compris NOT NULL). Ce n'est pas seulement important que l'auteur du déclencheur s'en souvienne; cela limite également les simplifications et les transformations que l'optimiseur de requête peut effectuer.
Un deuxième problème présenté dans les propriétés de tri ci-dessus, mais non mis en évidence, est que l'estimation de sortie ne comprend que 32 lignes. La table de travail interne n'a pas de statistiques associées, donc l'optimiseur suppose à l'effet de l'opération Distinct. Nous "savons" que les valeurs RowID sont uniques, mais sans aucune information concrète, l'optimiseur fait une mauvaise estimation. Ce problème reviendra nous hanter lors du prochain test.
Test de déclenchement avec 5 000 lignes
Modifiez maintenant le script de test pour générer 5 000 lignes :
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Le plan d'exécution du déclencheur est :
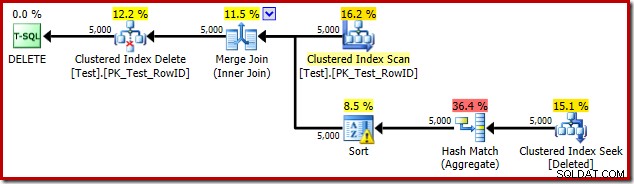
Cette fois, l'optimiseur a décidé de scinder les opérations de distinction et de tri. La distinction sur RowID est effectuée par l'opérateur Hash Match (Aggregate) :
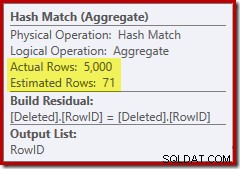
Notez que l'estimation de l'optimiseur pour la sortie est de 71 lignes. En fait, les 5 000 lignes survivent à la distinction car RowID est unique. L'estimation inexacte signifie qu'une fraction inadéquate de l'allocation de mémoire de requête est allouée au tri, qui finit par se répandre sur tempdb :
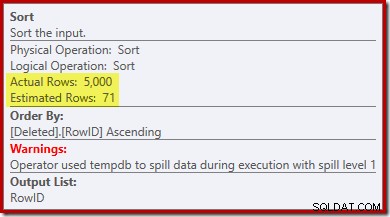
Ce test doit être effectué sur SQL Server 2012 ou supérieur afin de voir l'avertissement de tri dans le plan d'exécution. Dans les versions précédentes, le plan ne contenait aucune information sur les débordements - une trace du profileur sur l'événement Trier les avertissements serait nécessaire pour le révéler (et vous auriez besoin de corréler cela avec la requête source d'une manière ou d'une autre).
Test de déclenchement avec 5 000 lignes sur SQL Server 2014
Si le test précédent est répété sur SQL Server 2014, dans une base de données définie sur le niveau de compatibilité 120 afin que le nouvel estimateur de cardinalité (CE) soit utilisé, le plan d'exécution du déclencheur est à nouveau différent :
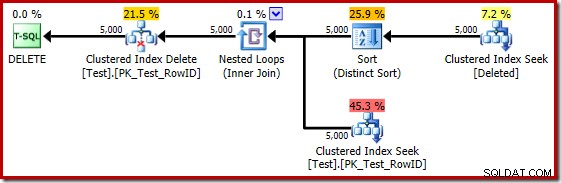
À certains égards, ce plan d'exécution semble être une amélioration. Le tri distinct (inutile) est toujours là, mais la stratégie globale semble plus naturelle :pour chaque RowID candidat distinct dans le supprimé table, joignez-la à la table de base (vérifiant ainsi que la ligne candidate existe réellement) puis supprimez-la.
Malheureusement, le plan 2014 est basé sur des estimations de cardinalité pires que celles que nous avons vues dans SQL Server 2012. Changer l'explorateur de plan SQL Sentry pour afficher l'estimation le nombre de lignes montre clairement le problème :
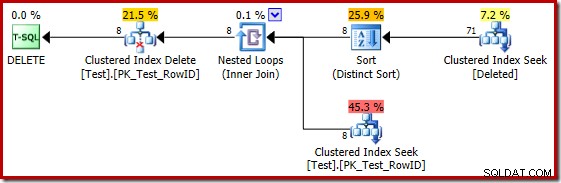
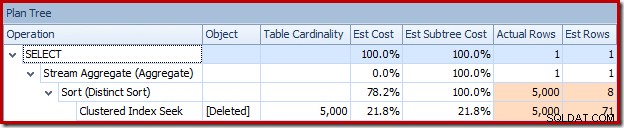
L'optimiseur a choisi une stratégie de boucles imbriquées pour la jointure car il s'attendait à un très petit nombre de lignes sur son entrée supérieure. Le premier problème se produit au niveau de Clustered Index Seek. L'optimiseur sait que la table supprimée contient 5 000 lignes à ce stade, comme nous pouvons le voir en passant à l'affichage de l'arborescence du plan et en ajoutant la colonne facultative Table Cardinality (que j'aurais aimé inclure par défaut) :
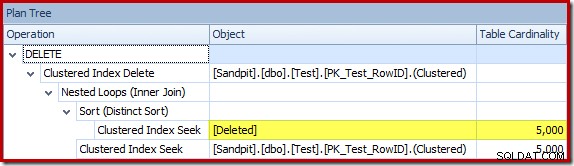
L'« ancien » estimateur de cardinalité dans SQL Server 2012 et les versions antérieures est suffisamment intelligent pour savoir que la « recherche » sur la table de travail interne renverrait les 5 000 lignes (il a donc choisi une jointure de fusion). Le nouveau CE n'est pas si intelligent. Il voit la table de travail comme une "boîte noire" et devine l'effet de la recherche sur le code d'action =3 :
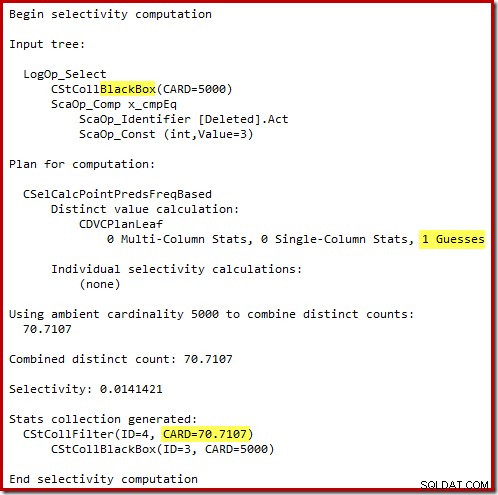
L'estimation de 71 lignes (arrondies) est un résultat assez misérable, mais l'erreur est aggravée lorsque le nouveau CE estime les lignes pour l'opération distincte sur ces 71 lignes :
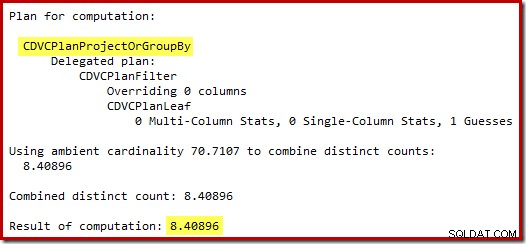
Sur la base des 8 lignes attendues, l'optimiseur choisit la stratégie Nested Loops. Une autre façon de voir ces erreurs d'estimation consiste à ajouter l'instruction suivante au corps du déclencheur (à des fins de test uniquement) :
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
Le plan estimé montre clairement les erreurs d'estimation :
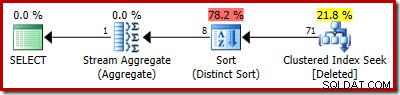
Le plan actuel affiche toujours 5 000 lignes :
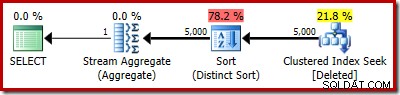
Ou vous pouvez comparer l'estimation au réel en même temps dans l'arborescence du plan :
Un million de lignes…
Les mauvaises estimations lors de l'utilisation de l'estimateur de cardinalité de 2014 obligent l'optimiseur à sélectionner une stratégie de boucles imbriquées même lorsque la table de test contient un million de lignes. Le nouveau CE 2014 estimé plan pour ce test est :
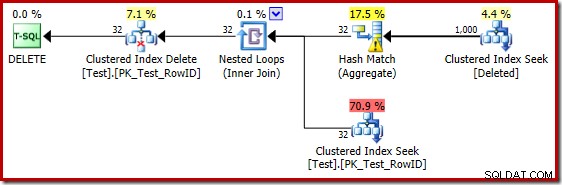
La « recherche » estime 1 000 lignes à partir de la cardinalité connue de 1 000 000 et l'estimation distincte est de 32 lignes. Le plan de post-exécution révèle l'effet sur la mémoire réservée au Hash Match :
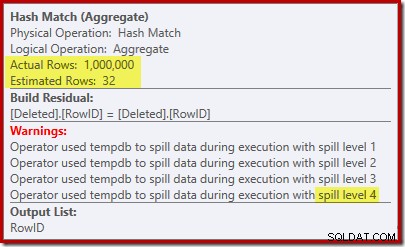
S'attendant à seulement 32 lignes, le Hash Match rencontre de réels problèmes, déversant de manière récursive sa table de hachage avant de se terminer.
Réflexions finales
S'il est vrai qu'un déclencheur ne doit jamais être écrit pour faire quelque chose qui peut être réalisé avec l'intégrité référentielle déclarative, il est également vrai qu'un déclencheur bien écrit déclencheur qui utilise un efficace plan d'exécution peut être comparable en termes de performances au coût de maintenance d'un index non clusterisé supplémentaire.
Il y a deux problèmes pratiques avec la déclaration ci-dessus. Tout d'abord (et avec la meilleure volonté du monde), les gens n'écrivent pas toujours un bon code de déclenchement. Deuxièmement, obtenir un bon plan d'exécution de l'optimiseur de requêtes en toutes circonstances peut être difficile. La nature des déclencheurs est qu'ils sont appelés avec un large éventail de cardinalités d'entrée et de distributions de données.
Même pour les triggers AFTER, le manque d'index et de statistiques sur les supprimés et inséré les pseudo-tables signifient que la sélection du plan est souvent basée sur des suppositions ou des informations erronées. Même lorsqu'un bon plan est initialement sélectionné, des exécutions ultérieures peuvent réutiliser le même plan alors qu'une recompilation aurait été un meilleur choix. Il existe des moyens de contourner les limitations, principalement grâce à l'utilisation de tables temporaires et d'index/statistiques explicites, mais même là, une grande prudence est requise (puisque les déclencheurs sont une forme de procédure stockée).
Avec les déclencheurs INSTEAD OF, les risques peuvent être encore plus grands car le contenu du insert et supprimé les tables sont des candidats non vérifiés - l'optimiseur de requête ne peut pas utiliser de contraintes sur la table de base pour simplifier et affiner son plan d'exécution. Le nouvel estimateur de cardinalité de SQL Server 2014 représente également un véritable pas en arrière en ce qui concerne les plans de déclenchement INSTEAD OF. Deviner l'effet d'une opération de recherche que le moteur s'est introduit est un oubli surprenant et malvenu.