Pourquoi l'exécution d'une requête prend-elle autant de temps ? Pourquoi n'y a-t-il pas d'index ? Il y a de fortes chances que vous ayez entendu parler d'EXPLAIN dans PostgreSQL. Cependant, il y a encore beaucoup de gens qui ne savent pas comment l'utiliser. J'espère que cet article aidera les utilisateurs à s'attaquer à ce formidable outil.
Cet article est la révision d'auteur de Comprendre EXPLAIN par Guillaume Lelarge. Comme j'ai raté certaines informations, je vous recommande fortement de vous familiariser avec l'original.
Le diable n'est pas aussi noir qu'il est peint
Il est important de comprendre la logique du noyau PostgreSQL pour optimiser les requêtes. Je vais essayer d'expliquer. Ce n'est vraiment pas si compliqué.
EXPLAIN affiche les informations nécessaires qui expliquent ce que fait le noyau pour chaque requête spécifique.
Examinons ce que la commande EXPLAIN affiche et comprenons ce qui se passe exactement dans PostgreSQL. Vous pouvez appliquer ces informations à PostgreSQL 9.2 et versions supérieures.
Nos tâches :
- Apprenez à lire et à comprendre le résultat de la commande EXPLAIN
- Comprendre ce qui se passe dans PostgreSQL lorsqu'une requête est exécutée
Premiers pas
Nous allons nous entraîner sur une table de test avec un million de lignes.
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
Essayez de lire les données
EXPLAIN SELECT * FROM foo;
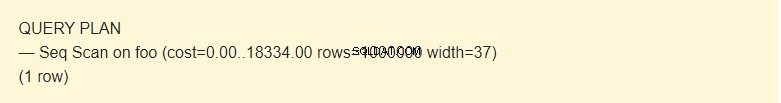
Il est possible de lire les données d'une table de plusieurs manières. Dans notre cas, EXPLAIN notifie qu'un Seq Scan est utilisé - une lecture séquentielle, bloc par bloc, des données de la table Foo.
Quel est le coût ? ?
Eh bien, ce n'est pas un temps, mais un concept conçu pour estimer le coût d'une opération. La première valeur 0,00 correspond aux coûts d'obtention de la première ligne. La deuxième valeur 18334.00 correspond aux coûts d'obtention de toutes les lignes.
Lignes sont le nombre approximatif de lignes renvoyées lorsqu'une opération Seq Scan est effectuée. Le planificateur renvoie cette valeur. Dans mon cas, cela correspond au nombre réel de lignes dans le tableau.
Largeur est une taille moyenne d'une ligne en octets.
Essayons d'ajouter 10 lignes.
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

La valeur des lignes n'a pas été modifiée. Les statistiques du tableau sont anciennes. Pour mettre à jour les statistiques, appelez la commande ANALYSE.
Maintenant, lignes afficher le nombre correct de lignes.
Que se passe-t-il lors de l'exécution d'ANALYZE ?
- Au hasard, un certain nombre de lignes sont sélectionnées et lues à partir du tableau.
- Les statistiques des valeurs de chaque colonne sont collectées.
Le nombre de lignes lues par ANALYZE dépend du paramètre default_statistics_target.
Données réelles
Tout ce que nous avons vu ci-dessus dans la sortie de la commande EXPLAIN correspond à ce que le planificateur s'attend à obtenir. Essayons de les comparer avec les résultats sur des données réelles. Pour ce faire, utilisez EXPLAIN (ANALYSE).
EXPLAIN (ANALYZE) SELECT * FROM foo;

Une telle requête sera effectivement effectuée. Ainsi, si vous exécutez EXPLAIN (ANALYZE) pour les instructions INSERT, DELETE ou UPDATE, vos données seront modifiées. Fais attention! Dans ces cas, utilisez la commande ROLLBACK.
La commande affiche les paramètres supplémentaires suivants :
- le temps réel est le temps réel en millisecondes passé pour obtenir la première ligne et toutes les lignes, respectivement.
- rows est le nombre réel de lignes reçues avec Seq Scan.
- boucles est le nombre de fois que l'opération Seq Scan a dû être effectuée.
- Le temps d'exécution total correspond au temps total d'exécution de la requête.
Pour en savoir plus :
Optimisation des requêtes dans PostgreSQL. EXPLIQUER les bases – Partie 2
Optimisation des requêtes dans PostgreSQL. EXPLIQUER les bases – Partie 3