La réplication MariaDB est l'une des solutions de haute disponibilité les plus populaires pour MariaDB et largement utilisée par les plus grandes entreprises comme Booking.com et Google. Il est très facile à configurer, avec quelques compromis sur la maintenance continue comme les mises à niveau logicielles, les changements de schéma, les changements de topologie, le basculement et la récupération qui ont toujours été délicats. Néanmoins, avec le bon ensemble d'outils, vous devriez pouvoir gérer facilement la topologie. Dans cet article de blog, nous allons examiner quelques conseils pour surveiller efficacement la réplication MariaDB à l'aide de ClusterControl.
Utilisation de la visionneuse de topologie
Une configuration de réplication se compose d'un certain nombre de rôles. Un nœud dans une configuration de réplication peut être :
- Maître – L'auteur/lecteur principal.
- Maître de sauvegarde :esclave en lecture seule avec réplication semi-synchronisée, uniquement pour la redondance du maître.
- Maître intermédiaire - Répliquer à partir d'un maître, tandis que d'autres esclaves répliquent à partir de ce nœud.
- Serveur Binlog :collecte/stocke uniquement les journaux binaires sans fournir de données.
- Esclave :réplique à partir d'un maître et généralement défini en lecture seule.
- Esclave multi-source – Réplication à partir de plusieurs maîtres.
Chaque rôle a sa propre responsabilité et ses propres limites et il faut comprendre la topologie correcte lorsqu'il s'agit de nœuds de base de données. Cela est également vrai pour l'application, où l'application doit écrire uniquement sur le nœud maître à un moment donné. Ainsi, il est important d'avoir une vue d'ensemble sur quel nœud tient quel rôle, afin de ne pas bousiller notre base de données.
Dans ClusterControl, la visionneuse de topologie peut vous donner un aperçu de la topologie de réplication et de son état, comme illustré dans la capture d'écran suivante :
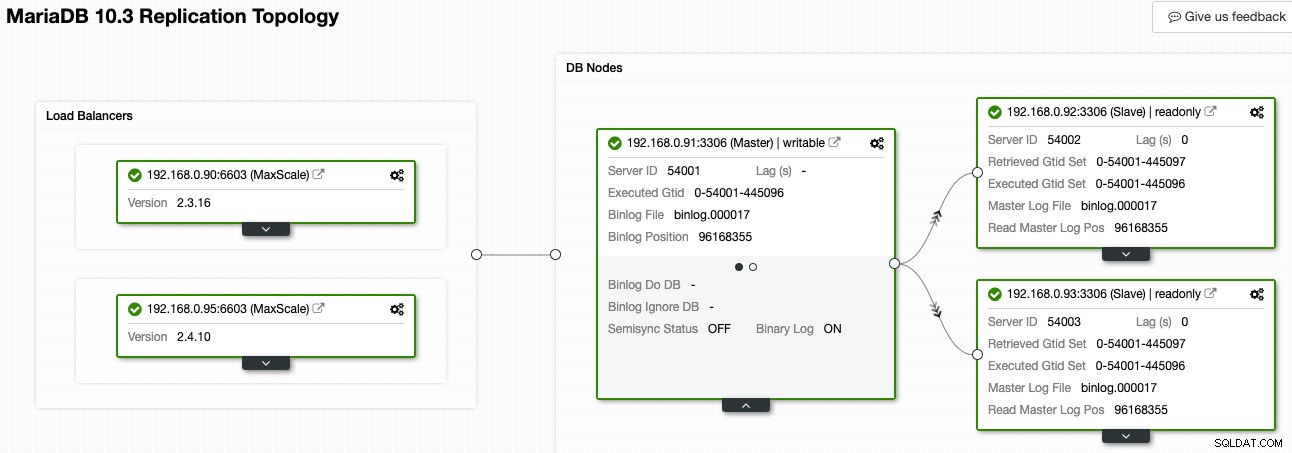
ClusterControl comprend la réplication MariaDB et est capable de visualiser la topologie avec le flux de données de réplication correct, comme représenté par les flèches pointant vers les nœuds esclaves. Nous pouvons facilement distinguer quel nœud est le maître, les esclaves et les équilibreurs de charge (MaxScale) dans notre configuration de réplication. La case verte indique que tous les services importants fonctionnent comme prévu avec le rôle attribué.
Considérez la capture d'écran suivante où un certain nombre de nos nœuds ont des problèmes :
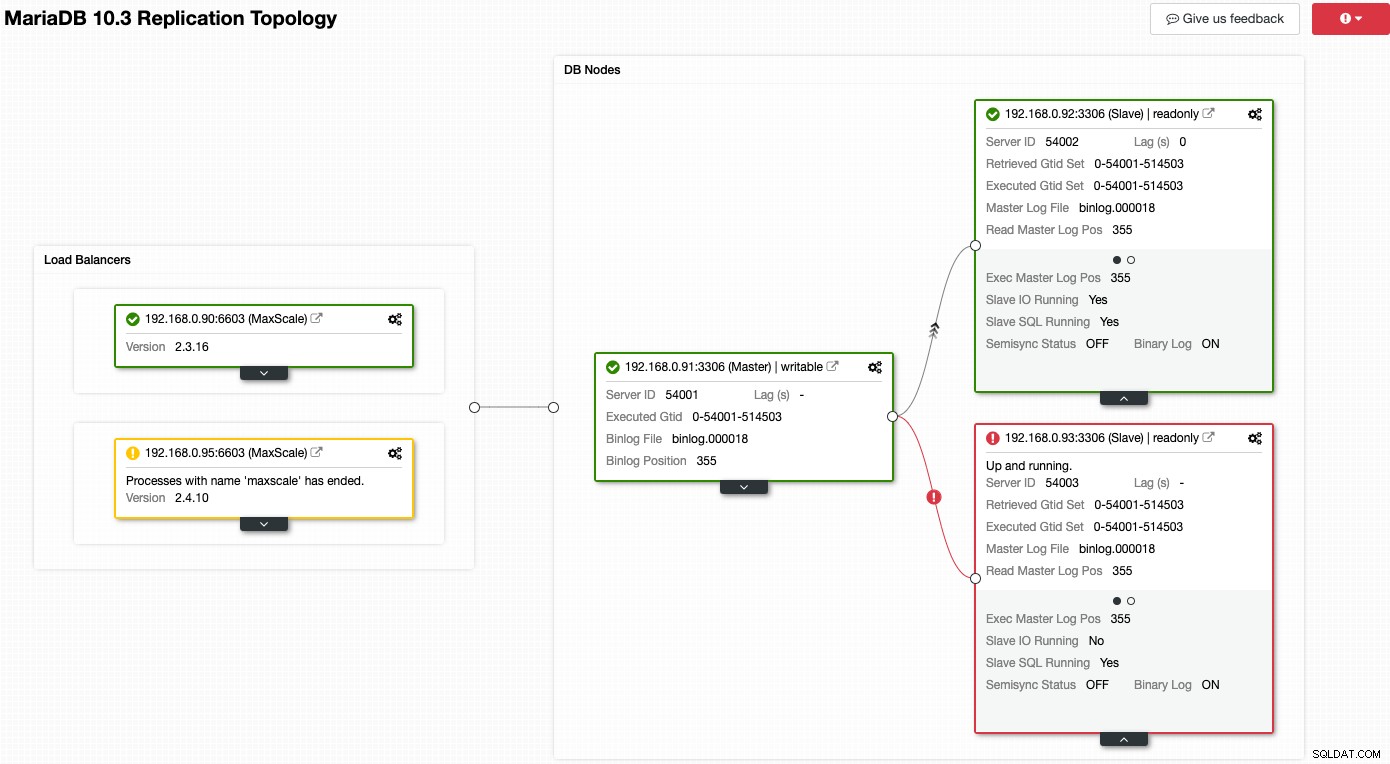
ClusterControl vous indiquera immédiatement ce qui ne va pas avec la topologie actuelle. L'un des esclaves (boîte rouge) affiche "E/S esclave en cours d'exécution" sur Non, pour indiquer un problème de connectivité à répliquer à partir du maître. Alors que la case jaune indique que notre service MaxScale n'est pas en cours d'exécution. Nous pouvons également dire que les versions de MaxScale ne sont pas identiques pour les deux nœuds. Vous pouvez également effectuer des tâches de gestion en cliquant directement sur l'icône d'engrenage (en haut à droite de chaque case), ce qui réduit les risques de sélectionner un mauvais nœud.
Délai de réplication
C'est la chose la plus importante si vous comptez sur la cohérence de la réplication des données. Un décalage de réplication se produit lorsque les esclaves ne peuvent pas suivre les mises à jour qui se produisent sur le maître. Les modifications non appliquées s'accumulent dans les journaux de relais des esclaves et la version de la base de données sur les esclaves devient de plus en plus différente de celle du maître.
Dans ClusterControl, vous pouvez trouver l'histogramme de retard de réplication sous Présentation > Retard de réplication où ClusterControl échantillonne constamment la valeur Seconds_Behind_Master à partir de la sortie "SHOW SLAVE STATUS" :
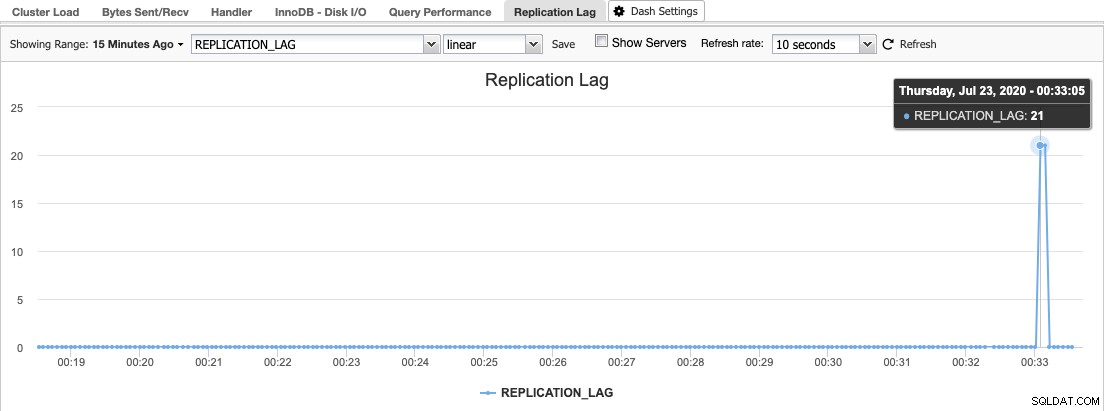
Un décalage de réplication se produit lorsque le thread d'E/S ou le thread SQL ne peut pas faire face aux demandes qui lui sont faites. Si le Thread d'E/S souffre, cela signifie que la connexion réseau entre le maître et ses esclaves est lente ou a des problèmes. Vous voudrez peut-être envisager d'activer le protocole slave_compressed_protocol pour compresser le trafic réseau ou signaler à votre administrateur réseau.
S'il s'agit du thread SQL, le problème est probablement dû à des requêtes mal optimisées qui mettent trop de temps à s'appliquer à l'esclave. Il peut y avoir des transactions de longue durée ou trop d'activité d'E/S. L'absence de clé primaire sur les tables esclaves lors de l'utilisation du format de réplication ROW ou MIXED est également une cause fréquente de décalage sur ce thread. Vérifiez que les versions maître et esclave des tables ont une clé primaire.
D'autres trucs et astuces sont couverts dans cet article de blog, Comment réduire le retard de réplication dans les déploiements multi-cloud.
Taille du journal binaire/relais
Il est important de surveiller la taille du disque des journaux binaires et de relais, car cela peut consommer une quantité considérable de stockage sur chaque nœud d'un cluster de réplication. Généralement, on définirait la variable système expire_logs_days pour faire expirer automatiquement les fichiers journaux binaires après un nombre de jours donné, par exemple, expire_logs_days=7. La taille des journaux binaires dépend totalement du nombre d'événements binaires créés (écritures entrantes) et peu que nous sachions combien d'espace disque il consommerait avant que les journaux ne soient expirés par MariaDB. Gardez à l'esprit que si vous activez log_slave_updates sur les esclaves, la taille des journaux sera presque doublée en raison de l'existence de journaux binaires et relais sur le même serveur.
Pour ClusterControl, nous pouvons définir un seuil d'utilisation de l'espace disque sous ClusterControl -> Paramètres -> Seuils pour obtenir un avertissement et des notifications critiques comme ci-dessous :
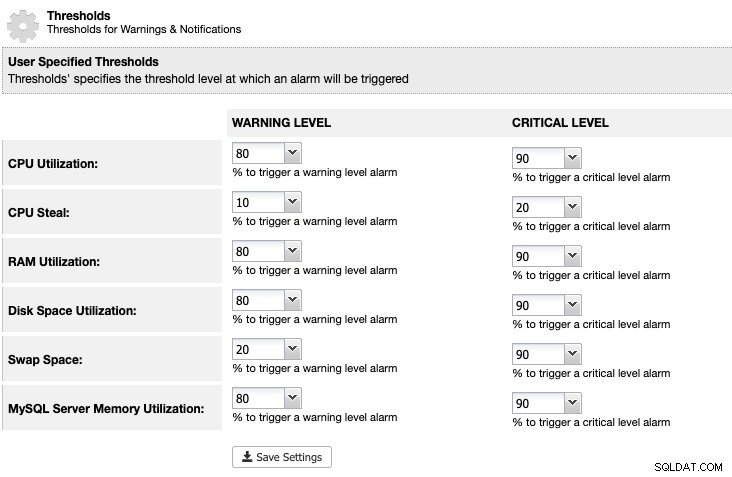
ClusterControl surveille tout l'espace disque lié aux services MariaDB comme l'emplacement des données MariaDB répertoire, le répertoire des journaux binaires ainsi que la partition racine. Si vous avez atteint le seuil, envisagez de purger manuellement les journaux binaires à l'aide de la commande PURGE BINARY LOGS, comme expliqué et discuté dans cet article.
Activer les tableaux de bord de surveillance
ClusterControl fournit deux options de surveillance pour échantillonner les nœuds de la base de données :sans agent ou avec agent. La valeur par défaut est sans agent où l'échantillonnage se produit via SSH dans un mécanisme d'extraction uniquement. La surveillance basée sur des agents nécessite qu'un serveur Prometheus soit en cours d'exécution et que tous les nœuds surveillés soient configurés avec au moins trois exportateurs :
- Exportateur de processus (port 9011)
- Exportateur de métriques de nœud/système (port 9100)
- Exportateur MySQL/MariaDB (port 9104)
Pour activer le tableau de bord de surveillance basé sur l'agent, il faut aller dans ClusterControl -> Tableaux de bord -> Activer la surveillance basée sur l'agent. Une fois activé, vous verrez un ensemble de tableaux de bord configurés pour notre réplication MariaDB, ce qui nous donne un bien meilleur aperçu de notre configuration de réplication. La capture d'écran suivante montre ce que vous verriez pour le nœud maître :
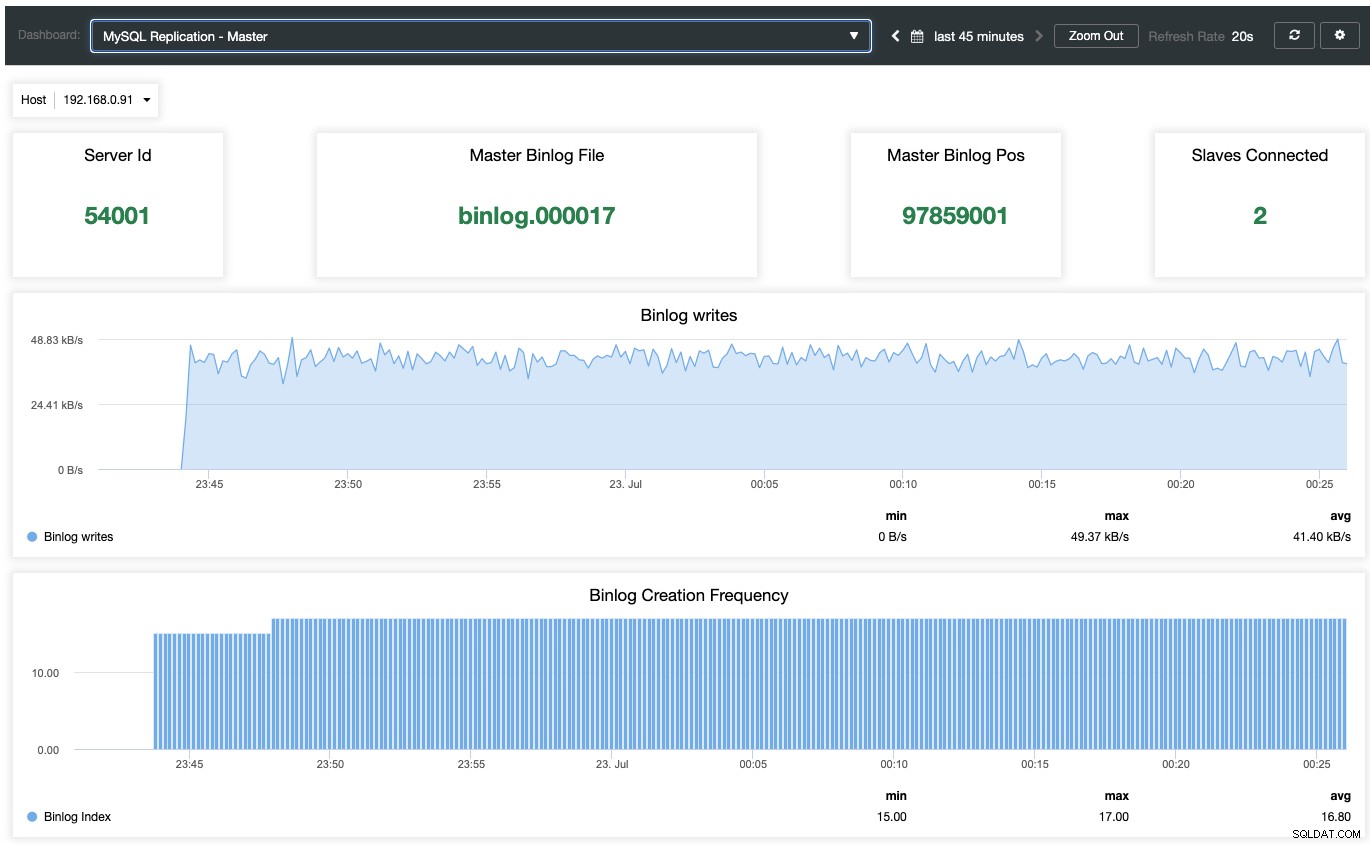
Outre les tableaux de bord de surveillance standard MariaDB tels que les métriques générales, les caches et InnoDB, vous sera présenté avec un tableau de bord de réplication. Pour le nœud maître, nous pouvons obtenir de nombreuses informations utiles concernant l'état du maître, le débit d'écriture et la fréquence de création de binlog.
Alors que pour les esclaves, tous les états importants sont échantillonnés et résumés dans la capture d'écran suivante. si tout est vert, vous êtes entre de bonnes mains :
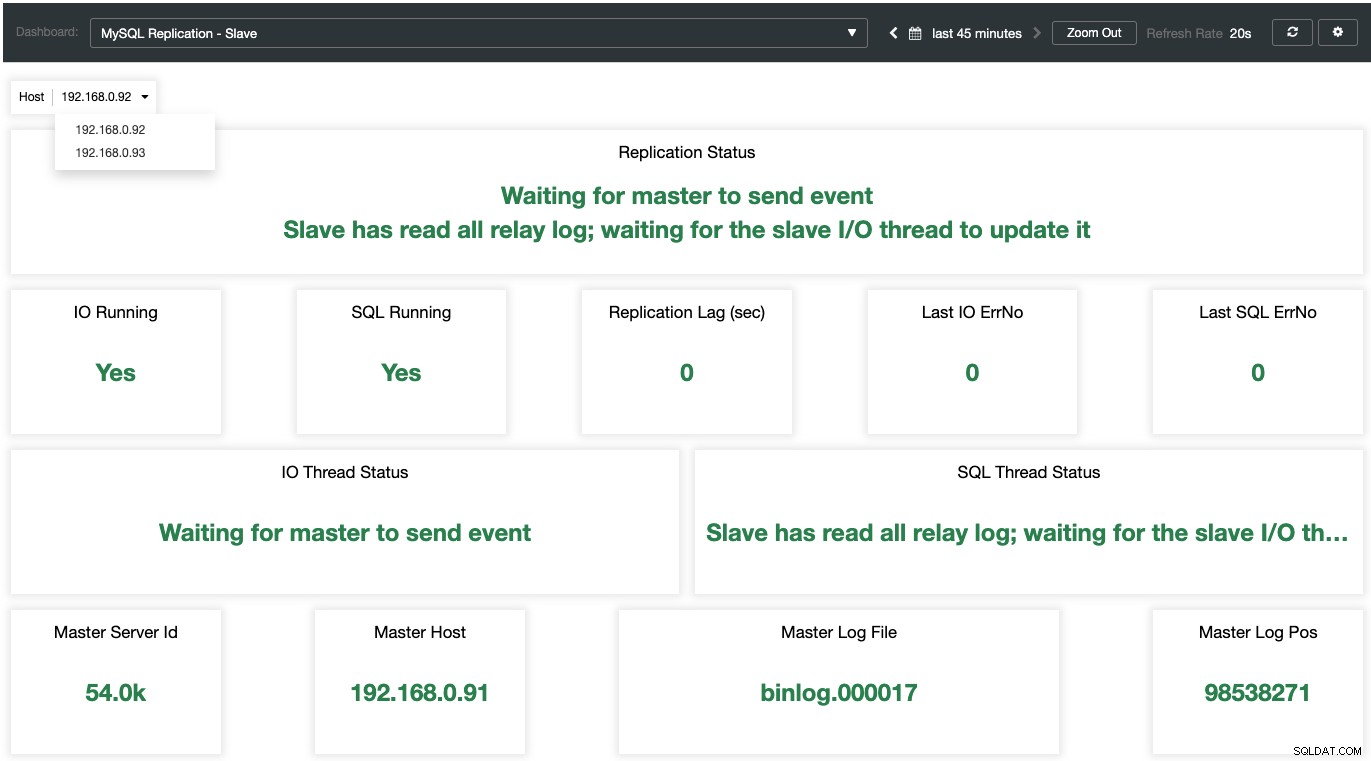
Comprendre le journal des erreurs MariaDB
MariaDB enregistre ses événements importants dans le journal des erreurs, ce qui est utile pour comprendre ce qui se passait avec le serveur, en particulier avant, pendant et après un changement de topologie. ClusterControl fournit une vue centralisée des journaux d'erreurs sous ClusterControl -> Journaux -> Journaux système en les extrayant de chaque nœud de base de données. Vous cliquez sur "Actualiser les journaux" pour déclencher une tâche afin d'extraire les derniers journaux du serveur.
Les fichiers collectés sont représentés dans une arborescence de navigation et une zone de texte avec coloration syntaxique pour une meilleure lisibilité :
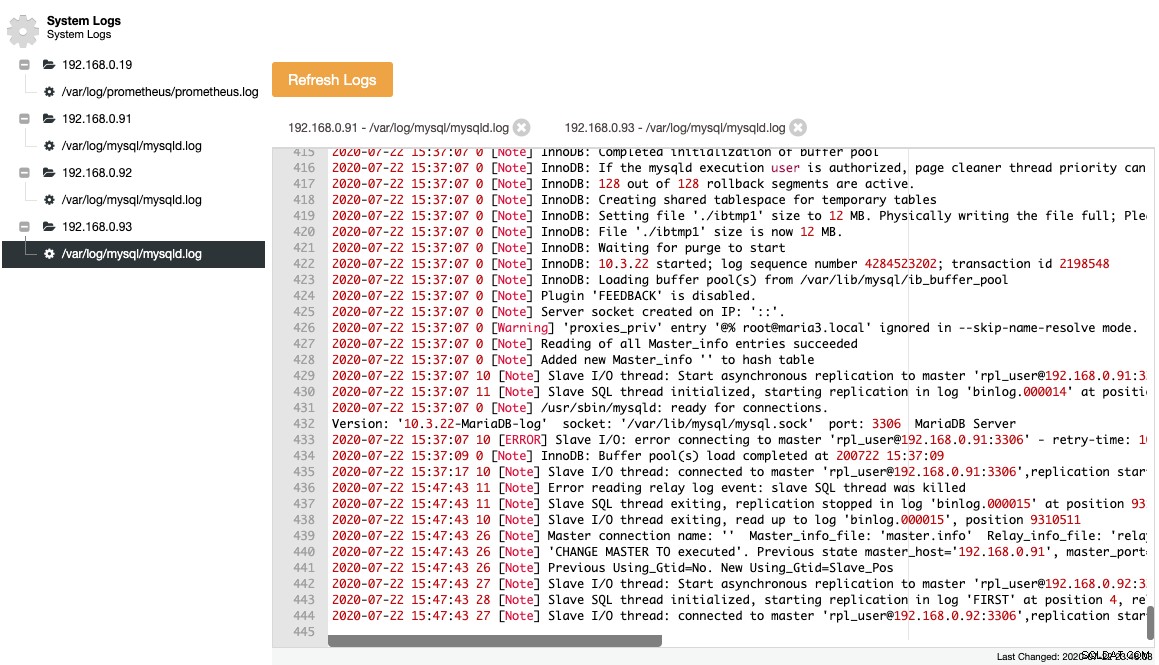
À partir de la capture d'écran ci-dessus, nous pouvons comprendre la séquence d'événements et ce qui est arrivé à ce nœud lors d'un événement de changement de topologie. À partir des 12 dernières lignes du journal des erreurs ci-dessus, l'esclave a eu une erreur une fois connecté au maître et le dernier fichier journal binaire et la position ont été enregistrés dans le journal avant qu'il ne s'arrête. Ensuite, une nouvelle commande CHANGE MASTER a été exécutée avec les informations GTID, comme indiqué dans la ligne "Previous Using_Gtid=No. New Using_Gtid=Slave_Pos", puis la réplication reprend comme nous le souhaitions.
Alerte et notifications MariaDB
La surveillance est incomplète sans alertes et notifications. Tous les événements et alarmes générés par ClusterControl peuvent être envoyés par e-mail ou à tout autre outil tiers pris en charge. Pour les notifications par e-mail, on peut configurer si le type d'événements sera livré immédiatement, ignoré ou digéré (un rapport résumé quotidien) :

Pour tous les événements de gravité critique, il est recommandé de tout définir sur "Livraison" afin que vous receviez les notifications dès que possible. Définissez "Digest" sur les événements d'avertissement afin de bien connaître la santé et l'état du cluster.
Vous pouvez intégrer vos outils de communication et de messagerie préférés à ClusterControl en utilisant la fonction de gestion des notifications sous ClusterControl -> Intégrations -> Notifications tierces. ClusterControl peut envoyer des alarmes et des événements à PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow ou à tout autre webhook enregistré par un utilisateur.
La capture d'écran suivante montre que tous les événements critiques seront transmis au canal de télégramme configuré pour notre cluster de réplication MariaDB 10.3 :

ClusterControl prend également en charge l'intégration de chatbot, où vous pouvez interagir avec le service de contrôleur via le client s9s directement depuis votre outil de messagerie, comme indiqué dans cet article de blog, Automatisez votre base de données avec CCBot :Intégration de ClusterControl Hubot.
Conclusion
ClusterControl propose un ensemble complet d'outils de surveillance proactive pour vos clusters de bases de données. Utilisez ClusterControl pour surveiller votre configuration de réplication MariaDB car la plupart des fonctionnalités de surveillance sont disponibles gratuitement dans l'édition communautaire. Ne les manquez pas !