
Ce n'est pas une bonne fragmentation non plus
Le mois dernier, j'ai écrit sur la fragmentation inattendue des index clusterisés. Cette fois, j'aimerais discuter de certaines des choses que vous pouvez faire pour éviter la fragmentation des index. Je suppose que vous avez lu le post précédent et que vous connaissez les termes que j'y ai définis, et dans le reste de cet article, quand je dis "fragmentation", je fais référence à la fois à la fragmentation logique et aux problèmes de faible densité de page.
Choisir une bonne clé de cluster
La structure de données la plus coûteuse sur laquelle opérer pour supprimer la fragmentation est l'index clusterisé d'une table, car c'est la plus grande structure car elle contient toutes les données de la table. Du point de vue de la fragmentation, il est logique de choisir une clé de cluster qui correspond au modèle d'insertion de table, de sorte qu'il n'y a aucune possibilité qu'une insertion se produise sur une page où il n'y a pas d'espace, provoquant ainsi une division de page et introduisant une fragmentation.
Ce qui constitue la meilleure clé de cluster pour une table donnée fait l'objet de nombreux débats, mais en général, vous ne vous tromperez pas si votre clé de cluster a les propriétés simples suivantes :
- Étroit (c'est-à-dire aussi peu de colonnes que possible)
- Statique (c'est-à-dire que vous ne le mettez jamais à jour)
- Unique
- En constante augmentation
C'est la propriété toujours croissante qui est la plus importante pour la prévention de la fragmentation, car elle évite les insertions aléatoires qui peuvent provoquer des fractionnements de page sur des pages déjà pleines. Des exemples d'un tel choix de clé sont les colonnes int identity et bigint identity, ou même un GUID séquentiel de la fonction NEWSEQUENTIALID().
Avec ces types de clés, les nouvelles lignes auront une valeur de clé garantie supérieure à toutes les autres dans la table, et ainsi le point d'insertion de la nouvelle ligne sera à la fin de la page la plus à droite dans la structure de l'index clusterisé. Finalement, les nouvelles lignes rempliront cette page et une autre page sera ajoutée sur le côté droit de l'index, mais sans qu'aucune division de page dommageable ne se produise.
Maintenant, si vous avez une clé d'index clusterisée qui n'augmente pas toujours, cela peut être une procédure très complexe et désagréable de la changer en une clé toujours croissante, alors ne vous inquiétez pas - à la place, vous pouvez utiliser un facteur de remplissage comme je discute ci-dessous.
Soit dit en passant, pour un aperçu beaucoup plus approfondi du choix d'une clé de cluster et de toutes ses ramifications, consultez la catégorie de blog Clé de clustering de Kimberly (lire de bas en haut).
Ne pas mettre à jour les colonnes de clé d'index
Chaque fois qu'une colonne clé est mise à jour, ce n'est pas simplement une simple mise à jour sur place, bien que de nombreux endroits en ligne et dans les livres disent que c'est le cas (ils ont tort). Une colonne de clé ne peut pas être mise à jour sur place car la nouvelle valeur de clé signifierait alors que la ligne est dans le mauvais ordre de clé pour l'index. Au lieu de cela, une mise à jour de colonne de clé est traduite en une suppression de ligne complète plus une insertion de ligne complète avec la nouvelle valeur de clé. Si la page où la nouvelle ligne sera insérée n'a pas assez d'espace, une division de page se produira, provoquant une fragmentation.
Éviter les mises à jour de colonne de clé devrait être facile à faire pour l'index clusterisé, car il s'agit d'une mauvaise conception qui nécessite la mise à jour de la clé de cluster d'une ligne de table. Cependant, pour les index non clusterisés, il est inévitable que les mises à jour de la table impliquent des colonnes sur lesquelles se trouve un index non clusterisé. Dans ces cas, vous devrez utiliser un facteur de remplissage.
Ne mettez pas à jour les colonnes de longueur variable
Celui-ci est plus facile à dire qu'à faire. Si vous devez utiliser des colonnes de longueur variable et qu'il est possible qu'elles soient mises à jour, il est possible qu'elles grossissent et nécessitent donc plus d'espace pour la ligne mise à jour, entraînant une division de page si la page est déjà pleine.
Dans ce cas, vous pouvez faire plusieurs choses pour éviter la fragmentation :
- Utiliser un facteur de remplissage
- Utilisez plutôt une colonne de longueur fixe, si la surcharge de tous les octets de remplissage supplémentaires est moins problématique que la fragmentation ou l'utilisation d'un facteur de remplissage
- Utilisez une valeur d'espace réservé pour "réserver" de l'espace pour la colonne :c'est une astuce que vous pouvez utiliser si l'application entre dans une nouvelle ligne, puis revient pour remplir certains détails, ce qui entraîne une extension de colonne de longueur variable
- Effectuer une suppression et une insertion au lieu d'une mise à jour
Utiliser un facteur de remplissage
Comme vous pouvez le voir, de nombreuses façons d'éviter la fragmentation sont désagréables car elles impliquent des changements d'application ou de schéma, et donc l'utilisation d'un facteur de remplissage est un moyen facile d'atténuer la fragmentation.
Un facteur de remplissage d'index est un paramètre de l'index qui spécifie la quantité d'espace vide à laisser sur chaque page de niveau feuille lorsque l'index est créé, reconstruit ou réorganisé. L'idée est qu'il y a suffisamment d'espace libre sur la page pour permettre des insertions ou des croissances de lignes aléatoires (à partir d'une balise de version ajoutée ou de colonnes de longueur variable mises à jour) sans que la page ne se remplisse et ne nécessite une division de page. Cependant, la page finira par se remplir, et donc périodiquement l'espace libre doit être actualisé en reconstruisant ou en réorganisant l'index (généralement appelé maintenance de l'index). L'astuce consiste à trouver le bon facteur de remplissage à utiliser, ainsi que la bonne périodicité de maintenance de l'index.
Vous pouvez en savoir plus sur la définition d'un facteur de remplissage dans MSDN ici. Ne tombez pas dans le piège de définir le facteur de remplissage pour l'instance entière (en utilisant sp_configure) car cela signifie que tous les index seront reconstruits ou réorganisés en utilisant cette valeur de facteur de remplissage, même les index qui n'ont pas de problèmes de fragmentation. Vous ne voulez pas que vos grands index clusterisés, avec de belles clés toujours croissantes, aient tous 30% de leur espace au niveau feuille gaspillé à préparer des insertions aléatoires qui ne se produiront jamais. Il est préférable de déterminer quels index sont réellement affectés par la fragmentation et de ne définir qu'un facteur de remplissage pour ceux-ci.
Il n'y a pas de bonne réponse ou de formule magique que je puisse vous donner pour cela. La pratique généralement acceptée consiste à mettre en place un facteur de remplissage de 70 (ce qui signifie laisser 30 % d'espace libre) pour les index où la fragmentation est un problème, à surveiller la rapidité de la fragmentation, puis à modifier soit le facteur de remplissage, soit la fréquence de maintenance de l'index. (ou les deux).
Oui, cela signifie que vous gaspillez délibérément de l'espace dans les index pour éviter la fragmentation, mais c'est un bon compromis à faire étant donné le coût élevé des fractionnements de page et la façon dont la fragmentation peut nuire aux performances. Et oui, malgré ce que certains pourraient dire, cela reste important même si vous utilisez des SSD.
Résumé
Il y a quelques choses simples que vous pouvez faire pour éviter la fragmentation, mais dès que vous entrez dans des index non clusterisés, ou utilisez l'isolation d'instantané ou des secondaires lisibles, la fragmentation fait son apparition et vous devez essayer de l'empêcher.
Maintenant, ne vous précipitez pas et pensez que vous devriez définir un facteur de remplissage de 70 sur toutes vos instances - vous devez les choisir et les définir avec soin, comme je l'ai décrit ci-dessus.
Et n'oubliez pas SQL Sentry Fragmentation Manager, que vous pouvez utiliser (en tant que module complémentaire de Performance Advisor) pour déterminer où se situent les problèmes de fragmentation, puis les résoudre. Par exemple, dans l'onglet Index, vous pouvez facilement trier vos index en fonction de la fragmentation la plus élevée (et, si vous le souhaitez, appliquer un filtre à la colonne du nombre de lignes, pour ignorer vos tables plus petites) :
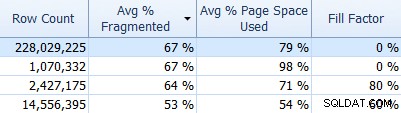
Et voyez ensuite si ces index utilisent le facteur de remplissage par défaut (0 %), ou peut-être un facteur de remplissage autre que celui par défaut, qui pourrait ne pas correspondre à vos données et aux modèles DML. Je vous laisse deviner lesquels de la capture d'écran ci-dessus m'intéresseraient le plus. La mise en œuvre de facteurs de remplissage d'index plus appropriés est le moyen le plus simple de résoudre les problèmes que vous détectez.



