C'est ce mardi du mois - vous savez, celui où se déroule la fête de quartier des blogueurs connue sous le nom de T-SQL Tuesday. Ce mois-ci, il est hébergé par Russ Thomas (@SQLJudo), et le sujet est "Appel à tous les tuners et Gear Heads". Je vais traiter ici un problème lié aux performances, bien que je m'excuse de ne pas être entièrement conforme aux directives que Russ a énoncées dans son invitation (je ne vais pas utiliser d'indices, d'indicateurs de trace ou de guides de plan) .
À SQLBits la semaine dernière, j'ai fait une présentation sur les déclencheurs, et mon bon ami et collègue MVP Erland Sommarskog était présent. À un moment donné, j'ai suggéré qu'avant de créer un nouveau déclencheur sur une table, vous devriez vérifier si des déclencheurs existent déjà et envisager de combiner la logique au lieu d'ajouter un déclencheur supplémentaire. Mes raisons étaient principalement pour la maintenabilité du code, mais aussi pour les performances. Erland m'a demandé si j'avais déjà testé pour voir s'il y avait une surcharge supplémentaire à avoir plusieurs déclencheurs pour la même action, et j'ai dû admettre que, non, je n'avais rien fait d'important. Je vais donc le faire maintenant.
Dans AdventureWorks2014, j'ai créé un ensemble simple de tables qui représentent essentiellement sys.all_objects (~2 700 lignes) et sys.all_columns (~9 500 lignes). Je voulais mesurer l'effet sur la charge de travail de diverses approches de mise à jour des deux tables - essentiellement, vous avez des utilisateurs qui mettent à jour la table des colonnes et vous utilisez un déclencheur pour mettre à jour une colonne différente dans la même table et quelques colonnes dans la table des objets.
- T1 :référence :supposons que vous pouvez contrôler tous les accès aux données via une procédure stockée ; dans ce cas, les mises à jour des deux tables peuvent être effectuées directement, sans avoir besoin de déclencheurs. (Ce n'est pas pratique dans le monde réel, car vous ne pouvez pas interdire de manière fiable l'accès direct aux tables.)
- T2 :déclencheur unique par rapport à une autre table :supposons que vous pouvez contrôler l'instruction de mise à jour par rapport à la table affectée et ajouter d'autres colonnes, mais que les mises à jour de la table secondaire doivent être implémentées avec un déclencheur. Nous mettrons à jour les trois colonnes avec une seule déclaration.
- T3 :Déclencheur unique pour les deux tables :Dans ce cas, nous avons un déclencheur avec deux instructions, une qui met à jour l'autre colonne de la table affectée et une qui met à jour les trois colonnes de la table secondaire.
- T4 :Déclencheur unique pour les deux tableaux :Comme T3, mais cette fois, nous avons un déclencheur avec quatre instructions, une qui met à jour l'autre colonne dans la table affectée, et une instruction pour chaque colonne mise à jour dans la table secondaire. Cela pourrait être la façon dont il est géré si les exigences sont ajoutées au fil du temps et qu'une déclaration distincte est jugée plus sûre en termes de tests de régression.
- T5 :deux déclencheurs :Un déclencheur met à jour uniquement la table affectée ; l'autre utilise une seule instruction pour mettre à jour les trois colonnes de la table secondaire. C'est peut-être ainsi que cela se passe si les autres déclencheurs ne sont pas remarqués ou s'il est interdit de les modifier.
- T6 :quatre déclencheurs :Un déclencheur met à jour uniquement la table affectée ; les trois autres mettent à jour chaque colonne de la table secondaire. Encore une fois, cela pourrait être la façon dont cela se passe si vous ne savez pas que les autres déclencheurs existent, ou si vous avez peur de toucher les autres déclencheurs en raison de problèmes de régression.
Voici les données sources que nous traitons :
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Maintenant, pour chacun des 6 tests, nous allons exécuter nos mises à jour 1 000 fois, et mesurer la durée
T1 :référence
C'est le scénario où nous avons la chance d'éviter les déclencheurs (encore une fois, pas très réaliste). Dans ce cas, nous mesurerons les lectures et la durée de ce lot. J'ai mis /*real*/ dans le texte de la requête afin que je puisse facilement extraire les statistiques de ces déclarations uniquement, et non des déclarations des déclencheurs, car en fin de compte, les métriques remontent aux déclarations qui invoquent les déclencheurs. Notez également que les mises à jour réelles que je fais n'ont pas vraiment de sens, alors ignorez que je définis le classement sur le nom du serveur/instance et le principal_id de l'objet au session_id de la session en cours .
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2 :déclencheur unique
Pour cela, nous avons besoin du déclencheur simple suivant, qui ne met à jour que dbo.src :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Ensuite, notre lot n'a plus qu'à mettre à jour les deux colonnes de la table principale :
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3 :déclencheur unique pour les deux tables
Pour ce test, notre déclencheur ressemble à ceci :
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Et maintenant, le lot que nous testons n'a plus qu'à mettre à jour la colonne d'origine dans la table primaire ; l'autre est géré par le trigger :
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4 :déclencheur unique pour les deux tables
C'est comme T3, mais maintenant le déclencheur a quatre instructions :
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Le lot de test est inchangé :
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5 :deux déclencheurs
Ici, nous avons un déclencheur pour mettre à jour la table primaire et un déclencheur pour mettre à jour la table secondaire :
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Le lot de test est encore une fois très basique :
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6 :Quatre déclencheurs
Cette fois, nous avons un déclencheur pour chaque colonne affectée ; une dans la table principale et trois dans les tables secondaires.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Et le lot de test :
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
Mesurer l'impact de la charge de travail
Enfin, j'ai écrit une requête simple contre sys.dm_exec_query_stats pour mesurer les lectures et la durée de chaque test :
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Résultats
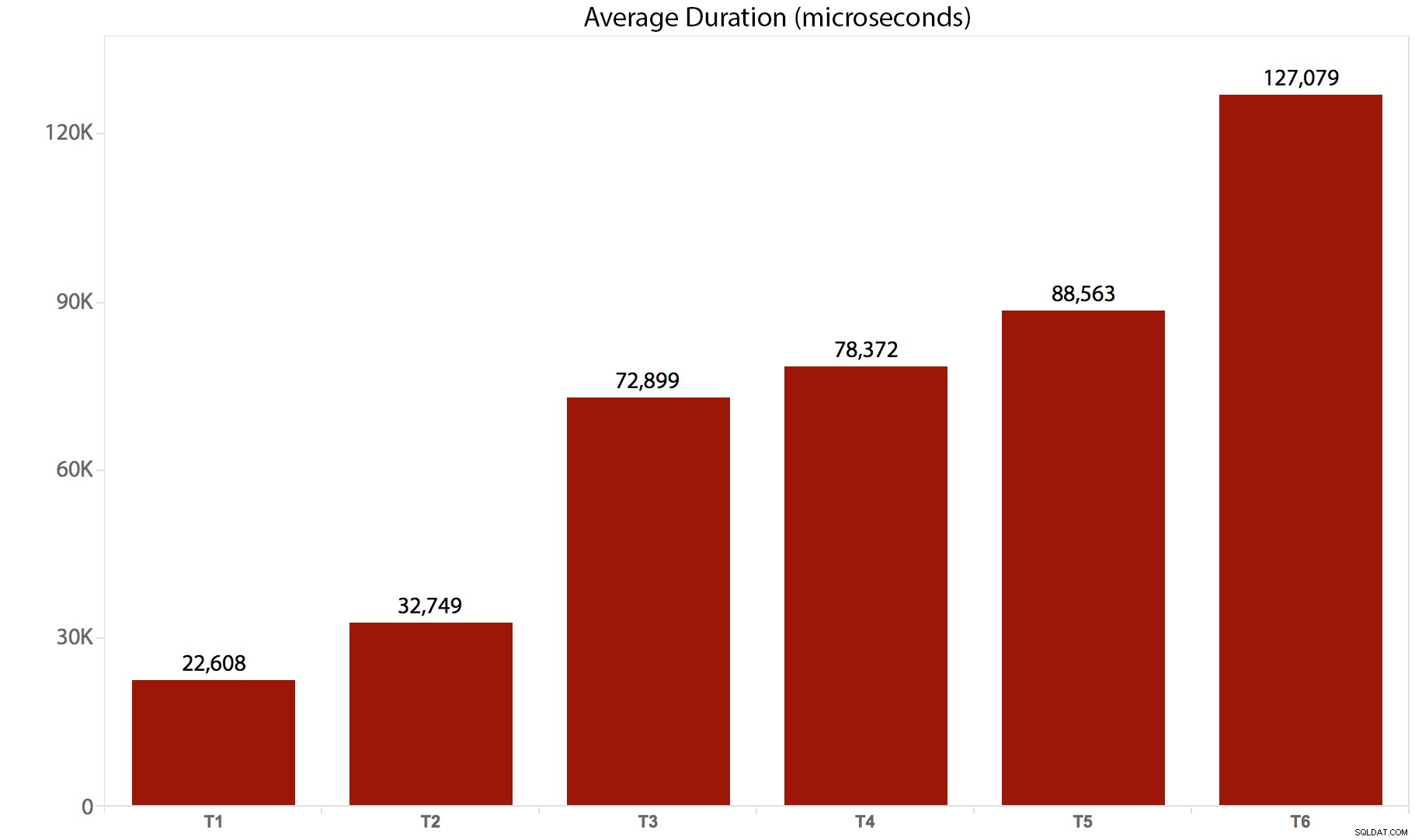
J'ai exécuté les tests 10 fois, recueilli les résultats et fait la moyenne de tout. Voici comment cela s'est produit :
| Test/Lot | Durée moyenne (microsecondes) | Nombre total de lectures (8 000 pages) |
|---|---|---|
| T1 :UPDATE /*réel*/ dbo.tr1 … | 22 608 | 205 134 |
| T2 :UPDATE /*réel*/ dbo.tr2 … | 32 749 | 11 331 628 |
| T3 :UPDATE /*réel*/ dbo.tr3 … | 72 899 | 22 838 308 |
| T4 :MISE À JOUR /*réel*/ dbo.tr4 … | 78 372 | 44 463 275 |
| T5 :MISE À JOUR /*réel*/ dbo.tr5 … | 88 563 | 41 514 778 |
| T6 :MISE À JOUR /*réel*/ dbo.tr6 … | 127 079 | 100 330 753 |
Et voici une représentation graphique de la durée :
Conclusion
Il est clair que, dans ce cas, il y a une surcharge substantielle pour chaque déclencheur invoqué - tous ces lots ont finalement affecté le même nombre de lignes, mais dans certains cas, les mêmes lignes ont été touchées plusieurs fois. J'effectuerai probablement d'autres tests de suivi pour mesurer la différence lorsque la même ligne n'est jamais touchée plus d'une fois - un schéma plus compliqué, peut-être, où 5 ou 10 autres tables doivent être touchées à chaque fois, et ces différentes déclarations pourraient être en un seul déclencheur ou en plusieurs. Je suppose que les différences de surcharge seront davantage dues à des éléments tels que la simultanéité et le nombre de lignes affectées que par la surcharge du déclencheur lui-même - mais nous verrons.
Vous voulez essayer la démo vous-même ? Téléchargez le script ici.