Dans mon article précédent, j'ai lancé une nouvelle série sur les verrous en expliquant ce qu'ils sont, pourquoi ils sont nécessaires et les mécanismes de leur fonctionnement, et je vous recommande fortement de lire cet article avant celui-ci. Dans cet article, je vais discuter du verrou FGCB_ADD_REMOVE et montrer comment cela peut être un goulot d'étranglement.
Qu'est-ce que le verrou FGCB_ADD_REMOVE ?
La plupart des noms de classes de verrous sont directement liés à la structure de données qu'ils protègent. Le verrou FGCB_ADD_REMOVE protège une structure de données appelée FGCB, ou File Group Control Block, et il y aura un de ces verrous pour chaque groupe de fichiers en ligne de chaque base de données en ligne dans une instance SQL Server. Chaque fois qu'un fichier dans un groupe de fichiers est ajouté, supprimé, agrandi ou réduit, le verrou doit être acquis en mode EX, et lors de la détermination du prochain fichier à allouer, le verrou doit être acquis en mode SH pour empêcher tout changement de groupe de fichiers. (N'oubliez pas que les allocations d'étendue pour un groupe de fichiers sont effectuées sur une base circulaire via les fichiers du groupe de fichiers et prennent également en compte le remplissage proportionnel , que j'explique ici.)
Comment le loquet devient-il un goulot d'étranglement ?
Le scénario le plus courant lorsque ce verrou devient un goulot d'étranglement est le suivant :
- Il existe une base de données à fichier unique, donc toutes les allocations doivent provenir de ce fichier de données
- Le paramètre de croissance automatique du fichier est défini sur très petit (rappelez-vous qu'avant SQL Server 2016, le paramètre de croissance automatique par défaut pour les fichiers de données était de 1 Mo !)
- De nombreuses opérations simultanées nécessitent l'allocation d'espace (par exemple, une charge de travail d'insertion constante à partir de nombreuses connexions client)
Dans ce cas, même s'il n'y a qu'un seul fichier, un thread nécessitant une allocation doit toujours acquérir le verrou FGCB_ADD_REMOVE en mode SH. Il essaiera ensuite d'allouer à partir du fichier de données unique, réalisera qu'il n'y a pas d'espace, puis acquiert le verrou en mode EX afin de pouvoir ensuite développer le fichier.
Imaginons que huit threads s'exécutant sur huit planificateurs distincts essaient tous d'allouer en même temps, et tous réalisent qu'il n'y a pas d'espace dans le fichier, ils doivent donc l'agrandir. Ils tenteront chacun d'acquérir le verrou en mode EX. Un seul d'entre eux pourra l'acquérir et il procédera à la croissance du fichier et les autres devront attendre, avec un type d'attente de LATCH_EX et une description de ressource de FGCB_ADD_REMOVE plus l'adresse mémoire du verrou.
Les sept threads en attente se trouvent dans la file d'attente premier entré, premier sorti (FIFO) du verrou. Lorsque le thread effectuant la croissance du fichier est terminé, il libère le verrou et l'accorde au premier thread en attente. Ce nouveau propriétaire du verrou va développer le fichier et découvre qu'il a déjà été développé et qu'il n'y a rien à faire. Ainsi, il libère le verrou et l'accorde au prochain thread en attente. Et ainsi de suite.
Les sept threads en attente ont tous attendu le verrou en mode EX mais ont fini par ne rien faire une fois qu'ils ont obtenu le verrou, de sorte que les sept threads ont essentiellement perdu du temps écoulé, le temps perdu augmentant un peu pour chaque thread le plus bas la file d'attente FIFO c'était.
Montrer le goulot d'étranglement
Maintenant, je vais vous montrer le scénario exact ci-dessus, en utilisant des événements étendus. J'ai créé une base de données à fichier unique avec un petit paramètre de croissance automatique et des centaines de connexions simultanées en insérant simplement des données dans une table.
Je peux utiliser la session d'événement prolongée suivante pour voir ce qui se passe :
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO La session effectue un suivi lorsqu'un thread entre dans la file d'attente du verrou, lorsqu'il quitte la file d'attente (c'est-à-dire lorsqu'il obtient le verrou) et lorsqu'une croissance du fichier de données se produit. L'utilisation du suivi de causalité signifie que nous pouvons voir une chronologie des actions de chaque thread.
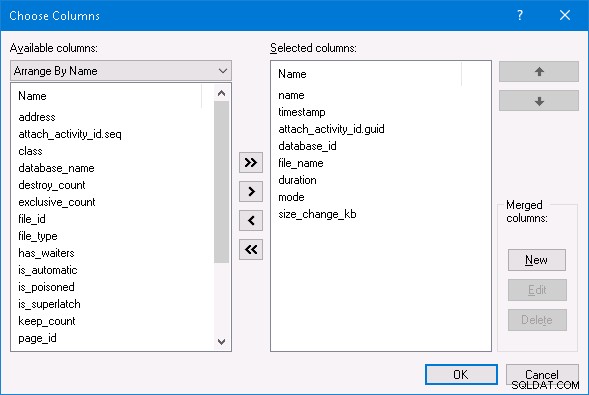
À l'aide de SQL Server Management Studio, je peux sélectionner l'option Watch Live Data pour la session d'événement étendue et voir toute l'activité de l'événement étendu. Si vous voulez faire la même chose, dans la fenêtre Live Data, faites un clic droit sur l'un des noms de colonne en haut et modifiez les colonnes sélectionnées comme ci-dessous :
J'ai laissé la charge de travail s'exécuter pendant quelques minutes pour atteindre un état stable, puis j'ai vu un exemple parfait du scénario que j'ai décrit ci-dessus :
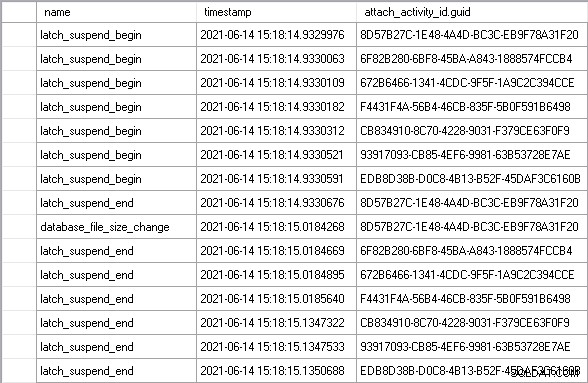
Utilisation de attach_activity_id.guid valeurs pour identifier différents threads, nous pouvons voir que sept threads commencent à attendre le verrou en 61,5 microsecondes. Le thread avec la valeur GUID commençant par 8D57 acquiert le verrou en mode EX (le latch_suspend_end event) puis agrandit immédiatement le fichier (le database_file_size_change un événement). Le thread 8D57 libère alors le verrou et l'accorde en mode EX au thread 6F82, qui a attendu 85 millisecondes. Cela n'a rien à voir donc il accorde le verrou au thread 672B. Et ainsi de suite, jusqu'à ce que le thread EDB8 obtienne le verrou, après avoir attendu 202 millisecondes.
Au total, les six threads qui ont attendu sans raison ont attendu presque 1 seconde. Une partie de ce temps est le temps d'attente du signal, où même si le thread a reçu le verrou, il doit encore remonter en haut de la file d'attente exécutable du planificateur avant de pouvoir accéder au processeur et exécuter du code. Vous pourriez dire que ce n'est pas une mesure juste du temps passé à attendre le verrou, mais c'est absolument le cas, car le temps d'attente du signal n'aurait pas été encouru si le thread n'avait pas dû attendre en premier lieu.
De plus, vous pourriez penser qu'un délai de 200 millisecondes n'est pas si important, mais tout dépend des accords de niveau de service de performance pour la charge de travail en question. Nous avons plusieurs clients à haut volume où si un lot prend plus de 200 millisecondes à s'exécuter, il n'est pas autorisé sur le système de production !
Résumé
Si vous surveillez les attentes sur votre serveur et que vous remarquez que LATCH_EX est l'une des principales attentes, vous pouvez utiliser le code de cet article pour voir si FGCB_ADD_REMOVE est l'un des coupables.
Le moyen le plus simple de vous assurer que votre charge de travail ne rencontre pas un goulot d'étranglement FGCB_ADD_REMOVE consiste à vous assurer qu'aucun paramètre de croissance automatique de fichier de données n'est configuré à l'aide des valeurs par défaut pré-SQL Server 2016. Dans les sys.master_files vue, la valeur par défaut de 1 Mo s'afficherait sous la forme d'un fichier de données (type_desc colonne définie sur ROWS) avec is_percent_growth colonne définie sur 0 et la colonne de croissance définie sur 128.
Donner une recommandation sur ce que devrait être la croissance automatique est une toute autre discussion, mais vous connaissez maintenant un impact potentiel sur les performances si vous ne modifiez pas les valeurs par défaut dans les versions antérieures.