Bien qu'elles s'accompagnent de nombreuses restrictions et d'importantes mises en garde d'implémentation, les vues indexées restent une fonctionnalité SQL Server très puissante lorsqu'elles sont correctement utilisées dans les bonnes circonstances. Une utilisation courante consiste à fournir une vue pré-agrégée des données sous-jacentes, permettant aux utilisateurs d'interroger directement les résultats sans encourir les coûts de traitement des jointures, filtres et agrégats sous-jacents à chaque exécution d'une requête.
Bien que les nouvelles fonctionnalités de l'édition Enterprise, telles que le stockage en colonnes et le traitement en mode batch, aient transformé les caractéristiques de performances de nombreuses requêtes volumineuses de ce type, il n'existe toujours pas de moyen plus rapide d'obtenir un résultat que d'éviter complètement tout le traitement sous-jacent, quelle que soit l'efficacité de ce traitement. aurait pu devenir.
Avant que les vues indexées (et leurs cousines plus limitées, les colonnes calculées) ne soient ajoutées au produit, les professionnels des bases de données écrivaient parfois du code complexe à plusieurs déclencheurs pour présenter les résultats d'une requête importante dans une vraie table. Ce type d'arrangement est notoirement difficile à obtenir en toutes circonstances, en particulier lorsque des modifications simultanées des données sous-jacentes sont fréquentes.
La fonction de vues indexées rend tout cela beaucoup plus facile, là où elle est appliquée de manière sensée et correcte. Le moteur de base de données prend en charge tout ce qui est nécessaire pour s'assurer que les données lues à partir d'une vue indexée correspondent à tout moment à la requête sous-jacente et aux données de la table.
Maintenance incrémentielle
SQL Server maintient les données de vue indexées synchronisées avec la requête sous-jacente en mettant automatiquement à jour les index de vue de manière appropriée chaque fois que les données changent dans les tables de base. Le coût de cette activité de maintenance est supporté par le processus de modification des données de base. Les opérations supplémentaires nécessaires pour maintenir les index de vue sont ajoutées silencieusement au plan d'exécution pour l'opération d'insertion, de mise à jour, de suppression ou de fusion d'origine. En arrière-plan, SQL Server s'occupe également de problèmes plus subtils concernant l'isolement des transactions, par exemple en garantissant une gestion correcte des transactions exécutées sous l'isolement d'instantané ou d'instantané validé en lecture.
Construire les opérations de plan d'exécution supplémentaires nécessaires pour maintenir correctement les index de vue n'est pas une mince affaire, comme le savent tous ceux qui ont tenté d'implémenter une "table récapitulative maintenue par le code de déclenchement". La complexité de la tâche est l'une des raisons pour lesquelles les vues indexées ont tant de restrictions. Limiter la surface prise en charge aux jointures internes, aux projections, aux sélections (filtres) et aux agrégats SUM et COUNT_BIG réduit considérablement la complexité de la mise en œuvre.
Les vues indexées sont maintenues incrémentiellement . Cela signifie que le processeur de requêtes détermine l'effet net des modifications de la table de base sur la vue et applique uniquement les modifications nécessaires pour mettre la vue à jour. Dans des cas simples, il peut calculer les deltas nécessaires uniquement à partir des modifications de la table de base et des données actuellement stockées dans la vue. Lorsque la définition de la vue contient des jointures, la partie de maintenance de la vue indexée du plan d'exécution devra également accéder aux tables jointes, mais cela peut généralement être effectué efficacement, étant donné les index de table de base appropriés.
Pour simplifier davantage l'implémentation, SQL Server utilise toujours la même forme de plan de base (comme point de départ) pour implémenter les opérations de maintenance des vues indexées. Les fonctionnalités normales fournies par l'optimiseur de requête sont utilisées pour simplifier et optimiser la forme de maintenance standard, le cas échéant. Nous allons maintenant passer à un exemple pour aider à rapprocher ces concepts.
Exemple 1 - Insertion d'une seule ligne
Supposons que nous ayons la table simple et la vue indexée suivantes :
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Une fois ce script exécuté, les données de l'exemple de table ressemblent à ceci :

Et la vue indexée contient :

L'exemple le plus simple d'un plan de maintenance de vue indexée pour cette configuration se produit lorsque nous ajoutons une seule ligne à la table de base :
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); Le plan d'exécution de cet encart est présenté ci-dessous :
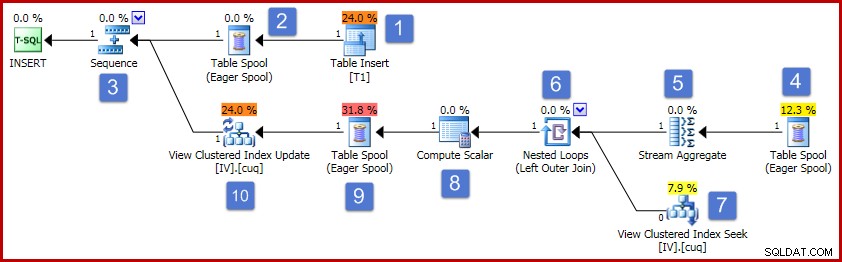
En suivant les chiffres du schéma, le fonctionnement de ce plan d'exécution se déroule comme suit :
- L'opérateur d'insertion de table ajoute la nouvelle ligne à la table de base. Il s'agit du seul opérateur de plan associé à l'insertion de la table de base ; tous les opérateurs restants sont concernés par la maintenance de la vue indexée.
- Eager Table Spool enregistre les données de ligne insérées dans un stockage temporaire.
- L'opérateur de séquence garantit que la branche supérieure du plan s'exécute jusqu'à la fin avant que la branche suivante de la séquence ne soit activée. Dans ce cas particulier (insertion d'une seule ligne), il serait valable de supprimer la Séquence (et les spools aux positions 2 et 4), en connectant directement l'entrée Stream Aggregate à la sortie de l'Insert Table. Cette optimisation possible n'est pas implémentée, donc la Séquence et les Spools restent.
- Ce spool de table Eager est associé au spool en position 2 (il a une propriété ID de nœud principal qui fournit ce lien explicitement). Le spool relit les lignes (une ligne dans le cas présent) à partir du même stockage temporaire écrit par le spool principal. Comme mentionné ci-dessus, les spools et les positions 2 et 4 sont inutiles, et apparaissent simplement parce qu'ils existent dans le modèle générique pour la maintenance des vues indexées.
- Le Stream Aggregate calcule la somme des données de la colonne Value dans l'ensemble inséré et compte le nombre de lignes présentes par groupe de clés d'affichage. La sortie correspond aux données incrémentielles nécessaires pour maintenir la vue synchronisée avec les données de base. Notez que le Stream Aggregate n'a pas d'élément Group By car l'optimiseur de requête sait qu'une seule valeur est en cours de traitement. Cependant, l'optimiseur n'applique pas une logique similaire pour remplacer les agrégats par des projections (la somme d'une seule valeur est simplement la valeur elle-même, et le nombre sera toujours un pour une insertion de ligne unique). Le calcul des agrégats de somme et de comptage pour une seule ligne de données n'est pas une opération coûteuse, donc cette optimisation manquée n'est pas vraiment préoccupante.
- La jointure associe chaque modification incrémentielle calculée à une clé existante dans la vue indexée. La jointure est une jointure externe, car les données nouvellement insérées peuvent ne correspondre à aucune donnée existante dans la vue.
- Cet opérateur localise la ligne à modifier dans la vue.
- Le Compute Scalar a deux responsabilités importantes. Tout d'abord, il détermine si chaque modification incrémentielle affectera une ligne existante dans la vue ou si une nouvelle ligne devra être créée. Pour ce faire, il vérifie si la jointure externe a produit une valeur nulle du côté vue de la jointure. Notre exemple d'encart est pour le groupe 3, qui n'existe pas actuellement dans la vue, donc une nouvelle ligne sera créée. La deuxième fonction du Compute Scalar est de calculer de nouvelles valeurs pour les colonnes de la vue. Si une nouvelle ligne doit être ajoutée à la vue, il s'agit simplement du résultat de la somme incrémentielle du Stream Aggregate. Si une ligne existante dans la vue doit être mise à jour, la nouvelle valeur est la valeur existante dans la ligne de la vue plus la somme incrémentielle du Stream Aggregate.
- Cette bobine de table Eager est destinée à la protection d'Halloween. Il est requis pour l'exactitude lorsqu'une opération d'insertion affecte une table qui est également référencée du côté de l'accès aux données de la requête. Elle n'est techniquement pas nécessaire si l'opération de maintenance sur une seule ligne entraîne la mise à jour d'une ligne de vue existante, mais elle reste quand même dans le plan.
- Le dernier opérateur du plan est étiqueté comme opérateur de mise à jour, mais il effectuera soit une insertion soit une mise à jour pour chaque ligne qu'il reçoit en fonction de la valeur de la colonne "code d'action" ajoutée par le scalaire de calcul au nœud 8 . Plus généralement, cet opérateur de mise à jour est capable d'insérer, de mettre à jour et de supprimer.
Il y a pas mal de détails ici, donc pour résumer :
- L'agrégat regroupe les modifications de données en fonction de la clé groupée unique de la vue. Il calcule l'effet net des modifications de la table de base sur chaque colonne par clé.
- La jointure externe connecte les modifications incrémentielles par clé aux lignes existantes dans la vue.
- Le scalaire de calcul calcule si une nouvelle ligne doit être ajoutée à la vue ou si une ligne existante doit être mise à jour. Il calcule les valeurs de colonne finales pour l'opération d'insertion ou de mise à jour de la vue.
- L'opérateur de mise à jour de la vue insère une nouvelle ligne ou met à jour une ligne existante comme indiqué par le code d'action.
Exemple 2 – Insertion sur plusieurs lignes
Croyez-le ou non, le plan d'exécution d'insertion de table de base à une seule ligne décrit ci-dessus a fait l'objet d'un certain nombre de simplifications. Bien que certaines optimisations supplémentaires possibles aient été manquées (comme indiqué), l'optimiseur de requête a quand même réussi à supprimer certaines opérations du modèle de maintenance de la vue indexée générale et à réduire la complexité des autres.
Plusieurs de ces optimisations ont été autorisées car nous n'insérions qu'une seule ligne, mais d'autres ont été activées car l'optimiseur a pu voir les valeurs littérales ajoutées à la table de base. Par exemple, l'optimiseur pourrait voir que la valeur de groupe insérée transmettrait le prédicat dans la clause WHERE de la vue.
Si nous insérons maintenant deux lignes, avec les valeurs "masquées" dans les variables locales, nous obtenons un plan un peu plus complexe :
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
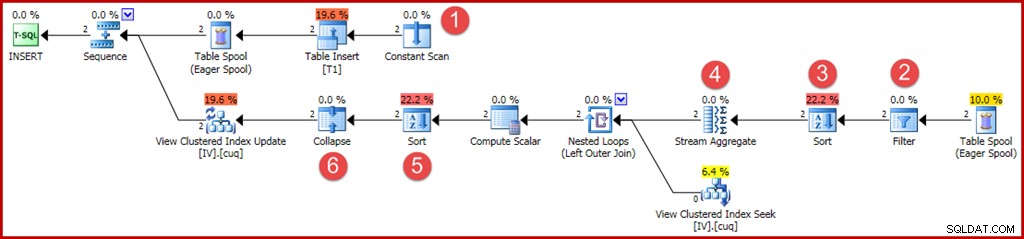
Les opérateurs nouveaux ou modifiés sont annotés comme avant :
- Le Constant Scan fournit les valeurs à insérer. Auparavant, une optimisation pour les insertions à une seule ligne permettait d'omettre cet opérateur.
- Un opérateur de filtre explicite est maintenant requis pour vérifier que les groupes insérés dans la table de base correspondent à la clause WHERE dans la vue. En l'occurrence, les deux nouvelles lignes réussiront le test, mais l'optimiseur ne peut pas voir les valeurs dans les variables pour le savoir à l'avance. De plus, il ne serait pas sûr de mettre en cache un plan qui a ignoré ce filtre car une future réutilisation du plan pourrait avoir des valeurs différentes dans les variables.
- Un tri est désormais requis pour s'assurer que les lignes arrivent au Stream Aggregate dans l'ordre du groupe. Le tri était précédemment supprimé car il est inutile de trier une seule ligne.
- Le Stream Aggregate a maintenant une propriété "group by", correspondant à la clé groupée unique de la vue.
- Ce tri est requis pour présenter les lignes dans l'ordre des codes d'action et des clés d'affichage, ce qui est nécessaire au bon fonctionnement de l'opérateur Collapse. Le tri est un opérateur entièrement bloquant, il n'est donc plus nécessaire d'utiliser une bobine de table Eager pour la protection d'Halloween.
- Le nouvel opérateur Collapse combine une insertion et une suppression adjacentes sur la même valeur de clé en une seule opération de mise à jour. Cet opérateur n'est pas réellement obligatoire dans ce cas, car aucun code d'action de suppression ne peut être généré (seulement insertions et mises à jour). Cela semble être un oubli, ou peut-être quelque chose laissé pour des raisons de sécurité. Les parties générées automatiquement d'un plan de requête de mise à jour peuvent devenir extrêmement complexes, il est donc difficile de le savoir avec certitude.
Les propriétés du filtre (dérivées de la clause WHERE de la vue) sont :
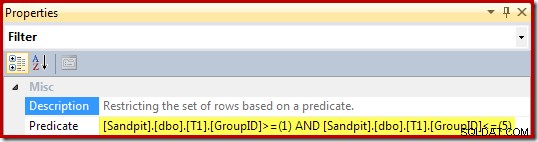
Le Stream Aggregate regroupe par la clé de vue et calcule la somme et le nombre d'agrégats par groupe :
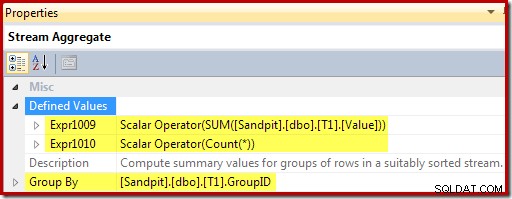
Le scalaire de calcul identifie l'action à effectuer par ligne (insérer ou mettre à jour dans ce cas) et calcule la valeur à insérer ou mettre à jour dans la vue :
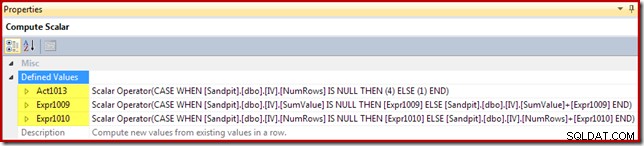
Le code d'action reçoit une étiquette d'expression [Act1xxx]. Les valeurs valides sont 1 pour une mise à jour, 3 pour une suppression et 4 pour une insertion. Cette expression d'action entraîne une insertion (code 4) si aucune ligne correspondante n'a été trouvée dans la vue (c'est-à-dire que la jointure externe a renvoyé une valeur nulle pour la colonne NumRows). Si une ligne correspondante a été trouvée, le code d'action est 1 (mise à jour).
Notez que NumRows est le nom donné à la colonne COUNT_BIG(*) requise dans la vue. Dans un plan qui pourrait entraîner des suppressions de la vue, le scalaire de calcul détecterait quand cette valeur deviendrait zéro (aucune ligne pour le groupe actuel) et générerait un code d'action de suppression (3).
Les expressions restantes conservent les agrégats de somme et de comptage dans la vue. Notez cependant que les étiquettes d'expression [Expr1009] et [Expr1010] ne sont pas nouvelles; ils font référence aux étiquettes créées par le Stream Aggregate. La logique est simple :si une ligne correspondante n'a pas été trouvée, la nouvelle valeur à insérer est simplement la valeur calculée au niveau de l'agrégat. Si une ligne correspondante dans la vue a été trouvée, la valeur mise à jour est la valeur actuelle de la ligne plus l'incrément calculé par l'agrégat.
Enfin, l'opérateur de mise à jour de la vue (affiché sous la forme d'une mise à jour de l'index clusterisé dans SSMS) affiche la référence de la colonne d'action ([Act1013] définie par le Compute Scalar) :
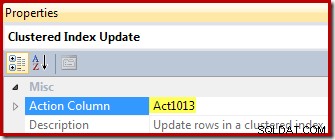
Exemple 3 – Mise à jour multi-lignes
Jusqu'à présent, nous n'avons examiné que les inserts de la table de base. Les plans d'exécution pour une suppression sont très similaires, avec seulement quelques différences mineures dans les calculs détaillés. Cet exemple suivant passe donc à l'examen du plan de maintenance pour une mise à jour de la table de base :
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Comme précédemment, cette requête utilise des variables pour masquer les valeurs littérales à l'optimiseur, empêchant l'application de certaines simplifications. Il est également prudent de mettre à jour deux groupes distincts, empêchant les optimisations qui peuvent être appliquées lorsque l'optimiseur sait qu'un seul groupe (une seule ligne de la vue indexée) sera affecté. Le plan d'exécution annoté pour la requête de mise à jour est ci-dessous :
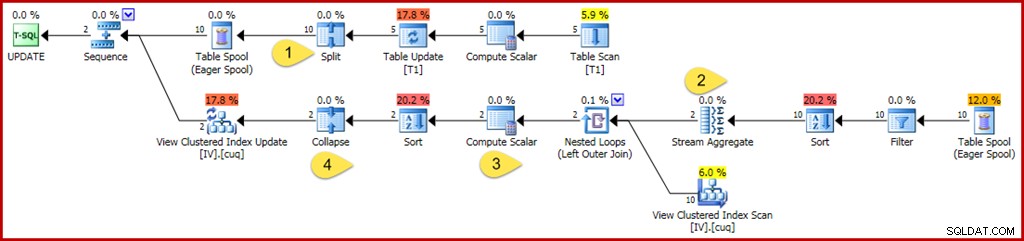
Les modifications et le point d'intérêt sont :
- Le nouvel opérateur Split transforme chaque mise à jour de ligne de la table de base en une opération de suppression et d'insertion distincte. Chaque ligne de mise à jour est divisée en deux lignes distinctes, ce qui double le nombre de lignes après ce point du plan. Split fait partie du modèle split-sort-collapse nécessaire pour se protéger contre les erreurs de violation de clé unique transitoires incorrectes.
- Le Stream Aggregate est modifié pour tenir compte des lignes entrantes qui peuvent spécifier une suppression ou une insertion (en raison du fractionnement et déterminé par une colonne de code d'action dans la ligne). Une ligne d'insertion contribue à la valeur d'origine dans les agrégats de somme ; le signe est inversé pour les lignes d'action de suppression. De même, l'agrégat du nombre de lignes compte ici les lignes d'insertion comme +1 et les lignes de suppression comme -1.
- La logique Compute Scalar est également modifiée pour refléter que l'effet net des modifications par groupe peut nécessiter une éventuelle action d'insertion, de mise à jour ou de suppression sur la vue matérialisée. Il n'est pas réellement possible que cette requête de mise à jour particulière entraîne l'insertion ou la suppression d'une ligne dans cette vue, mais la logique requise pour en déduire cela dépasse les capacités de raisonnement actuelles de l'optimiseur. Une requête de mise à jour ou une définition de vue légèrement différente peut en effet entraîner un mélange d'actions d'insertion, de suppression et de mise à jour de la vue.
- L'opérateur Collapse est mis en évidence uniquement pour son rôle dans le modèle split-sort-collapse mentionné ci-dessus. Notez qu'il ne fait que réduire les suppressions et les insertions sur la même clé ; des suppressions et des insertions sans correspondance après l'effondrement sont parfaitement possibles (et assez courantes).
Comme précédemment, les propriétés de l'opérateur clé à examiner pour comprendre le travail de maintenance de la vue indexée sont le filtre, l'agrégat de flux, la jointure externe et le scalaire de calcul.
Exemple 4 - Mise à jour multi-lignes avec jointures
Pour compléter l'aperçu des plans d'exécution de maintenance des vues indexées, nous aurons besoin d'un nouvel exemple de vue qui joint plusieurs tables ensemble et inclut une projection dans la liste de sélection :
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); Pour garantir l'exactitude, l'une des exigences de la vue indexée est qu'un agrégat de somme ne peut pas fonctionner sur une expression susceptible d'avoir la valeur null. La définition de vue ci-dessus utilise ISNULL pour répondre à cette exigence. Un exemple de requête de mise à jour qui produit un composant de plan de maintenance d'index assez complet est présenté ci-dessous, ainsi que le plan d'exécution qu'il produit :
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
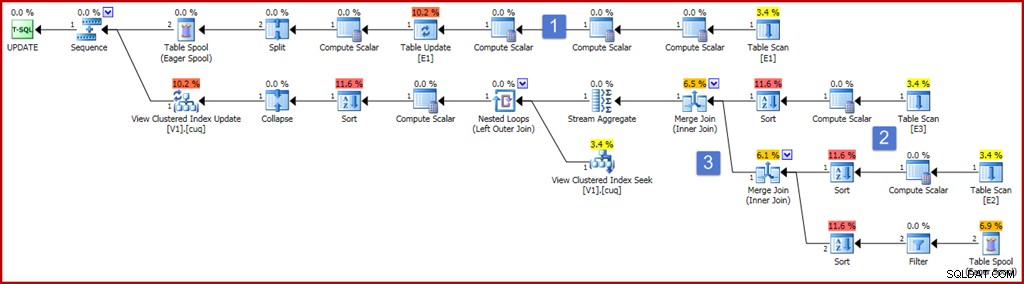
Le plan semble assez volumineux et compliqué maintenant, mais la plupart des éléments sont exactement comme nous l'avons déjà vu. Les principales différences sont :
- La branche supérieure du plan comprend un certain nombre d'opérateurs Compute Scalar supplémentaires. Celles-ci pourraient être organisées de manière plus compacte, mais elles sont essentiellement présentes pour capturer les valeurs de pré-mise à jour des colonnes non groupées. Le scalaire de calcul à gauche de la mise à jour de la table capture la valeur post-mise à jour de la colonne "a", avec la projection ISNULL appliquée.
- Les nouveaux scalaires de calcul dans cette zone du plan calculent la valeur produite par l'expression ISNULL sur chaque table source. En général, les projections sur les tables jointes dans la vue seront représentées ici par des scalaires de calcul. Les tris dans cette zone du plan sont présents uniquement parce que l'optimiseur a choisi une stratégie de jointure par fusion pour des raisons de coût (rappelez-vous que la fusion nécessite une entrée triée par clé de jointure).
- Les deux opérateurs de jointure sont nouveaux et implémentent simplement les jointures dans la définition de la vue. Ces jointures apparaissent toujours avant le Stream Aggregate qui calcule l'effet incrémentiel des modifications sur la vue. Notez qu'une modification apportée à une table de base peut avoir pour conséquence qu'une ligne qui répondait aux critères de jointure ne se joint plus, et vice versa. Toutes ces complexités potentielles sont gérées correctement (compte tenu des restrictions de vues indexées) par le Stream Aggregate qui produit un résumé des modifications par clé de vue une fois les jointures effectuées.
Réflexions finales
Ce dernier plan représente à peu près le modèle complet de gestion d'une vue indexée, bien que l'ajout d'index non clusterisés à la vue ajouterait également des opérateurs supplémentaires spoolés à partir de la sortie de l'opérateur de mise à jour de la vue. Mis à part un fractionnement supplémentaire (et une combinaison de tri et de réduction si l'index non clusterisé de la vue est unique), il n'y a rien de très spécial dans cette possibilité. L'ajout d'une clause de sortie à la requête de la table de base peut également produire des opérateurs supplémentaires intéressants, mais encore une fois, ceux-ci ne sont pas particuliers à la maintenance des vues indexées en soi.
Pour résumer la stratégie globale complète :
- Les modifications de la table de base sont appliquées normalement ; les valeurs de pré-mise à jour peuvent être capturées.
- Un opérateur de fractionnement peut être utilisé pour transformer les mises à jour en paires supprimer/insérer.
- Un spool impatient enregistre les informations de modification de la table de base dans un stockage temporaire.
- Toutes les tables de la vue sont accessibles, à l'exception de la table de base mise à jour (qui est lue à partir du spool).
- Les projections dans la vue sont représentées par des scalaires de calcul.
- Les filtres de la vue sont appliqués. Les filtres peuvent être poussés dans les balayages ou les recherches en tant que résidus.
- Les jointures spécifiées dans la vue sont exécutées.
- Un agrégat calcule les modifications incrémentielles nettes regroupées par clé de vue en cluster.
- L'ensemble de modifications incrémentielles est joint à l'extérieur de la vue.
- Un scalaire de calcul calcule un code d'action (insérer/mettre à jour/supprimer par rapport à la vue) pour chaque modification et calcule les valeurs réelles à insérer ou à mettre à jour. La logique de calcul est basée sur la sortie de l'agrégat et le résultat de la jointure externe à la vue.
- Les modifications sont triées par ordre de clé de vue et de code d'action, et réduites aux mises à jour, le cas échéant.
- Enfin, les modifications incrémentielles sont appliquées à la vue elle-même.
Comme nous l'avons vu, l'ensemble normal d'outils disponibles pour l'optimiseur de requête est toujours appliqué aux parties générées automatiquement du plan, ce qui signifie qu'une ou plusieurs des étapes ci-dessus peuvent être simplifiées, transformées ou supprimées entièrement. Cependant, la forme de base et le fonctionnement du plan restent intacts.
Si vous avez suivi les exemples de code, vous pouvez utiliser le script suivant pour nettoyer :
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;