Dans un monde parfait, peu importe la syntaxe T-SQL particulière que nous avons choisie pour exprimer une requête. Toute construction sémantiquement identique conduirait à exactement le même plan d'exécution physique, avec exactement les mêmes performances.
Pour y parvenir, l'optimiseur de requêtes SQL Server aurait besoin de connaître toutes les équivalences logiques possibles (en supposant que nous puissions les connaître toutes) et de disposer du temps et des ressources nécessaires pour explorer toutes les options. Étant donné le nombre énorme de façons possibles d'exprimer la même exigence dans T-SQL et le grand nombre de transformations possibles, les combinaisons deviennent rapidement ingérables pour tous les cas, sauf les plus simples.
Un "monde parfait" avec une indépendance totale de la syntaxe peut ne pas sembler aussi parfait aux utilisateurs qui doivent attendre des jours, des semaines, voire des années pour qu'une requête modestement complexe soit compilée. L'optimiseur de requêtes fait donc des compromis :il explore certaines équivalences courantes et s'efforce d'éviter de consacrer plus de temps à la compilation et à l'optimisation qu'il n'en gagne en temps d'exécution. Son objectif peut se résumer à essayer de trouver un plan d'exécution raisonnable dans un délai raisonnable, tout en consommant des ressources raisonnables.
L'une des conséquences de tout cela est que les plans d'exécution sont souvent sensibles à la forme écrite de la requête. L'optimiseur a une certaine logique pour transformer rapidement certaines constructions équivalentes largement utilisées en une forme commune, mais ces capacités ne sont ni bien documentées ni (tout près) complètes.
Nous pouvons certainement maximiser nos chances d'obtenir un bon plan d'exécution en écrivant des requêtes plus simples, en fournissant des index utiles, en maintenant de bonnes statistiques et en nous limitant à des concepts plus relationnels (par exemple en évitant les curseurs, les boucles explicites et les fonctions non en ligne), mais c'est pas une solution complète. Il n'est pas non plus possible de dire qu'une construction T-SQL sera toujours produire un meilleur plan d'exécution qu'une alternative sémantiquement identique.
Mon conseil habituel est de commencer par le formulaire de requête relationnelle le plus simple qui répond à vos besoins, en utilisant la syntaxe T-SQL que vous jugez préférable. Si la requête ne répond pas aux exigences après l'optimisation physique (par exemple, l'indexation), il peut être utile d'essayer d'exprimer la requête d'une manière légèrement différente, tout en conservant la sémantique d'origine. C'est la partie délicate. Quelle partie de la requête devriez-vous essayer de réécrire ? Quelle réécriture devriez-vous essayer ? Il n'y a pas de réponse simple et unique à ces questions. Certaines d'entre elles dépendent de l'expérience, bien que connaître un peu l'optimisation des requêtes et les composants internes du moteur d'exécution puisse également être un guide utile.
Exemple
Cet exemple utilise la table AdventureWorks TransactionHistory. Le script ci-dessous fait une copie de la table et crée un index clusterisé et non clusterisé. Nous ne modifierons aucunement les données ; cette étape sert juste à clarifier l'indexation (et à donner un nom plus court à la table) :
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
La tâche consiste à produire une liste d'ID de produit et d'historique pour six produits particuliers. Une façon d'exprimer la requête est :
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Cette requête renvoie 764 lignes à l'aide du plan d'exécution suivant (affiché dans SentryOne Plan Explorer) :

Cette requête simple se qualifie pour la compilation de plans TRIVIAL. Le plan d'exécution comporte six opérations de recherche d'index distinctes en une :
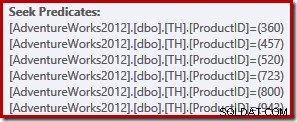
Les lecteurs aux yeux d'aigle auront remarqué que les six recherches sont répertoriées en ascendant l'ordre des ID de produit, et non dans l'ordre (arbitraire) spécifié dans la liste IN de la requête d'origine. En effet, si vous exécutez vous-même la requête, vous observerez très probablement les résultats renvoyés dans l'ordre croissant des ID de produit. La requête n'est pas garantie pour renvoyer les résultats dans cet ordre bien sûr, car nous n'avons pas spécifié de clause ORDER BY de niveau supérieur. On peut cependant ajouter une telle clause ORDER BY, sans changer le plan d'exécution produit dans ce cas :
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Je ne répéterai pas le graphique du plan d'exécution, car il est exactement le même :la requête se qualifie toujours pour un plan trivial, les opérations de recherche sont exactement les mêmes et les deux plans ont exactement le même coût estimé. L'ajout de la clause ORDER BY ne nous a précisément rien coûté, mais nous a permis de garantir l'ordre des résultats.
Nous avons maintenant la garantie que les résultats seront renvoyés dans l'ordre des ID de produit, mais notre requête ne précise pas actuellement comment les lignes avec le same ID de produit sera commandé. En regardant les résultats, vous remarquerez peut-être que les lignes pour le même ID de produit semblent être triées par ID de transaction, en ordre croissant.
Sans un ORDER BY explicite, il ne s'agit que d'une autre observation (c'est-à-dire que nous ne pouvons pas nous fier à cet ordre), mais nous pouvons modifier la requête pour nous assurer que les lignes sont triées par ID de transaction dans chaque ID de produit :
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Encore une fois, le plan d'exécution de cette requête est exactement le même qu'avant; le même plan trivial avec le même coût estimé est produit. La différence est que les résultats sont maintenant garantis à commander d'abord par ID de produit, puis par ID de transaction.
Certaines personnes pourraient être tentées de conclure que les deux requêtes précédentes renverraient également toujours des lignes dans cet ordre, car les plans d'exécution sont les mêmes. Ce n'est pas une implication sûre, car tous les détails du moteur d'exécution ne sont pas exposés dans les plans d'exécution (même sous la forme XML). Sans une clause order by explicite, SQL Server est libre de renvoyer les lignes dans n'importe quel ordre, même si le plan nous semble identique (il pourrait, par exemple, effectuer les recherches dans l'ordre spécifié dans le texte de la requête). Le fait est que l'optimiseur de requête connaît et peut appliquer certains comportements au sein du moteur qui ne sont pas visibles pour les utilisateurs.
Au cas où vous vous demanderiez comment notre index non clusterisé non unique sur Product ID peut renvoyer des lignes dans Product et Dans l'ordre de l'ID de transaction, la réponse est que la clé d'index non clusterisée incorpore l'ID de transaction (l'unique clé d'index clusterisée). En fait, le physique la structure de notre index non clusterisé est exactement le même, à tous les niveaux, comme si on avait créé l'index avec la définition suivante :
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Nous pouvons même écrire la requête avec un DISTINCT ou GROUP BY explicite et toujours obtenir exactement le même plan d'exécution :
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Pour être clair, cela ne nécessite en aucun cas de modifier l'index non cluster d'origine. Comme dernier exemple, notez que nous pouvons également demander des résultats par ordre décroissant :
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
Les propriétés du plan d'exécution indiquent maintenant que l'index est parcouru en arrière :

En dehors de cela, le plan est le même :il a été produit à l'étape d'optimisation du plan trivial et a toujours le même coût estimé.
Réécrire la requête
Il n'y a rien de mal avec la requête ou le plan d'exécution précédent, mais nous aurions peut-être choisi d'exprimer la requête différemment :
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Il est clair que ce formulaire spécifie exactement les mêmes résultats que l'original, et en effet la nouvelle requête produit le même plan d'exécution (plan trivial, recherche multiple en un, même coût estimé). Le formulaire OR indique peut-être un peu plus clairement que le résultat est une combinaison des résultats pour les six ID de produit individuels, ce qui pourrait nous amener à essayer une autre variante qui rend cette idée encore plus explicite :
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
Le plan d'exécution de la requête UNION ALL est assez différent :
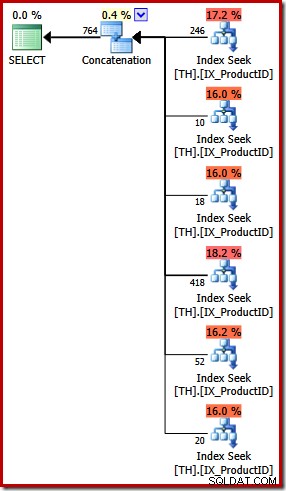
Mis à part les différences visuelles évidentes, ce plan nécessitait une optimisation basée sur les coûts (FULL) (il ne se qualifiait pas pour un plan trivial), et le coût estimé est (relativement parlant) un peu plus élevé, autour de 0,02 unités contre environ 0,005 unités avant.
Cela nous ramène à mes remarques d'ouverture :l'optimiseur de requêtes ne connaît pas toutes les équivalences logiques et ne peut pas toujours reconnaître les requêtes alternatives comme spécifiant les mêmes résultats. Ce que je veux dire à ce stade, c'est que l'expression de cette requête particulière en utilisant UNION ALL plutôt que IN a entraîné un plan d'exécution moins optimal.
Deuxième exemple
Cet exemple choisit un ensemble différent de six ID de produit et demande les résultats dans l'ordre des ID de transaction :
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Notre index non clusterisé ne peut pas fournir de lignes dans l'ordre demandé, donc l'optimiseur de requête a le choix entre rechercher sur l'index non clusterisé et trier, ou scanner l'index clusterisé (qui est indexé sur l'ID de transaction uniquement) et appliquer les prédicats d'ID de produit comme un résiduel. Il se trouve que les ID de produit répertoriés ont une sélectivité inférieure à celle de l'ensemble précédent, de sorte que l'optimiseur choisit une analyse d'index groupée dans ce cas :
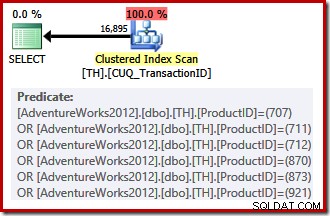
Parce qu'il y a un choix basé sur les coûts à faire, ce plan d'exécution n'était pas admissible à un plan trivial. Le coût estimé du plan final est d'environ 0,714 unités. L'analyse de l'index clusterisé nécessite 797 lectures logiques au moment de l'exécution.
Peut-être étant surpris que la requête n'utilise pas l'index produit, nous pourrions essayer de forcer une recherche de l'index non clusterisé en utilisant un indice d'index, ou en spécifiant FORCESEEK :
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
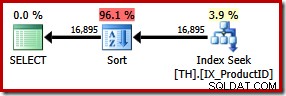
Cela se traduit par un tri explicite par ID de transaction. On estime que le nouveau tri représente 96 % du nouveau plan 1,15 coût unitaire. Ce coût estimé plus élevé explique pourquoi l'optimiseur a choisi l'analyse d'index cluster apparemment moins chère lorsqu'il est laissé à lui-même. Le coût d'E/S de la nouvelle requête est cependant inférieur :lorsqu'elle est exécutée, la recherche d'index ne consomme que 49 lectures logiques (au lieu de 797).
Nous aurions également pu choisir d'exprimer cette requête en utilisant (l'idée précédemment infructueuse) UNION ALL :
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Le produit le plan d'exécution suivant (cliquez sur l'image pour l'agrandir dans une nouvelle fenêtre) :

Ce plan peut sembler plus complexe, mais son coût est estimé à seulement 0,099 unités, ce qui est bien inférieur à l'analyse de l'index clusterisé (0,714 unités) ou rechercher plus trier (1.15 unités). De plus, le nouveau plan ne consomme que 49 lectures logiques au moment de l'exécution - identiques au plan de recherche + tri, et bien inférieures aux 797 nécessaires pour l'analyse de l'index clusterisé.
Cette fois, l'expression de la requête à l'aide de UNION ALL a produit un bien meilleur plan, à la fois en termes de coût estimé et de lectures logiques. L'ensemble de données source est un peu trop petit pour faire une comparaison vraiment significative entre les durées des requêtes ou l'utilisation du processeur, mais l'analyse de l'index clusterisé prend deux fois plus de temps (26 ms) que les deux autres sur mon système.
Le tri supplémentaire dans le plan suggéré est probablement inoffensif dans cet exemple simple car il est peu probable qu'il se répande sur le disque, mais de nombreuses personnes préféreront de toute façon le plan UNION ALL car il est non bloquant, évite une allocation de mémoire et ne nécessite pas de indice de requête.
Conclusion
Nous avons vu que la syntaxe des requêtes peut affecter le plan d'exécution choisi par l'optimiseur, même si les requêtes spécifient logiquement exactement le même ensemble de résultats. La même réécriture (par exemple UNION ALL) entraînera parfois une amélioration et parfois la sélection d'un plan moins bon.
Réécrire les requêtes et essayer une autre syntaxe est une technique de réglage valide, mais il faut faire attention. L'un des risques est que les modifications futures du produit pourraient entraîner l'arrêt soudain de la production du meilleur plan par le formulaire de requête différent, mais on pourrait dire que c'est toujours un risque et qu'il est atténué par des tests préalables à la mise à niveau ou l'utilisation de guides de plan.
Il y a aussi un risque de se laisser emporter par cette technique :l'utilisation de constructions de requêtes "étranges" ou "inhabituelles" pour obtenir un plan plus performant est souvent le signe qu'une ligne a été franchie. L'endroit exact où se situe la distinction entre une syntaxe alternative valide et "inhabituel/bizarre" est probablement assez subjectif ; mon guide personnel est de travailler avec des formulaires de requête relationnels équivalents et de garder les choses aussi simples que possible.