Vous avez tous entendu parler de la mise à l'échelle :votre architecture doit être évolutive, vous devez pouvoir évoluer pour répondre à la demande, etc. Qu'est-ce que cela veut dire quand on parle de bases de données ? À quoi ressemble la mise à l'échelle dans les coulisses ? Ce sujet est vaste et il est impossible d'en couvrir tous les aspects. Cette série de deux articles de blog tente de vous donner un aperçu du sujet de l'évolutivité des bases de données.
Pourquoi évoluons-nous ?
Tout d'abord, examinons ce qu'est l'évolutivité. En bref, nous parlons de la capacité à gérer une charge plus élevée par vos systèmes de base de données. Il peut s'agir de gérer des pics d'activité de courte durée, il peut s'agir de gérer une charge de travail progressivement accrue dans votre environnement de base de données. Il peut y avoir de nombreuses raisons d'envisager une mise à l'échelle. La plupart d'entre eux viennent avec leurs propres défis. Nous pouvons passer un peu de temps à passer en revue des exemples de situations dans lesquelles nous pourrions vouloir évoluer.
Augmentation de la consommation de ressources
C'est le plus générique - votre charge a augmenté au point où vos ressources existantes ne sont plus capables de la gérer. Cela peut être n'importe quoi. La charge du processeur a augmenté et votre cluster de base de données n'est plus en mesure de fournir des données avec un temps d'exécution de requête raisonnable et stable. L'utilisation de la mémoire a augmenté à un point tel que la base de données n'est plus liée au processeur mais est devenue liée aux E/S et, par conséquent, les performances des nœuds de la base de données ont été considérablement réduites. Le réseau peut également être un goulot d'étranglement. Vous serez peut-être surpris de voir quelles limites liées à la mise en réseau sont attribuées à vos instances cloud. En fait, cela peut devenir la limite la plus courante à laquelle vous devez faire face car le réseau est tout dans le cloud - pas seulement les données envoyées entre l'application et la base de données, mais aussi le stockage est attaché sur le réseau. Il peut également s'agir de l'utilisation du disque - vous manquez simplement d'espace disque ou, plus probablement, étant donné que nous pouvons avoir des disques assez volumineux de nos jours, la taille de la base de données a dépassé la taille "gérable". La maintenance comme le changement de schéma devient un défi, les performances sont réduites en raison de la taille des données, les sauvegardes prennent du temps à se terminer. Tous ces cas peuvent être un cas valable pour un besoin de mise à l'échelle.
Augmentation soudaine de la charge de travail
Un autre cas où une mise à l'échelle est nécessaire est une augmentation soudaine de la charge de travail. Pour une raison quelconque (qu'il s'agisse d'efforts de marketing, de contenu viral, d'urgence ou de situation similaire), votre infrastructure subit une augmentation significative de la charge sur le cluster de bases de données. La charge du processeur dépasse le plafond, les E/S de disque ralentissent les requêtes, etc. Pratiquement toutes les ressources que nous avons mentionnées dans la section précédente peuvent être surchargées et commencer à causer des problèmes.
Opération prévue
La troisième raison que nous voudrions souligner est la plus générique - une sorte d'opération planifiée. Il peut s'agir d'une activité marketing planifiée dont vous vous attendez à générer plus de trafic, le Black Friday, des tests de charge ou à peu près tout ce que vous savez à l'avance.
Chacune de ces raisons a ses propres caractéristiques. Si vous pouvez planifier à l'avance, vous pouvez préparer le processus en détail, le tester et l'exécuter quand vous en avez envie. Vous aimerez très probablement le faire dans une période de "faible trafic", tant que quelque chose comme ça existe dans vos charges de travail (cela n'est pas obligé d'exister). D'un autre côté, des pics soudains de charge, surtout s'ils sont suffisamment importants pour avoir un impact sur la production, forceront une réaction immédiate, peu importe à quel point vous êtes préparé et à quel point c'est sûr - si vos services sont déjà impactés, vous pouvez tout aussi bien allez-y au lieu d'attendre.
Types de mise à l'échelle de la base de données
Il existe deux principaux types de mise à l'échelle :verticale et horizontale. Les deux ont des avantages et des inconvénients, les deux sont utiles dans des situations différentes. Examinons-les et discutons des cas d'utilisation pour les deux scénarios.
Échelle verticale
Cette méthode de mise à l'échelle est probablement la plus ancienne :si votre matériel n'est pas assez puissant pour faire face à la charge de travail, renforcez-le. Nous parlons ici simplement d'ajouter des ressources aux nœuds existants dans le but de les rendre suffisamment capables de gérer les tâches données. Cela a des répercussions que nous aimerions aborder.
Avantages de la mise à l'échelle verticale
Le plus important est que tout reste le même. Vous aviez trois nœuds dans un cluster de base de données, vous avez toujours trois nœuds, juste plus capables. Il n'est pas nécessaire de reconcevoir votre environnement, de modifier la façon dont l'application doit accéder à la base de données - tout reste exactement le même car, en termes de configuration, rien n'a vraiment changé.
Un autre avantage important de la mise à l'échelle verticale est qu'elle peut être très rapide, en particulier dans les environnements cloud. L'ensemble du processus consiste, à peu près, à arrêter le nœud existant, à modifier le matériel, à redémarrer le nœud. Pour les configurations classiques sur site, sans aucune virtualisation, cela peut être délicat - vous n'avez peut-être pas de CPU plus rapides disponibles pour échanger, la mise à niveau des disques vers des disques plus grands ou plus rapides peut également prendre du temps, mais pour les environnements cloud, qu'ils soient publics ou privés, cela peut être aussi simple que d'exécuter trois commandes :arrêter l'instance, mettre à niveau l'instance vers une taille plus grande, démarrer l'instance. Les adresses IP virtuelles et les volumes réattachables facilitent le déplacement des données entre les instances.
Inconvénients de la mise à l'échelle verticale
Le principal inconvénient de la mise à l'échelle verticale est que, tout simplement, elle a ses limites. Si vous utilisez la plus grande taille d'instance disponible, avec les volumes de disque les plus rapides, vous ne pouvez pas faire grand-chose d'autre. Il n'est pas non plus si facile d'augmenter considérablement les performances de votre cluster de bases de données. Cela dépend principalement de la taille de l'instance initiale, mais si vous exécutez déjà des nœuds assez performants, vous ne pourrez peut-être pas atteindre un scale-out 10x en utilisant la mise à l'échelle verticale. Les nœuds qui seraient 10 fois plus rapides peuvent tout simplement ne pas exister.
Mise à l'échelle horizontale
La mise à l'échelle horizontale est une bête différente. Au lieu d'augmenter avec la taille de l'instance, nous restons au même niveau mais nous nous développons horizontalement en ajoutant plus de nœuds. Encore une fois, il y a des avantages et des inconvénients à cette méthode.
Avantages de la mise à l'échelle horizontale
Le principal avantage de la mise à l'échelle horizontale est que, théoriquement, le ciel est la limite. Il n'y a pas de limite rigide artificielle de scale-out, même si des limites existent, principalement en raison de la communication intra-cluster de plus en plus importante avec chaque nouveau nœud ajouté au cluster.
Un autre avantage important serait que vous pouvez faire évoluer le cluster sans avoir besoin de temps d'arrêt. Si vous souhaitez mettre à niveau le matériel, vous devez arrêter l'instance, la mettre à niveau, puis redémarrer. Si vous souhaitez ajouter plus de nœuds au cluster, il vous suffit de provisionner ces nœuds, d'installer le logiciel dont vous avez besoin, y compris la base de données, et de le laisser rejoindre le cluster. Facultativement (selon que le cluster dispose de méthodes internes pour provisionner de nouveaux nœuds avec les données), vous devrez peut-être le provisionner avec des données par vous-même. Cependant, il s'agit généralement d'un processus automatisé.
Inconvénients de la mise à l'échelle horizontale
Le principal problème auquel vous devez faire face est que l'ajout de plus en plus de nœuds rend difficile la gestion de l'ensemble de l'environnement. Vous devez être en mesure de dire quels nœuds sont disponibles, une telle liste doit être maintenue et mise à jour à chaque nouveau nœud créé. Vous pouvez avoir besoin de solutions externes comme le service d'annuaire (Consul ou Etcd) pour garder la trace des nœuds et de leur état. Cela augmente évidemment la complexité de l'ensemble de l'environnement.
Un autre problème potentiel est que le processus de scale-out prend du temps. Ajouter de nouveaux nœuds et les provisionner avec des logiciels et, surtout, des données demande du temps. Combien, cela dépend du matériel (principalement des E/S et du débit du réseau) et de la taille des données. Pour les grandes configurations, cela peut prendre beaucoup de temps et cela peut être un obstacle pour les situations où la mise à l'échelle doit se produire immédiatement. Attendre des heures pour ajouter de nouveaux nœuds peut ne pas être acceptable si le cluster de base de données est affecté au point que les opérations ne sont pas effectuées correctement.
Prérequis de mise à l'échelle
Réplication des données
Avant toute tentative de mise à l'échelle, votre environnement doit répondre à quelques exigences. Pour commencer, votre application doit pouvoir tirer parti de plusieurs nœuds. S'il ne peut utiliser qu'un seul nœud, vos options sont à peu près limitées à la mise à l'échelle verticale. Vous pouvez augmenter la taille de ce nœud ou ajouter des ressources matérielles au serveur bare metal et le rendre plus performant, mais c'est le mieux que vous puissiez faire :vous serez toujours limité par la disponibilité de matériel plus performant et, éventuellement, vous trouverez vous-même sans possibilité d'évoluer davantage.
D'autre part, si vous avez les moyens d'utiliser plusieurs nœuds de base de données par votre application, vous pouvez bénéficier d'une mise à l'échelle horizontale. Arrêtons-nous ici et discutons de ce dont vous avez besoin pour utiliser plusieurs nœuds à leur plein potentiel.
Pour commencer, la possibilité de séparer les lectures des écritures. Traditionnellement, l'application se connecte à un seul nœud. Ce nœud est utilisé pour gérer toutes les écritures et toutes les lectures exécutées par l'application.

L'ajout d'un deuxième nœud au cluster, du point de vue de la mise à l'échelle, ne change rien . Vous devez garder à l'esprit qu'en cas de défaillance d'un nœud, l'autre devra gérer le trafic, de sorte qu'à aucun moment la somme de la charge sur les deux nœuds ne doit être trop élevée pour qu'un seul nœud puisse la gérer.

Avec trois nœuds disponibles, vous pouvez utiliser pleinement deux nœuds. Cela nous permet de faire évoluer une partie du trafic de lecture :si un nœud a une capacité de 100 % (et nous préférerions fonctionner au maximum à 70 %), alors deux nœuds représentent 200 %. Trois nœuds :300 %. Si un nœud est en panne et si nous poussons les nœuds restants presque à la limite, nous pouvons dire que nous sommes capables de travailler avec 170 à 180 % de la capacité d'un seul nœud si le cluster est dégradé. Cela nous donne une belle charge de 60 % sur chaque nœud si les trois nœuds sont disponibles.
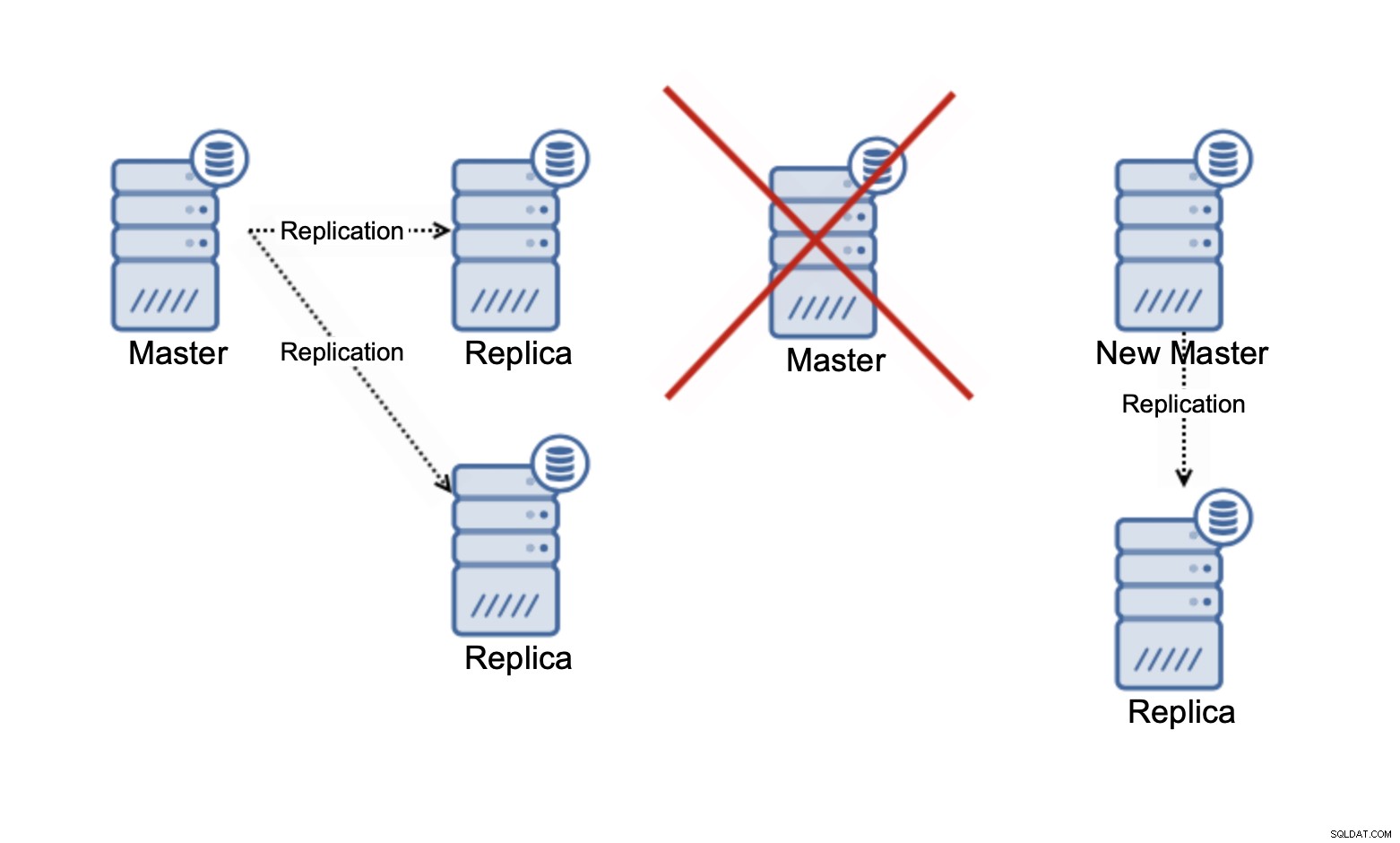
Veuillez garder à l'esprit que nous ne parlons que de la mise à l'échelle des lectures pour le moment . À aucun moment, la réplication ne peut améliorer votre capacité d'écriture. Dans la réplication asynchrone, vous n'avez qu'un seul écrivain (maître), et pour la réplication synchrone, comme Galera, où l'ensemble de données est partagé entre tous les nœuds, chaque écriture qui se produit sur un nœud devra être effectuée sur les nœuds restants du groupe.
Dans un cluster Galera à trois nœuds, si vous écrivez une ligne, vous écrivez en fait trois lignes, une pour chaque nœud. Ajouter plus de nœuds ou de répliques ne fera aucune différence. Au lieu d'écrire la même ligne sur trois nœuds, vous l'écrivez sur cinq. C'est pourquoi diviser vos écritures dans un cluster multi-maître, où l'ensemble de données est partagé entre tous les nœuds (il existe des clusters multi-maîtres où les données sont fragmentées, par exemple MySQL NDB Cluster - ici, l'histoire de l'évolutivité en écriture est totalement différente), n'a pas trop de sens. Cela ajoute une surcharge de traitement des conflits d'écriture potentiels sur tous les nœuds alors qu'il ne change vraiment rien en ce qui concerne la capacité d'écriture totale.
Équilibrage de charge et séparation lecture/écriture
La possibilité de séparer les lectures des écritures est indispensable si vous souhaitez mettre à l'échelle vos lectures dans des configurations de réplication asynchrone. Vous devez pouvoir envoyer le trafic d'écriture à un nœud, puis envoyer les lectures à tous les nœuds de la topologie de réplication. Comme nous l'avons mentionné précédemment, cette fonctionnalité est également très utile dans les clusters multi-maîtres car elle nous permet de supprimer les conflits d'écriture qui peuvent survenir si vous essayez de répartir les écritures sur plusieurs nœuds du cluster. Comment pouvons-nous effectuer la séparation lecture/écriture ? Il existe plusieurs méthodes que vous pouvez utiliser pour le faire. Creusons un peu ce sujet.
Division R/W au niveau de l'application
Le scénario le plus simple, le moins fréquent aussi :votre application est capable de configurer quels nœuds doivent recevoir des écritures et quels nœuds doivent recevoir des lectures. Cette fonctionnalité peut être configurée de plusieurs manières, la plus simple étant la liste codée en dur des nœuds, mais il peut également s'agir d'un inventaire de nœuds dynamique mis à jour par des threads d'arrière-plan. Le principal problème avec cette approche est que toute la logique doit être écrite comme une partie de l'application. Avec une liste de nœuds codés en dur, le scénario le plus simple nécessiterait des modifications du code d'application pour chaque modification de la topologie de réplication. En revanche, des solutions plus avancées comme la mise en œuvre d'une découverte de service seraient plus complexes à maintenir sur le long terme.
R/W fractionné dans le connecteur
Une autre option serait d'utiliser un connecteur pour effectuer une séparation lecture/écriture. Tous n'ont pas cette option, mais certains l'ont. Un exemple serait php-mysqlnd ou Connector/J. Son intégration dans l'application peut différer en fonction du connecteur lui-même. Dans certains cas, la configuration doit être effectuée dans l'application, dans certains cas, elle doit être effectuée dans un fichier de configuration séparé pour le connecteur. L'avantage de cette approche est que même si vous devez étendre votre application, la plupart du nouveau code est prêt à l'emploi et maintenu par des sources externes. Cela facilite la gestion d'une telle configuration et vous devez écrire moins de code (le cas échéant).
Répartition R/W dans l'équilibreur de charge
Enfin, une des meilleures solutions :les loadbalancers. L'idée est simple - faites passer vos données via un équilibreur de charge qui sera capable de faire la distinction entre les lectures et les écritures et de les envoyer à un emplacement approprié. Il s'agit d'une grande amélioration du point de vue de la convivialité, car nous pouvons séparer la découverte de la base de données et le routage des requêtes de l'application. La seule chose que l'application doit faire est d'envoyer le trafic de la base de données à un point de terminaison unique composé d'un nom d'hôte et d'un port. Le reste se passe en arrière-plan. Les équilibreurs de charge travaillent pour acheminer les requêtes vers des nœuds de base de données backend. Les équilibreurs de charge peuvent également effectuer la découverte de la topologie de réplication ou vous pouvez implémenter un inventaire de service approprié à l'aide d'etcd ou de consul et le mettre à jour via vos outils d'orchestration d'infrastructure comme Ansible.
Ceci conclut la première partie de ce blog. Dans le second, nous discuterons des défis auxquels nous sommes confrontés lors de la mise à l'échelle du niveau de la base de données. Nous discuterons également de certaines manières de faire évoluer nos clusters de bases de données.



