Les groupes de disponibilité, introduits dans SQL Server 2012, représentent un changement fondamental dans la façon dont nous envisageons à la fois la haute disponibilité et la reprise après sinistre pour nos bases de données. L'une des grandes choses rendues possibles ici est de décharger les opérations en lecture seule sur un réplica secondaire, de sorte que l'instance principale de lecture/écriture ne soit pas dérangée par des choses embêtantes comme les rapports de l'utilisateur final. La configuration n'est pas simple, mais elle est beaucoup plus facile et plus maintenable que les solutions précédentes (levez la main si vous avez aimé la mise en place de la mise en miroir et des instantanés, et toute la maintenance perpétuelle impliquée).
Les gens sont très enthousiastes lorsqu'ils entendent parler des groupes de disponibilité. Ensuite, la réalité frappe:la fonctionnalité nécessite l'édition Enterprise de SQL Server (à partir de SQL Server 2014, de toute façon). Enterprise Edition est chère, surtout si vous avez beaucoup de cœurs, et surtout depuis l'élimination des licences basées sur CAL (sauf si vous avez bénéficié de droits acquis à partir de 2008 R2, auquel cas vous êtes limité aux 20 premiers cœurs). Cela nécessite également le clustering de basculement Windows Server (WSFC), une complication non seulement pour démontrer la technologie sur un ordinateur portable, mais également pour l'édition Enterprise de Windows, un contrôleur de domaine et tout un tas de configurations pour prendre en charge le clustering. Et il existe également de nouvelles exigences concernant la Software Assurance; un coût supplémentaire si vous souhaitez que vos instances de secours soient conformes.
Certains clients ne peuvent pas justifier le prix. D'autres voient la valeur, mais ne peuvent tout simplement pas se le permettre. Que doivent donc faire ces utilisateurs ?
Votre nouveau héros :l'envoi de journaux
L'expédition de journaux existe depuis des lustres. C'est simple et ça marche. Presque toujours. Et en plus de contourner les coûts de licence et les obstacles de configuration présentés par les groupes de disponibilité, cela peut également éviter la pénalité de 14 octets dont Paul Randal (@PaulRandal) a parlé dans la newsletter SQLskills Insider de cette semaine (13 octobre 2014).
L'un des défis que les gens rencontrent avec l'utilisation de la copie du journal expédié comme secondaire lisible, cependant, est que vous devez expulser tous les utilisateurs actuels afin d'appliquer de nouveaux journaux - donc soit vous avez des utilisateurs ennuyés parce qu'ils sont à plusieurs reprises perturbés d'exécuter des requêtes, ou vos utilisateurs sont ennuyés parce que leurs données sont obsolètes. C'est parce que les gens se limitent à un seul secondaire lisible.
Cela n'a pas à être ainsi; Je pense qu'il existe une solution élégante ici, et bien que cela puisse nécessiter beaucoup plus de travail initial que, par exemple, l'activation des groupes de disponibilité, ce sera sûrement une option attrayante pour certains.
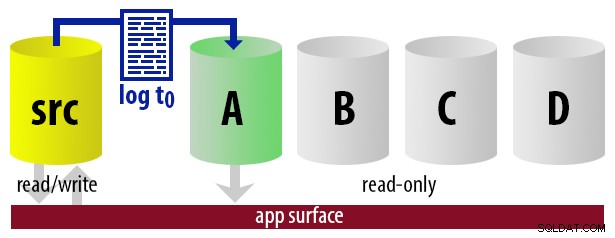
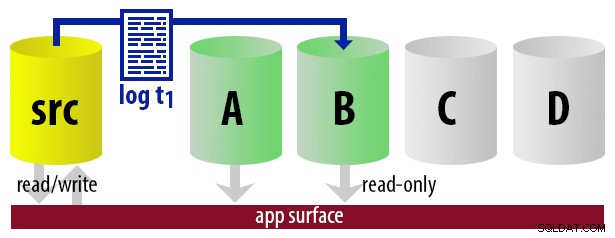
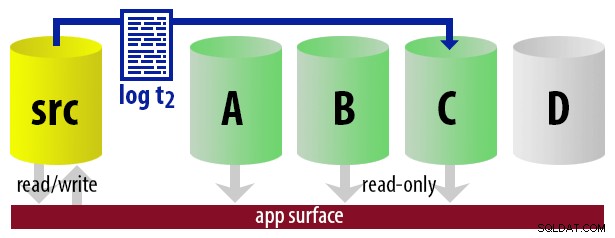
Fondamentalement, nous pouvons mettre en place un certain nombre de secondaires, où nous enregistrerons le navire et n'en ferons qu'un le secondaire "actif", en utilisant une approche circulaire. Le travail qui expédie les journaux sait lequel est actuellement actif, il ne restaure donc que les nouveaux journaux sur le serveur "suivant" en utilisant le WITH STANDBY option. L'application de génération de rapports utilise les mêmes informations pour déterminer au moment de l'exécution quelle doit être la chaîne de connexion pour le prochain rapport exécuté par l'utilisateur. Lorsque la prochaine sauvegarde du journal est prête, tout est décalé d'une unité et l'instance qui deviendra désormais la nouvelle secondaire lisible est restaurée à l'aide de WITH STANDBY .
Pour que le modèle reste simple, supposons que nous ayons quatre instances qui servent de secondaires lisibles et que nous effectuons des sauvegardes de journaux toutes les 15 minutes. À tout moment, nous aurons un secondaire actif en mode veille, avec des données ne datant pas de plus de 15 minutes, et trois secondaires en mode veille qui ne traitent pas de nouvelles requêtes (mais peuvent toujours renvoyer des résultats pour des requêtes plus anciennes).
Cela fonctionnera mieux si aucune requête ne devrait durer plus de 45 minutes. (Vous devrez peut-être ajuster ces cycles en fonction de la nature de vos opérations en lecture seule, du nombre d'utilisateurs simultanés qui exécutent des requêtes plus longues et de la possibilité de perturber les utilisateurs en expulsant tout le monde.)
Cela fonctionnera également mieux si des requêtes consécutives exécutées par le même utilisateur peuvent changer leur chaîne de connexion (c'est la logique qui devra être dans l'application, bien que vous puissiez utiliser des synonymes ou des vues selon l'architecture), et contiennent des données différentes qui ont changé entre-temps (comme s'ils interrogeaient la base de données en direct, en constante évolution).
Avec toutes ces hypothèses à l'esprit, voici une séquence illustrative d'événements pour les 75 premières minutes de notre mise en œuvre :
| heure | événements | visuel |
|---|---|---|
| 12:00 (t0) |
|  |
| 12:15 (t1) |
|  |
| 12:30 (t2) |
|  |
| 12:45 (t3) |
| 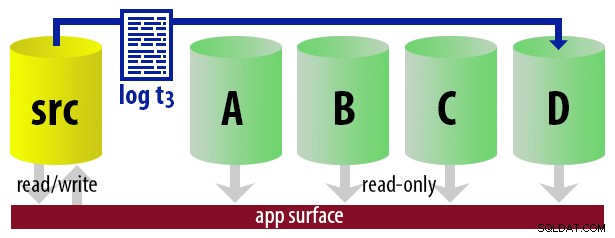 |
| 13:00 (t4) |
| 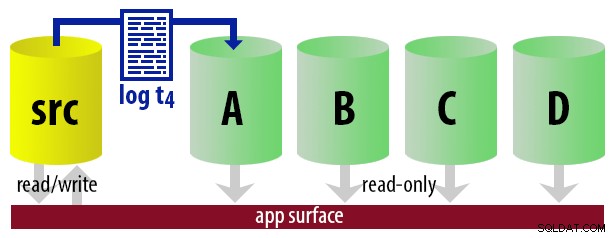 |
Cela peut sembler assez simple ; écrire le code pour gérer tout cela est un peu plus intimidant. Un aperçu :
- Sur le serveur principal (je l'appellerai
BOSS), créer une base de données. Avant même de penser à aller plus loin, activez Trace Flag 3226 pour éviter que les messages de sauvegarde réussis ne jonchent le journal des erreurs de SQL Server. - Sur
BOSS, ajoutez un serveur lié pour chaque secondaire (je les appelleraiPEON1->PEON4). - Dans un endroit accessible à tous les serveurs, créez un partage de fichiers pour stocker les sauvegardes de base de données/journaux et assurez-vous que les comptes de service de chaque instance disposent d'un accès en lecture/écriture. De plus, chaque instance secondaire doit avoir un emplacement spécifié pour le fichier de secours.
- Dans une base de données utilitaire distincte (ou MSDB, si vous préférez), créez des tables qui contiendront des informations de configuration sur la ou les bases de données, toutes les bases de données secondaires et l'historique de sauvegarde et de restauration des journaux.
- Créer des procédures stockées qui sauvegarderont la base de données et restaureront les secondaires
WITH NORECOVERY, puis appliquez un journalWITH STANDBY, et marquez une instance comme instance secondaire de secours actuelle. Ces procédures peuvent également être utilisées pour réinitialiser l'ensemble de la configuration de l'envoi de journaux en cas de problème. - Créez une tâche qui s'exécutera toutes les 15 minutes pour effectuer les tâches décrites ci-dessus :
- sauvegarder le journal
- déterminer à quel secondaire appliquer les sauvegardes de journaux non appliquées
- restaurer ces journaux avec les paramètres appropriés
- Créez une procédure stockée (et/ou une vue ?) qui indiquera à la ou aux applications appelantes quel secondaire elles doivent utiliser pour toute nouvelle requête en lecture seule.
- Créez une procédure de nettoyage pour effacer l'historique de sauvegarde des journaux pour les journaux qui ont été appliqués à tous les secondaires (et peut-être aussi pour déplacer ou purger les fichiers eux-mêmes).
- Augmentez la solution avec une gestion des erreurs et des notifications robustes.
Étape 1 - créer une base de données
Mon instance principale est Standard Edition, nommée .\BOSS . Sur cette instance, je crée une base de données simple avec une table :
USE [master]; GO CREATE DATABASE UserData; GO ALTER DATABASE UserData SET RECOVERY FULL; GO USE UserData; GO CREATE TABLE dbo.LastUpdate(EventTime DATETIME2); INSERT dbo.LastUpdate(EventTime) SELECT SYSDATETIME();
Ensuite, je crée un travail SQL Server Agent qui met simplement à jour cet horodatage toutes les minutes :
UPDATE UserData.dbo.LastUpdate SET EventTime = SYSDATETIME();
Cela crée simplement la base de données initiale et simule l'activité, ce qui nous permet de valider la rotation de la tâche d'envoi de journaux à travers chacun des secondaires lisibles. Je tiens à déclarer explicitement que le but de cet exercice n'est pas de tester l'envoi de journaux ou de prouver le volume que nous pouvons traverser ; c'est un tout autre exercice.
Étape 2 :ajouter des serveurs liés
J'ai quatre instances secondaires Express Edition nommées .\PEON1 , .\PEON2 , .\PEON3 , et .\PEON4 . J'ai donc exécuté ce code quatre fois, en changeant @s à chaque fois :
USE [master];
GO
DECLARE @s NVARCHAR(128) = N'.\PEON1', -- repeat for .\PEON2, .\PEON3, .\PEON4
@t NVARCHAR(128) = N'true';
EXEC [master].dbo.sp_addlinkedserver @server = @s, @srvproduct = N'SQL Server';
EXEC [master].dbo.sp_addlinkedsrvlogin @rmtsrvname = @s, @useself = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'collation compatible', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'data access', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc out', @optvalue = @t; Étape 3 :valider le(s) partage(s) de fichiers
Dans mon cas, les 5 instances sont sur le même serveur, je viens donc de créer un dossier pour chaque instance :C:\temp\Peon1\ , C:\temp\Peon2\ , etc. N'oubliez pas que si vos serveurs secondaires se trouvent sur des serveurs différents, l'emplacement doit être relatif à ce serveur, mais toujours accessible à partir du serveur principal (un chemin UNC est donc généralement utilisé). Vous devez valider que chaque instance peut écrire sur ce partage, et vous devez également valider que chaque instance peut écrire à l'emplacement spécifié pour le fichier de secours (j'ai utilisé les mêmes dossiers pour le secours). Vous pouvez valider cela en sauvegardant une petite base de données de chaque instance vers chacun de ses emplacements spécifiés - ne continuez pas tant que cela ne fonctionne pas.
Étape 4 :créer des tableaux
J'ai décidé de placer ces données dans msdb , mais je n'ai pas vraiment de sentiments forts pour ou contre la création d'une base de données séparée. La première table dont j'ai besoin est celle qui contient des informations sur la ou les bases de données que je vais envoyer :
CREATE TABLE dbo.PMAG_Databases ( DatabaseName SYSNAME, LogBackupFrequency_Minutes SMALLINT NOT NULL DEFAULT (15), CONSTRAINT PK_DBS PRIMARY KEY(DatabaseName) ); GO INSERT dbo.PMAG_Databases(DatabaseName) SELECT N'UserData';
(Si vous êtes curieux de connaître le schéma de dénomination, PMAG signifie "Poor Man's Availability Groups".)
Une autre table requise est celle qui contient des informations sur les secondaires, y compris leurs dossiers individuels et leur statut actuel dans la séquence d'envoi des journaux.
CREATE TABLE dbo.PMAG_Secondaries
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
CommonFolder VARCHAR(512) NOT NULL,
DataFolder VARCHAR(512) NOT NULL,
LogFolder VARCHAR(512) NOT NULL,
StandByLocation VARCHAR(512) NOT NULL,
IsCurrentStandby BIT NOT NULL DEFAULT 0,
CONSTRAINT PK_Sec PRIMARY KEY(DatabaseName, ServerInstance),
CONSTRAINT FK_Sec_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName)
);
Si vous souhaitez effectuer une sauvegarde locale à partir du serveur source et que les serveurs secondaires restaurent à distance, ou vice versa, vous pouvez diviser CommonFolder en deux colonnes (BackupFolder et RestoreFolder ), et apportez les modifications pertinentes dans le code (il n'y en aura pas tant que ça).
Étant donné que je peux remplir cette table en me basant au moins partiellement sur les informations contenues dans sys.servers – profitant du fait que les données/journaux et autres dossiers sont nommés d'après les noms d'instance :
INSERT dbo.PMAG_Secondaries
(
DatabaseName,
ServerInstance,
CommonFolder,
DataFolder,
LogFolder,
StandByLocation
)
SELECT
DatabaseName = N'UserData',
ServerInstance = name,
CommonFolder = 'C:\temp\Peon' + RIGHT(name, 1) + '\',
DataFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
LogFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
StandByLocation = 'C:\temp\Peon' + RIGHT(name, 1) + '\'
FROM sys.servers
WHERE name LIKE N'.\PEON[1-4]';
J'ai également besoin d'une table pour suivre les sauvegardes de journaux individuelles (pas seulement la dernière), car dans de nombreux cas, je devrai restaurer plusieurs fichiers journaux dans une séquence. Je peux obtenir ces informations à partir de msdb.dbo.backupset , mais il est beaucoup plus compliqué d'obtenir des informations telles que l'emplacement, et je n'ai peut-être pas le contrôle sur d'autres tâches susceptibles de nettoyer l'historique des sauvegardes.
CREATE TABLE dbo.PMAG_LogBackupHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT NOT NULL,
Location VARCHAR(2000) NOT NULL,
BackupTime DATETIME NOT NULL DEFAULT SYSDATETIME(),
CONSTRAINT PK_LBH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LBH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LBH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
); Vous pourriez penser qu'il est inutile de stocker une ligne pour chaque secondaire et de stocker l'emplacement de chaque sauvegarde, mais c'est pour la pérennité - pour gérer le cas où vous déplacez le CommonFolder pour n'importe quel secondaire.
Et enfin un historique des restaurations de journaux pour que, à tout moment, je puisse voir quels journaux ont été restaurés et où, et la tâche de restauration peut être sûre de ne restaurer que les journaux qui n'ont pas encore été restaurés :
CREATE TABLE dbo.PMAG_LogRestoreHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT,
RestoreTime DATETIME,
CONSTRAINT PK_LRH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LRH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LRH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
); Étape 5 - initialiser les secondaires
Nous avons besoin d'une procédure stockée qui générera un fichier de sauvegarde (et le reflétera à tous les emplacements requis par différentes instances), et nous restaurerons également un journal sur chaque secondaire pour les mettre tous en veille. À ce stade, ils seront tous disponibles pour les requêtes en lecture seule, mais un seul sera la veille "actuelle" à la fois. Il s'agit de la procédure stockée qui gérera à la fois les sauvegardes complètes et les sauvegardes du journal des transactions ; lorsqu'une sauvegarde complète est demandée, et @init est défini sur 1, il réinitialise automatiquement l'envoi de journaux.
CREATE PROCEDURE [dbo].[PMAG_Backup]
@dbname SYSNAME,
@type CHAR(3) = 'bak', -- or 'trn'
@init BIT = 0 -- only used with 'bak'
AS
BEGIN
SET NOCOUNT ON;
-- generate a filename pattern
DECLARE @now DATETIME = SYSDATETIME();
DECLARE @fn NVARCHAR(256) = @dbname + N'_' + CONVERT(CHAR(8), @now, 112)
+ RIGHT(REPLICATE('0',6) + CONVERT(VARCHAR(32), DATEDIFF(SECOND,
CONVERT(DATE, @now), @now)), 6) + N'.' + @type;
-- generate a backup command with MIRROR TO for each distinct CommonFolder
DECLARE @sql NVARCHAR(MAX) = N'BACKUP'
+ CASE @type WHEN 'bak' THEN N' DATABASE ' ELSE N' LOG ' END
+ QUOTENAME(@dbname) + '
' + STUFF(
(SELECT DISTINCT CHAR(13) + CHAR(10) + N' MIRROR TO DISK = '''
+ s.CommonFolder + @fn + ''''
FROM dbo.PMAG_Secondaries AS s
WHERE s.DatabaseName = @dbname
FOR XML PATH(''), TYPE).value(N'.[1]',N'nvarchar(max)'),1,9,N'') + N'
WITH NAME = N''' + @dbname + CASE @type
WHEN 'bak' THEN N'_PMAGFull' ELSE N'_PMAGLog' END
+ ''', INIT, FORMAT' + CASE WHEN LEFT(CONVERT(NVARCHAR(128),
SERVERPROPERTY(N'Edition')), 3) IN (N'Dev', N'Ent')
THEN N', COMPRESSION;' ELSE N';' END;
EXEC [master].sys.sp_executesql @sql;
IF @type = 'bak' AND @init = 1 -- initialize log shipping
BEGIN
EXEC dbo.PMAG_InitializeSecondaries @dbname = @dbname, @fn = @fn;
END
IF @type = 'trn'
BEGIN
-- record the fact that we backed up a log
INSERT dbo.PMAG_LogBackupHistory
(
DatabaseName,
ServerInstance,
BackupSetID,
Location
)
SELECT
DatabaseName = @dbname,
ServerInstance = s.ServerInstance,
BackupSetID = MAX(b.backup_set_id),
Location = s.CommonFolder + @fn
FROM msdb.dbo.backupset AS b
CROSS JOIN dbo.PMAG_Secondaries AS s
WHERE b.name = @dbname + N'_PMAGLog'
AND s.DatabaseName = @dbname
GROUP BY s.ServerInstance, s.CommonFolder + @fn;
-- once we've backed up logs,
-- restore them on the next secondary
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname;
END
END Cela appelle à son tour deux procédures que vous pourriez appeler séparément (mais que vous ne ferez probablement pas). Tout d'abord, la procédure qui va initialiser les secondaires à la première exécution :
ALTER PROCEDURE dbo.PMAG_InitializeSecondaries
@dbname SYSNAME,
@fn VARCHAR(512)
AS
BEGIN
SET NOCOUNT ON;
-- clear out existing history/settings (since this may be a re-init)
DELETE dbo.PMAG_LogBackupHistory WHERE DatabaseName = @dbname;
DELETE dbo.PMAG_LogRestoreHistory WHERE DatabaseName = @dbname;
UPDATE dbo.PMAG_Secondaries SET IsCurrentStandby = 0
WHERE DatabaseName = @dbname;
DECLARE @sql NVARCHAR(MAX) = N'',
@files NVARCHAR(MAX) = N'';
-- need to know the logical file names - may be more than two
SET @sql = N'SELECT @files = (SELECT N'', MOVE N'''''' + name
+ '''''' TO N''''$'' + CASE [type] WHEN 0 THEN N''df''
WHEN 1 THEN N''lf'' END + ''$''''''
FROM ' + QUOTENAME(@dbname) + '.sys.database_files
WHERE [type] IN (0,1)
FOR XML PATH, TYPE).value(N''.[1]'',N''nvarchar(max)'');';
EXEC master.sys.sp_executesql @sql,
N'@files NVARCHAR(MAX) OUTPUT',
@files = @files OUTPUT;
SET @sql = N'';
-- restore - need physical paths of data/log files for WITH MOVE
-- this can fail, obviously, if those path+names already exist for another db
SELECT @sql += N'EXEC ' + QUOTENAME(ServerInstance)
+ N'.master.sys.sp_executesql N''RESTORE DATABASE ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + CommonFolder + @fn + N'''''' + N' WITH REPLACE,
NORECOVERY' + REPLACE(REPLACE(REPLACE(@files, N'$df$', DataFolder
+ @dbname + N'.mdf'), N'$lf$', LogFolder + @dbname + N'.ldf'), N'''', N'''''')
+ N';'';' + CHAR(13) + CHAR(10)
FROM dbo.PMAG_Secondaries
WHERE DatabaseName = @dbname;
EXEC [master].sys.sp_executesql @sql;
-- backup a log for this database
EXEC dbo.PMAG_Backup @dbname = @dbname, @type = 'trn';
-- restore logs
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname, @PrepareAll = 1;
END Et ensuite la procédure qui restaurera les logs :
CREATE PROCEDURE dbo.PMAG_RestoreLogs
@dbname SYSNAME,
@PrepareAll BIT = 0
AS
BEGIN
SET NOCOUNT ON;
DECLARE @StandbyInstance SYSNAME,
@CurrentInstance SYSNAME,
@BackupSetID INT,
@Location VARCHAR(512),
@StandByLocation VARCHAR(512),
@sql NVARCHAR(MAX),
@rn INT;
-- get the "next" standby instance
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 0
AND ServerInstance > (SELECT ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandBy = 1);
IF @StandbyInstance IS NULL -- either it was last or a re-init
BEGIN
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries;
END
-- get that instance up and into STANDBY
-- for each log in logbackuphistory not in logrestorehistory:
-- restore, and insert it into logrestorehistory
-- mark the last one as STANDBY
-- if @prepareAll is true, mark all others as NORECOVERY
-- in this case there should be only one, but just in case
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT bh.BackupSetID, s.ServerInstance, bh.Location, s.StandbyLocation,
rn = ROW_NUMBER() OVER (PARTITION BY s.ServerInstance ORDER BY bh.BackupSetID DESC)
FROM dbo.PMAG_LogBackupHistory AS bh
INNER JOIN dbo.PMAG_Secondaries AS s
ON bh.DatabaseName = s.DatabaseName
AND bh.ServerInstance = s.ServerInstance
WHERE s.DatabaseName = @dbname
AND s.ServerInstance = CASE @PrepareAll
WHEN 1 THEN s.ServerInstance ELSE @StandbyInstance END
AND NOT EXISTS
(
SELECT 1 FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE DatabaseName = @dbname
AND ServerInstance = s.ServerInstance
AND BackupSetID = bh.BackupSetID
)
ORDER BY CASE s.ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 2 END, bh.BackupSetID;
OPEN c;
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
WHILE @@FETCH_STATUS -1
BEGIN
-- kick users out - set to single_user then back to multi
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance) + N'.[master].sys.sp_executesql '
+ 'N''IF EXISTS (SELECT 1 FROM sys.databases WHERE name = N'''''
+ @dbname + ''''' AND [state] 1)
BEGIN
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET SINGLE_USER '
+ N'WITH ROLLBACK IMMEDIATE;
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET MULTI_USER;
END;'';';
EXEC [master].sys.sp_executesql @sql;
-- restore the log (in STANDBY if it's the last one):
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance)
+ N'.[master].sys.sp_executesql ' + N'N''RESTORE LOG ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + @Location + N''''' WITH ' + CASE WHEN @rn = 1
AND (@CurrentInstance = @StandbyInstance OR @PrepareAll = 1) THEN
N'STANDBY = N''''' + @StandbyLocation + @dbname + N'.standby''''' ELSE
N'NORECOVERY' END + N';'';';
EXEC [master].sys.sp_executesql @sql;
-- record the fact that we've restored logs
INSERT dbo.PMAG_LogRestoreHistory
(DatabaseName, ServerInstance, BackupSetID, RestoreTime)
SELECT @dbname, @CurrentInstance, @BackupSetID, SYSDATETIME();
-- mark the new standby
IF @rn = 1 AND @CurrentInstance = @StandbyInstance -- this is the new STANDBY
BEGIN
UPDATE dbo.PMAG_Secondaries
SET IsCurrentStandby = CASE ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 0 END
WHERE DatabaseName = @dbname;
END
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
END
CLOSE c; DEALLOCATE c;
END (Je sais que c'est beaucoup de code et beaucoup de SQL dynamique crypté. J'ai essayé d'être très libéral avec les commentaires ; s'il y a un élément avec lequel vous rencontrez des problèmes, faites-le moi savoir.)
Alors maintenant, tout ce que vous avez à faire pour que le système soit opérationnel est de faire deux appels de procédure :
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'bak', @init = 1; EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Vous devriez maintenant voir chaque instance avec une copie de secours de la base de données :
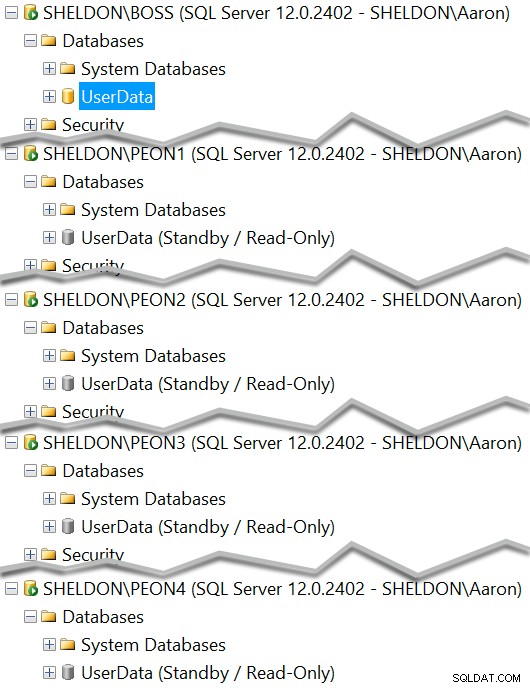
Et vous pouvez voir lequel doit actuellement servir de veille en lecture seule :
SELECT ServerInstance, IsCurrentStandby FROM dbo.PMAG_Secondaries WHERE DatabaseName = N'UserData';
Étape 6 :créer une tâche qui sauvegarde/restaure les journaux
Vous pouvez placer cette commande dans une tâche que vous planifiez toutes les 15 minutes :
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Cela déplacera le secondaire actif toutes les 15 minutes et ses données seront 15 minutes plus récentes que le secondaire actif précédent. Si vous avez plusieurs bases de données sur des calendriers différents, vous pouvez créer plusieurs tâches ou planifier la tâche plus fréquemment et vérifier les dbo.PMAG_Databases table pour chaque LogBackupFrequency_Minutes valeur pour déterminer si vous devez exécuter la sauvegarde/restauration pour cette base de données.
Étape 7 : affichage et procédure pour indiquer à l'application quelle veille est active
CREATE VIEW dbo.PMAG_ActiveSecondaries
AS
SELECT DatabaseName, ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 1;
GO
CREATE PROCEDURE dbo.PMAG_GetActiveSecondary
@dbname SYSNAME
AS
BEGIN
SET NOCOUNT ON;
SELECT ServerInstance
FROM dbo.PMAG_ActiveSecondaries
WHERE DatabaseName = @dbname;
END
GO
Dans mon cas, j'ai également créé manuellement une vue réunissant tous les UserData bases de données afin que je puisse comparer la récence des données sur le primaire avec chaque secondaire.
CREATE VIEW dbo.PMAG_CompareRecency_UserData
AS
WITH x(ServerInstance, EventTime)
AS
(
SELECT @@SERVERNAME, EventTime FROM UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON1', EventTime FROM [.\PEON1].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON2', EventTime FROM [.\PEON2].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON3', EventTime FROM [.\PEON3].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON4', EventTime FROM [.\PEON4].UserData.dbo.LastUpdate
)
SELECT x.ServerInstance, s.IsCurrentStandby, x.EventTime,
Age_Minutes = DATEDIFF(MINUTE, x.EventTime, SYSDATETIME()),
Age_Seconds = DATEDIFF(SECOND, x.EventTime, SYSDATETIME())
FROM x LEFT OUTER JOIN dbo.PMAG_Secondaries AS s
ON s.ServerInstance = x.ServerInstance
AND s.DatabaseName = N'UserData';
GO Exemples de résultats du week-end :
SELECT [Now] = SYSDATETIME(); SELECT ServerInstance, IsCurrentStandby, EventTime, Age_Minutes, Age_Seconds FROM dbo.PMAG_CompareRecency_UserData ORDER BY Age_Seconds DESC;
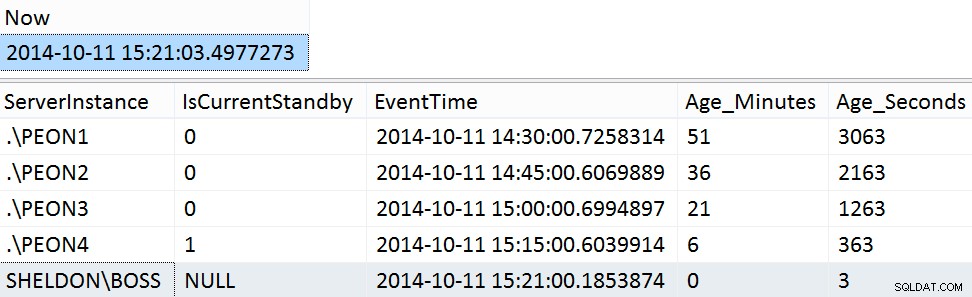
Étape 8 - procédure de nettoyage
Nettoyer l'historique de sauvegarde et de restauration des journaux est assez facile.
CREATE PROCEDURE dbo.PMAG_CleanupHistory
@dbname SYSNAME,
@DaysOld INT = 7
AS
BEGIN
SET NOCOUNT ON;
DECLARE @cutoff INT;
-- this assumes that a log backup either
-- succeeded or failed on all secondaries
SELECT @cutoff = MAX(BackupSetID)
FROM dbo.PMAG_LogBackupHistory AS bh
WHERE DatabaseName = @dbname
AND BackupTime < DATEADD(DAY, -@DaysOld, SYSDATETIME())
AND EXISTS
(
SELECT 1
FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE BackupSetID = bh.BackupSetID
AND DatabaseName = @dbname
AND ServerInstance = bh.ServerInstance
);
DELETE dbo.PMAG_LogRestoreHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
DELETE dbo.PMAG_LogBackupHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
END
GO Désormais, vous pouvez l'ajouter en tant qu'étape dans la tâche existante, ou vous pouvez la planifier complètement séparément ou dans le cadre d'autres routines de nettoyage.
Je laisserai le nettoyage du système de fichiers pour un autre article (et probablement un mécanisme distinct, comme PowerShell ou C# - ce n'est généralement pas le genre de chose que vous voulez que T-SQL fasse).
Étape 9 – Augmenter la solution
Il est vrai qu'il pourrait y avoir une meilleure gestion des erreurs et d'autres subtilités ici pour rendre cette solution plus complète. Pour l'instant, je vais laisser cela comme un exercice pour le lecteur, mais je prévois d'examiner les messages de suivi pour détailler les améliorations et les raffinements de cette solution.
Variables et limites
Notez que dans mon cas, j'ai utilisé Standard Edition comme primaire et Express Edition pour tous les secondaires. Vous pouvez aller plus loin sur l'échelle budgétaire et même utiliser Express Edition comme principal - beaucoup de gens pensent qu'Express Edition ne prend pas en charge l'envoi de journaux, alors qu'en fait c'est simplement l'assistant qui n'était pas présent dans les versions de Management Studio Express avant SQL Server 2012 Service Pack 1. Cela dit, étant donné qu'Express Edition ne prend pas en charge l'Agent SQL Server, il serait difficile d'en faire un éditeur dans ce scénario - vous devriez configurer votre propre planificateur pour appeler les procédures stockées (C# application de ligne de commande exécutée par le Planificateur de tâches Windows, les travaux PowerShell ou les travaux de l'Agent SQL Server sur une autre instance). Pour utiliser Express à chaque extrémité, vous devez également être sûr que votre fichier de données ne dépassera pas 10 Go et que vos requêtes fonctionneront correctement avec la mémoire, le processeur et les limitations de fonctionnalités de cette édition. Je ne suggère en aucun cas qu'Express soit idéal; Je l'ai simplement utilisé pour démontrer qu'il est possible d'avoir gratuitement des secondaires lisibles très flexibles (ou très proches).
De plus, ces instances distinctes dans mon scénario vivent toutes sur la même machine virtuelle, mais cela ne doit pas du tout fonctionner de cette façon - vous pouvez répartir les instances sur plusieurs serveurs ; ou, vous pouvez aller dans l'autre sens et restaurer différentes copies de la base de données, avec des noms différents, sur la même instance. Ces configurations nécessiteraient des changements minimes par rapport à ce que j'ai exposé ci-dessus. Et combien de bases de données vous restaurez, et à quelle fréquence, dépend entièrement de vous - bien qu'il y ait une limite supérieure pratique (où [average query time] > [number of secondaries] x [log backup interval] ).
Enfin, il y a certainement des limites à cette approche. Une liste non exhaustive :
- Bien que vous puissiez continuer à effectuer des sauvegardes complètes selon votre propre calendrier, les sauvegardes de journaux doivent constituer votre seul mécanisme de sauvegarde de journaux. Si vous avez besoin de stocker les sauvegardes de journaux à d'autres fins, vous ne pourrez pas sauvegarder les journaux séparément de cette solution, car ils interféreront avec la chaîne de journaux. Au lieu de cela, vous pouvez envisager d'ajouter un
MIRROR TOsupplémentaire arguments to the existing log backup scripts, if you need to have copies of the logs used elsewhere. - While "Poor Man's Availability Groups" may seem like a clever name, it can also be a bit misleading. This solution certainly lacks many of the HA/DR features of Availability Groups, including failover, automatic page repair, and support in the UI, Extended Events and DMVs. This was only meant to provide the ability for non-Enterprise customers to have an infrastructure that supports multiple readable secondaries.
- I tested this on a very isolated VM system with no concurrency. This is not a complete solution and there are likely dozens of ways this code could be made tighter; as a first step, and to focus on the scaffolding and to show you what's possible, I did not build in bulletproof resiliency. You will need to test it at your scale and with your workload to discover your breaking points, and you will also potentially need to deal with transactions over linked servers (always fun) and automating the re-initialization in the event of a disaster.
The "Insurance Policy"
Log shipping also offers a distinct advantage over many other solutions, including Availability Groups, mirroring and replication:a delayed "insurance policy" as I like to call it. At my previous job, I did this with full backups, but you could easily use log shipping to accomplish the same thing:I simply delayed the restores to one of the secondary instances by 24 hours. This way, I was protected from any client "shooting themselves in the foot" going back to yesterday, and I could get to their data easily on the delayed copy, because it was 24 hours behind. (I implemented this the first time a customer ran a delete without a where clause, then called us in a panic, at which point we had to restore their database to a point in time before the delete – which was both tedious and time consuming.) You could easily adapt this solution to treat one of these instances not as a read-only secondary but rather as an insurance policy. More on that perhaps in another post.