Les plans d'exécution fournissent une riche source d'informations qui peuvent nous aider à identifier les moyens d'améliorer les performances des requêtes importantes. Les gens recherchent souvent des éléments tels que des analyses et des recherches volumineuses pour identifier les optimisations potentielles des chemins d'accès aux données. Ces problèmes peuvent souvent être résolus rapidement en créant un nouvel index ou en étendant un existant avec plus de colonnes incluses.
Nous pouvons également utiliser des plans post-exécution pour comparer le nombre de lignes réel et attendu entre les opérateurs de plan. Lorsque ceux-ci s'avèrent significativement différents, nous pouvons essayer de fournir de meilleures informations statistiques à l'optimiseur en mettant à jour les statistiques existantes, en créant de nouveaux objets statistiques, en utilisant des statistiques sur des colonnes calculées ou peut-être en divisant une requête complexe en un composant moins complexe. pièces.
Au-delà de cela, nous pouvons également examiner les opérations coûteuses du plan, en particulier celles qui consomment de la mémoire comme le tri et le hachage. Le tri peut parfois être évité grâce aux changements d'indexation. D'autres fois, nous devrons peut-être refactoriser la requête en utilisant une syntaxe qui favorise un plan qui préserve un ordre particulier souhaité.
Parfois, les performances ne seront toujours pas suffisantes même après l'application de toutes ces techniques de réglage des performances. Une prochaine étape possible consiste à réfléchir un peu plus au plan dans son ensemble . Cela signifie prendre du recul, essayer de comprendre la stratégie globale choisie par l'optimiseur de requêtes, pour voir si nous pouvons identifier une amélioration algorithmique.
Cet article explore ce dernier type d'analyse, à l'aide d'un exemple simple de problème consistant à trouver des valeurs de colonne uniques dans un ensemble de données modérément volumineux. Comme c'est souvent le cas dans des problèmes analogues du monde réel, la colonne d'intérêt aura relativement peu de valeurs uniques, par rapport au nombre de lignes dans le tableau. Cette analyse comporte deux parties :la création des exemples de données et l'écriture de la requête de valeurs distinctes elle-même.
Création des exemples de données
Pour fournir l'exemple le plus simple possible, notre table de test n'a qu'une seule colonne avec un index clusterisé (cette colonne contiendra des valeurs en double afin que l'index ne puisse pas être déclaré unique) :
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
Pour choisir des nombres dans l'air, nous choisirons de charger dix millions de lignes au total, avec une répartition égale sur mille valeurs distinctes . Une technique courante pour générer des données comme celle-ci consiste à joindre certaines tables système et à appliquer le ROW_NUMBER une fonction. Nous utiliserons également l'opérateur modulo pour limiter les nombres générés aux valeurs distinctes souhaitées :
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); Le plan d'exécution estimé pour cette requête est le suivant (cliquez sur l'image pour l'agrandir si nécessaire) :

Cela prend environ 30 secondes pour créer les exemples de données sur mon ordinateur portable. Ce n'est en aucun cas une durée énorme, mais il est toujours intéressant de réfléchir à ce que nous pourrions faire pour rendre ce processus plus efficace…
Analyse du plan
Nous commencerons par comprendre à quoi sert chaque opération du plan.
La section du plan d'exécution à droite de l'opérateur Segment concerne la fabrication de lignes par recoupement des tables système :

L'opérateur Segment est là au cas où la fonction de fenêtre aurait un PARTITION BY clause. Ce n'est pas le cas ici, mais cela figure quand même dans le plan de requête. L'opérateur Sequence Project génère les numéros de lignes et Top limite la sortie du plan à dix millions de lignes :

Le Compute Scalar définit l'expression qui applique la fonction modulo et en ajoute un au résultat :

Nous pouvons voir comment les étiquettes d'expression Sequence Project et Compute Scalar sont liées à l'aide de l'onglet Expressions de Plan Explorer :

Cela nous donne une idée plus complète du déroulement de ce plan :le projet de séquence numérote les lignes et étiquette l'expression Expr1050; le Compute Scalar étiquette le résultat du calcul modulo et plus un comme Expr1052 . Notez également la conversion implicite dans l'expression Compute Scalar. La colonne de la table de destination est de type entier, alors que le ROW_NUMBER produit un bigint, donc une conversion restrictive est nécessaire.
Le prochain opérateur du plan est un tri. D'après les estimations de coût de l'optimiseur de requêtes, il s'agit de l'opération la plus coûteuse (88,1 % estimation ):

Il se peut que la raison pour laquelle ce plan comporte le tri ne soit pas immédiatement évidente, car il n'y a pas d'exigence de commande explicite dans la requête. Le tri est ajouté au plan pour s'assurer que les lignes arrivent à l'opérateur d'insertion d'index clusterisé dans l'ordre de l'index clusterisé. Cela favorise les écritures séquentielles, évite le fractionnement des pages et constitue l'un des prérequis pour un INSERT à journalisation minimale. opérations.
Ce sont toutes des choses potentiellement bonnes, mais le tri lui-même est plutôt cher. En effet, la vérification du plan d'exécution post-exécution ("réel") révèle que le Sort a également manqué de mémoire au moment de l'exécution et a dû se déverser sur tempdb physique disque :

Le débordement de tri se produit bien que le nombre estimé de lignes soit exactement correct et malgré le fait que la requête ait reçu toute la mémoire demandée (comme indiqué dans les propriétés du plan pour la racine INSERT nœud):

Les déversements de tri sont également indiqués par la présence de IO_COMPLETION attend dans l'onglet des statistiques d'attente de Plan Explorer PRO :

Enfin, pour cette section d'analyse de plan, notez le DML Request Sort propriété de l'opérateur Clustered Index Insert est définie sur true :

Cet indicateur indique que l'optimiseur a besoin de la sous-arborescence sous Insert pour fournir des lignes dans l'ordre de tri des clés d'index (d'où la nécessité de l'opérateur de tri problématique).
Éviter le tri
Maintenant que nous savons pourquoi le tri apparaît, nous pouvons tester pour voir ce qui se passe si nous le supprimons. Il existe des moyens de réécrire la requête pour "tromper" l'optimiseur en lui faisant croire que moins de lignes seraient insérées (donc le tri ne serait pas utile), mais un moyen rapide d'éviter le tri directement (à des fins expérimentales uniquement) consiste à utiliser un indicateur de trace non documenté 8795. Cela définit le DML Request Sort propriété sur false, de sorte que les lignes ne sont plus obligées d'arriver à l'insertion d'index clusterisé dans l'ordre des clés clusterisées :
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); Le nouveau plan de requête post-exécution est le suivant (cliquez sur l'image pour l'agrandir) :

L'opérateur de tri a disparu, mais la nouvelle requête s'exécute pendant plus de 50 secondes (contre 30 secondes avant que). Il y a plusieurs raisons à cela. Tout d'abord, nous perdons toute possibilité d'insertions à journalisation minimale car celles-ci nécessitent des données triées (DML Request Sort =true). Deuxièmement, un grand nombre de "mauvais" fractionnements de page se produiront lors de l'insertion. Au cas où cela semble contre-intuitif, rappelez-vous que bien que le ROW_NUMBER la fonction numérote les lignes de manière séquentielle, l'effet de l'opérateur modulo est de présenter une séquence répétitive de nombres 1…1000 à l'insertion d'index cluster.
Le même problème fondamental se produit si nous utilisons des astuces T-SQL pour réduire le nombre de lignes attendu afin d'éviter le tri au lieu d'utiliser l'indicateur de trace non pris en charge.
Éviter le tri II
En regardant le plan dans son ensemble, il semble clair que nous aimerions générer des lignes d'une manière qui évite un tri explicite, mais qui récolte toujours les avantages d'une journalisation minimale et de l'évitement du fractionnement de pages erronées. En termes simples :nous voulons un plan qui présente les lignes dans l'ordre des clés groupées, mais sans tri.
Armés de cette nouvelle perspective, nous pouvons exprimer notre requête d'une manière différente. La requête suivante génère chaque nombre de 1 à 1 000 et les jointures croisées définies avec 10 000 lignes pour produire le degré de duplication requis. L'idée est de générer un jeu d'inserts qui présente 10 000 lignes numérotées '1' puis 10 000 numérotées '2'… et ainsi de suite.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Malheureusement, l'optimiseur produit toujours un plan avec un tri :

Il n'y a pas grand-chose à dire dans la défense de l'optimiseur ici, c'est juste un plan stupide. Il a choisi de générer 10 000 lignes puis de croiser celles numérotées de 1 à 1000. Cela ne permet pas de conserver l'ordre naturel des numéros, donc le tri est incontournable.
Éviter le tri – Enfin !
La stratégie que l'optimiseur a manquée est de prendre les nombres 1…1000 d'abord , et croisez chaque nombre avec 10 000 lignes (en faisant 10 000 copies de chaque nombre dans l'ordre). Le plan attendu éviterait un tri en utilisant une jointure croisée de boucles imbriquées qui préserve l'ordre des lignes sur l'entrée externe.
Nous pouvons obtenir ce résultat en forçant l'optimiseur à accéder aux tables dérivées dans l'ordre spécifié dans la requête, en utilisant le FORCE ORDER indice de requête :
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Enfin, nous obtenons le plan que nous recherchions :
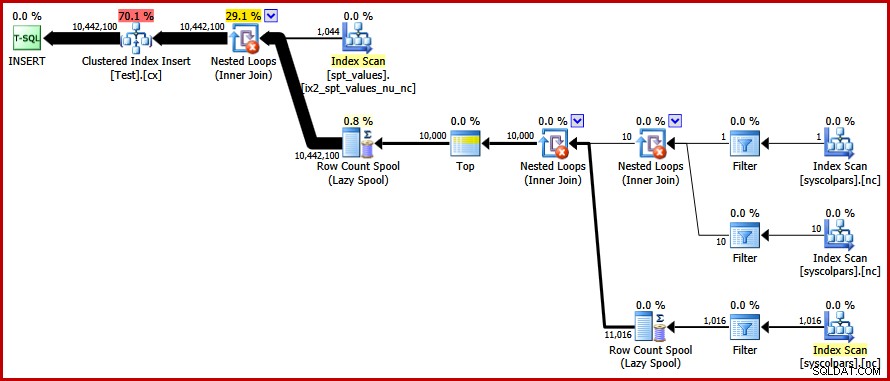
Ce plan évite un tri explicite tout en évitant les "mauvaises" divisions de page et en permettant des insertions minimalement enregistrées dans l'index clusterisé (en supposant que la base de données n'utilise pas le FULL modèle de récupération). Il charge les dix millions de lignes en environ 9 secondes sur mon ordinateur portable (avec un seul disque rotatif SATA à 7200 tr/min). Cela représente un gain d'efficacité marqué sur les 30 à 50 secondes temps écoulé vu avant la réécriture.
Trouver les valeurs distinctes
Maintenant que nous avons créé les exemples de données, nous pouvons porter notre attention sur l'écriture d'une requête pour trouver les valeurs distinctes dans la table. Une manière naturelle d'exprimer cette exigence dans T-SQL est la suivante :
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
Le plan d'exécution est très simple, comme vous vous en doutez :

Cela prend environ 2 900 ms pour fonctionner sur ma machine, et nécessite 43 406 lectures logiques :

Suppression du MAXDOP (1) l'indicateur de requête génère un plan parallèle :

Cela se termine en environ 1 500 ms (mais avec 8 764 ms de temps CPU consommé) et 43 804 lectures logiques :

Les mêmes plans et résultats de performance si nous utilisons GROUP BY au lieu de DISTINCT .
Un meilleur algorithme
Les plans de requête présentés ci-dessus lisent toutes les valeurs de la table de base et les traitent via un Stream Aggregate. En considérant la tâche dans son ensemble, il semble inefficace d'analyser les 10 millions de lignes alors que nous savons qu'il existe relativement peu de valeurs distinctes.
Une meilleure stratégie pourrait être de trouver la valeur unique la plus basse dans le tableau, puis de trouver la suivante la plus élevée, et ainsi de suite jusqu'à ce que nous manquions de valeurs. Fondamentalement, cette approche se prête à la recherche de singleton dans l'index plutôt qu'à l'analyse de chaque ligne.
Nous pouvons implémenter cette idée dans une seule requête en utilisant un CTE récursif, où la partie ancre trouve le plus bas valeur distincte, la partie récursive trouve la valeur distincte suivante et ainsi de suite. Une première tentative d'écriture de cette requête est :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Malheureusement, cette syntaxe ne compile pas :

Ok, donc les fonctions d'agrégation ne sont pas autorisées. Au lieu d'utiliser MIN , nous pouvons écrire la même logique en utilisant TOP (1) avec un ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Toujours pas de joie.
Il s'avère que nous pouvons contourner ces restrictions en réécrivant la partie récursive pour numéroter les lignes candidates dans l'ordre requis, puis filtrer pour la ligne numérotée "un". Cela peut sembler un peu détourné, mais la logique est exactement la même :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Cette requête fait compile et produit le plan de post-exécution suivant :

Remarquez l'opérateur Top dans la partie récursive du plan d'exécution (en surbrillance). Nous ne pouvons pas écrire un TOP T-SQL dans la partie récursive d'une expression de table commune récursive, mais cela ne signifie pas que l'optimiseur ne peut pas en utiliser une ! L'optimiseur introduit le Top sur la base d'un raisonnement sur le nombre de lignes qu'il devra vérifier pour trouver celle numérotée "1".
Les performances de ce plan (non parallèle) sont bien meilleures que l'approche Stream Aggregate. Il se termine en environ 50 ms , avec 3007 lectures logiques par rapport à la table source (et 6 001 lignes lues à partir de la table de travail du spool), par rapport au meilleur précédent de 1 500 ms (8 764 ms de temps CPU à DOP 8) et 43 804 lectures logiques :


Conclusion
Il n'est pas toujours possible d'obtenir des percées dans les performances des requêtes en prenant en compte les éléments individuels du plan de requête seuls. Parfois, nous devons analyser la stratégie derrière l'ensemble du plan d'exécution, puis réfléchir latéralement pour trouver un algorithme et une mise en œuvre plus efficaces.