Je vois beaucoup de conseils là-bas qui disent quelque chose du genre :"Changez votre curseur pour une opération basée sur un ensemble ; cela le rendra plus rapide." Bien que cela puisse souvent être le cas, ce n'est pas toujours vrai. Un cas d'utilisation que je vois où un curseur surpasse à plusieurs reprises l'approche basée sur un ensemble typique est le calcul des totaux cumulés. En effet, l'approche basée sur les ensembles doit généralement examiner une partie des données sous-jacentes plus d'une fois, ce qui peut être une mauvaise chose de manière exponentielle à mesure que les données deviennent plus volumineuses ; alors qu'un curseur - aussi douloureux que cela puisse paraître - peut parcourir chaque ligne/valeur exactement une fois.
Ce sont nos options de base dans les versions les plus courantes de SQL Server. Dans SQL Server 2012, cependant, plusieurs améliorations ont été apportées aux fonctions de fenêtrage et à la clause OVER, principalement issues de plusieurs excellentes suggestions soumises par son collègue MVP Itzik Ben-Gan (voici l'une de ses suggestions). En fait, Itzik a un nouveau livre MS-Press qui couvre toutes ces améliorations de manière beaucoup plus détaillée, intitulé "Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions."
Alors naturellement, j'étais curieux; la nouvelle fonctionnalité de fenêtrage rendrait-elle les techniques de curseur et d'auto-jointure obsolètes ? Seraient-ils plus faciles à coder ? Seraient-ils plus rapides dans tous les cas (peu importe tous) ? Quelles autres approches pourraient être valables ?
La configuration
Pour faire quelques tests, configurons une base de données :
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO Et puis remplissez un tableau avec 10 000 lignes que nous pouvons utiliser pour effectuer des totaux cumulés. Rien de bien compliqué, juste un tableau récapitulatif avec une ligne pour chaque date et un nombre représentant le nombre de contraventions pour excès de vitesse émises. Je n'ai pas eu de contravention pour excès de vitesse depuis quelques années, donc je ne sais pas pourquoi c'était mon choix subconscient pour un modèle de données simpliste, mais c'est ainsi.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Résultats abrégés :
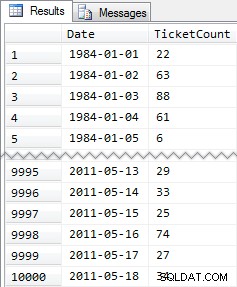
Encore une fois, 10 000 lignes de données assez simples - de petites valeurs INT et une série de dates de 1984 à mai 2011.
Les approches
Maintenant, ma mission est relativement simple et typique de nombreuses applications :renvoyer un ensemble de résultats contenant les 10 000 dates, ainsi que le total cumulé de toutes les contraventions pour excès de vitesse jusqu'à cette date incluse. La plupart des gens essaieraient d'abord quelque chose comme ça (nous appellerons cela la "jointure interne " méthode):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
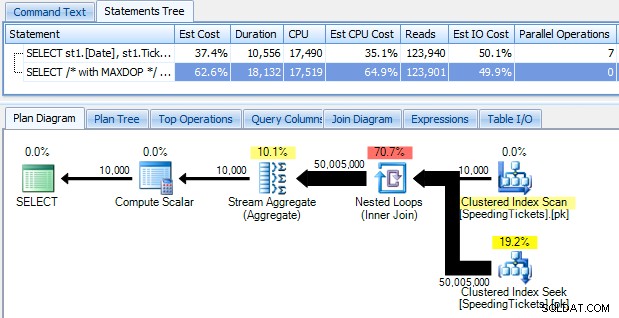
… et soyez choqué de découvrir qu'il faut près de 10 secondes pour courir. Examinons rapidement pourquoi en visualisant le plan d'exécution graphique, à l'aide de SQL Sentry Plan Explorer :

Les grosses flèches devraient donner une indication immédiate de ce qui se passe :la boucle imbriquée lit une ligne pour la première agrégation, deux lignes pour la seconde, trois lignes pour la troisième, et ainsi de suite sur l'ensemble des 10 000 lignes. Cela signifie que nous devrions voir environ ((10000 * (10000 + 1)) / 2) lignes traitées une fois que l'ensemble complet est parcouru, et cela semble correspondre au nombre de lignes indiqué dans le plan.
Notez que l'exécution de la requête sans parallélisme (à l'aide de l'indicateur de requête OPTION (MAXDOP 1)) simplifie un peu la forme du plan, mais n'aide pas du tout en termes de temps d'exécution ou d'E/S ; comme le montre le plan, la durée double en fait presque et les lectures ne diminuent que d'un très petit pourcentage. Par rapport au forfait précédent :
Il existe de nombreuses autres approches que les gens ont essayées pour obtenir des totaux cumulés efficaces. Un exemple est la "méthode de sous-requête " qui utilise simplement une sous-requête corrélée de la même manière que la méthode de jointure interne décrite ci-dessus :
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Comparaison de ces deux forfaits :
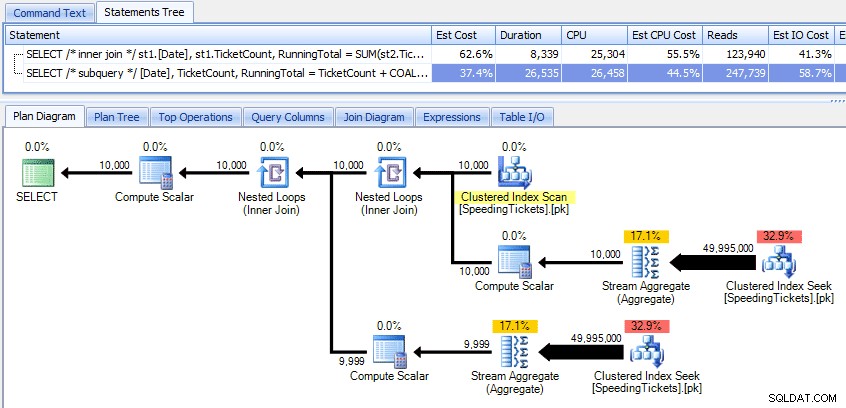
Ainsi, alors que la méthode de sous-requête semble avoir un plan global plus efficace, c'est pire là où c'est important :la durée et les E/S. Nous pouvons voir ce qui y contribue en creusant un peu plus les plans. En passant à l'onglet Top Operations, nous pouvons voir que dans la méthode de jointure interne, la recherche d'index clusterisé est exécutée 10 000 fois, et toutes les autres opérations ne sont exécutées que quelques fois. Cependant, plusieurs opérations sont exécutées 9 999 ou 10 000 fois dans la méthode subquery :
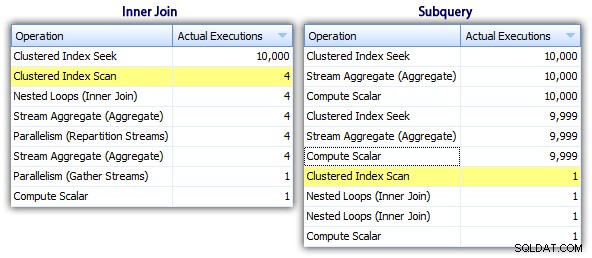
Ainsi, l'approche de sous-requête semble être pire, pas meilleure. La prochaine méthode que nous essaierons, j'appellerai la "mise à jour originale ". Ce n'est pas exactement garanti pour fonctionner, et je ne le recommanderais jamais pour le code de production, mais je l'inclus pour être complet. Fondamentalement, la mise à jour originale profite du fait que lors d'une mise à jour, vous pouvez rediriger les devoirs que la variable s'incrémente dans les coulisses à mesure que chaque ligne est mise à jour.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Je répète que je ne crois pas que cette approche soit sûre pour la production, quels que soient les témoignages que vous entendrez de personnes indiquant qu'elle "n'échoue jamais". À moins que le comportement ne soit documenté et garanti, j'essaie de rester à l'écart des hypothèses basées sur le comportement observé. Vous ne savez jamais quand une modification du chemin de décision de l'optimiseur (basée sur un changement de statistiques, un changement de données, un service pack, un indicateur de trace, un indice de requête, etc.) modifiera radicalement le plan et conduira potentiellement à un ordre différent. Si vous aimez vraiment cette approche non intuitive, vous pouvez vous sentir un peu mieux en utilisant l'option de requête FORCE ORDER (et cela essaiera d'utiliser une analyse ordonnée du PK, puisque c'est le seul index éligible sur la variable de table):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
Pour un peu plus de confiance à un coût d'E/S légèrement plus élevé, vous pouvez remettre en jeu la table d'origine et vous assurer que le PK de la table de base est utilisé :
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Personnellement, je ne pense pas que ce soit beaucoup plus garanti, car la partie SET de l'opération pourrait potentiellement influencer l'optimiseur indépendamment du reste de la requête. Encore une fois, je ne recommande pas cette approche, j'inclus simplement la comparaison par souci d'exhaustivité. Voici le plan de cette requête :
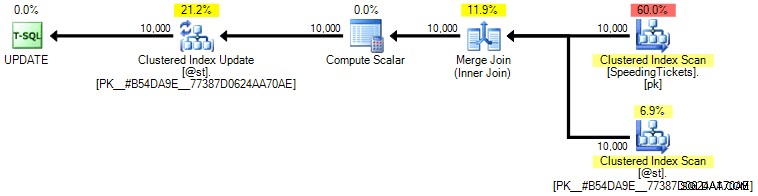
Sur la base du nombre d'exécutions que nous voyons dans l'onglet Top Operations (je vous épargne la capture d'écran ; c'est 1 pour chaque opération), il est clair que même si nous effectuons une jointure afin de nous sentir mieux dans la commande, le bizarre update permet de calculer les totaux cumulés en une seule passe de données. En la comparant aux requêtes précédentes, elle est beaucoup plus efficace, même si elle vide d'abord les données dans une variable de table et est séparée en plusieurs opérations :

Cela nous amène à un "CTE récursif ". Cette méthode utilise la valeur de date et repose sur l'hypothèse qu'il n'y a pas d'écarts. Puisque nous avons rempli ces données ci-dessus, nous savons qu'il s'agit d'une série entièrement contiguë, mais dans de nombreux scénarios, vous ne pouvez pas faire cela hypothèse. Ainsi, même si je l'ai inclus pour être complet, cette approche ne sera pas toujours valide. Dans tous les cas, cela utilise un CTE récursif avec la première date (connue) dans le tableau comme point d'ancrage, et le récursif portion déterminée en ajoutant un jour (en ajoutant l'option MAXRECURSION puisque nous savons exactement combien de lignes nous avons) :
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Cette requête fonctionne à peu près aussi efficacement que la méthode de mise à jour originale. Nous pouvons le comparer aux méthodes de sous-requête et de jointure interne :

Comme la méthode de mise à jour originale, je ne recommanderais pas cette approche CTE en production à moins que vous ne puissiez absolument garantir que votre colonne clé n'a pas de lacunes. Si vous avez des lacunes dans vos données, vous pouvez construire quelque chose de similaire en utilisant ROW_NUMBER(), mais cela ne sera pas plus efficace que la méthode d'auto-jointure ci-dessus.
Et puis nous avons le "curseur " approche :
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; … qui est beaucoup plus codé, mais contrairement à ce que l'opinion populaire pourrait suggérer, revient en 1 seconde. Nous pouvons voir pourquoi à partir de certains des détails du plan ci-dessus :la plupart des autres approches finissent par lire les mêmes données encore et encore, alors que l'approche du curseur lit chaque ligne une fois et conserve le total cumulé dans une variable au lieu de calculer la somme sur et encore. Nous pouvons le voir en examinant les déclarations capturées en générant un plan réel dans Plan Explorer :
Nous pouvons voir que plus de 20 000 déclarations ont été collectées, mais si nous trions par lignes estimées ou réelles décroissantes, nous constatons qu'il n'y a que deux opérations qui traitent plus d'une ligne. Ce qui est loin de quelques-unes des méthodes ci-dessus qui provoquent des lectures exponentielles en raison de la lecture répétée des mêmes lignes précédentes pour chaque nouvelle ligne.
Examinons maintenant les nouvelles améliorations de fenêtrage dans SQL Server 2012. En particulier, nous pouvons désormais calculer SUM OVER() et spécifier un ensemble de lignes par rapport à la ligne actuelle. Ainsi, par exemple :
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Il se trouve que ces deux requêtes donnent la même réponse, avec des totaux cumulés corrects. Mais fonctionnent-ils exactement de la même manière ? Les plans suggèrent que non. La version avec ROWS a un opérateur supplémentaire, un projet de séquence de 10 000 lignes :
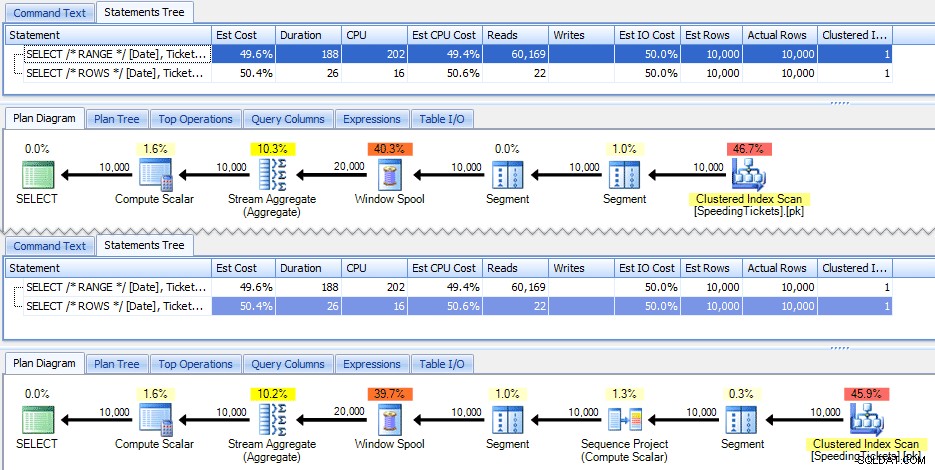
Et c'est à peu près l'ampleur de la différence dans le plan graphique. Mais si vous regardez d'un peu plus près les métriques d'exécution réelles, vous voyez des différences mineures dans la durée et le CPU, et une énorme différence dans les lectures. Pourquoi est-ce? Eh bien, c'est parce que RANGE utilise un spool sur disque, tandis que ROWS utilise un spool en mémoire. Avec de petits ensembles, la différence est probablement négligeable, mais le coût de la bobine sur disque peut certainement devenir plus apparent à mesure que les ensembles deviennent plus grands. Je ne veux pas gâcher la fin, mais vous pourriez penser que l'une de ces solutions fonctionnera mieux que l'autre lors d'un test plus approfondi.
Soit dit en passant, la version suivante de la requête donne les mêmes résultats, mais fonctionne comme la version RANGE plus lente ci-dessus :
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Donc, pendant que vous jouez avec les nouvelles fonctions de fenêtrage, vous voudrez garder à l'esprit de petites choses comme celle-ci :la version abrégée d'une requête, ou celle que vous avez écrite en premier, n'est pas nécessairement celle que vous voulez pour passer en production.
Les tests réels
Afin de mener des tests équitables, j'ai créé une procédure stockée pour chaque approche, et mesuré les résultats en capturant des instructions sur un serveur où je surveillais déjà avec SQL Sentry (si vous n'utilisez pas notre outil, vous pouvez collecter des événements SQL:BatchCompleted de la même manière en utilisant SQL Server Profiler).
Par "tests équitables", je veux dire que, par exemple, la méthode de mise à jour originale nécessite une mise à jour réelle des données statiques, ce qui signifie modifier le schéma sous-jacent ou utiliser une variable de table/table temporaire. J'ai donc structuré les procédures stockées pour créer chacune leur propre variable de table, et soit y stocker les résultats, soit y stocker les données brutes, puis mettre à jour le résultat. L'autre problème que je voulais éliminer était de renvoyer les données au client. Ainsi, les procédures ont chacune un paramètre de débogage spécifiant s'il faut renvoyer aucun résultat (valeur par défaut), top/bottom 5 ou all. Dans les tests de performances, je l'ai configuré pour qu'il ne renvoie aucun résultat, mais bien sûr, j'ai validé chacun pour m'assurer qu'ils renvoyaient les bons résultats.
Les procédures stockées sont toutes modélisées de cette façon (j'ai joint un script qui crée la base de données et les procédures stockées, donc j'inclus juste un modèle ici pour plus de brièveté) :
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO Et je les ai appelés dans un lot comme suit :
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Je me suis vite rendu compte que certains de ces appels n'apparaissaient pas dans Top SQL car le seuil par défaut est de 5 secondes. J'ai changé cela en 100 millisecondes (quelque chose que vous ne voulez jamais faire sur un système de production !) Comme suit :
Je le répète :ce comportement n'est pas toléré pour les systèmes de production !
J'ai toujours trouvé que l'une des commandes ci-dessus n'était pas interceptée par le seuil Top SQL; c'était la version Windowed_Rows. J'ai donc ajouté ce qui suit à ce lot uniquement :
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
Et maintenant, j'obtenais les 7 lignes renvoyées dans Top SQL. Ici, ils sont classés par utilisation du processeur en ordre décroissant :
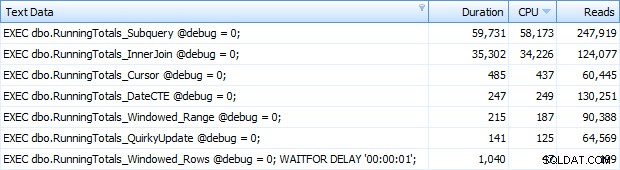
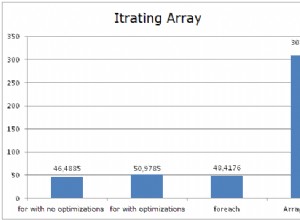
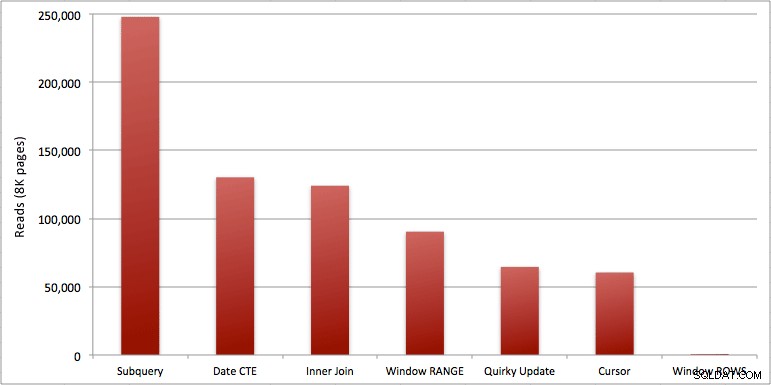
Vous pouvez voir la seconde supplémentaire que j'ai ajoutée au lot Windowed_Rows; il n'était pas pris par le seuil Top SQL car il s'est terminé en seulement 40 millisecondes ! C'est clairement notre meilleure performance et, si nous avons SQL Server 2012 disponible, ce devrait être la méthode que nous utilisons. Le curseur n'est pas non plus à moitié mauvais, compte tenu des performances ou d'autres problèmes avec les solutions restantes. Tracer la durée sur un graphique n'a pas beaucoup de sens - deux points hauts et cinq points bas indiscernables. Mais si les E/S sont votre goulot d'étranglement, vous pourriez trouver la visualisation des lectures intéressante :
Conclusion
De ces résultats, nous pouvons tirer quelques conclusions :
- Les agrégats fenêtrés dans SQL Server 2012 rendent les problèmes de performances liés aux calculs des totaux cumulés (et de nombreux autres problèmes de ligne(s) suivante(s)/ligne(s) précédente(s)) de manière alarmante plus efficaces. Quand j'ai vu le faible nombre de lectures, j'ai pensé qu'il y avait une sorte d'erreur, que j'avais dû oublier d'effectuer un travail. Mais non, vous obtenez le même nombre de lectures si votre procédure stockée effectue simplement un SELECT ordinaire à partir de la table SpeedingTickets. (N'hésitez pas à tester vous-même avec STATISTICS IO.)
- Les problèmes que j'ai signalés plus tôt à propos de RANGE vs. ROWS donnent des durées d'exécution légèrement différentes (différence de durée d'environ 6x - n'oubliez pas d'ignorer la seconde que j'ai ajoutée avec WAITFOR), mais les différences de lecture sont astronomiques en raison de la bobine sur disque. Si votre agrégat fenêtré peut être résolu à l'aide de ROWS, évitez RANGE, mais vous devez tester que les deux donnent le même résultat (ou au moins que ROWS donne la bonne réponse). Notez également que si vous utilisez une requête similaire et que vous ne spécifiez ni RANGE ni ROWS, le plan fonctionnera comme si vous aviez spécifié RANGE).
- Les méthodes de sous-requête et de jointure interne sont relativement catastrophiques. 35 secondes à une minute pour générer ces totaux cumulés ? Et c'était sur une seule table maigre sans renvoyer les résultats au client. Ces comparaisons peuvent être utilisées pour montrer aux gens pourquoi une solution purement basée sur un ensemble n'est pas toujours la meilleure réponse.
- Parmi les approches les plus rapides, en supposant que vous n'êtes pas encore prêt pour SQL Server 2012, et en supposant que vous ignorez à la fois la méthode de mise à jour originale (non prise en charge) et la méthode de date CTE (ne peut pas garantir une séquence contiguë), seul le curseur s'exécute acceptable. Il a la durée la plus élevée des solutions "plus rapides", mais le moins de lectures.
J'espère que ces tests aideront à mieux apprécier les améliorations de fenêtrage que Microsoft a ajoutées à SQL Server 2012. Assurez-vous de remercier Itzik si vous le voyez en ligne ou en personne, car il a été le moteur de ces changements. De plus, j'espère que cela aide à ouvrir certains esprits sur le fait qu'un curseur n'est pas toujours la solution maléfique et redoutée qu'il est souvent décrit.
(En tant qu'addendum, j'ai testé la fonction CLR offerte par Pavel Pawlowski, et les caractéristiques de performance étaient presque identiques à la solution SQL Server 2012 utilisant ROWS. Les lectures étaient identiques, le processeur était de 78 contre 47 et la durée globale était de 73 au lieu de 40. Donc, si vous n'allez pas passer à SQL Server 2012 dans un proche avenir, vous voudrez peut-être ajouter la solution de Pavel à vos tests.)
Pièces jointes :RunningTotals_Demo.sql.zip (2kb)