Mon collègue Steve Wright (blog | @SQL_Steve) m'a récemment posé une question sur un résultat étrange qu'il voyait. Afin de tester certaines fonctionnalités de notre dernier outil, SQL Sentry Plan Explorer PRO, il avait fabriqué une table large et volumineuse et exécutait diverses requêtes sur celle-ci. Dans un cas, il renvoyait beaucoup de données, mais STATISTICS IO montrait que très peu de lectures avaient lieu. J'ai envoyé un ping à certaines personnes sur #sqlhelp et, comme il semblait que personne n'avait vu ce problème, j'ai pensé bloguer à ce sujet.
TL;Version DR
En bref, sachez qu'il existe certains scénarios dans lesquels vous ne pouvez pas compter sur STATISTICS IO pour te dire la verité. Dans certains cas (celui-ci impliquant TOP et le parallélisme), il sous-déclarera largement les lectures logiques. Cela peut vous amener à croire que vous avez une requête très conviviale pour les E/S alors que ce n'est pas le cas. Il existe d'autres cas plus évidents, par exemple lorsque vous avez un tas d'E/S masquées par l'utilisation de fonctions scalaires définies par l'utilisateur. Nous pensons que Plan Explorer rend ces cas plus évidents; celui-ci, cependant, est un peu plus délicat.
La requête du problème
La table comporte 37 millions de lignes, jusqu'à 250 octets par ligne, environ 1 million de pages et une très faible fragmentation (0,42 % au niveau 0, 15 % au niveau 1 et 0 au-delà). Il n'y a pas de colonnes calculées, pas de FDU en jeu et pas d'index à l'exception d'une clé primaire en cluster sur le INT principal colonne. Une requête simple renvoyant 500 000 lignes, toutes les colonnes, en utilisant TOP et SELECT * :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029');
(Et oui, je me rends compte que je viole mes propres règles et que j'utilise SELECT * et TOP sans ORDER BY , mais par souci de simplicité, je fais de mon mieux pour minimiser mon influence sur l'optimiseur.)
Résultats :
(500000 ligne(s) affectée(s))Table 'OrderHistory'. Nombre de balayages 1, lectures logiques 23, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Nous renvoyons 500 000 lignes et cela prend environ 10 secondes. Je sais immédiatement que quelque chose ne va pas avec le nombre de lectures logiques. Même si je ne connaissais pas déjà les données sous-jacentes, je peux dire à partir des résultats de la grille dans Management Studio que cela extrait plus de 23 pages de données, qu'elles proviennent de la mémoire ou du cache, et cela devrait se refléter quelque part dans STATISTICS IO . En regardant le plan…
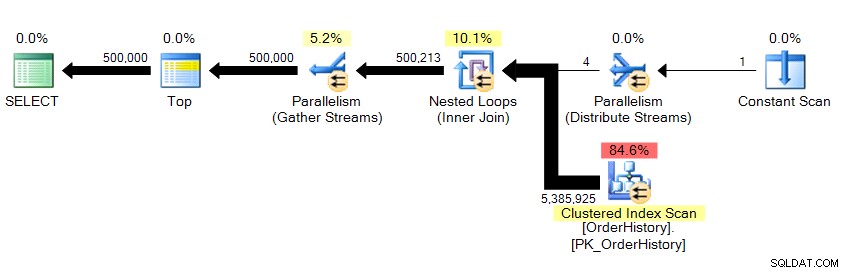
… nous voyons que le parallélisme est là, et que nous avons scanné toute la table. Alors, comment est-il possible qu'il n'y ait que 23 lectures logiques ?
Une autre requête "identique"
L'une de mes premières questions à Steve était :"Que se passe-t-il si vous éliminez le parallélisme ?" Alors je l'ai essayé. J'ai pris la version originale de la sous-requête et ajouté MAXDOP 1 :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);
Résultats et planification :
(500000 ligne(s) affectée(s))Table 'OrderHistory'. Nombre de balayages 1, lectures logiques 149589, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
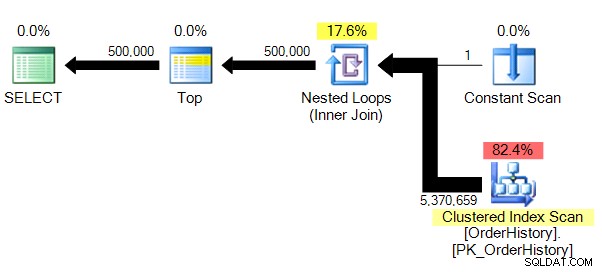
Nous avons un plan un peu moins complexe, et sans le parallélisme (pour des raisons évidentes), STATISTICS IO nous montre des nombres beaucoup plus crédibles pour le nombre de lectures logiques.
Quelle est la vérité ?
Il n'est pas difficile de voir que l'une de ces requêtes ne dit pas toute la vérité. Tandis que STATISTICS IO pourrait ne pas nous dire toute l'histoire, peut-être que la trace le fera. Si nous récupérons les métriques d'exécution en générant un plan d'exécution réel dans Plan Explorer, nous constatons que la requête magique à faible lecture extrait en fait les données de la mémoire ou du disque, et non d'un nuage de poussière de lutin magique. En fait, il a *plus* de lectures que l'autre version :

Il est donc clair que des lectures se produisent, elles n'apparaissent tout simplement pas correctement dans le STATISTICS IO sortie.
Quel est le problème ?
Eh bien, je vais être tout à fait honnête :je ne sais pas, à part le fait que le parallélisme joue définitivement un rôle, et cela semble être une sorte de condition de course. STATISTICS IO (et, puisque c'est là que nous obtenons les données, notre onglet Table I/O) affiche un nombre de lectures très trompeur. Il est clair que la requête renvoie toutes les données que nous recherchons, et il ressort clairement des résultats de trace qu'elle utilise des lectures et non une osmose pour le faire. J'ai posé la question à Paul White (blog | @SQL_Kiwi) à ce sujet et il a suggéré que seuls certains des nombres d'E/S pré-thread sont inclus dans le total (et convient qu'il s'agit d'un bogue).
Si vous voulez essayer cela à la maison, tout ce dont vous avez besoin est AdventureWorks (cela devrait être reproductible avec les versions 2008, 2008 R2 et 2012), et la requête suivante :
SET STATISTICS IO ON; DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS; GO SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101'); SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101') OPTION (MAXDOP 1); DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;
(Notez que SETCPUWEIGHT n'est utilisé que pour amadouer le parallélisme. Pour plus d'informations, consultez le billet de blog de Paul White sur l'établissement des coûts du plan.)
Résultats :
Tableau 'SalesOrderHeader'. Nombre de balayages 1, lectures logiques 4, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.Table 'SalesOrderHeader'. Nombre de balayages 1, lectures logiques 333, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Paul a souligné une reproduction encore plus simple :
SET STATISTICS IO ON; GO SELECT TOP (15000) * FROM Production.TransactionHistory WHERE TransactionDate < (SELECT '20080101') OPTION (QUERYTRACEON 8649, MAXDOP 4); SELECT TOP (15000) * FROM Production.TransactionHistory AS th WHERE TransactionDate < (SELECT '20080101');
Résultats :
Tableau 'Historique des transactions'. Nombre de balayages 1, lectures logiques 5, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.Table 'TransactionHistory'. Nombre de balayages 1, lectures logiques 110, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Il semble donc que l'on puisse facilement reproduire cela à volonté avec un TOP opérateur et un DOP suffisamment faible. J'ai signalé un bogue :
- STATISTICS IO sous-déclare les lectures logiques pour les plans parallèles
Et Paul a déposé deux autres bogues quelque peu liés impliquant le parallélisme, le premier à la suite de notre conversation :
- Erreur d'estimation de cardinalité avec prédicat poussé sur une recherche [article de blog associé]
- Performances médiocres avec parallélisme et Top [article de blog associé]
(Pour les nostalgiques, voici six autres bogues de parallélisme que j'ai signalés il y a quelques années.)
Quelle est la leçon ?
Soyez prudent lorsque vous faites confiance à une source unique. Si vous regardez uniquement STATISTICS IO après avoir modifié une requête comme celle-ci, vous pourriez être tenté de vous concentrer sur la baisse miraculeuse des lectures au lieu de l'augmentation de la durée. À ce stade, vous pouvez vous féliciter, quitter le travail tôt et profiter de votre week-end, en pensant que vous venez d'avoir un impact considérable sur les performances de votre requête. Quand bien sûr rien ne pourrait être plus éloigné de la vérité.



