Python et SQL sont deux des langages les plus importants pour les analystes de données.
Dans cet article, je vais vous expliquer tout ce que vous devez savoir pour connecter Python et SQL.
Vous apprendrez à extraire des données de bases de données relationnelles directement dans vos pipelines d'apprentissage automatique, à stocker les données de votre application Python dans votre propre base de données ou à tout autre cas d'utilisation que vous pourriez proposer.
Ensemble, nous couvrirons :
- Pourquoi apprendre à utiliser Python et SQL ensemble ?
- Comment configurer votre environnement Python et votre serveur MySQL
- Connexion au serveur MySQL en Python
- Création d'une nouvelle base de données
- Créer des tables et des relations entre tables
- Remplir des tableaux avec des données
- Lecture des données
- Mise à jour des enregistrements
- Suppression d'enregistrements
- Création d'enregistrements à partir de listes Python
- Créer des fonctions réutilisables pour faire tout cela pour nous à l'avenir
C'est beaucoup de choses très utiles et très cool. Allons-y !
Une note rapide avant de commencer :il existe un Jupyter Notebook contenant tout le code utilisé dans ce didacticiel disponible dans ce référentiel GitHub. Le codage est fortement recommandé !
La base de données et le code SQL utilisés ici proviennent tous de ma précédente série Introduction à SQL publiée sur Towards Data Science (contactez-moi si vous rencontrez des problèmes pour visualiser les articles et je peux vous envoyer un lien pour les voir gratuitement).
Si vous n'êtes pas familier avec SQL et les concepts derrière les bases de données relationnelles, je vous orienterais vers cette série (en plus, il y a bien sûr une énorme quantité de choses intéressantes disponibles ici sur freeCodeCamp !)
Pourquoi Python avec SQL ?
Pour les analystes de données et les scientifiques de données, Python présente de nombreux avantages. Une vaste gamme de bibliothèques open source en fait un outil incroyablement utile pour tout analyste de données.
Nous avons pandas, NumPy et Vaex pour l'analyse de données, Matplotlib, seaborn et Bokeh pour la visualisation, et TensorFlow, scikit-learn et PyTorch pour les applications d'apprentissage automatique (et bien d'autres encore).
Avec sa courbe d'apprentissage (relativement) facile et sa polyvalence, il n'est pas étonnant que Python soit l'un des langages de programmation à la croissance la plus rapide.
Donc, si nous utilisons Python pour l'analyse de données, cela vaut la peine de se demander - d'où viennent toutes ces données ?
Bien qu'il existe une grande variété de sources pour les ensembles de données, dans de nombreux cas - en particulier dans les entreprises - les données seront stockées dans une base de données relationnelle. Les bases de données relationnelles sont un moyen extrêmement efficace, puissant et largement utilisé pour créer, lire, mettre à jour et supprimer des données de toutes sortes.
Les systèmes de gestion de bases de données relationnelles (SGBDR) les plus largement utilisés - Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 - utilisent tous le langage de requête structuré (SQL) pour accéder aux données et y apporter des modifications.
Notez que chaque RDBMS utilise une saveur légèrement différente de SQL, donc le code SQL écrit pour l'un ne fonctionnera généralement pas dans un autre sans modifications (normalement assez mineures). Mais les concepts, les structures et les opérations sont largement identiques.
Cela signifie que pour un analyste de données en activité, une solide compréhension de SQL est extrêmement importante. Savoir utiliser Python et SQL ensemble vous donnera encore plus d'avantages lorsqu'il s'agira de travailler avec vos données.
Le reste de cet article sera consacré à vous montrer exactement comment nous pouvons faire cela.
Mise en route
Configuration requise et installation
Pour coder avec ce didacticiel, vous aurez besoin de votre propre environnement Python configuré.
J'utilise Anaconda, mais il existe de nombreuses façons de le faire. Recherchez simplement sur Google "comment installer Python" si vous avez besoin d'aide supplémentaire. Vous pouvez également utiliser Binder pour coder avec le Jupyter Notebook associé.
Nous utiliserons MySQL Community Server car il est gratuit et largement utilisé dans l'industrie. Si vous utilisez Windows, ce guide vous aidera à vous installer. Voici également des guides pour les utilisateurs Mac et Linux (bien que cela puisse varier selon la distribution Linux).
Une fois que vous les aurez configurés, nous devrons les faire communiquer entre eux.
Pour cela, nous devons installer la bibliothèque MySQL Connector Python. Pour ce faire, suivez les instructions ou utilisez simplement pip :
pip install mysql-connector-pythonNous allons également utiliser des pandas, alors assurez-vous de l'avoir également installé.
pip install pandasImporter des bibliothèques
Comme pour chaque projet en Python, la toute première chose que nous voulons faire est d'importer nos bibliothèques.
Il est recommandé d'importer toutes les bibliothèques que nous allons utiliser au début du projet, afin que les personnes qui lisent ou révisent notre code sachent à peu près ce qui s'en vient afin qu'il n'y ait pas de surprises.
Pour ce tutoriel, nous n'utiliserons que deux bibliothèques - MySQL Connector et pandas.
import mysql.connector
from mysql.connector import Error
import pandas as pdNous importons la fonction d'erreur séparément afin d'y avoir facilement accès pour nos fonctions.
Connexion au serveur MySQL
À ce stade, nous devrions avoir MySQL Community Server configuré sur notre système. Nous devons maintenant écrire du code en Python qui nous permet d'établir une connexion à ce serveur.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionLa création d'une fonction réutilisable pour un code comme celui-ci est la meilleure pratique, afin que nous puissions l'utiliser encore et encore avec un minimum d'effort. Une fois que ceci est écrit une fois que vous pouvez le réutiliser dans tous vos projets à l'avenir également, alors à l'avenir, vous en serez reconnaissant !
Passons en revue cette ligne par ligne afin que nous comprenions ce qui se passe ici :
La première ligne nous nomme la fonction (create_server_connection) et nomme les arguments que cette fonction prendra (host_name, user_name et user_password).
La ligne suivante ferme toutes les connexions existantes afin que le serveur ne soit pas confondu avec plusieurs connexions ouvertes.
Ensuite, nous utilisons un bloc Python try-except pour gérer les erreurs potentielles. La première partie essaie de créer une connexion au serveur en utilisant la méthode mysql.connector.connect() en utilisant les détails spécifiés par l'utilisateur dans les arguments. Si cela fonctionne, la fonction imprime un joyeux petit message de réussite.
La partie except du bloc imprime l'erreur renvoyée par le serveur MySQL, dans le cas malheureux où il y a une erreur.
Enfin, si la connexion réussit, la fonction renvoie un objet de connexion.
Nous l'utilisons en pratique en affectant la sortie de la fonction à une variable, qui devient alors notre objet de connexion. Nous pouvons ensuite lui appliquer d'autres méthodes (comme le curseur) et créer d'autres objets utiles.
connection = create_server_connection("localhost", "root", pw)Cela devrait produire un message de réussite :

Création d'une nouvelle base de données
Maintenant que nous avons établi une connexion, notre prochaine étape consiste à créer une nouvelle base de données sur notre serveur.
Dans ce didacticiel, nous ne le ferons qu'une seule fois, mais encore une fois, nous l'écrirons comme une fonction réutilisable afin d'avoir une fonction utile et agréable que nous pourrons réutiliser pour de futurs projets.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Cette fonction prend deux arguments, connection (notre objet de connexion) et query (une requête SQL que nous écrirons à l'étape suivante). Il exécute la requête dans le serveur via la connexion.
Nous utilisons la méthode du curseur sur notre objet de connexion pour créer un objet curseur (MySQL Connector utilise un paradigme de programmation orienté objet, il y a donc beaucoup d'objets héritant des propriétés des objets parents).
Cet objet curseur a des méthodes telles que execute, executemany (que nous utiliserons dans ce tutoriel) ainsi que plusieurs autres méthodes utiles.
Si cela peut aider, nous pouvons considérer l'objet curseur comme nous donnant accès au curseur clignotant dans une fenêtre de terminal du serveur MySQL.
Ensuite, nous définissons une requête pour créer la base de données et appelons la fonction :

Toutes les requêtes SQL utilisées dans ce didacticiel sont expliquées dans ma série de didacticiels Introduction à SQL, et le code complet peut être trouvé dans le bloc-notes Jupyter associé dans ce référentiel GitHub, donc je ne fournirai pas d'explications sur ce que fait le code SQL dans ce tutoriel.
C'est peut-être la requête SQL la plus simple possible. Si vous pouvez lire l'anglais, vous pouvez probablement comprendre ce qu'il fait !
L'exécution de la fonction create_database avec les arguments ci-dessus entraîne la création d'une base de données appelée "école" sur notre serveur.
Pourquoi notre base de données s'appelle-t-elle 'école' ? Ce serait peut-être le bon moment pour examiner plus en détail exactement ce que nous allons implémenter dans ce didacticiel.
Notre base de données
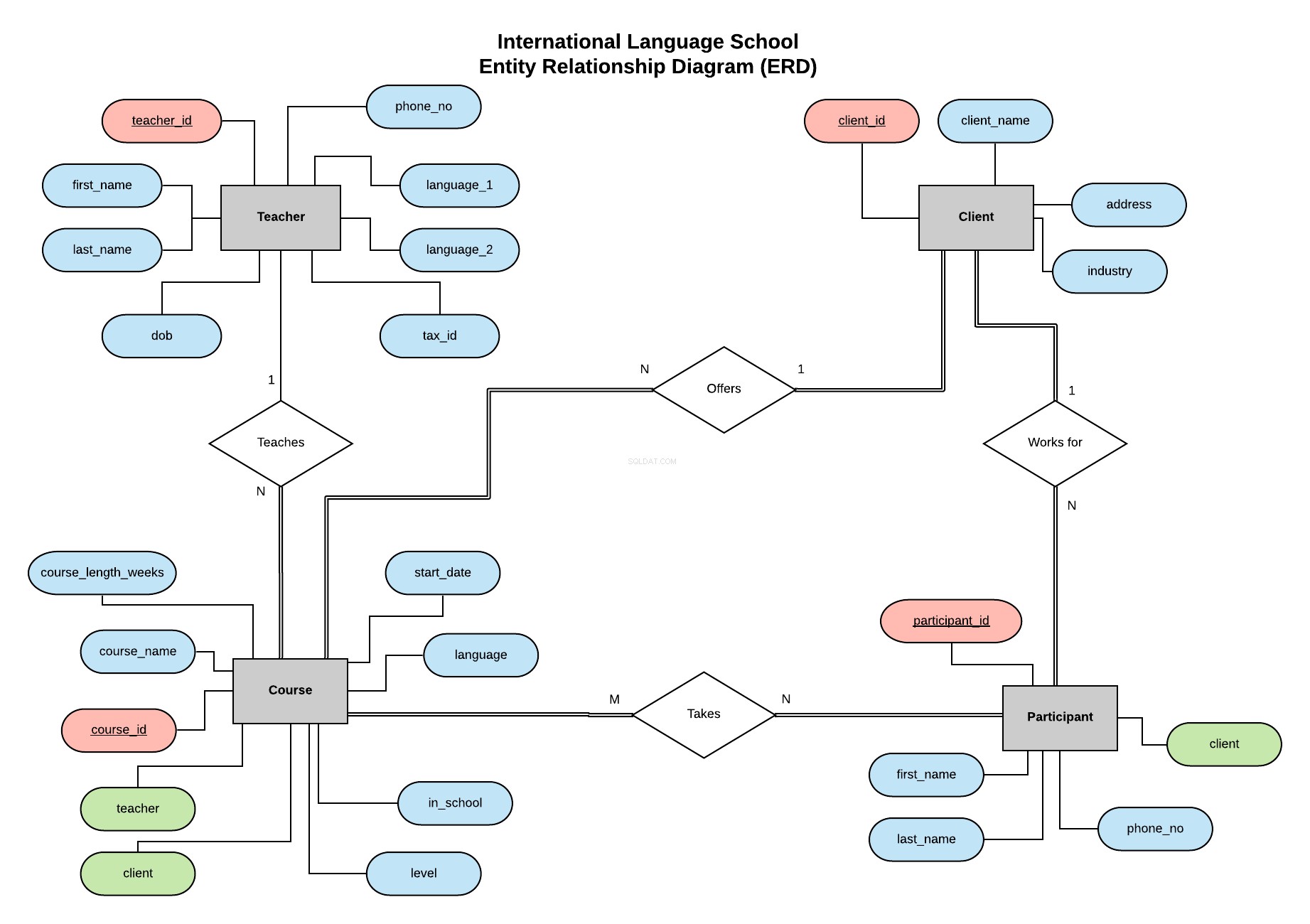
Suivant l'exemple de ma série précédente, nous allons implémenter la base de données de l'International Language School - une école de formation linguistique fictive qui propose des cours de langue professionnelle aux entreprises clientes.
Ce diagramme de relation d'entité (ERD) présente nos entités (enseignant, client, cours et participant) et définit les relations entre elles.
Toutes les informations concernant ce qu'est un ERD et ce qu'il faut prendre en compte lors de sa création et de la conception d'une base de données se trouvent dans cet article.
Le code SQL brut, les exigences de la base de données et les données à insérer dans la base de données sont tous contenus dans ce référentiel GitHub, mais vous le verrez également tout au long de ce didacticiel.
Connexion à la base de données
Maintenant que nous avons créé une base de données dans MySQL Server, nous pouvons modifier notre fonction create_server_connection pour nous connecter directement à cette base de données.
Notez qu'il est possible - courant, en fait - d'avoir plusieurs bases de données sur un serveur MySQL, nous voulons donc toujours et automatiquement nous connecter à la base de données qui nous intéresse.
Nous pouvons le faire comme suit :
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionC'est exactement la même fonction, mais maintenant nous prenons un argument de plus - le nom de la base de données - et le passons comme argument à la méthode connect().
Création d'une fonction d'exécution de requête
La fonction finale que nous allons créer (pour l'instant) est extrêmement vitale - une fonction d'exécution de requête. Cela va prendre nos requêtes SQL, stockées en Python sous forme de chaînes, et les transmettre à la méthode cursor.execute() pour les exécuter sur le serveur.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Cette fonction est exactement la même que notre fonction create_database précédente, sauf qu'elle utilise la méthode connection.commit() pour s'assurer que les commandes détaillées dans nos requêtes SQL sont implémentées.
Cela va être notre fonction de cheval de bataille, que nous utiliserons (aux côtés de create_db_connection) pour créer des tables, établir des relations entre ces tables, remplir les tables avec des données et mettre à jour et supprimer des enregistrements dans notre base de données.
Si vous êtes un expert SQL, cette fonction vous permettra d'exécuter toutes les commandes et requêtes complexes que vous pourriez avoir, directement à partir d'un script Python. Cela peut être un outil très puissant pour gérer vos données.
Créer des tableaux
Nous sommes maintenant prêts à commencer à exécuter des commandes SQL sur notre serveur et à commencer à créer notre base de données. La première chose que nous voulons faire est de créer les tables nécessaires.
Commençons par notre tableau Enseignant :
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryTout d'abord, nous attribuons notre commande SQL (expliquée en détail ici) à une variable avec un nom approprié.
Dans ce cas, nous utilisons la notation entre guillemets triples de Python pour les chaînes multilignes pour stocker notre requête SQL, puis nous l'alimentons dans notre fonction execute_query pour l'implémenter.
Notez que ce formatage multiligne est purement pour le bénéfice des humains qui lisent notre code. Ni SQL ni Python ne s'en soucient si la commande SQL est répartie comme ceci. Tant que la syntaxe est correcte, les deux langues l'accepteront.
Pour le bénéfice des humains qui liront votre code, cependant (même si ce ne sera que le futur-vous !), il est très utile de le faire pour rendre le code plus lisible et compréhensible.
Il en va de même pour la CAPITALISATION des opérateurs en SQL. Il s'agit d'une convention largement utilisée qui est fortement recommandée, mais le logiciel réel qui exécute le code est insensible à la casse et traitera 'CREATE TABLE teacher' et 'create table teacher' comme des commandes identiques.

L'exécution de ce code nous donne nos messages de réussite. Nous pouvons également le vérifier dans le client de ligne de commande du serveur MySQL :
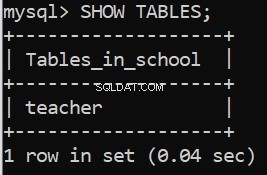
Génial! Créons maintenant les tables restantes.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Cela crée les quatre tables nécessaires à nos quatre entités.
Nous voulons maintenant définir les relations entre eux et créer une table supplémentaire pour gérer la relation plusieurs-à-plusieurs entre les tables des participants et des cours (voir ici pour plus de détails).
Nous procédons exactement de la même manière :
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Nos tables sont maintenant créées, ainsi que les contraintes appropriées, la clé primaire et les relations de clé étrangère.
Remplir les tableaux
L'étape suivante consiste à ajouter des enregistrements aux tables. Encore une fois, nous utilisons execute_query pour alimenter nos commandes SQL existantes dans le serveur. Recommençons avec la table Enseignant.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)Est-ce que ça marche? Nous pouvons vérifier à nouveau dans notre client de ligne de commande MySQL :
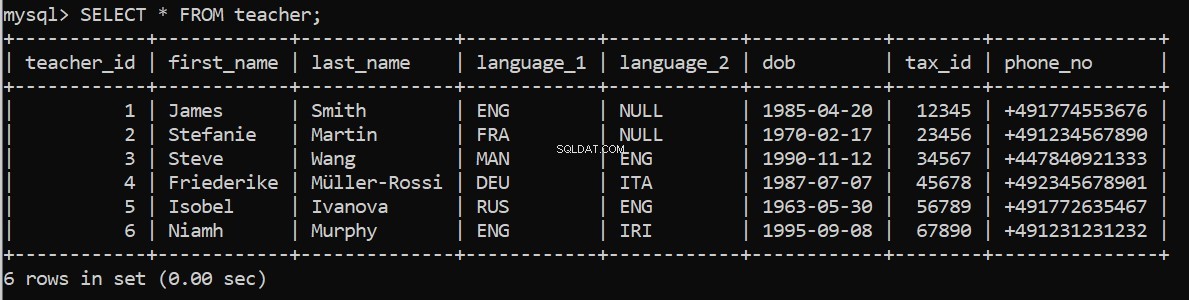
Maintenant, remplissez les tables restantes.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Étonnante! Nous avons maintenant créé une base de données complète avec des relations, des contraintes et des enregistrements dans MySQL, en utilisant uniquement des commandes Python.
Nous avons suivi cette étape par étape pour que cela reste compréhensible. Mais à ce stade, vous pouvez voir que tout cela pourrait très facilement être écrit dans un script Python et exécuté en une seule commande dans le terminal. Des trucs puissants.
Lecture des données
Nous avons maintenant une base de données fonctionnelle avec laquelle travailler. En tant qu'analyste de données, vous êtes susceptible d'entrer en contact avec des bases de données existantes dans les organisations où vous travaillez. Il sera très utile de savoir comment extraire des données de ces bases de données afin qu'elles puissent ensuite être introduites dans votre pipeline de données python. C'est ce sur quoi nous allons travailler ensuite.
Pour cela, nous aurons besoin d'une fonction supplémentaire, cette fois en utilisant curseur.fetchall() au lieu de curseur.commit(). Avec cette fonction, nous lisons les données de la base de données et n'apporterons aucune modification.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Encore une fois, nous allons implémenter cela d'une manière très similaire à execute_query. Essayons-le avec une requête simple pour voir comment cela fonctionne.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)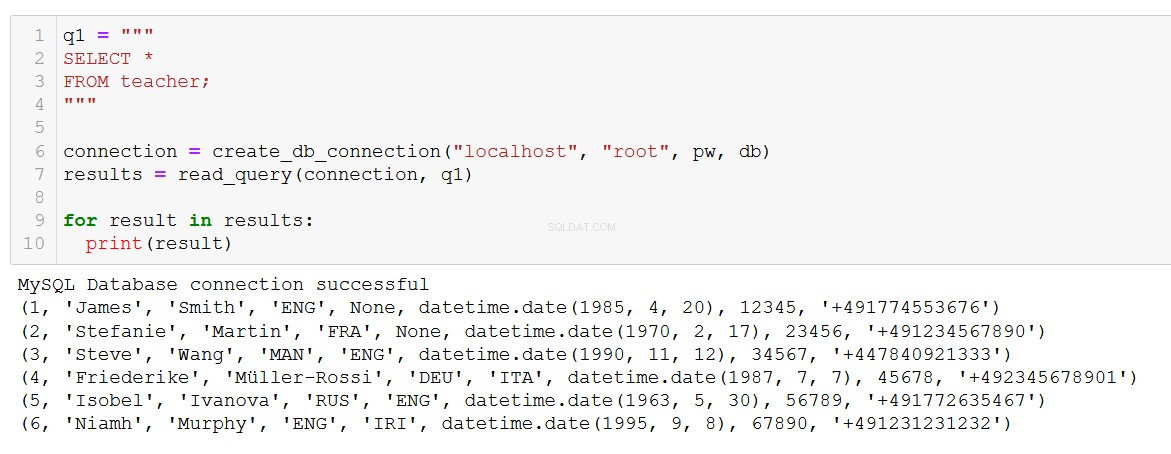
Exactement ce que nous attendons. La fonction fonctionne également avec des requêtes plus complexes, comme celle-ci impliquant un JOIN sur les tables course et client.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)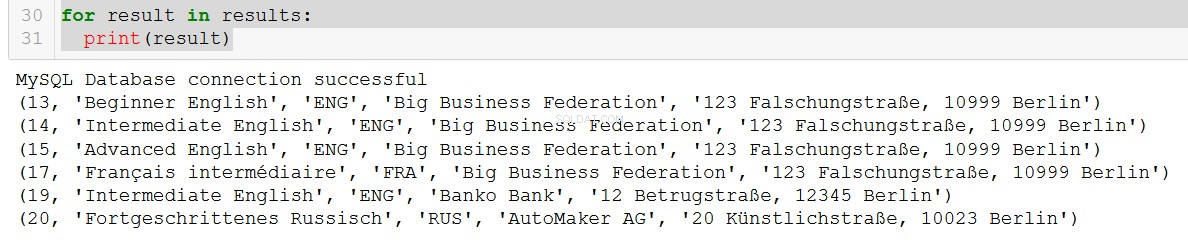
Très beau.
Pour nos pipelines de données et nos workflows en Python, nous souhaiterons peut-être obtenir ces résultats dans différents formats pour les rendre plus utiles ou prêts à être manipulés.
Passons en revue quelques exemples pour voir comment nous pouvons faire cela.
Formater la sortie dans une liste
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Formater la sortie dans une liste de listes
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Formatage de la sortie dans un pandas DataFrame
Pour les analystes de données utilisant Python, pandas est notre vieil ami magnifique et de confiance. Il est très simple de convertir la sortie de notre base de données en un DataFrame, et à partir de là, les possibilités sont infinies !
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)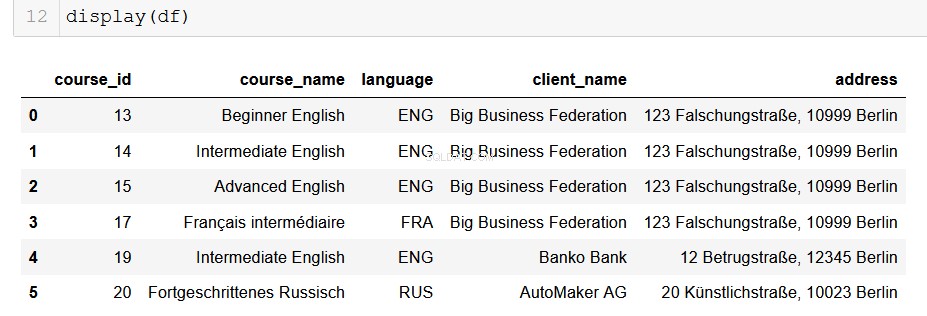
J'espère que vous pouvez voir les possibilités qui se déroulent devant vous ici. Avec seulement quelques lignes de code, nous pouvons facilement extraire toutes les données que nous pouvons gérer des bases de données relationnelles où elles se trouvent et les insérer dans nos pipelines d'analyse de données à la pointe de la technologie. C'est vraiment utile.
Mise à jour des enregistrements
Lorsque nous maintenons une base de données, nous devrons parfois apporter des modifications aux enregistrements existants. Dans cette section, nous allons voir comment procéder.
Supposons que l'ILS soit informé que l'un de ses clients existants, la Big Business Federation, déménage ses bureaux au 23 Fingiertweg, 14534 Berlin. Dans ce cas, l'administrateur de la base de données (c'est nous !) devra faire quelques changements.
Heureusement, nous pouvons le faire avec notre fonction execute_query aux côtés de l'instruction SQL UPDATE.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Notez que la clause WHERE est très importante ici. Si nous exécutons cette requête sans la clause WHERE, toutes les adresses de tous les enregistrements de notre table Client seront mises à jour sur 23 Fingiertweg. Ce n'est vraiment pas ce que nous cherchons à faire.
Notez également que nous avons utilisé "WHERE client_id =101" dans la requête UPDATE. Il aurait également été possible d'utiliser "WHERE client_name ='Big Business Federation'" ou "WHERE address ='123 Falschungstraße, 10999 Berlin'" ou encore "WHERE address LIKE '%Falschung%'".
L'important est que la clause WHERE nous permette d'identifier de manière unique l'enregistrement (ou les enregistrements) que nous voulons mettre à jour.
Suppression d'enregistrements
Il est également possible d'utiliser notre fonction execute_query pour supprimer des enregistrements, en utilisant DELETE.
Lors de l'utilisation de SQL avec des bases de données relationnelles, nous devons être prudents en utilisant l'opérateur DELETE. Ce n'est pas Windows, il n'y a pas de "Êtes-vous sûr de vouloir supprimer ceci?" pop-up d'avertissement, et il n'y a pas de bac de recyclage. Une fois que nous supprimons quelque chose, il est vraiment parti.
Cela dit, nous avons vraiment besoin de supprimer des choses parfois. Jetons donc un coup d'œil à cela en supprimant un cours de notre table Course.
Tout d'abord, rappelons-nous quels cours nous avons.
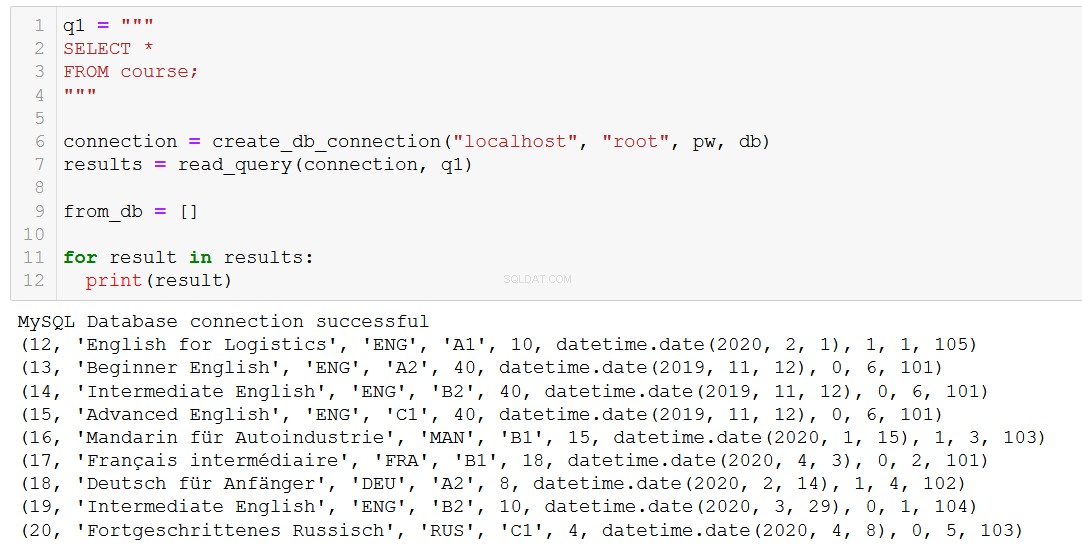
Disons que le cours 20, "Fortgeschrittenes Russisch" (c'est-à-dire "Russe avancé" pour vous et moi), touche à sa fin, nous devons donc le supprimer de notre base de données.
À ce stade, vous ne serez pas du tout surpris de la façon dont nous procédons :enregistrez la commande SQL sous forme de chaîne, puis introduisez-la dans notre fonction performante execute_query.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Vérifions pour confirmer que cela a eu l'effet escompté :
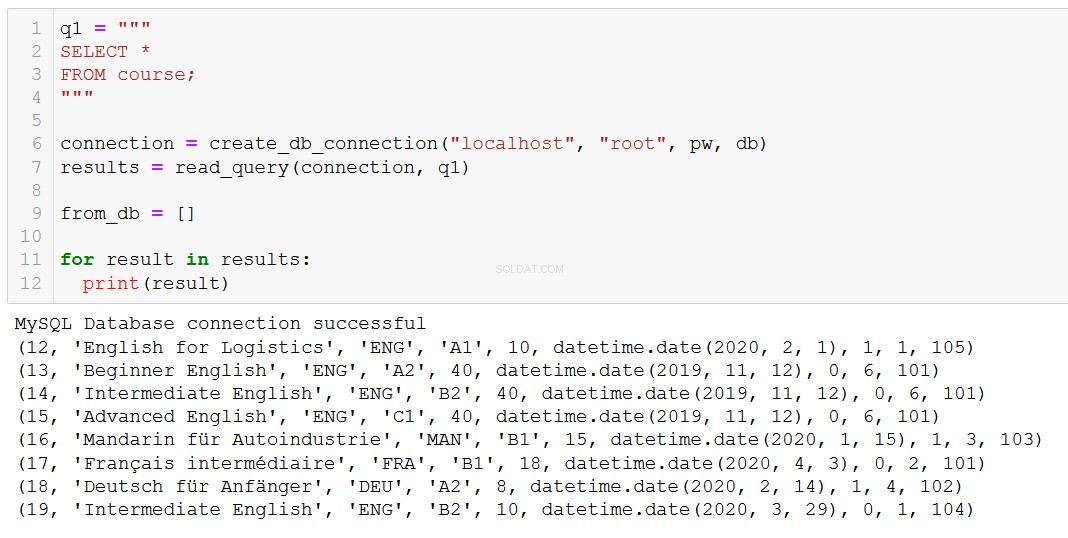
Le « russe avancé » a disparu, comme nous nous y attendions.
Cela fonctionne également avec la suppression de colonnes entières à l'aide de DROP COLUMN et de tables entières à l'aide des commandes DROP TABLE, mais nous ne les couvrirons pas dans ce didacticiel.
Allez-y et expérimentez-les, cependant - peu importe que vous supprimiez une colonne ou une table d'une base de données pour une école fictive, et c'est une bonne idée de vous familiariser avec ces commandes avant de passer à un environnement de production.
Oh CRUD
À ce stade, nous sommes maintenant en mesure de terminer les quatre opérations principales pour le stockage de données persistantes.
Nous avons appris à :
- Créer :des bases de données, des tables et des enregistrements entièrement nouveaux
- Lire :extraire des données d'une base de données et stocker ces données dans plusieurs formats
- Mettre à jour :apporter des modifications aux enregistrements existants dans la base de données
- Supprimer - supprimer les enregistrements qui ne sont plus nécessaires
Ce sont des choses incroyablement utiles à faire.
Avant de terminer ici, nous avons encore une compétence très pratique à apprendre.
Création d'enregistrements à partir de listes
Nous avons vu lors du remplissage de nos tables que nous pouvions utiliser la commande SQL INSERT dans notre fonction execute_query pour insérer des enregistrements dans notre base de données.
Étant donné que nous utilisons Python pour manipuler notre base de données SQL, il serait utile de pouvoir prendre une structure de données Python (comme une liste) et de l'insérer directement dans notre base de données.
Cela peut être utile lorsque nous voulons stocker les journaux d'activité des utilisateurs sur une application de médias sociaux que nous avons écrite en Python, ou les entrées des utilisateurs dans un Wiki que nous avons construit, par exemple. Il y a autant d'utilisations possibles pour cela que vous pouvez penser.
Cette méthode est également plus sécurisée si notre base de données est ouverte à nos utilisateurs à tout moment, car elle aide à prévenir les attaques par injection SQL, qui peuvent endommager ou même détruire l'ensemble de notre base de données.
Pour ce faire, nous allons écrire une fonction en utilisant la méthode executemany(), au lieu de la méthode execute() plus simple que nous avons utilisée jusqu'à présent.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Maintenant que nous avons la fonction, nous devons définir une commande SQL ('sql') et une liste contenant les valeurs que nous souhaitons entrer dans la base de données ('val'). Les valeurs doivent être stockées sous forme de liste de tuples, ce qui est une manière assez courante de stocker des données en Python.
Pour ajouter deux nouveaux enseignants à la base de données, nous pouvons écrire un code comme celui-ci :
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Notez ici que dans le code 'sql', nous utilisons le '%s' comme espace réservé pour notre valeur. La ressemblance avec l'espace réservé '%s' pour une chaîne en python est juste une coïncidence (et franchement, très déroutante), nous voulons utiliser '%s' pour tous les types de données (chaînes, entiers, dates, etc.) avec MySQL Python Connecteur.
Vous pouvez voir un certain nombre de questions sur Stackoverflow où quelqu'un est devenu confus et a essayé d'utiliser des espaces réservés '%d' pour les entiers parce qu'ils ont l'habitude de le faire en Python. Cela ne fonctionnera pas ici - nous devons utiliser un '%s' pour chaque colonne à laquelle nous voulons ajouter une valeur.
La fonction executemany prend ensuite chaque tuple de notre liste 'val' et insère la valeur pertinente pour cette colonne à la place de l'espace réservé et exécute la commande SQL pour chaque tuple contenu dans la liste.
Cela peut être effectué pour plusieurs lignes de données, tant qu'elles sont correctement formatées. Dans notre exemple, nous allons simplement ajouter deux nouveaux enseignants, à titre indicatif, mais en principe, nous pouvons en ajouter autant que nous le souhaitons.
Allons-y, exécutons cette requête et ajoutons les enseignants à notre base de données.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)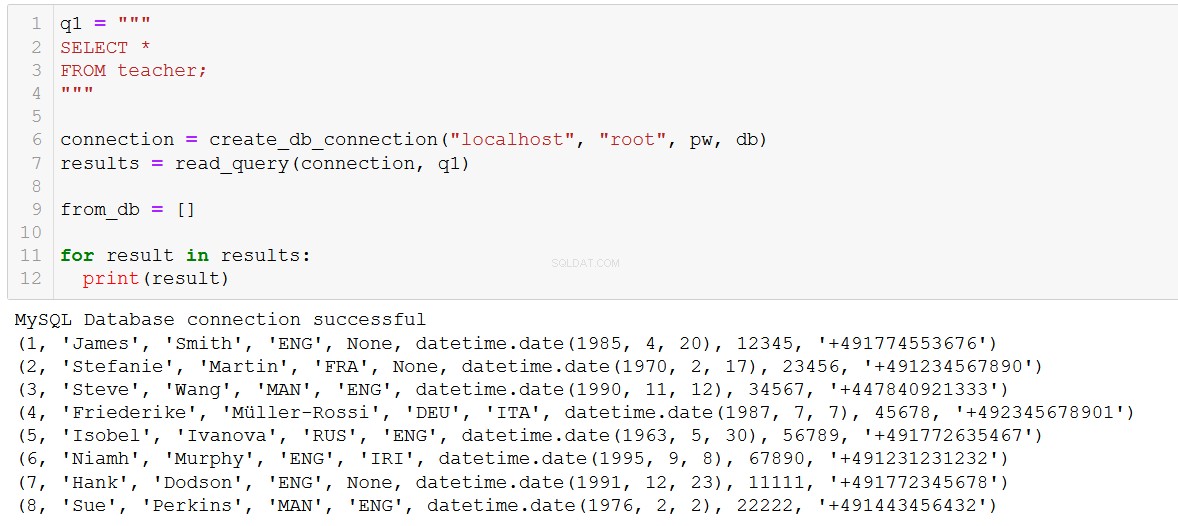
Bienvenue à l'ILS, Hank et Sue !
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Conclusion
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!