Il est établi depuis longtemps que les variables de table avec un grand nombre de lignes peuvent être problématiques, car l'optimiseur les considère toujours comme ayant une seule ligne. Sans recompilation après que la variable de table a été renseignée (car avant cela, elle est vide), il n'y a pas de cardinalité pour la table et les recompilations automatiques ne se produisent pas car les variables de table ne sont même pas soumises à un seuil de recompilation. Les plans sont donc basés sur une cardinalité de table de zéro, pas un, mais le minimum est augmenté à un comme le décrit Paul White (@SQL_Kiwi) dans cette réponse dba.stackexchange.
La façon dont nous pouvons généralement contourner ce problème consiste à ajouter OPTION (RECOMPILE) à la requête référençant la variable de table, forçant l'optimiseur à inspecter la cardinalité de la variable de table après qu'elle a été renseignée. Pour éviter d'avoir à modifier manuellement chaque requête pour ajouter un indice de recompilation explicite, un nouvel indicateur de trace (2453) a été introduit dans SQL Server 2012 Service Pack 2 et SQL Server 2014 Cumulative Update #3 :
- KB #2952444 :CORRECTIF :performances médiocres lorsque vous utilisez des variables de table dans SQL Server 2012 ou SQL Server 2014
Lorsque l'indicateur de trace 2453 est actif, l'optimiseur peut obtenir une image précise de la cardinalité de table après la création de la variable de table. Cela peut être une bonne chose ™ pour de nombreuses requêtes, mais probablement pas toutes, et vous devez savoir en quoi cela fonctionne différemment de OPTION (RECOMPILE) . Plus particulièrement, l'optimisation d'intégration de paramètres dont parle Paul White dans ce post se produit sous OPTION (RECOMPILE) , mais pas sous ce nouvel indicateur de trace.
Un test simple
Mon test initial consistait simplement à remplir une variable de table et à la sélectionner ; cela a donné le nombre de lignes estimé bien trop familier de 1. Voici le test que j'ai exécuté (et j'ai ajouté l'indice de recompilation pour comparer) :
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, t.name FROM @t AS t; SELECT t.id, t.name FROM @t AS t OPTION (RECOMPILE); DBCC TRACEOFF(2453);
En utilisant SQL Sentry Plan Explorer, nous pouvons voir que le plan graphique pour les deux requêtes dans ce cas est identique, probablement au moins en partie parce qu'il s'agit littéralement d'un plan trivial :

Plan graphique pour une analyse d'index triviale contre @t
Cependant, les estimations ne sont pas les mêmes. Même si l'indicateur de trace est activé, nous obtenons toujours une estimation de 1 provenant de l'analyse de l'index si nous n'utilisons pas l'indicateur de recompilation :
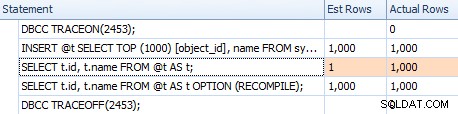
Comparer les estimations d'un plan trivial dans la grille des déclarations
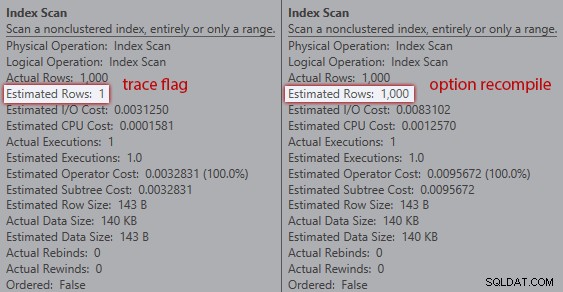
Comparaison des estimations entre l'indicateur de trace (à gauche) et la recompilation (à droite)
Si vous m'avez déjà rencontré en personne, vous pouvez probablement imaginer le visage que j'ai fait à ce stade. J'ai pensé avec certitude que soit l'article de la base de connaissances mentionnait le mauvais numéro d'indicateur de trace, soit que j'avais besoin d'un autre paramètre activé pour qu'il soit vraiment actif.
Benjamin Nevarez (@BenjaminNevarez) m'a rapidement fait remarquer que je devais regarder de plus près l'article de la base de connaissances "Bogues corrigés dans SQL Server 2012 Service Pack 2". Bien qu'ils aient masqué le texte derrière une puce masquée sous Highlights > Relational Engine, l'article de la liste de correctifs décrit légèrement mieux le comportement de l'indicateur de trace que l'article d'origine (c'est moi qui souligne) :
Si une variable de table est jointe à d'autres tables dans SQL Server, cela peut entraîner un ralentissement des performances en raison d'une sélection de plan de requête inefficace, car SQL Server ne prend pas en charge les statistiques ou ne suit pas le nombre de lignes dans une variable de table lors de la compilation d'un plan de requête.Il semblerait donc d'après cette description que l'indicateur de trace ne vise à résoudre le problème que lorsque la variable de table participe à une jointure. (Pourquoi cette distinction n'est pas faite dans l'article original, je n'en ai aucune idée.) t même essayer de faire quoi que ce soit dans ce cas. Mais cela se déclenchera si une optimisation basée sur les coûts est effectuée, même sans jointure ; l'indicateur de trace n'a tout simplement aucun effet sur les plans triviaux. Voici un exemple de plan non trivial qui n'implique pas de jointure :
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID(); SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID() OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Ce plan n'est plus anodin; l'optimisation est marquée comme complète. La majeure partie du coût est transférée à un opérateur de tri :
Plan graphique moins trivial
Et les estimations s'alignent pour les deux requêtes (je vous épargnerai les info-bulles cette fois-ci, mais je peux vous assurer qu'elles sont identiques) :

Grille d'instructions pour les plans moins triviaux avec et sans l'indice de recompilation
Il semble donc que l'article de la base de connaissances ne soit pas tout à fait exact - j'ai pu contraindre le comportement attendu de l'indicateur de trace sans introduire de jointure. Mais je veux aussi le tester avec une jointure.
Un meilleur test
Prenons cet exemple simple, avec et sans l'indicateur de trace :
--DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; --DBCC TRACEOFF(2453);
Sans l'indicateur de trace, l'optimiseur estime qu'une ligne proviendra du parcours d'index par rapport à la variable de table. Cependant, avec l'indicateur de trace activé, il obtient les 1 000 lignes :
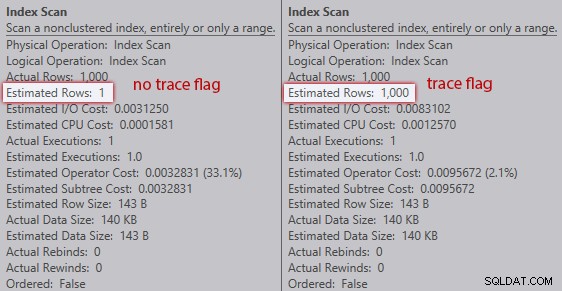
Comparaison des estimations d'analyse d'index (pas d'indicateur de trace à gauche, drapeau de trace à droite)
Les différences ne s'arrêtent pas là. Si nous y regardons de plus près, nous pouvons voir une variété de décisions différentes prises par l'optimiseur, toutes issues de ces meilleures estimations :
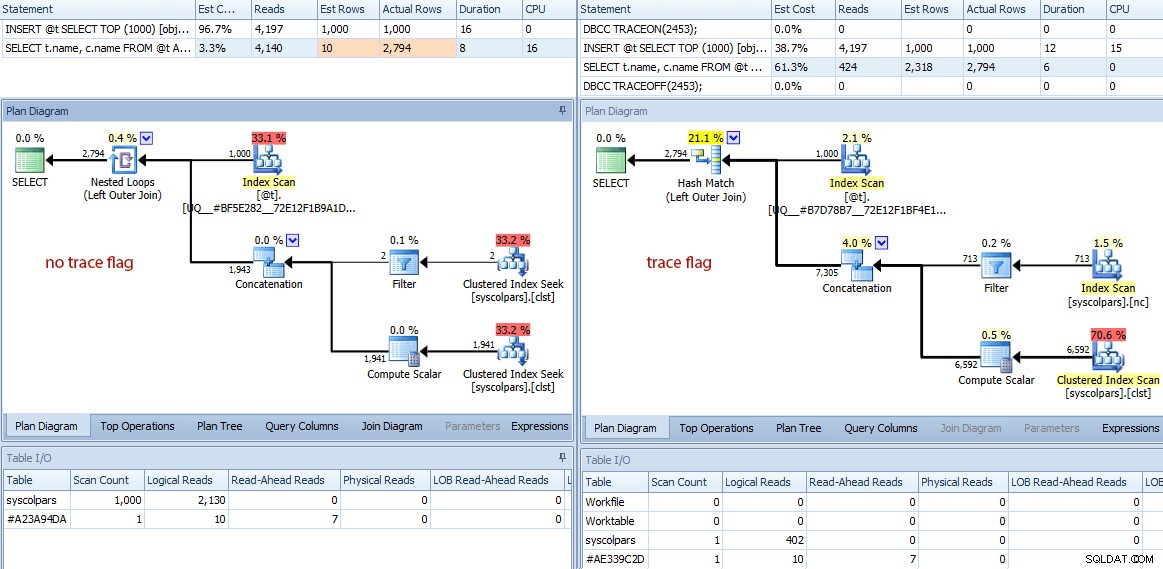
Comparaison des plans (pas d'indicateur de trace à gauche, indicateur de trace à droite)
Un résumé rapide des différences :
- La requête sans l'indicateur de trace a effectué 4 140 opérations de lecture, tandis que la requête avec l'estimation améliorée n'en a effectué que 424 (une réduction d'environ 90 %).
- L'optimiseur a estimé que l'ensemble de la requête renverrait 10 lignes sans l'indicateur de trace, et 2 318 lignes beaucoup plus précises avec l'indicateur de trace.
- Sans l'indicateur de trace, l'optimiseur a choisi d'effectuer une jointure de boucles imbriquées (ce qui est logique lorsque l'une des entrées est estimée être très petite). Cela a conduit l'opérateur de concaténation et les deux recherches d'index à s'exécuter 1 000 fois, contrairement à la correspondance de hachage choisie sous l'indicateur de trace, où l'opérateur de concaténation et les deux analyses ne s'exécutent qu'une seule fois.
- L'onglet Table I/O affiche également 1 000 balayages (balayages de plage déguisés en recherches d'index) et un nombre de lectures logiques beaucoup plus élevé par rapport à
syscolpars(la table système derrièresys.all_columns). - Bien que la durée n'ait pas été significativement affectée (24 millisecondes contre 18 millisecondes), vous pouvez probablement imaginer le type d'impact que ces autres différences pourraient avoir sur une requête plus sérieuse.
- Si nous basculons le diagramme vers les coûts estimés, nous pouvons voir à quel point la variable de table peut être très différente pour tromper l'optimiseur sans l'indicateur de trace :
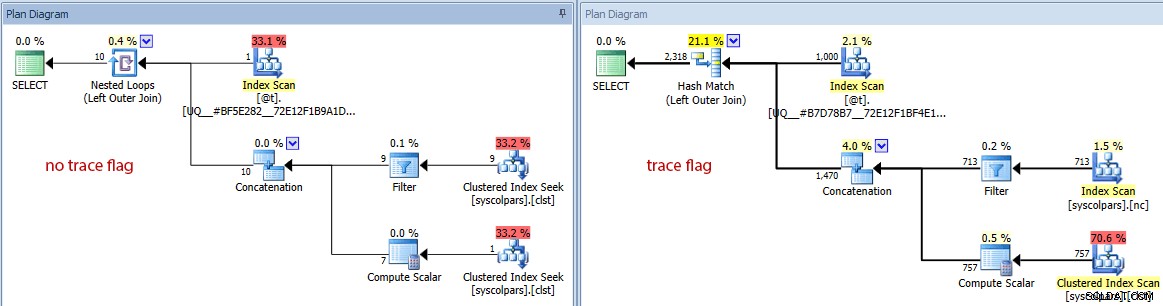
Comparaison du nombre de lignes estimé (pas d'indicateur de trace à gauche, trace drapeau à droite)
Il est clair et non choquant que l'optimiseur réussisse mieux à sélectionner le bon plan lorsqu'il a une vue précise de la cardinalité impliquée. Mais à quel prix ?
Recompilation et surcharge
Lorsque nous utilisons OPTION (RECOMPILE) avec le lot ci-dessus, sans l'indicateur de trace activé, nous obtenons le plan suivant - qui est à peu près identique au plan avec l'indicateur de trace (la seule différence notable étant que les lignes estimées sont de 2 316 au lieu de 2 318) :
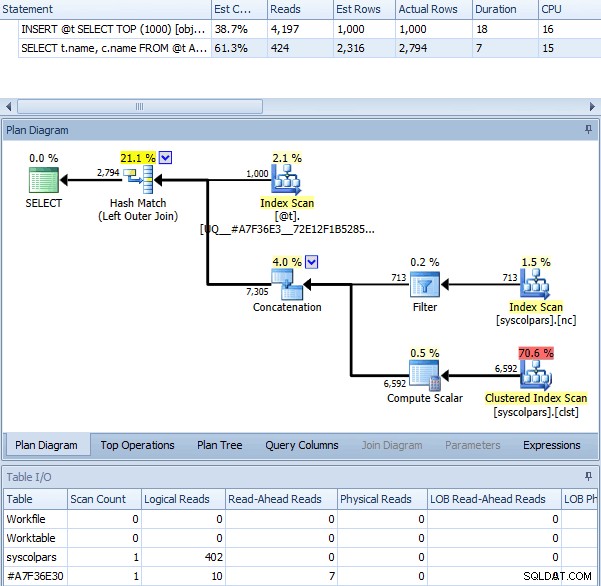
Même requête avec OPTION (RECOMPILE)
Donc, cela pourrait vous amener à croire que l'indicateur de trace accomplit des résultats similaires en déclenchant une recompilation pour vous à chaque fois. Nous pouvons étudier cela à l'aide d'une session d'événements étendus très simple :
CREATE EVENT SESSION [CaptureRecompiles] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles] ON SERVER STATE = START; J'ai exécuté l'ensemble de lots suivant, qui a exécuté 20 requêtes avec (a) aucune option de recompilation ou indicateur de trace, (b) l'option de recompilation et (c) un indicateur de trace au niveau de la session.
/* default - no trace flag, no recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; GO 20 /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); GO 20 /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DBCC TRACEOFF(2453); GO 20
Ensuite, j'ai regardé les données de l'événement :
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255);
Les résultats montrent qu'aucune recompilation ne s'est produite sous la requête standard, l'instruction faisant référence à la variable de table a été recompilée une fois sous l'indicateur de trace et, comme vous vous en doutez, à chaque fois avec le RECOMPILE choix :
| sql_text | recompile_count |
|---|---|
| /* recompiler */ DECLARE @t TABLE (i INT … | 20 |
| /* indicateur de trace */ DBCC TRACEON(2453); DÉCLARER @t … | 1 |
Résultats de la requête sur les données XEvents
Ensuite, j'ai désactivé la session d'événements étendus, puis j'ai changé le lot pour mesurer à l'échelle. Essentiellement, le code mesure 1 000 itérations de création et de remplissage d'une variable de table, puis sélectionne ses résultats dans une table #temp (une façon de supprimer la sortie de ces nombreux jeux de résultats jetables), en utilisant chacune des trois méthodes.
SET NOCOUNT ON; /* default - no trace flag, no recompile */ SELECT SYSDATETIME(); GO DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; DBCC TRACEOFF(2453); GO 1000 SELECT SYSDATETIME(); GO
J'ai exécuté ce lot 10 fois et pris les moyennes; ils étaient :
| Méthode | Durée moyenne (millisecondes) |
|---|---|
| Par défaut | 23 148,4 |
| Recompiler | 29 959,3 |
| Drapeau de suivi | 22 100,7 |
Durée moyenne pour 1 000 itérations
Dans ce cas, obtenir les bonnes estimations à chaque fois en utilisant l'indicateur de recompilation était beaucoup plus lent que le comportement par défaut, mais l'utilisation de l'indicateur de trace était légèrement plus rapide. Cela a du sens car - alors que les deux méthodes corrigent le comportement par défaut d'utiliser une fausse estimation (et d'obtenir un mauvais plan en conséquence), les recompilations prennent des ressources et, lorsqu'elles ne produisent pas ou ne peuvent pas produire un plan plus efficace, ont tendance à contribuent à la durée globale du lot.
Cela semble simple, mais attendez…
Le test ci-dessus est légèrement - et intentionnellement - erroné. Nous insérons le même nombre de lignes (1 000) dans la variable de table à chaque fois . Que se passe-t-il si la population initiale de la variable de table varie pour différents lots ? Nous verrons sûrement des recompilations alors, même sous l'indicateur de trace, n'est-ce pas ? C'est l'heure d'un autre test. Configurons une session Événements étendus légèrement différente, juste avec un nom de fichier cible différent (pour ne pas confondre les données de l'autre session) :
CREATE EVENT SESSION [CaptureRecompiles_v2] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles_v2.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles_v2] ON SERVER STATE = START;
Inspectons maintenant ce lot, en configurant des nombres de lignes pour chaque itération qui sont significativement différents. Nous allons exécuter cela trois fois, en supprimant les commentaires appropriés afin d'avoir un lot sans indicateur de trace ni recompilation explicite, un lot avec l'indicateur de trace et un lot avec OPTION (RECOMPILE) (avoir un commentaire précis au début facilite l'identification de ces lots dans des endroits comme la sortie d'événements étendus) :
/* default, no trace flag or recompile */
/* recompile */
/* trace flag */
DECLARE @i INT = 1;
WHILE @i <= 6
BEGIN
--DBCC TRACEON(2453); -- uncomment this for trace flag
DECLARE @t TABLE(id INT PRIMARY KEY);
INSERT @t SELECT TOP (CASE @i
WHEN 1 THEN 24
WHEN 2 THEN 1782
WHEN 3 THEN 1701
WHEN 4 THEN 12
WHEN 5 THEN 15
WHEN 6 THEN 1560
END) [object_id]
FROM sys.all_objects;
SELECT t.id, c.name
FROM @t AS t
INNER JOIN sys.all_objects AS c
ON t.id = c.[object_id]
--OPTION (RECOMPILE); -- uncomment this for recompile
--DBCC TRACEOFF(2453); -- uncomment this for trace flag
DELETE @t;
SET @i += 1;
END
J'ai exécuté ces lots dans Management Studio, les ai ouverts individuellement dans Plan Explorer et filtré l'arborescence des instructions uniquement sur SELECT requête. Nous pouvons voir le comportement différent dans les trois lots en examinant les lignes estimées et réelles :

Comparaison de trois lots, en examinant les lignes estimées par rapport aux lignes réelles
Dans la grille la plus à droite, vous pouvez clairement voir où les recompilations ne se sont pas produites sous l'indicateur de trace
Nous pouvons vérifier les données XEvents pour voir ce qui s'est réellement passé avec les recompilations :
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles_v2*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255); Résultats :
| sql_text | recompile_count |
|---|---|
| /* recompiler */ DECLARE @i INT =1; PENDANT… | 6 |
| /* trace flag */ DECLARE @i INT =1; PENDANT… | 4 |
Résultats de la requête sur les données XEvents
Très intéressant! Sous l'indicateur de trace, nous * voyons * les recompilations, mais uniquement lorsque la valeur du paramètre d'exécution a varié de manière significative par rapport à la valeur mise en cache. Lorsque la valeur d'exécution est différente, mais pas de beaucoup, nous n'obtenons pas de recompilation et les mêmes estimations sont utilisées. Il est donc clair que l'indicateur de trace introduit un seuil de recompilation pour les variables de table, et j'ai confirmé (par un test séparé) que cela utilise le même algorithme que celui décrit pour les tables #temp dans cet article "ancien" mais toujours pertinent. Je le prouverai dans un article de suivi.
Encore une fois, nous testerons les performances, en exécutant le lot 1 000 fois (avec la session Événements étendus désactivée) et en mesurant la durée :
| Méthode | Durée moyenne (millisecondes) |
|---|---|
| Par défaut | 101 285,4 |
| Recompiler | 111 423,3 |
| Drapeau de suivi | 110 318,2 |
Durée moyenne pour 1 000 itérations
Dans ce scénario spécifique, nous perdons environ 10 % des performances en forçant une recompilation à chaque fois ou en utilisant un indicateur de trace. Je ne sais pas exactement comment le delta a été distribué :les plans étaient-ils basés sur de meilleures estimations, pas de manière significative mieux? Les recompilations ont-elles compensé les gains de performances de autant ? Je ne veux pas passer trop de temps là-dessus, et c'était un exemple trivial, mais cela vous montre que jouer avec le fonctionnement de l'optimiseur peut être une affaire imprévisible. Parfois, vous pouvez être mieux avec le comportement par défaut de cardinalité =1, sachant que vous ne provoquerez jamais de recompilations indues. Là où l'indicateur de trace peut avoir beaucoup de sens, c'est si vous avez des requêtes dans lesquelles vous remplissez à plusieurs reprises des variables de table avec le même ensemble de données (par exemple, une table de recherche de code postal) ou si vous utilisez toujours 50 ou 1 000 lignes (par exemple, remplir une variable de tableau à utiliser dans la pagination). Dans tous les cas, vous devez certainement tester l'impact que cela a sur toute charge de travail où vous prévoyez d'introduire l'indicateur de trace ou des recompilations explicites.
TVP et types de tableaux
J'étais également curieux de savoir comment cela affecterait les types de table et si nous verrions des améliorations de la cardinalité pour les TVP, où ce même symptôme existe. J'ai donc créé un type de table simple qui imite la variable de table utilisée jusqu'à présent :
USE MyTestDB; GO CREATE TYPE dbo.t AS TABLE ( id INT PRIMARY KEY );
Ensuite, j'ai pris le lot ci-dessus et j'ai simplement remplacé DECLARE @t TABLE(id INT PRIMARY KEY); avec DECLARE @t dbo.t; – tout le reste est resté exactement le même. J'ai exécuté les trois mêmes lots, et voici ce que j'ai vu :

Comparaison des estimations et des valeurs réelles entre le comportement par défaut, la recompilation des options et l'indicateur de trace 2453
Alors oui, il semble que l'indicateur de trace fonctionne exactement de la même manière avec les TVP :les recompilations génèrent de nouvelles estimations pour l'optimiseur lorsque le nombre de lignes dépasse le seuil de recompilation, et sont ignorées lorsque le nombre de lignes est "suffisamment proche".
Avantages, inconvénients et mises en garde
L'un des avantages de l'indicateur de trace est que vous pouvez éviter certains recompile et voit toujours la cardinalité de la table - tant que vous vous attendez à ce que le nombre de lignes dans la variable de table soit stable ou que vous n'observiez pas d'écarts de plan significatifs en raison de la cardinalité variable. Une autre est que vous pouvez l'activer globalement ou au niveau de la session et ne pas avoir à introduire d'indices de recompilation dans toutes vos requêtes. Et enfin, au moins dans le cas où la cardinalité des variables de table était stable, des estimations appropriées ont conduit à de meilleures performances que la valeur par défaut, et également à de meilleures performances que l'utilisation de l'option de recompilation - toutes ces compilations peuvent certainement s'additionner.
Il y a aussi des inconvénients, bien sûr. Celui que j'ai mentionné ci-dessus est celui comparé à OPTION (RECOMPILE) vous manquez certaines optimisations, telles que l'intégration de paramètres. Une autre est que l'indicateur de trace n'aura pas l'impact que vous attendez sur des plans triviaux. Et celui que j'ai découvert en cours de route est que l'utilisation de QUERYTRACEON l'indication pour appliquer l'indicateur de trace au niveau de la requête ne fonctionne pas - pour autant que je sache, l'indicateur de trace doit être en place lorsque la variable de table ou TVP est créée et/ou remplie pour que l'optimiseur voie la cardinalité ci-dessus 1.
Gardez à l'esprit que l'exécution de l'indicateur de trace globalement introduit la possibilité de régressions du plan de requête à toute requête impliquant une variable de table (c'est pourquoi cette fonctionnalité a été introduite sous un indicateur de trace en premier lieu), alors assurez-vous de tester l'ensemble de votre charge de travail peu importe comment vous utilisez l'indicateur de trace. En outre, lorsque vous testez ce comportement, veuillez le faire dans une base de données utilisateur ; certaines des optimisations et simplifications auxquelles vous vous attendez normalement ne se produisent tout simplement pas lorsque le contexte est défini sur tempdb, de sorte que tout comportement que vous y observez peut ne pas rester cohérent lorsque vous déplacez le code et les paramètres vers une base de données utilisateur.
Conclusion
Si vous utilisez des variables de table ou des TVP avec un nombre important mais relativement cohérent de lignes, vous pouvez trouver avantageux d'activer cet indicateur de trace pour certains lots ou procédures afin d'obtenir une cardinalité de table précise sans forcer manuellement une recompilation sur des requêtes individuelles. Vous pouvez également utiliser l'indicateur de trace au niveau de l'instance, ce qui affectera toutes les requêtes. Mais comme pour tout changement, dans les deux cas, vous devrez faire preuve de diligence pour tester les performances de l'ensemble de votre charge de travail, rechercher explicitement toute régression et vous assurer que vous souhaitez le comportement de l'indicateur de trace, car vous pouvez faire confiance à la stabilité de votre variable de table. nombre de lignes.
Je suis heureux de voir l'indicateur de trace ajouté à SQL Server 2014, mais ce serait mieux si cela devenait le comportement par défaut. Non pas qu'il y ait un avantage significatif à utiliser de grandes variables de table sur de grandes tables #temp, mais ce serait bien de voir plus de parité entre ces deux types de structures temporaires qui pourraient être dictées à un niveau supérieur. Plus nous avons de parité, moins les gens doivent délibérer sur celui qu'ils doivent utiliser (ou du moins ont moins de critères à prendre en compte lors du choix). Martin Smith a une excellente session de questions-réponses sur dba.stackexchange qui doit probablement être mise à jour :Quelle est la différence entre une table temporaire et une variable de table dans SQL Server ?
Remarque importante
Si vous allez installer SQL Server 2012 Service Pack 2 (qu'il s'agisse ou non d'utiliser cet indicateur de trace), veuillez également consulter mon article sur une régression dans SQL Server 2012 et 2014 qui peut - dans de rares scénarios - introduire la perte ou la corruption potentielle de données lors des reconstructions d'index en ligne. Des mises à jour cumulatives sont disponibles pour SQL Server 2012 SP1 et SP2 ainsi que pour SQL Server 2014. Il n'y aura pas de correctif pour la branche RTM 2012.
Tests supplémentaires
J'ai d'autres choses sur ma liste à tester. D'une part, j'aimerais voir si cet indicateur de trace a un effet sur les types de table en mémoire dans SQL Server 2014. Je vais également prouver sans l'ombre d'un doute que l'indicateur de trace 2453 utilise le même seuil de recompilation pour la table variables et TVP comme pour les tables #temp.



