PostgreSQL est un projet génial et il évolue à une vitesse incroyable. Nous nous concentrerons sur l'évolution des capacités de tolérance aux pannes dans PostgreSQL à travers ses versions avec une série d'articles de blog. Ceci est le troisième article de la série et nous parlerons des problèmes de chronologie et de leurs effets sur la tolérance aux pannes et la fiabilité de PostgreSQL.
Si vous souhaitez assister à la progression de l'évolution depuis le début, veuillez consulter les deux premiers articles de blog de la série :
- Évolution de la tolérance aux pannes dans PostgreSQL
- Évolution de la tolérance aux pannes dans PostgreSQL :phase de réplication

Échéances
La possibilité de restaurer la base de données à un point antérieur dans le temps crée des complexités dont nous couvrirons certains des cas en expliquant le basculement (Fig. 1), commutation (Fig. 2) et pg_rewind (Fig. 3) cas plus loin dans cette rubrique.
Par exemple, dans l'historique d'origine de la base de données, supposons que vous ayez supprimé une table critique à 17h15 mardi soir, mais que vous ne vous soyez rendu compte de votre erreur que mercredi midi. Imperturbable, vous sortez votre sauvegarde, restaurez au point dans le temps 17h14 mardi soir et êtes opérationnel. Dans cette histoire de l'univers des bases de données, vous n'avez jamais supprimé la table. Mais supposons que vous réalisiez plus tard que ce n'était pas une si bonne idée et que vous vouliez revenir à un mercredi matin dans l'histoire originale. Vous ne pourrez pas le faire si, alors que votre base de données était opérationnelle, elle a écrasé certains des fichiers de segment WAL qui ont conduit à l'heure à laquelle vous souhaitez maintenant pouvoir revenir.
Ainsi, pour éviter cela, vous devez distinguer la série d'enregistrements WAL générés après avoir effectué une récupération ponctuelle de ceux qui ont été générés dans l'historique de la base de données d'origine.
Pour faire face à ce problème, PostgreSQL a une notion de chronologie. Chaque fois qu'une récupération d'archive se termine, une nouvelle chronologie est créée pour identifier la série d'enregistrements WAL générés après cette récupération. Le numéro d'identification de la chronologie fait partie des noms de fichier de segment WAL afin qu'une nouvelle chronologie n'écrase pas les données WAL générées par les chronologies précédentes. Il est en effet possible d'archiver de nombreuses chronologies différentes.
Considérez la situation où vous n'êtes pas tout à fait sûr du point dans le temps auquel récupérer, et vous devez donc effectuer plusieurs récupérations ponctuelles par essais et erreurs jusqu'à ce que vous trouviez le meilleur endroit pour bifurquer de l'ancien historique. Sans délais, ce processus générerait bientôt un gâchis ingérable. Avec les chronologies, vous pouvez récupérer n'importe quel état antérieur, y compris les états des branches de chronologie que vous avez abandonnées précédemment.
Chaque fois qu'une nouvelle chronologie est créée, PostgreSQL crée un fichier "d'historique de la chronologie" qui montre de quelle chronologie il s'est séparé et quand. Ces fichiers d'historique sont nécessaires pour permettre au système de choisir les bons fichiers de segment WAL lors de la récupération à partir d'une archive contenant plusieurs chronologies. Par conséquent, ils sont archivés dans la zone d'archive WAL tout comme les fichiers de segment WAL. Les fichiers d'historique ne sont que de petits fichiers texte, il est donc bon marché et approprié de les conserver indéfiniment (contrairement aux fichiers de segment qui sont volumineux). Vous pouvez, si vous le souhaitez, ajouter des commentaires à un fichier d'historique pour enregistrer vos propres notes sur comment et pourquoi cette chronologie particulière a été créée. De tels commentaires seront particulièrement précieux lorsque vous avez un fourré de délais différents à la suite d'une expérimentation.
Le comportement par défaut de la récupération est de récupérer selon la même chronologie qui était en cours lorsque la sauvegarde de base a été effectuée. Si vous souhaitez récupérer dans une chronologie enfant (c'est-à-dire que vous souhaitez revenir à un état qui a lui-même été généré après une tentative de récupération), vous devez spécifier l'ID de la chronologie cible dans recovery.conf. Vous ne pouvez pas récupérer dans des chronologies qui ont bifurqué avant la sauvegarde de base.
Pour simplifier le concept de chronologie dans PostgreSQL, problèmes liés à la chronologie en cas de basculement , basculement et pg_rewind sont résumés et expliqués avec les Fig.1, Fig.2 et Fig.3.
Scénario de basculement :
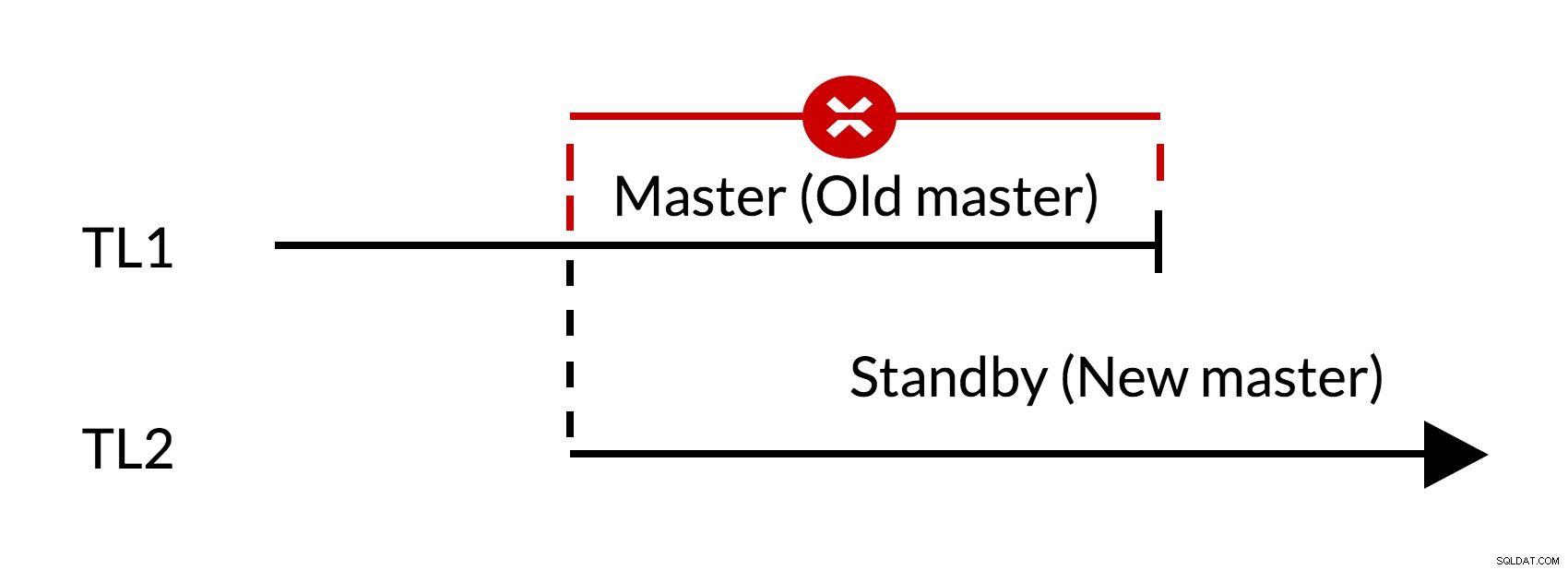
Fig.1 Basculement
- Il y a des changements en suspens dans l'ancien maître (TL1)
- L'augmentation de la chronologie représente le nouvel historique des modifications (TL2)
- Les modifications apportées à l'ancienne chronologie ne peuvent pas être lues sur les serveurs qui sont passés à la nouvelle chronologie
- L'ancien maître ne peut pas suivre le nouveau maître
Scénario de bascule :
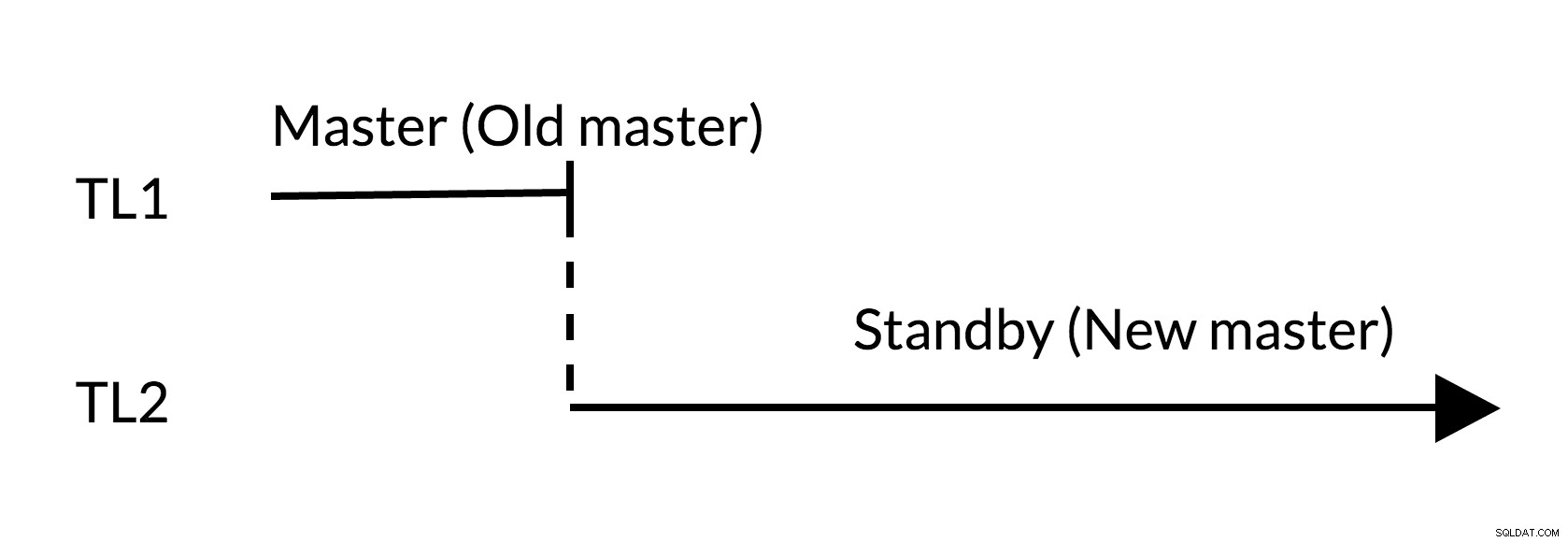 Fig.2 Basculement
Fig.2 Basculement
- Il n'y a pas de modifications en suspens dans l'ancien maître (TL1)
- L'augmentation de la chronologie représente le nouvel historique des modifications (TL2)
- L'ancien maître peut devenir le remplaçant du nouveau maître
Scénario pg_rewind :
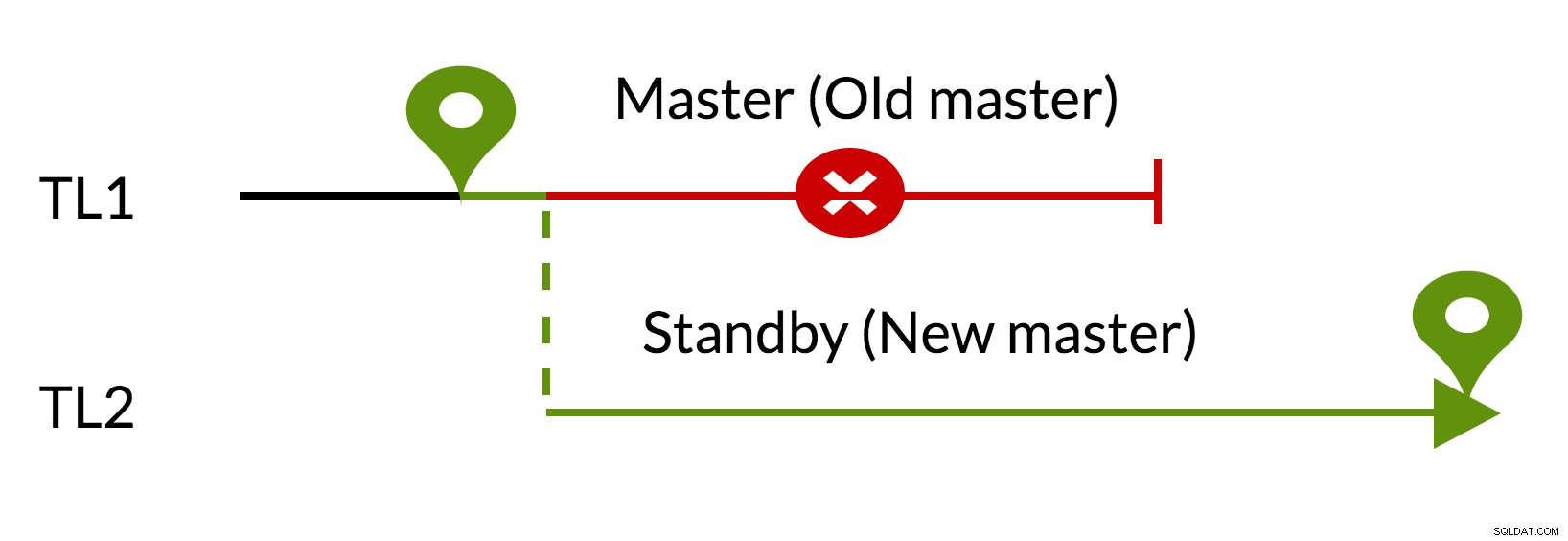 Fig.3 pg_rewind
Fig.3 pg_rewind
- Les modifications en attente sont supprimées à l'aide des données du nouveau maître (TL1)
- L'ancien maître peut suivre le nouveau maître (TL2)
pg_rewind
pg_rewind est un outil pour synchroniser un cluster PostgreSQL avec une autre copie du même cluster, après que les délais des clusters ont divergé. Un scénario typique consiste à remettre en ligne un ancien serveur maître après le basculement, en tant que serveur de secours qui suit le nouveau maître.
Le résultat équivaut à remplacer le répertoire de données cible par celui source. Tous les fichiers sont copiés, y compris les fichiers de configuration. L'avantage de pg_rewind par rapport à une nouvelle sauvegarde de base, ou à des outils comme rsync, est que pg_rewind ne nécessite pas de lire tous les fichiers inchangés du cluster. Cela le rend beaucoup plus rapide lorsque la base de données est volumineuse et que seule une petite partie de celle-ci diffère entre les clusters.
Comment ça marche ?
L'idée de base est de tout copier du nouveau cluster vers l'ancien, à l'exception des blocs dont nous savons qu'ils sont identiques.
- Analysez le journal WAL de l'ancien cluster, en commençant par le dernier point de contrôle avant le point où l'historique de la chronologie du nouveau cluster est dérivé de l'ancien cluster. Pour chaque enregistrement WAL, notez les blocs de données qui ont été touchés. Cela donne une liste de tous les blocs de données qui ont été modifiés dans l'ancien cluster, après le débranchement du nouveau cluster.
- Copiez tous ces blocs modifiés du nouveau cluster vers l'ancien.
- Copiez tous les autres fichiers tels que les fichiers de clog et de configuration du nouveau cluster vers l'ancien cluster, tout sauf les fichiers de relation.
- Appliquez le WAL du nouveau cluster, en commençant par le point de contrôle créé lors du basculement. (Strictement parlant, pg_rewind n'applique pas le WAL, il crée simplement un fichier d'étiquette de sauvegarde indiquant que lorsque PostgreSQL est démarré, il commencera à rejouer à partir de ce point de contrôle et appliquera tous les WAL requis.)
Remarque : wal_log_hints doit être défini dans postgresql.conf pour que pg_rewind puisse fonctionner. Ce paramètre ne peut être défini qu'au démarrage du serveur. La valeur par défaut est off .
Conclusion
Dans cet article de blog, nous avons discuté des délais dans Postgres et de la manière dont nous gérons les cas de basculement et de basculement. Nous avons également parlé du fonctionnement de pg_rewind et de ses avantages pour la tolérance aux pannes et la fiabilité de Postgres. Nous continuerons avec la validation synchrone dans le prochain article de blog.
Références
Documentation PostgreSQL
Livre de recettes d'administration PostgreSQL 9 – Deuxième édition
pg_rewind Présentation du Nordic PGDay par Heikki Linnakangas