La lecture validée est le deuxième plus faible des quatre niveaux d'isolement définis par la norme SQL. Néanmoins, il s'agit du niveau d'isolement par défaut pour de nombreux moteurs de base de données, y compris SQL Server. Cet article d'une série sur les niveaux d'isolement et les propriétés ACID des transactions examine les garanties logiques et physiques réellement fournies par l'isolement validé en lecture.
Garanties logiques
La norme SQL exige qu'une transaction s'exécutant sous l'isolement de lecture validée lise uniquement committed Les données. Il exprime cette exigence en interdisant le phénomène de concurrence connu sous le nom de lecture sale. Une lecture incorrecte se produit lorsqu'une transaction lit des données qui ont été écrites par une autre transaction, avant que cette deuxième transaction ne se termine. Une autre façon d'exprimer cela est de dire qu'une lecture incorrecte se produit lorsqu'une transaction lit des données non validées.
La norme mentionne également qu'une transaction s'exécutant à l'isolement de lecture validée peut rencontrer les phénomènes de concurrence connus sous le nom de lectures non répétables et fantômes . Bien que de nombreux livres expliquent ces phénomènes en termes de capacité d'une transaction à voir des éléments de données modifiés ou nouveaux si les données sont relues par la suite, cette explication peut renforcer l'idée fausse que les phénomènes de concurrence ne peuvent se produire qu'à l'intérieur d'une transaction explicite contenant plusieurs instructions. Ce n'est pas le cas. Une instruction unique sans transaction explicite est tout aussi vulnérable aux phénomènes de lecture non répétable et fantôme, comme nous le verrons bientôt.
C'est à peu près tout ce que la norme a à dire sur le sujet de l'isolement de lecture validée. À première vue, ne lire que les données validées semble être une assez bonne garantie d'un comportement sensé, mais comme toujours, le diable est dans les détails. Dès que vous commencez à chercher des échappatoires potentielles dans cette définition, il devient trop facile de trouver des cas où nos transactions validées en lecture pourraient ne pas produire les résultats auxquels nous pourrions nous attendre. Encore une fois, nous en discuterons plus en détail dans un instant ou deux.
Différentes implémentations physiques
Il y a au moins deux choses qui signifient que le comportement observé du niveau d'isolement de lecture validée peut être assez différent sur différents moteurs de base de données. Tout d'abord, l'exigence standard SQL de lire uniquement les données validées n'est pas signifie nécessairement que les données validées lues par une transaction seront les plus récentes données validées.
Un moteur de base de données est autorisé à lire une version validée d'une ligne à partir de n'importe quel moment dans le passé , tout en restant conforme à la définition standard SQL. Plusieurs produits de base de données populaires implémentent l'isolation validée en lecture de cette manière. Les résultats de la requête obtenus dans le cadre de cette implémentation de l'isolation validée en lecture peuvent être arbitrairement obsolètes , par rapport à l'état validé actuel de la base de données. Nous aborderons ce sujet tel qu'il s'applique à SQL Server dans le prochain article de la série.
La deuxième chose sur laquelle je veux attirer votre attention est que la définition standard SQL ne le fait pas empêcher une mise en œuvre particulière de fournir des protections supplémentaires contre les effets de concurrence au-delà de la prévention des lectures erronées . La norme spécifie uniquement que les lectures modifiées ne sont pas autorisées, elle n'exige pas que d'autres phénomènes de concurrence soient autorisés à n'importe quel niveau d'isolement donné.
Pour être clair sur ce deuxième point, un moteur de base de données conforme aux normes pourrait implémenter tous les niveaux d'isolation en utilisant serializable comportement si tel était son choix. Certains moteurs de base de données commerciaux majeurs fournissent également une implémentation de lecture validée qui va bien au-delà de la simple prévention des lectures incorrectes (bien qu'aucun ne va jusqu'à fournir une isolation complète dans l'ACID sens du mot).
En plus de cela, pour plusieurs produits populaires, lisez commis l'isolement est le le plus bas niveau d'isolement disponible ; leurs implémentations de lecture uncommitted isolation sont exactement les mêmes que read commit. Ceci est autorisé par la norme, mais ces types de différences ajoutent de la complexité à la tâche déjà difficile de migration de code d'une plate-forme à une autre. Lorsque l'on parle des comportements d'un niveau d'isolement, il est généralement important de spécifier également la plate-forme particulière.
Autant que je sache, SQL Server est unique parmi les principaux moteurs de base de données commerciaux en fournissant deux implémentations du niveau d'isolement de lecture validée, chacune avec des comportements physiques très différents. Ce message couvre le premier d'entre eux, verrouillage lecture validée.
Verrouillage SQL Server en lecture validée
Si l'option de base de données READ_COMMITTED_SNAPSHOT est OFF , SQL Server utilise un verrouillage implémentation du niveau d'isolation validé en lecture, où des verrous partagés sont pris pour empêcher une transaction concurrente de modifier simultanément les données, car la modification nécessiterait un verrou exclusif, qui n'est pas compatible avec le verrou partagé.
La principale différence entre le verrouillage de la lecture validée de SQL Server et le verrouillage de la lecture répétable (qui prend également des verrous partagés lors de la lecture des données) est que la lecture validée libère le verrou partagé dès que possible , tandis que la lecture répétable maintient ces verrous jusqu'à la fin de la transaction englobante.
Lorsque le verrouillage de la lecture validée acquiert des verrous au niveau de la granularité des lignes, le verrou partagé pris sur une ligne est libéré lorsqu'un verrou partagé est pris sur la ligne suivante . Au niveau de la granularité de page, le verrou de page partagé est libéré lorsque la première ligne de la page suivante est lue, et ainsi de suite. À moins qu'un indice de granularité de verrouillage ne soit fourni avec la requête, le moteur de base de données décide par quel niveau de granularité commencer. Notez que les indications de granularité ne sont traitées que comme des suggestions par le moteur, un verrou moins granulaire que celui demandé peut toujours être pris initialement. Les verrous peuvent également être augmentés lors de l'exécution du niveau de la ligne ou de la page au niveau de la partition ou de la table en fonction de la configuration du système.
Le point important ici est que les verrous partagés ne sont généralement conservés que pendant une très courte durée pendant l'exécution de l'instruction. Pour répondre explicitement à une idée fausse courante, le verrouillage de la lecture validée ne le fait pas maintenez les verrous partagés jusqu'à la fin de l'instruction.
Verrouiller les comportements de lecture validée
Les verrous partagés à court terme utilisés par l'implémentation validée de verrouillage de SQL Server offrent très peu des garanties généralement attendues d'une transaction de base de données par les programmeurs T-SQL. En particulier, une instruction s'exécutant sous le verrouillage read commited isolement :
- Peut rencontrer la même ligne plusieurs fois;
- Peut manquer complètement certaines lignes; et
- Ne pas fournir une vue ponctuelle des données
Cette liste peut ressembler davantage à une description des comportements étranges que vous pourriez associer davantage à l'utilisation de NOLOCK conseils, mais toutes ces choses peuvent vraiment se produire et se produisent lors de l'utilisation du verrouillage de l'isolation validée en lecture.
Exemple
Considérez la simple tâche de compter les lignes d'une table, en utilisant la requête évidente à instruction unique. Sous verrouillage de l'isolation validée en lecture avec granularité de verrouillage de ligne, notre requête prendra un verrou partagé sur la première ligne, le lira, libérera le verrou partagé, passera à la ligne suivante, et ainsi de suite jusqu'à ce qu'il atteigne la fin de la structure. est en train de lire. Pour cet exemple, supposons que notre requête lit un index b-tree dans l'ordre croissant des clés (bien qu'elle puisse tout aussi bien utiliser un ordre décroissant ou toute autre stratégie).
Depuis une seule ligne est verrouillé en partage à tout moment, il est clairement possible que des transactions simultanées modifient les lignes déverrouillées dans l'index que notre requête traverse. Si ces modifications simultanées modifient les valeurs de clé d'index, elles entraîneront le déplacement des lignes dans la structure d'index. Avec cette possibilité à l'esprit, le diagramme ci-dessous illustre deux scénarios problématiques qui peuvent se produire :
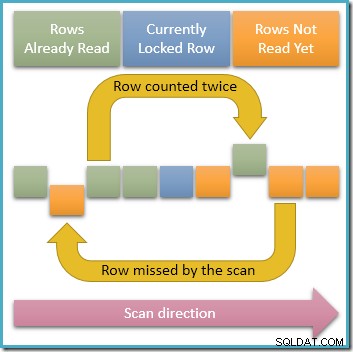
La flèche supérieure montre une ligne que nous avons déjà comptée et dont la clé d'index a été modifiée simultanément afin que la ligne avance par rapport à la position de balayage actuelle dans l'index, ce qui signifie que la ligne sera comptée deux fois . La deuxième flèche montre une ligne que notre analyse n'a pas encore rencontrée se déplaçant derrière la position d'analyse, ce qui signifie que la ligne ne sera pas comptée du tout.
Il ne s'agit pas d'une vue ponctuelle
La section précédente a montré comment le verrouillage de la lecture validée peut complètement manquer des données ou compter le même élément plusieurs fois (plus de deux fois, si nous n'avons pas de chance). Le troisième point dans la liste des comportements inattendus indique que le verrouillage de la lecture validée ne fournit pas non plus une vue ponctuelle des données.
Le raisonnement derrière cette déclaration devrait maintenant être facile à voir. Notre requête de comptage, par exemple, pourrait facilement lire les données qui ont été insérées par des transactions simultanées après le début de l'exécution de notre requête. De même, les données que notre requête voit peuvent être modifiées par une activité simultanée après le démarrage de notre requête et avant qu'elle ne se termine. Enfin, les données que nous avons lues et comptées peuvent être supprimées par une transaction simultanée avant la fin de notre requête.
De toute évidence, les données vues par une instruction ou une transaction s'exécutant sous un isolement verrouillé en lecture validée ne correspondent à aucun état unique de la base de données à un moment particulier dans le temps . Les données que nous rencontrons peuvent provenir de différents moments dans le temps, le seul facteur commun étant que chaque élément représente la dernière valeur validée de ces données au moment où elles ont été lues (même s'il a peut-être changé ou disparu depuis).
Quelle est la gravité de ces problèmes ?
Tout cela peut sembler être une situation assez floue si vous avez l'habitude de considérer vos requêtes à instruction unique et vos transactions explicites comme s'exécutant logiquement instantanément, ou comme s'exécutant sur un seul état ponctuel validé de la base de données lors de l'utilisation du niveau d'isolement SQL Server par défaut. Cela ne cadre certainement pas bien avec le concept d'isolement au sens ACID.
Compte tenu de la faiblesse apparente des garanties fournies par le verrouillage de l'isolation validée en lecture, vous pourriez commencer à vous demander comment tout de votre code T-SQL de production n'a jamais fonctionné correctement ! Bien sûr, nous pouvons accepter que l'utilisation d'un niveau d'isolement inférieur à sérialisable signifie que nous renonçons à l'isolation complète des transactions ACID en échange d'autres avantages potentiels, mais à quel point pouvons-nous nous attendre à ce que ces problèmes soient graves dans la pratique ?
Lignes manquantes et comptées deux fois
Ces deux premiers problèmes reposent essentiellement sur une activité simultanée modifiant les clés dans une structure d'index que nous analysons actuellement. Notez que la analyse inclut ici la partie d'analyse de plage partielle d'un index recherche , ainsi que l'index ou le balayage de table familier sans restriction.
Si nous analysons (par plage) une structure d'index dont les clés ne sont généralement pas modifiées par une activité concurrente, ces deux premiers problèmes ne devraient pas être vraiment un problème pratique. Il est cependant difficile d'en être certain, car les plans de requête peuvent changer pour utiliser une méthode d'accès différente, et le nouvel index recherché peut incorporer des clés volatiles.
Nous devons également garder à l'esprit que de nombreuses requêtes de production n'ont réellement besoin que d'une valeur approximative ou de répondre au mieux à certains types de questions de toute façon. Le fait que certaines lignes manquent ou soient comptées deux fois peut ne pas avoir beaucoup d'importance dans le schéma plus large des choses. Sur un système avec de nombreux changements simultanés, il peut même être difficile d'être sûr que le résultat a été imprécis, étant donné que les données changent si fréquemment. Dans ce genre de situation, une réponse à peu près correcte peut être suffisante pour les besoins du consommateur de données.
Aucune vue ponctuelle
La troisième question (la question d'une vision ponctuelle dite « cohérente » des données) revient également au même type de considérations. À des fins de création de rapports, où les incohérences ont tendance à entraîner des questions embarrassantes de la part des consommateurs de données, une vue instantanée est souvent préférable. Dans d'autres cas, le type d'incohérences résultant de l'absence d'une vue ponctuelle des données peut très bien être tolérable.
Scénarios problématiques
Il existe également de nombreux cas où les problèmes répertoriés seront être important. Par exemple, si vous écrivez du code qui applique des règles métier dans T-SQL, vous devez faire attention à sélectionner un niveau d'isolement (ou prendre toute autre action appropriée) pour garantir l'exactitude. De nombreuses règles métier peuvent être appliquées à l'aide de clés étrangères ou de contraintes, où les complexités de la sélection du niveau d'isolement sont gérées automatiquement pour vous par le moteur de base de données. En règle générale, l'utilisation de l'ensemble intégré d'intégrité déclarative fonctionnalités est préférable à la création de vos propres règles dans T-SQL.
Il existe une autre grande classe de requêtes qui n'applique pas tout à fait une règle métier en soi , mais qui pourraient néanmoins avoir des conséquences fâcheuses lorsqu'elles sont exécutées au niveau d'isolement par défaut de lecture validée avec verrouillage. Ces scénarios ne sont pas toujours aussi évidents que les exemples souvent cités de transfert d'argent entre comptes bancaires ou de garantie que le solde d'un certain nombre de comptes liés ne tombe jamais en dessous de zéro. Par exemple, considérez la requête suivante qui identifie les factures en souffrance comme une entrée d'un processus qui envoie des lettres de rappel sévères :
INSERT dbo.OverdueInvoices
SELECT I.InvoiceNumber
FROM dbo.Invoices AS INV
WHERE INV.TotalDue >
(
SELECT SUM(P.Amount)
FROM dbo.Payments AS P
WHERE P.InvoiceNumber = I.InvoiceNumber
); De toute évidence, nous ne voudrions pas envoyer une lettre à quelqu'un qui a entièrement payé sa facture en plusieurs fois, simplement parce que l'activité simultanée de la base de données au moment de l'exécution de notre requête signifie que nous avons calculé une somme incorrecte des paiements reçus. Les requêtes réelles sur des systèmes de production réels sont souvent beaucoup plus complexes que le simple exemple ci-dessus, bien sûr.
Pour terminer pour aujourd'hui, jetez un œil à la requête suivante et voyez si vous pouvez repérer le nombre d'opportunités pour que quelque chose d'imprévu se produise, si plusieurs requêtes de ce type sont exécutées simultanément au niveau d'isolement verrouillé en lecture validée (peut-être pendant que d'autres transactions non liées modifient également la table Cas) :
-- Allocate the oldest unallocated case ID to
-- the current case worker, while ensuring
-- the worker never has more than three
-- active cases at once.
UPDATE dbo.Cases
SET WorkerID = @WorkerID
WHERE
CaseID =
(
-- Find the oldest unallocated case ID
SELECT TOP (1)
C2.CaseID
FROM dbo.Cases AS C2
WHERE
C2.WorkerID IS NULL
ORDER BY
C2.DateCreated DESC
)
AND
(
SELECT COUNT_BIG(*)
FROM dbo.Cases AS C3
WHERE C3.WorkerID = @WorkerID
) < 3; Une fois que vous commencez à chercher toutes les petites façons dont une requête peut mal tourner à ce niveau d'isolement, il peut être difficile de s'arrêter. Gardez à l'esprit les mises en garde notées précédemment concernant le besoin réel de résultats complètement isolés et précis à un moment donné. Il est parfaitement acceptable d'avoir des requêtes qui renvoient des résultats suffisamment bons, tant que vous êtes conscient des compromis que vous faites en utilisant la lecture validée.
La prochaine fois
La partie suivante de cette série examine la deuxième implémentation physique de l'isolation de lecture validée disponible dans SQL Server, l'isolation d'instantané de lecture validée.
[ Voir l'index pour toute la série ]