Le tout premier article de blog sur ce site, en juillet 2012, parlait des meilleures approches pour les totaux cumulés. Depuis lors, on m'a demandé à plusieurs reprises comment j'aborderais le problème si les totaux cumulés étaient plus complexes - en particulier, si j'avais besoin de calculer les totaux cumulés pour plusieurs entités - par exemple, les commandes de chaque client.
L'exemple original utilisait un cas fictif d'une ville émettant des contraventions pour excès de vitesse; le total cumulé consistait simplement à agréger et à tenir un décompte du nombre de contraventions pour excès de vitesse par jour (indépendamment de la personne à qui la contravention avait été émise ou de son montant). Un exemple plus complexe (mais pratique) pourrait être l'agrégation de la valeur totale cumulée des contraventions pour excès de vitesse, regroupées par permis de conduire, par jour. Imaginons le tableau suivant :
CREATE TABLE dbo.SpeedingTickets ( IncidentID INT IDENTITY(1,1) PRIMARY KEY, LicenseNumber INT NOT NULL, IncidentDate DATE NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL ); CREATE UNIQUE INDEX x ON dbo.SpeedingTickets(LicenseNumber, IncidentDate) INCLUDE(TicketAmount);
Vous pourriez demander, DECIMAL(7,2) , vraiment? A quelle vitesse vont ces gens ? Eh bien, au Canada, par exemple, il n'est pas si difficile d'obtenir une amende de 10 000 $ pour excès de vitesse.
Maintenant, remplissons le tableau avec quelques exemples de données. Je n'entrerai pas dans tous les détails ici, mais cela devrait produire environ 6 000 lignes représentant plusieurs conducteurs et plusieurs montants de tickets sur une période d'un mois :
;WITH TicketAmounts(ID,Value) AS
(
-- 10 arbitrary ticket amounts
SELECT i,p FROM
(
VALUES(1,32.75),(2,75), (3,109),(4,175),(5,295),
(6,68.50),(7,125),(8,145),(9,199),(10,250)
) AS v(i,p)
),
LicenseNumbers(LicenseNumber,[newid]) AS
(
-- 1000 random license numbers
SELECT TOP (1000) 7000000 + number, n = NEWID()
FROM [master].dbo.spt_values
WHERE number BETWEEN 1 AND 999999
ORDER BY n
),
JanuaryDates([day]) AS
(
-- every day in January 2014
SELECT TOP (31) DATEADD(DAY, number, '20140101')
FROM [master].dbo.spt_values
WHERE [type] = N'P'
ORDER BY number
),
Tickets(LicenseNumber,[day],s) AS
(
-- match *some* licenses to days they got tickets
SELECT DISTINCT l.LicenseNumber, d.[day], s = RTRIM(l.LicenseNumber)
FROM LicenseNumbers AS l CROSS JOIN JanuaryDates AS d
WHERE CHECKSUM(NEWID()) % 100 = l.LicenseNumber % 100
AND (RTRIM(l.LicenseNumber) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
OR (RTRIM(l.LicenseNumber+1) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
)
INSERT dbo.SpeedingTickets(LicenseNumber,IncidentDate,TicketAmount)
SELECT t.LicenseNumber, t.[day], ta.Value
FROM Tickets AS t
INNER JOIN TicketAmounts AS ta
ON ta.ID = CONVERT(INT,RIGHT(t.s,1))-CONVERT(INT,LEFT(RIGHT(t.s,2),1))
ORDER BY t.[day], t.LicenseNumber; Cela peut sembler un peu trop compliqué, mais l'un des plus grands défis que j'ai souvent à relever lors de la rédaction de ces articles de blog est de construire une quantité appropriée de données "aléatoires" / arbitraires réalistes. Si vous avez une meilleure méthode pour la population de données arbitraires, n'utilisez pas mes marmonnements comme exemple - ils sont périphériques au point de ce post.
Approches
Il existe différentes façons de résoudre ce problème dans T-SQL. Voici sept approches, ainsi que leurs plans associés. J'ai laissé de côté des techniques comme les curseurs (car ils seront indéniablement plus lents) et les CTE récursifs basés sur la date (car ils dépendent de jours contigus).
Sous-requête #1
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND s.IncidentDate < o.IncidentDate
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
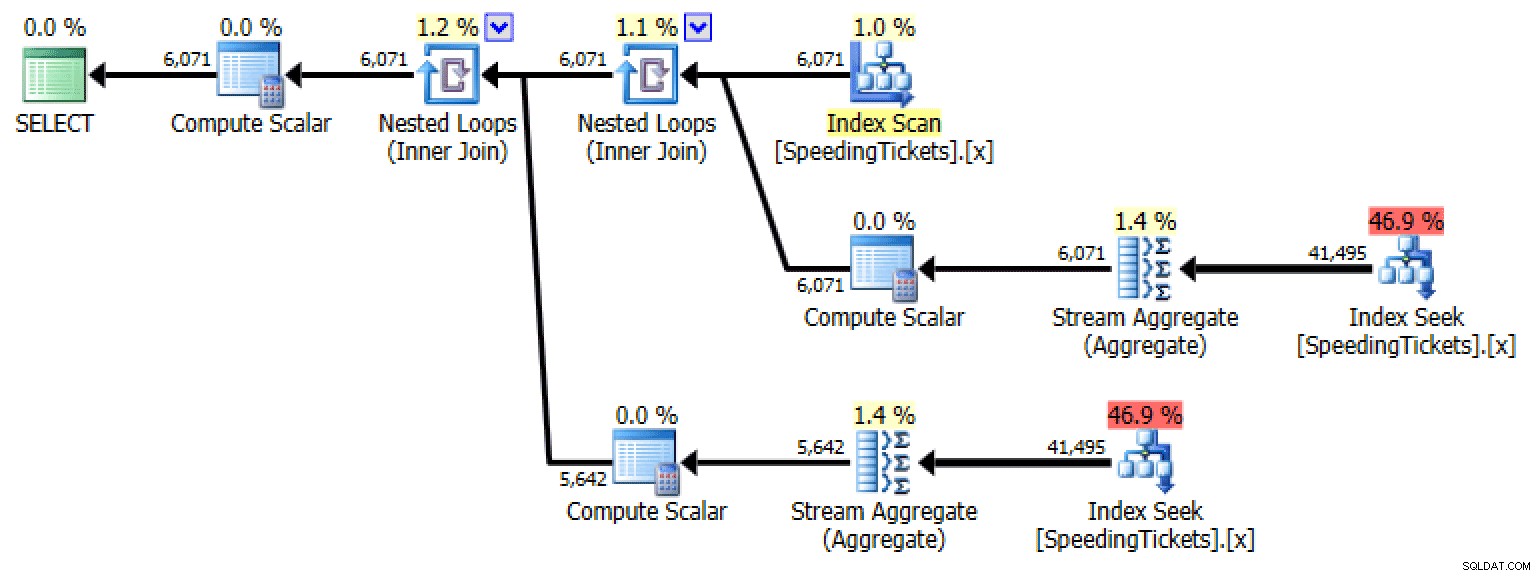
Planifier la sous-requête #1
Sous-requête #2
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
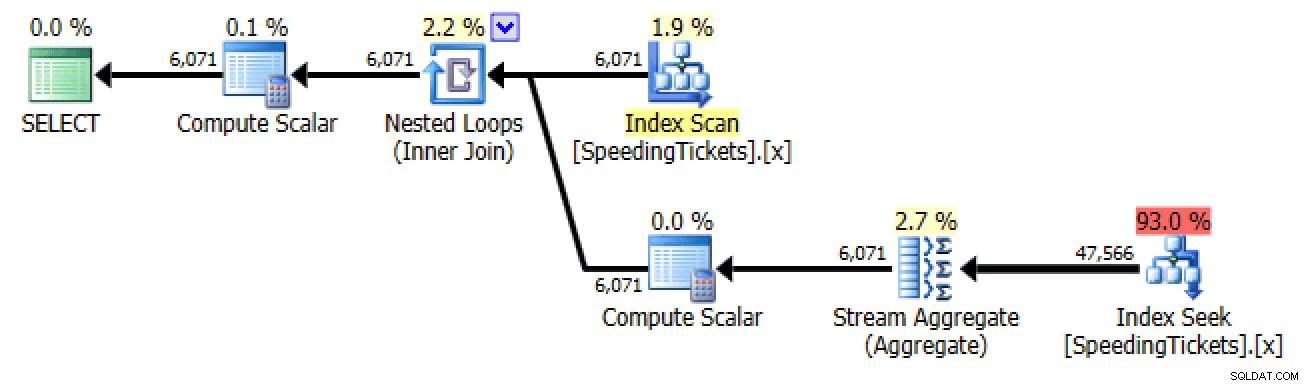
Planifier la sous-requête #2
Auto-jointure
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal = SUM(t2.TicketAmount) FROM dbo.SpeedingTickets AS t1 INNER JOIN dbo.SpeedingTickets AS t2 ON t1.LicenseNumber = t2.LicenseNumber AND t1.IncidentDate >= t2.IncidentDate GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount ORDER BY t1.LicenseNumber, t1.IncidentDate;
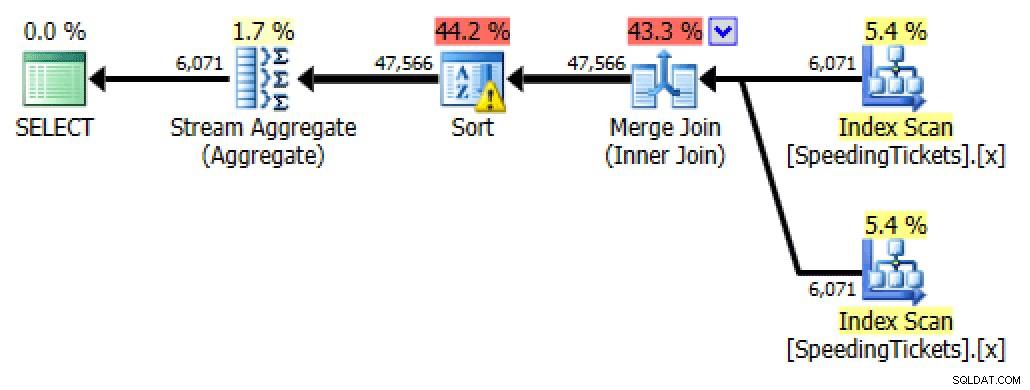
Planifier l'auto-jointure
Application extérieure
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
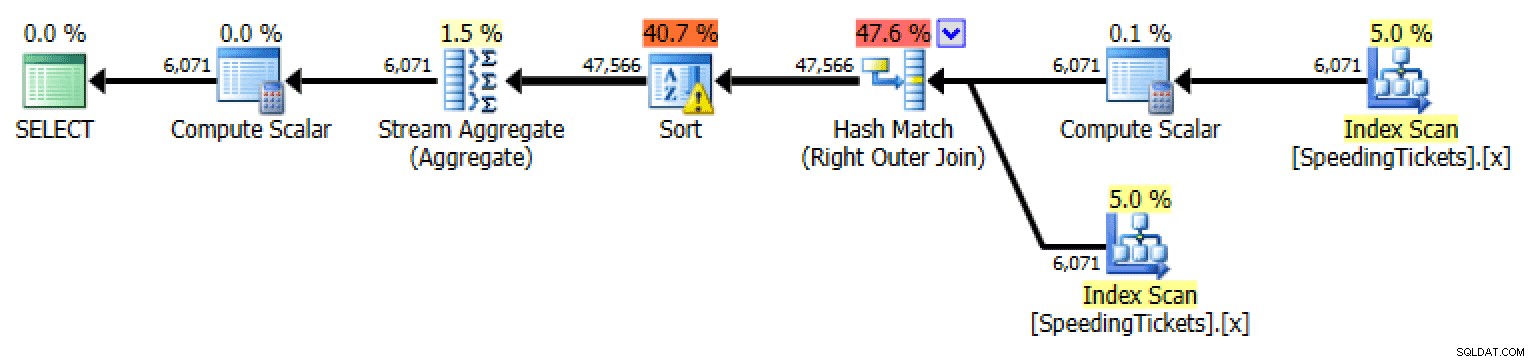
Planifier l'application externe
SUM OVER() en utilisant RANGE (2012+ uniquement)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate RANGE UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;

Planifiez SUM OVER() en utilisant RANGE
SUM OVER() en utilisant ROWS (2012+ uniquement)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate ROWS UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;

Planifiez SUM OVER() en utilisant ROWS
Itération basée sur des ensembles
Grâce à Hugo Kornelis (@Hugo_Kornelis) pour le chapitre 4 du volume 1 de SQL Server MVP Deep Dives, cette approche combine une approche basée sur les ensembles et une approche par curseur.
DECLARE @x TABLE
(
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL,
PRIMARY KEY(LicenseNumber, IncidentDate)
);
INSERT @x(LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate)
FROM dbo.SpeedingTickets;
DECLARE @rn INT = 1, @rc INT = 1;
WHILE @rc > 0
BEGIN
SET @rn += 1;
UPDATE [current]
SET RunningTotal = [last].RunningTotal + [current].TicketAmount
FROM @x AS [current]
INNER JOIN @x AS [last]
ON [current].LicenseNumber = [last].LicenseNumber
AND [last].rn = @rn - 1
WHERE [current].rn = @rn;
SET @rc = @@ROWCOUNT;
END
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal
FROM @x
ORDER BY LicenseNumber, IncidentDate; En raison de sa nature, cette approche produit de nombreux plans identiques lors du processus de mise à jour de la variable de table, qui sont tous similaires aux plans d'auto-jointure et d'application externe, mais peuvent utiliser une recherche :
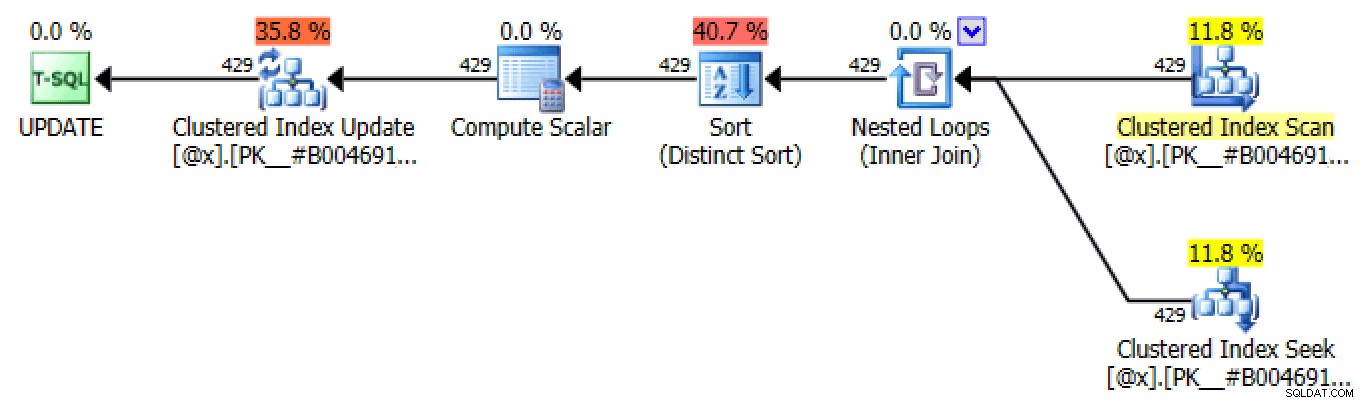
L'un des nombreux plans UPDATE produits par itération basée sur des ensembles
La seule différence entre chaque plan dans chaque itération est le nombre de lignes. À chaque itération successive, le nombre de lignes affectées doit rester le même ou diminuer, puisque le nombre de lignes affectées à chaque itération représente le nombre de conducteurs avec des tickets sur ce nombre de jours (ou, plus précisément, le nombre de jours à ce "rang").
Résultats de performances
Voici comment les approches se sont empilées, comme le montre SQL Sentry Plan Explorer, à l'exception de l'approche d'itération basée sur un ensemble qui, parce qu'elle se compose de nombreuses instructions individuelles, ne représente pas bien par rapport au reste.
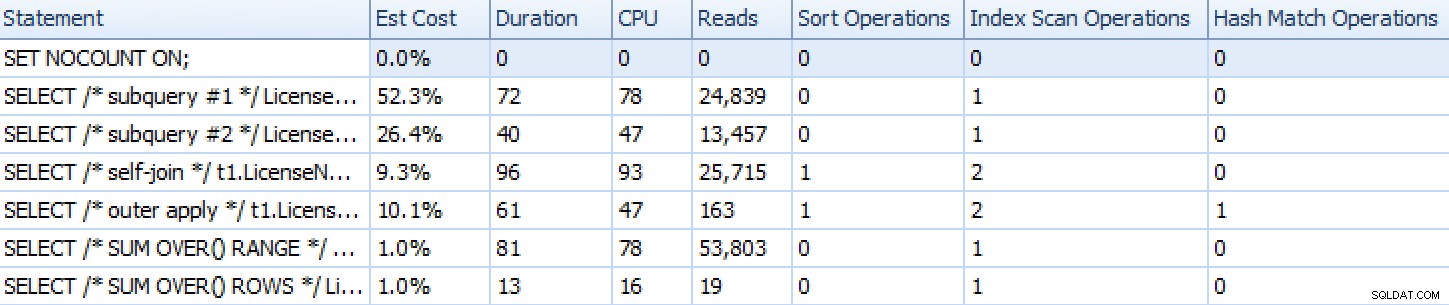
Métriques d'exécution de Plan Explorer pour six des sept approches
En plus d'examiner les plans et de comparer les métriques d'exécution dans Plan Explorer, j'ai également mesuré l'exécution brute dans Management Studio. Voici les résultats de l'exécution de chaque requête 10 fois, en gardant à l'esprit que cela inclut également le temps de rendu dans SSMS :
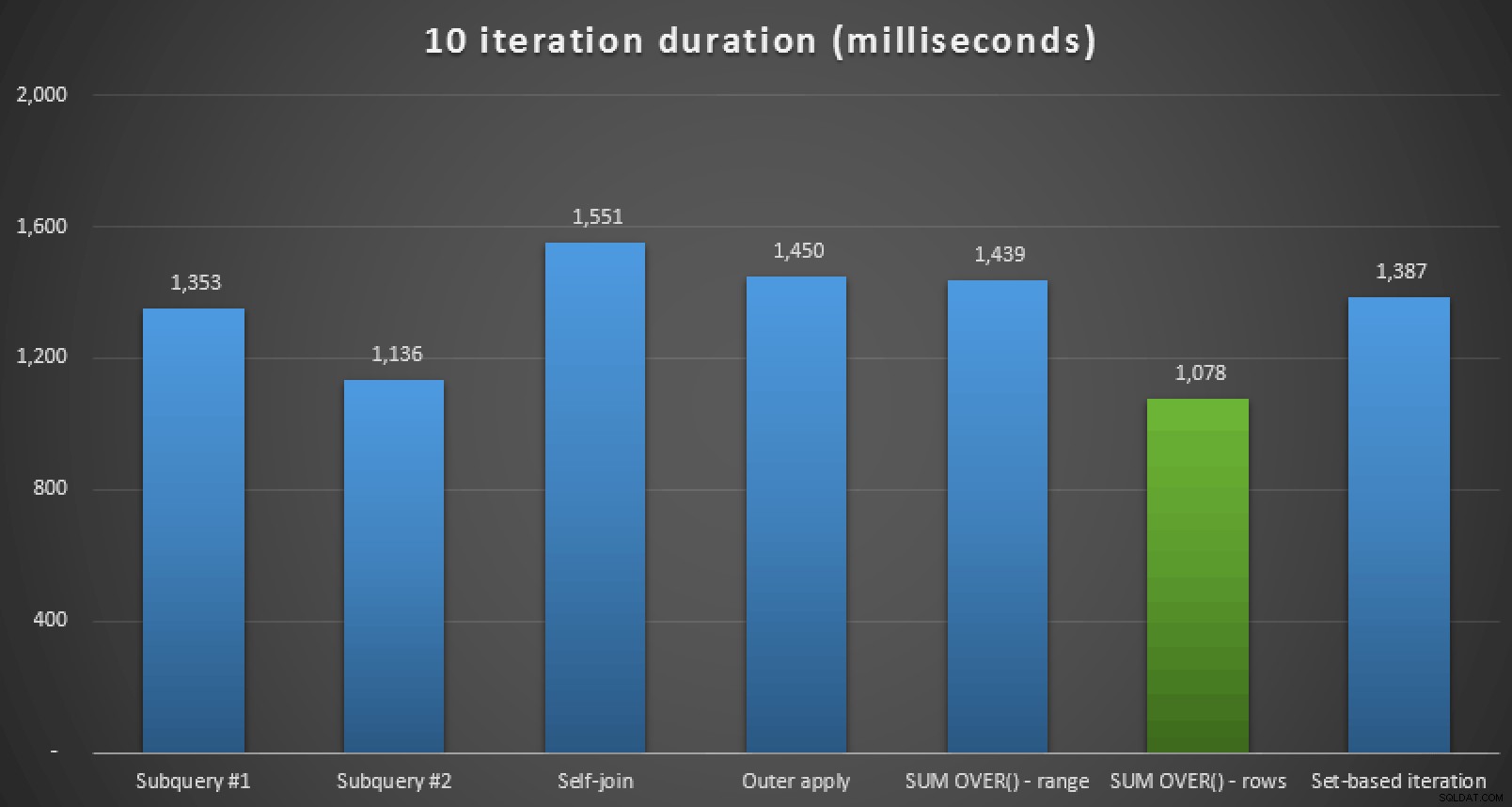
Durée d'exécution, en millisecondes, pour les sept approches (10 itérations )
Donc, si vous êtes sur SQL Server 2012 ou supérieur, la meilleure approche semble être SUM OVER() en utilisant ROWS UNBOUNDED PRECEDING . Si vous n'êtes pas sur SQL Server 2012, la deuxième approche de sous-requête semble être optimale en termes d'exécution, malgré le nombre élevé de lectures par rapport, disons, à OUTER APPLY requête. Dans tous les cas, bien sûr, vous devez tester ces approches, adaptées à votre schéma, sur votre propre système. Vos données, index et autres facteurs peuvent faire en sorte qu'une solution différente soit la plus optimale dans votre environnement.
Autres complexités
Désormais, l'index unique signifie que toute combinaison LicenseNumber + IncidentDate contiendra un seul total cumulé, dans le cas où un conducteur spécifique reçoit plusieurs tickets un jour donné. Cette règle métier permet de simplifier un peu notre logique, en évitant la nécessité d'un bris d'égalité pour produire des totaux cumulés déterministes.
Si vous avez des cas où vous pouvez avoir plusieurs lignes pour une combinaison LicenseNumber + IncidentDate donnée, vous pouvez rompre le lien en utilisant une autre colonne qui aide à rendre la combinaison unique (évidemment, la table source n'aurait plus de contrainte unique sur ces deux colonnes) . Notez que cela est possible même dans les cas où la DATE la colonne est en fait DATETIME – de nombreuses personnes supposent que les valeurs de date/heure sont uniques, mais ce n'est certainement pas toujours garanti, quelle que soit la granularité.
Dans mon cas, je pourrais utiliser le IDENTITY colonne, IncidentID; voici comment j'ajusterais chaque solution (en reconnaissant qu'il peut y avoir de meilleures façons ; je lance simplement des idées) :
/* --------- subquery #1 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND (s.IncidentDate < o.IncidentDate
-- added this line:
OR (s.IncidentDate = o.IncidentDate AND s.IncidentID < o.IncidentID))
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
/* --------- subquery #2 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
-- added this line:
AND IncidentID <= t.IncidentID
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
/* --------- self-join --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
INNER JOIN dbo.SpeedingTickets AS t2
ON t1.LicenseNumber = t2.LicenseNumber
AND t1.IncidentDate >= t2.IncidentDate
-- added this line:
AND t1.IncidentID >= t2.IncidentID
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- outer apply --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
-- added this line:
AND IncidentID <= t1.IncidentID
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- SUM() OVER using RANGE --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID RANGE UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- SUM() OVER using ROWS --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID ROWS UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- set-based iteration --------- */
DECLARE @x TABLE
(
-- added this column, and made it the PK:
IncidentID INT PRIMARY KEY,
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL
);
-- added the additional column to the INSERT/SELECT:
INSERT @x(IncidentID, LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT IncidentID, LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate, IncidentID)
-- and added this tie-breaker column ------------------------------^^^^^^^^^^^^
FROM dbo.SpeedingTickets;
-- the rest of the set-based iteration solution remained unchanged
Une autre complication que vous pouvez rencontrer est lorsque vous ne recherchez pas toute la table, mais plutôt un sous-ensemble (par exemple, dans ce cas, la première semaine de janvier). Vous devrez faire des ajustements en ajoutant WHERE clauses et gardez ces prédicats à l'esprit lorsque vous avez également des sous-requêtes corrélées.