Une transaction en SQL est une unité d'exécution qui regroupe une ou plusieurs tâches ensemble. Une transaction est considérée comme réussie si toutes les tâches qu'elle contient sont exécutées sans erreur.
Cependant, si l'une des tâches d'une transaction ne s'exécute pas, la transaction entière échoue. Une transaction n'a que deux résultats :réussi ou échoué.
Un scénario pratique
Prenons un exemple pratique d'un guichet automatique bancaire (DAB). Vous allez au guichet automatique et il vous demande votre carte. Il exécute une requête pour vérifier si la carte est valide ou non. Ensuite, il vous demande votre code PIN. Encore une fois, il exécute une requête pour faire correspondre le code PIN. Le guichet automatique vous demande alors le montant que vous souhaitez retirer et vous entrez le montant que vous souhaitez. Le guichet automatique exécute une autre requête pour déduire ce montant de votre compte, puis vous distribue les fonds.
Que se passe-t-il si le montant est déduit de votre compte et que le système se bloque en raison d'une panne de courant sans que les billets ne soient distribués ?
Cela pose problème car le client voit les fonds déduits sans avoir reçu d'argent. C'est là que les transactions peuvent être utiles.
En cas de plantage du système ou de toute autre erreur, toutes les tâches de la transaction sont annulées. Par conséquent, dans le cas d'un guichet automatique, le montant sera ajouté à votre compte si vous ne parvenez pas à le retirer pour une raison quelconque.
Qu'est-ce qu'une transaction ?
Dans sa forme la plus simple, un changement dans une table de base de données est une transaction. Par conséquent, les instructions INSERT, UPDATE et DELETE sont toutes des instructions de transaction. Lorsque vous écrivez une requête, une transaction est effectuée. Cependant, cette transaction ne peut pas être annulée. Nous verrons ci-dessous comment les transactions sont créées, validées et annulées, mais commençons par créer des données factices avec lesquelles travailler.
Préparation des données
Exécutez le script suivant sur votre serveur de base de données.
CREATE DATABASE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL,
total_score INT NOT NULL,
)
INSERT INTO student
VALUES (1, 'Jolly', 'Female', 20, 500),
(2, 'Jon', 'Male', 22, 545),
(3, 'Sara', 'Female', 25, 600),
(4, 'Laura', 'Female', 18, 400),
(5, 'Alan', 'Male', 20, 500) Le script SQL ci-dessus crée une base de données schooldb. Dans cette base de données, une table student est créée et des données factices sont ajoutées à cette table.
Exécuter des requêtes sans transactions
Exécutons trois requêtes standard. Nous n'utilisons pas les transactions pour le moment.
INSERT INTO student VALUES (6, 'Suzi', 'Female', 25, 395) UPDATE student SET age = 'Six' WHERE id= 6 DELETE from student WHERE id = 6
Ici, la première requête insère un enregistrement d'étudiant dans la base de données. La deuxième requête met à jour l'âge de l'étudiant et la troisième requête supprime l'enregistrement nouvellement inséré.
Si vous exécutez le script ci-dessus, vous verrez que l'enregistrement sera inséré dans la base de données, puis une erreur se produira lors de l'exécution de la deuxième requête.

Si vous regardez la deuxième requête, nous mettons à jour l'âge en stockant une valeur de chaîne dans la colonne age qui peut stocker des données de type entier. Par conséquent, une erreur sera renvoyée. Cependant, la première requête se terminera toujours avec succès. Cela signifie que si vous sélectionnez tous les enregistrements de la table des étudiants, vous verrez l'enregistrement nouvellement inséré.
[id de table=23 /]
Vous pouvez voir que l'enregistrement avec id=6 et le nom 'Suzi' a été inséré dans la base de données. Mais l'âge n'a pas pu être mis à jour et la deuxième requête a échoué.
Et si nous ne voulons pas cela ? Que se passe-t-il si nous voulons être sûrs que toutes les requêtes s'exécutent avec succès ou qu'aucune des requêtes ne s'exécute du tout ? C'est là que les transactions deviennent utiles.
Exécuter des requêtes avec des transactions
Exécutons maintenant les trois requêtes ci-dessus dans une transaction.
D'abord, voyons comment créer et valider une transaction.
Création d'une transaction
Pour exécuter une ou plusieurs requêtes en tant que transaction, encapsulez simplement les requêtes dans les mots clés BEGIN TRANSACTION et COMMIT TRANSACTION. Le BEGIN TRANSACTION déclare le début d'une TRANSACTION tandis que COMMIT TRANSACTION indique que la transaction est terminée.
Exécutons trois nouvelles requêtes sur la base de données que nous avons créée précédemment en tant que transaction. Nous allons ajouter un nouvel enregistrement pour un nouvel étudiant avec ID 7.
BEGIN TRANSACTION INSERT INTO student VALUES (7, 'Jena', 'Female', 22, 456) UPDATE student SET age = 'Twenty Three' WHERE id= 7 DELETE from student WHERE id = 7 COMMIT TRANSACTION
Lorsque la transaction ci-dessus est exécutée, une erreur se produit à nouveau dans la deuxième requête car une fois de plus une valeur de type chaîne est stockée dans la colonne age qui ne stocke que des données de type entier.
Cependant, étant donné que l'erreur se produit à l'intérieur d'une transaction, toutes les requêtes exécutées avec succès avant que cette erreur ne se produise seront automatiquement annulées. Par conséquent, la première requête qui insère un nouvel enregistrement d'étudiant avec id =7 et le nom 'Jena' sera également annulée.
Maintenant, si vous sélectionnez tous les enregistrements de la table des étudiants, vous verrez que le nouvel enregistrement pour "Jena" n'a pas été inséré.
Restauration manuelle des transactions
Nous savons que si une requête génère une erreur dans une transaction, toute la transaction, y compris toutes les requêtes déjà exécutées, est automatiquement annulée. Cependant, nous pouvons également annuler manuellement une transaction manuellement quand nous le voulons.
Pour annuler une transaction, le mot-clé ROLLBACK est utilisé suivi du nom de la transaction. Pour nommer une transaction, la syntaxe suivante est utilisée :
BEGIN TRANSACTION Transaction_name
Supposons que nous voulions que notre table d'étudiants n'ait aucun enregistrement contenant des noms d'étudiants en double. Nous ajouterons un dossier pour un nouvel étudiant. Nous vérifierons alors si un étudiant avec un nom identique au nom de l'étudiant nouvellement inséré existe dans la base de données. Si l'étudiant portant ce nom n'existe pas déjà, nous validerons notre transaction. Si un étudiant portant ce nom existe, nous annulerons notre transaction. Nous utiliserons des instructions conditionnelles dans notre requête.
Regardez la transaction suivante :
DECLARE @NameCount int BEGIN TRANSACTION AddStudent INSERT INTO student VALUES (8, 'Jacob', 'Male', 21, 600) SELECT @NameCount = COUNT(*) FROM student WHERE name = 'Jacob' IF @NameCount > 1 BEGIN ROLLBACK TRANSACTION AddStudent PRINT 'A student with this name already exists' END ELSE BEGIN COMMIT TRANSACTION AddStudent PRINT 'New record added successfully' END
Examinez attentivement le script ci-dessus. Beaucoup de choses se passent ici.
Dans la première ligne, nous créons une variable SQL de type entier NameCount.
Ensuite, nous commençons une transaction nommée "AddStudent". Vous pouvez donner n'importe quel nom à votre transaction.
Dans la transaction, nous avons inséré un nouvel enregistrement pour un étudiant avec l'identifiant = 8 et le nom "Jacob".
Ensuite, en utilisant la fonction d'agrégation COUNT, nous comptons le nombre d'enregistrements d'élèves dont le nom est "Jacob" et stockons le résultat dans la variable "NameCount".
Si la valeur de la variable est supérieure à 1, cela signifie qu'un étudiant portant le nom de "Jacob" existe déjà dans la base de données. Dans ce cas, nous ANNULONS notre transaction et IMPRIMONS un message à l'écran indiquant qu'un étudiant portant ce nom existe déjà.
Si ce n'est pas le cas, nous validons notre transaction et affichons le message "Nouvel enregistrement ajouté avec succès".
Lorsque vous exécutez la transaction ci-dessus pour la première fois, il n'y aura pas d'enregistrement d'étudiant avec le nom "Jacob". Par conséquent, la transaction sera validée et le message suivant sera imprimé :

Essayez maintenant d'exécuter le script SQL suivant sur le serveur :
DECLARE @NameCount int BEGIN TRANSACTION AddStudent INSERT INTO student VALUES (9, 'Jacob', 'Male', 22, 400) SELECT @NameCount = COUNT(*) FROM student WHERE name = 'Jacob' IF @NameCount > 1 BEGIN ROLLBACK TRANSACTION AddStudent PRINT 'A student with this name already exists' END ELSE BEGIN COMMIT TRANSACTION PRINT 'New record added successfully' END
Ici encore, nous insérons le dossier étudiant avec id =9 et le nom 'Jacob'. Puisqu'un dossier étudiant portant le nom de "Jacob" existe déjà dans la base de données, la transaction sera annulée et le message suivant sera imprimé :
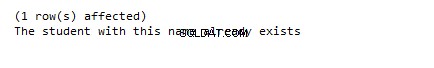
Liens utiles
- Cours sur les transactions SQL