Le besoin le plus courant pour supprimer le temps d'une valeur datetime est d'obtenir toutes les lignes qui représentent des commandes (ou des visites ou des accidents) qui se sont produites un jour donné. Cependant, toutes les techniques utilisées pour le faire ne sont pas efficaces ou même sûres.
TL;Version DR
Si vous voulez une requête de plage sûre qui fonctionne bien, utilisez une plage ouverte ou, pour les requêtes d'un jour sur SQL Server 2008 et versions ultérieures, utilisez CONVERT(DATE) :
DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
Quelques mises en garde :
- Soyez prudent avec le
DATEDIFFapproche, car certaines anomalies d'estimation de cardinalité peuvent survenir (voir cet article de blog et la question Stack Overflow qui l'a motivée pour plus d'informations). - Bien que la dernière utilise toujours potentiellement une recherche d'index (contrairement à toutes les autres expressions non sargables que j'ai jamais rencontrées), vous devez faire attention à la conversion de la colonne en une date avant de comparer. Cette approche peut également produire des estimations de cardinalité fondamentalement erronées. Voir cette réponse de Martin Smith pour plus de détails.
Dans tous les cas, lisez la suite pour comprendre pourquoi ce sont les deux seules approches que je recommande.
Toutes les approches ne sont pas sûres
Comme exemple dangereux, je vois celui-ci beaucoup utilisé :
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);
Il y a quelques problèmes avec cette approche, mais le plus notable est le calcul de la "fin" d'aujourd'hui - si le type de données sous-jacent est SMALLDATETIME , cette plage finale va s'arrondir ; si c'est DATETIME2 , vous pourriez théoriquement manquer des données à la fin de la journée. Si vous choisissez des minutes ou des nanosecondes ou tout autre espace pour s'adapter au type de données actuel, votre requête commencera à avoir un comportement étrange si le type de données change plus tard (et soyons honnêtes, si quelqu'un modifie le type de cette colonne pour qu'il soit plus ou moins granulaire, ils ne courent pas partout pour vérifier chaque requête qui y accède). Le fait de devoir coder de cette manière en fonction du type de données de date/heure dans la colonne sous-jacente est fragmenté et sujet aux erreurs. Il est préférable d'utiliser des plages de dates ouvertes pour cela :
J'en parle beaucoup plus dans quelques anciens articles de blog :
- Qu'est-ce que BETWEEN et le diable ont en commun ?
- Mauvaises habitudes à éliminer :mauvaise gestion des requêtes de date/plage
Mais je voulais comparer les performances de certaines des approches les plus courantes que je vois là-bas. J'ai toujours utilisé des plages ouvertes et depuis SQL Server 2008, nous pouvons utiliser CONVERT(DATE) et utilisez toujours un index sur cette colonne, ce qui est assez puissant.
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
Un test de performances simple
Pour effectuer un test de performance initial très simple, j'ai fait ce qui suit pour chacune des déclarations ci-dessus, en définissant une variable à la sortie du calcul 100 000 fois :
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
Je l'ai fait trois fois pour chaque méthode, et elles ont toutes duré entre 34 et 38 secondes. Donc à proprement parler, il y a des différences très négligeables dans ces méthodes lors de l'exécution des opérations en mémoire :
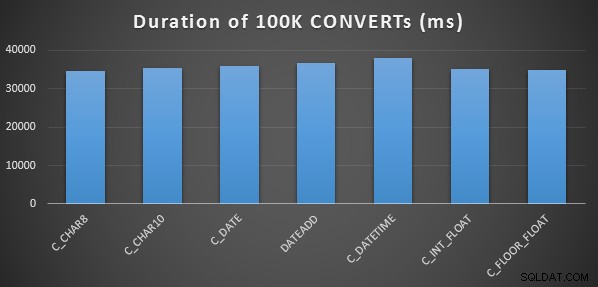
Un test de performances plus élaboré
Je voulais aussi comparer ces méthodes avec différents types de données (DATETIME , SMALLDATETIME , et DATETIME2 ), sur un index clusterisé et un tas, et avec et sans compression des données. J'ai donc d'abord créé une base de données simple. Grâce à l'expérimentation, j'ai déterminé que la taille optimale pour gérer 120 millions de lignes et toute l'activité de journal qui pourrait survenir (et pour empêcher les événements de croissance automatique d'interférer avec les tests) était un fichier de données de 20 Go et un journal de 3 Go :
CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
Ensuite, j'ai créé 12 tables :
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[Ensuite, répétez à nouveau pour DATETIME et DATETIME2.]
Ensuite, j'ai inséré 10 000 000 lignes dans chaque table. Pour ce faire, j'ai créé une vue qui générerait à chaque fois les mêmes 10 000 000 dates :
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
Cela m'a permis de remplir les tables de cette façon :
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[Ensuite, répétez à nouveau pour les tas et l'index clusterisé non compressé. J'ai mis un CHECKPOINT entre chaque insertion pour assurer la réutilisation des logs (le modèle de récupération est simple).]
INSÉRER les durées et l'espace utilisé
Voici les horaires de chaque insertion (tels qu'ils ont été capturés avec Plan Explorer) :
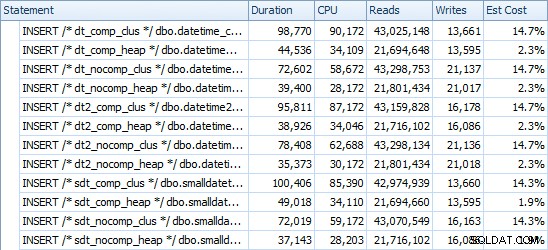
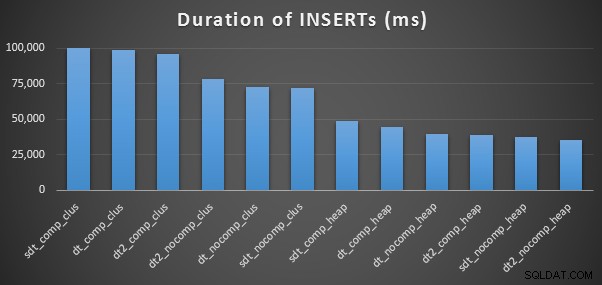
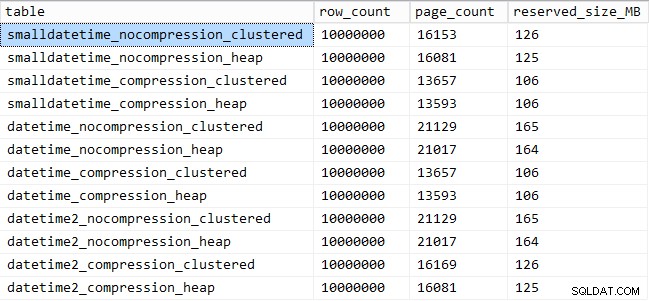
Et voici la quantité d'espace occupé par chaque table :
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
Performances du modèle de requête
Ensuite, j'ai entrepris de tester deux modèles de requête différents pour les performances :
- Compter les lignes pour un jour spécifique, en utilisant les sept approches ci-dessus, ainsi que la plage de dates ouverte
- Convertir les 10 000 000 de lignes à l'aide des sept approches ci-dessus, ainsi que simplement renvoyer les données brutes (car le formatage côté client peut être meilleur)
[À l'exception du FLOAT méthodes et le DATETIME2 colonne, puisque cette conversion n'est pas légale.]
Pour la première question, les requêtes ressemblent à ceci (répétées pour chaque type de table) :
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; Les résultats par rapport à un index clusterisé ressemblent à ceci (cliquez pour agrandir) :
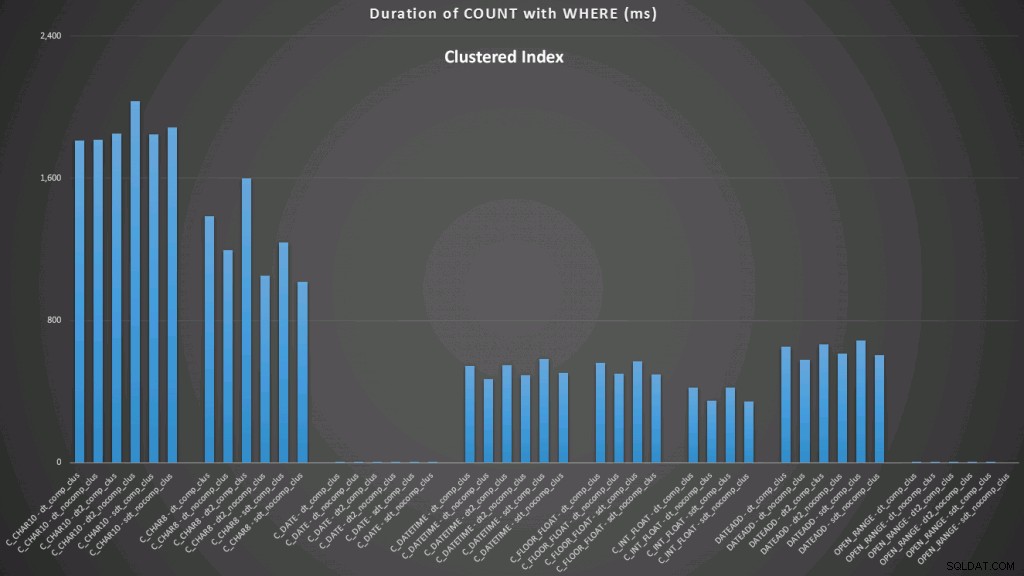
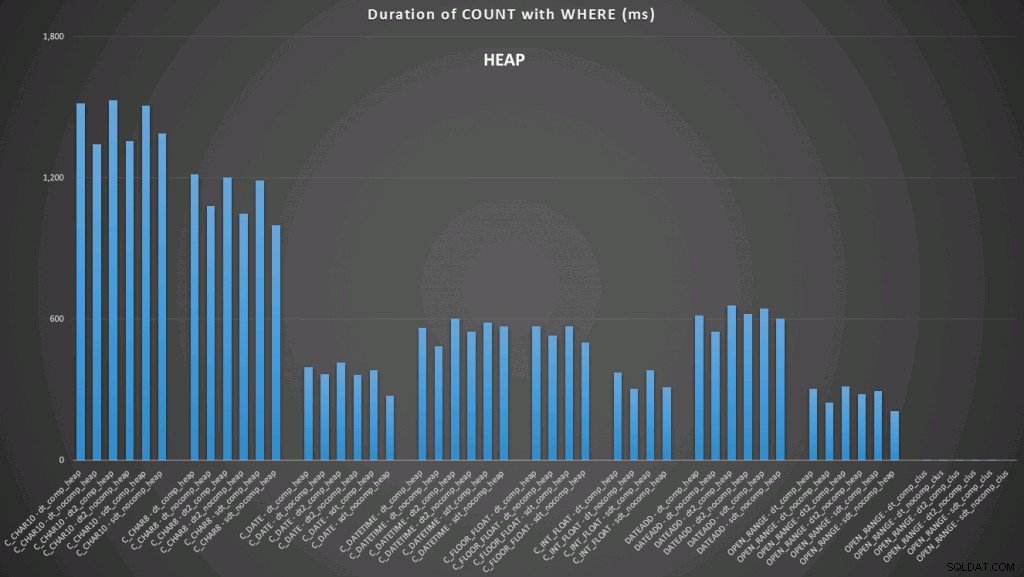
Ici, nous voyons que la conversion en date et la plage ouverte utilisant un indice sont les plus performantes. Cependant, contre un tas, la conversion en date prend en fait un certain temps, ce qui fait de la plage ouverte le choix optimal (cliquez pour agrandir) :
Et voici le deuxième ensemble de requêtes (encore une fois, répétant pour chaque type de table) :
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; En se concentrant sur les résultats des tables avec un index clusterisé, il est clair que la conversion à ce jour était très proche de la simple sélection des données brutes (cliquez pour agrandir) :
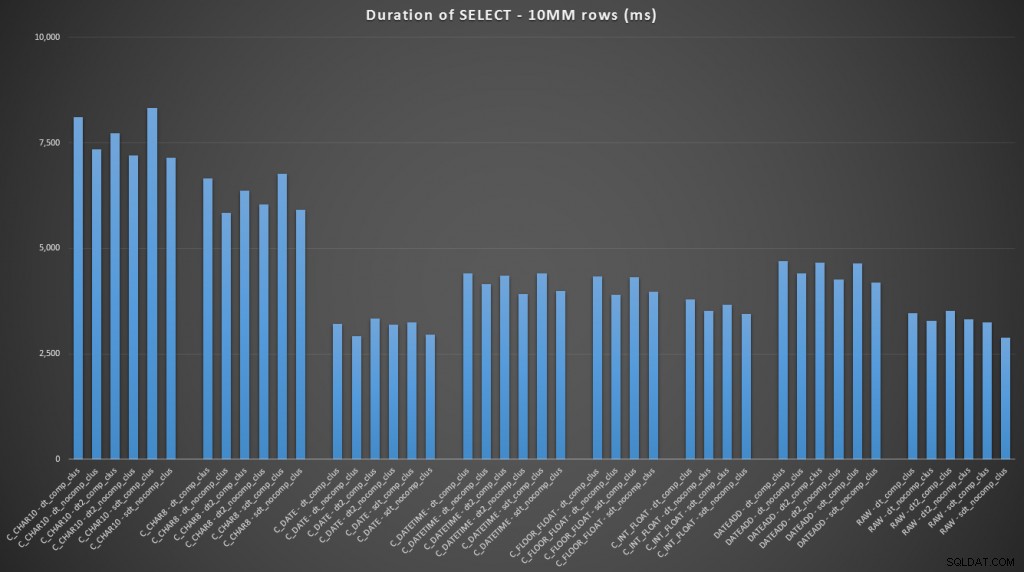
(Pour cet ensemble de requêtes, le tas a montré des résultats très similaires - pratiquement impossibles à distinguer.)
Conclusion
Au cas où vous voudriez passer à la punchline, ces résultats montrent que les conversions en mémoire ne sont pas importantes, mais si vous convertissez des données à la sortie d'une table (ou dans le cadre d'un prédicat de recherche), la méthode que vous choisissez peut avoir un impact dramatique sur les performances. Conversion en DATE (pour un seul jour) ou l'utilisation d'une plage de dates ouverte dans tous les cas donnera les meilleures performances, tandis que la méthode la plus populaire - la conversion en chaîne - est absolument catastrophique.
Nous voyons également que la compression peut avoir un effet décent sur l'espace de stockage, avec un impact très mineur sur les performances des requêtes. L'effet sur les performances d'insertion semble dépendre autant du fait que la table possède ou non un index clusterisé que de l'activation ou non de la compression. Cependant, avec un index clusterisé en place, il y avait une augmentation notable de la durée nécessaire pour insérer 10 millions de lignes. Quelque chose à garder à l'esprit et à équilibrer avec les économies d'espace disque.
De toute évidence, il pourrait y avoir beaucoup plus de tests impliqués, avec des charges de travail plus substantielles et variées, que j'explorerai peut-être plus en détail dans un prochain article.



