Dans la partie 1 de cette série, vous avez utilisé Flask et Connexion pour créer une API REST fournissant des opérations CRUD à une simple structure en mémoire appelée PEOPLE . Cela a fonctionné pour démontrer comment le module Connexion vous aide à créer une belle API REST avec une documentation interactive.
Comme certains l'ont noté dans les commentaires de la partie 1, les PEOPLE structure est réinitialisée à chaque redémarrage de l'application. Dans cet article, vous apprendrez à stocker les PEOPLE structure et les actions fournies par l'API à une base de données utilisant SQLAlchemy et Marshmallow.
SQLAlchemy fournit un modèle relationnel objet (ORM), qui stocke les objets Python dans une représentation de base de données des données de l'objet. Cela peut vous aider à continuer à penser de manière Pythonique et à ne pas vous soucier de la manière dont les données d'objet seront représentées dans une base de données.
Marshmallow fournit des fonctionnalités pour sérialiser et désérialiser les objets Python lorsqu'ils sortent et entrent dans notre API REST basée sur JSON. Marshmallow convertit les instances de classe Python en objets pouvant être convertis en JSON.
Vous pouvez trouver le code Python de cet article ici.
Bonus gratuit : Cliquez ici pour télécharger une copie du guide "Exemples d'API REST" et obtenir une introduction pratique aux principes de l'API Python + REST avec des exemples exploitables.
À qui s'adresse cet article
Si vous avez apprécié la partie 1 de cette série, cet article élargit encore plus votre ceinture à outils. Vous utiliserez SQLAlchemy pour accéder à une base de données d'une manière plus pythonique que SQL simple. Vous utiliserez également Marshmallow pour sérialiser et désérialiser les données gérées par l'API REST. Pour ce faire, vous utiliserez les fonctionnalités de programmation orientée objet de base disponibles en Python.
Vous utiliserez également SQLAlchemy pour créer une base de données et interagir avec elle. Ceci est nécessaire pour que l'API REST soit opérationnelle avec le PEOPLE données utilisées dans la partie 1.
L'application Web présentée dans la partie 1 verra ses fichiers HTML et JavaScript modifiés de manière mineure afin de prendre également en charge les modifications. Vous pouvez consulter la version finale du code de la partie 1 ici.
Dépendances supplémentaires
Avant de commencer à créer cette nouvelle fonctionnalité, vous devrez mettre à jour le virtualenv que vous avez créé afin d'exécuter le code de la partie 1 ou en créer un nouveau pour ce projet. La façon la plus simple de le faire après avoir activé votre virtualenv est d'exécuter cette commande :
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Cela ajoute plus de fonctionnalités à votre virtualenv :
-
Flask-SQLAlchemyajoute SQLAlchemy, ainsi que quelques liens avec Flask, permettant aux programmes d'accéder aux bases de données. -
flask-marshmallowajoute les parties Flask de Marshmallow, qui permettent aux programmes de convertir des objets Python vers et depuis des structures sérialisables. -
marshmallow-sqlalchemyajoute des crochets Marshmallow dans SQLAlchemy pour permettre aux programmes de sérialiser et de désérialiser les objets Python générés par SQLAlchemy. -
marshmallowajoute l'essentiel des fonctionnalités de Marshmallow.
Données sur les personnes
Comme mentionné ci-dessus, les PEOPLE La structure de données de l'article précédent est un dictionnaire Python en mémoire. Dans ce dictionnaire, vous avez utilisé le nom de famille de la personne comme clé de recherche. La structure de données ressemblait à ceci dans le code :
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Les modifications que vous apporterez au programme déplaceront toutes les données vers une table de base de données. Cela signifie que les données seront enregistrées sur votre disque et existeront entre les exécutions de server.py programme.
Comme le nom de famille était la clé du dictionnaire, le code limitait la modification du nom de famille d'une personne :seul le prénom pouvait être modifié. De plus, le passage à une base de données vous permettra de changer le nom de famille car il ne sera plus utilisé comme clé de recherche pour une personne.
Conceptuellement, une table de base de données peut être considérée comme un tableau à deux dimensions où les lignes sont des enregistrements et les colonnes sont des champs dans ces enregistrements.
Les tables de base de données ont généralement une valeur entière auto-incrémentée comme clé de recherche des lignes. C'est ce qu'on appelle la clé primaire. Chaque enregistrement de la table aura une clé primaire dont la valeur est unique dans toute la table. Avoir une clé primaire indépendante des données stockées dans la table vous permet de modifier n'importe quel autre champ de la ligne.
Remarque :
La clé primaire auto-incrémentée signifie que la base de données s'occupe de :
- Incrémenter le plus grand champ de clé primaire existant chaque fois qu'un nouvel enregistrement est inséré dans la table
- Utiliser cette valeur comme clé primaire pour les données nouvellement insérées
Cela garantit une clé primaire unique à mesure que la table grandit.
Vous allez suivre une convention de base de données consistant à nommer la table au singulier, de sorte que la table s'appellera person . Traduire nos PEOPLE structure ci-dessus dans une table de base de données nommée person vous donne ceci :
| id_personne | nom | fname | horodatage |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Pâques | Lapin | 2018-08-08 21:16:01.886834 |
Chaque colonne de la table a un nom de champ comme suit :
person_id: champ clé primaire pour chaque personnelname: nom de famille de la personnefname: prénom de la personnetimestamp: horodatage associé aux actions d'insertion/mise à jour
Interaction avec la base de données
Vous allez utiliser SQLite comme moteur de base de données pour stocker les PEOPLE Les données. SQLite est la base de données la plus largement distribuée dans le monde, et elle est fournie gratuitement avec Python. Il est rapide, effectue tout son travail à l'aide de fichiers et convient à un grand nombre de projets. Il s'agit d'un RDBMS (Relational Database Management System) complet qui inclut SQL, le langage de nombreux systèmes de bases de données.
Pour le moment, imaginez la person table existe déjà dans une base de données SQLite. Si vous avez déjà utilisé RDBMS, vous connaissez probablement SQL, le langage de requête structuré que la plupart des RDBMS utilisent pour interagir avec la base de données.
Contrairement aux langages de programmation comme Python, SQL ne définit pas comment pour obtenir les données :elles décrivent quoi les données sont souhaitées, en laissant le comment jusqu'au moteur de base de données.
Une requête SQL récupérant toutes les données de notre person tableau, trié par nom de famille, ressemblerait à ceci :
SELECT * FROM person ORDER BY 'lname';
Cette requête indique au moteur de base de données d'obtenir tous les champs de la table person et de les trier dans l'ordre croissant par défaut en utilisant le lname domaine.
Si vous deviez exécuter cette requête sur une base de données SQLite contenant la person table, les résultats seraient un ensemble d'enregistrements contenant toutes les lignes de la table, chaque ligne contenant les données de tous les champs constituant une ligne. Vous trouverez ci-dessous un exemple utilisant l'outil de ligne de commande SQLite exécutant la requête ci-dessus sur la person table de base de données :
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
La sortie ci-dessus est une liste de toutes les lignes de person table de base de données avec des caractères pipe ('|') séparant les champs de la ligne, ce qui est fait à des fins d'affichage par SQLite.
Python est tout à fait capable de s'interfacer avec de nombreux moteurs de base de données et d'exécuter la requête SQL ci-dessus. Les résultats seraient très probablement une liste de tuples. La liste externe contient tous les enregistrements de la person table. Chaque tuple interne individuel contiendrait toutes les données représentant chaque champ défini pour une ligne de table.
Obtenir des données de cette façon n'est pas très Pythonique. La liste des enregistrements est correcte, mais chaque enregistrement individuel n'est qu'un tuple de données. C'est au programme de connaître l'index de chaque champ afin de récupérer un champ particulier. Le code Python suivant utilise SQLite pour montrer comment exécuter la requête ci-dessus et afficher les données :
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Le programme ci-dessus effectue les opérations suivantes :
-
Ligne 1 importe le
sqlite3module. -
Ligne 3 crée une connexion au fichier de base de données.
-
Ligne 4 crée un curseur à partir de la connexion.
-
Ligne 5 utilise le curseur pour exécuter un
SQLrequête exprimée sous forme de chaîne. -
Ligne 6 récupère tous les enregistrements renvoyés par le
SQLrequête et les attribue auxpeoplevariables. -
Lignes 7 et 8 parcourir les
peoplelist variable et imprimez le prénom et le nom de chaque personne.
Les people variable de Ligne 6 ci-dessus ressemblerait à ceci en Python :
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
La sortie du programme ci-dessus ressemble à ceci :
Kent Brockman
Bunny Easter
Doug Farrell
Dans le programme ci-dessus, il faut savoir que le prénom d'une personne est à l'index 2 , et le nom de famille d'une personne est à l'index 1 . Pire, la structure interne de person doit également être connu chaque fois que vous passez la variable d'itération person en tant que paramètre d'une fonction ou d'une méthode.
Ce serait bien mieux si ce que vous avez obtenu en retour pour person était un objet Python, où chacun des champs est un attribut de l'objet. C'est l'une des choses que fait SQLAlchemy.
Petites tables Bobby
Dans le programme ci-dessus, l'instruction SQL est une simple chaîne transmise directement à la base de données pour exécution. Dans ce cas, ce n'est pas un problème car le SQL est un littéral de chaîne entièrement sous le contrôle du programme. Cependant, le cas d'utilisation de votre API REST prendra l'entrée utilisateur de l'application Web et l'utilisera pour créer des requêtes SQL. Cela peut ouvrir votre application aux attaques.
Vous vous souviendrez de la partie 1 que l'API REST pour obtenir une seule person des PEOPLE les données ressemblaient à ceci :
GET /api/people/{lname}
Cela signifie que votre API attend une variable, lname , dans le chemin du point de terminaison de l'URL, qu'il utilise pour rechercher une seule person . Modifier le code Python SQLite ci-dessus pour ce faire ressemblerait à ceci :
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
L'extrait de code ci-dessus effectue les opérations suivantes :
-
Ligne 1 définit le
lnamevariable en'Farrell'. Cela proviendrait du chemin du point de terminaison de l'URL de l'API REST. -
Ligne 2 utilise le formatage de chaîne Python pour créer une chaîne SQL et l'exécuter.
Pour garder les choses simples, le code ci-dessus définit le lname variable à une constante, mais en réalité, cela proviendrait du chemin du point de terminaison de l'URL de l'API et pourrait être tout ce qui est fourni par l'utilisateur. Le SQL généré par le formatage de chaîne ressemble à ceci :
SELECT * FROM person WHERE lname = 'Farrell'
Lorsque ce SQL est exécuté par la base de données, il recherche la person table pour un enregistrement où le nom de famille est égal à 'Farrell' . C'est ce qui est prévu, mais tout programme qui accepte les entrées de l'utilisateur est également ouvert aux utilisateurs malveillants. Dans le programme ci-dessus, où le lname variable est définie par une entrée fournie par l'utilisateur, cela ouvre votre programme à ce qu'on appelle une attaque par injection SQL. C'est ce qu'on appelle affectueusement les tables Little Bobby :
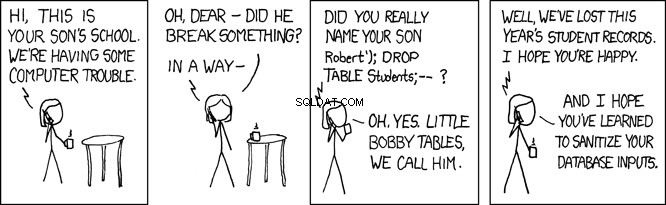
Par exemple, imaginez qu'un utilisateur malveillant appelle votre API REST de cette manière :
GET /api/people/Farrell');DROP TABLE person;
La requête API REST ci-dessus définit le lname variable à 'Farrell');DROP TABLE person;' , qui dans le code ci-dessus générerait cette instruction SQL :
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
L'instruction SQL ci-dessus est valide et, lorsqu'elle est exécutée par la base de données, elle trouvera un enregistrement où lname correspond à 'Farrell' . Ensuite, il trouvera le caractère délimiteur de l'instruction SQL ; et ira de l'avant et laissera tomber toute la table. Cela détruirait essentiellement votre application.
Vous pouvez protéger votre programme en désinfectant toutes les données que vous obtenez des utilisateurs de votre application. La désinfection des données dans ce contexte signifie que votre programme examine les données fournies par l'utilisateur et s'assure qu'elles ne contiennent rien de dangereux pour le programme. Cela peut être difficile à faire correctement et devrait être fait partout où les données utilisateur interagissent avec la base de données.
Il existe un autre moyen beaucoup plus simple :utilisez SQLAlchemy. Il nettoiera les données utilisateur pour vous avant de créer des instructions SQL. C'est un autre gros avantage et une raison d'utiliser SQLAlchemy lorsque vous travaillez avec des bases de données.
Modélisation des données avec SQLAlchemy
SQLAlchemy est un gros projet et fournit de nombreuses fonctionnalités pour travailler avec des bases de données utilisant Python. L'une des choses qu'il fournit est un ORM, ou Object Relational Mapper, et c'est ce que vous allez utiliser pour créer et travailler avec la person tableau de la base de données. Cela vous permet de mapper une ligne de champs de la table de base de données à un objet Python.
La programmation orientée objet vous permet de connecter des données avec un comportement, les fonctions qui opèrent sur ces données. En créant des classes SQLAlchemy, vous pouvez connecter les champs des lignes de la table de la base de données au comportement, ce qui vous permet d'interagir avec les données. Voici la définition de la classe SQLAlchemy pour les données dans le person table de base de données :
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
La classe Person hérite de db.Model , auquel vous accéderez lorsque vous commencerez à créer le code du programme. Pour l'instant, cela signifie que vous héritez d'une classe de base appelée Model , fournissant des attributs et des fonctionnalités communs à toutes les classes qui en sont dérivées.
Les autres définitions sont des attributs de niveau classe définis comme suit :
-
__tablename__ = 'person'connecte la définition de classe à lapersontable de base de données. -
person_id = db.Column(db.Integer, primary_key=True)crée une colonne de base de données contenant un entier servant de clé primaire pour la table. Cela indique également à la base de données queperson_idsera une valeur entière auto-incrémentée. -
lname = db.Column(db.String)crée le champ du nom de famille, une colonne de base de données contenant une valeur de chaîne. -
fname = db.Column(db.String)crée le champ prénom, une colonne de base de données contenant une valeur de chaîne. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)crée un champ d'horodatage, une colonne de base de données contenant une valeur de date/heure. Ledefault=datetime.utcnowparamètre définit par défaut la valeur d'horodatage sur leutcnowactuel valeur lors de la création d'un enregistrement. Leonupdate=datetime.utcnowle paramètre met à jour l'horodatage avec leutcnowactuel valeur lorsque l'enregistrement est mis à jour.
Remarque :Horodatages UTC
Vous vous demandez peut-être pourquoi l'horodatage de la classe ci-dessus est par défaut et est mis à jour par datetime.utcnow() méthode, qui renvoie un UTC, ou Coordinated Universal Time. C'est un moyen de normaliser la source de votre horodatage.
La source, ou temps zéro, est une ligne allant du nord au sud du pôle nord au sud de la Terre à travers le Royaume-Uni. Il s'agit du fuseau horaire zéro à partir duquel tous les autres fuseaux horaires sont décalés. En l'utilisant comme source de temps zéro, vos horodatages sont décalés par rapport à ce point de référence standard.
Si votre application est accessible à partir de différents fuseaux horaires, vous disposez d'un moyen d'effectuer des calculs de date/heure. Tout ce dont vous avez besoin est un horodatage UTC et le fuseau horaire de destination.
Si vous deviez utiliser les fuseaux horaires locaux comme source d'horodatage, vous ne pourriez pas effectuer de calculs de date/heure sans informations sur les fuseaux horaires locaux décalés par rapport à l'heure zéro. Sans les informations de source d'horodatage, vous ne pourriez pas faire de comparaisons de date/heure ou de calculs du tout.
Travailler avec un horodatage basé sur UTC est une bonne norme à suivre. Voici un site de boîte à outils pour travailler avec et mieux les comprendre.
Où allez-vous avec cette Person définition de classe ? L'objectif final est de pouvoir exécuter une requête à l'aide de SQLAlchemy et de récupérer une liste d'instances de Person classe. À titre d'exemple, regardons l'instruction SQL précédente :
SELECT * FROM people ORDER BY lname;
Montrez le même petit exemple de programme ci-dessus, mais en utilisant maintenant SQLAlchemy :
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
En ignorant la ligne 1 pour le moment, ce que vous voulez, c'est toute la person enregistrements triés par ordre croissant par le lname domaine. Ce que vous récupérez des instructions SQLAlchemy Person.query.order_by(Person.lname).all() est une liste de Person objets pour tous les enregistrements de la person table de base de données dans cet ordre. Dans le programme ci-dessus, les people la variable contient la liste de Person objets.
Le programme itère sur les people variable, prenant chaque person tour à tour et imprimer le prénom et le nom de la personne à partir de la base de données. Notez que le programme n'a pas besoin d'utiliser des index pour obtenir le fname ou lname valeurs :il utilise les attributs définis sur le Person objet.
L'utilisation de SQLAlchemy vous permet de penser en termes d'objets avec un comportement plutôt qu'en SQL brut . Cela devient encore plus avantageux lorsque vos tables de base de données deviennent plus grandes et les interactions plus complexes.
Sérialisation/Désérialisation des données modélisées
Travailler avec des données modélisées SQLAlchemy dans vos programmes est très pratique. C'est particulièrement pratique dans les programmes qui manipulent les données, en effectuant peut-être des calculs ou en les utilisant pour créer des présentations à l'écran. Votre application est une API REST fournissant essentiellement des opérations CRUD sur les données, et en tant que telle, elle n'effectue pas beaucoup de manipulation de données.
L'API REST fonctionne avec les données JSON, et ici vous pouvez rencontrer un problème avec le modèle SQLAlchemy. Étant donné que les données renvoyées par SQLAlchemy sont des instances de classe Python, Connexion ne peut pas sérialiser ces instances de classe en données au format JSON. Rappelez-vous de la partie 1 que Connexion est l'outil que vous avez utilisé pour concevoir et configurer l'API REST à l'aide d'un fichier YAML, et y connecter des méthodes Python.
Dans ce contexte, la sérialisation signifie la conversion d'objets Python, qui peuvent contenir d'autres objets Python et des types de données complexes, en structures de données plus simples pouvant être analysées en types de données JSON, répertoriés ici :
string: un type de chaînenumber: nombres pris en charge par Python (entiers, flottants, longs)object: un objet JSON, qui équivaut à peu près à un dictionnaire Pythonarray: à peu près équivalent à une liste Pythonboolean: représenté dans JSON commetrueoufalse, mais en Python commeTrueouFalsenull: essentiellement unNoneen Python
Par exemple, votre Person la classe contient un horodatage, qui est un Python DateTime . Il n'y a pas de définition de date/heure dans JSON, donc l'horodatage doit être converti en chaîne pour exister dans une structure JSON.
Votre Person class est assez simple pour obtenir les attributs de données et créer manuellement un dictionnaire à renvoyer à partir de nos points de terminaison d'URL REST ne serait pas très difficile. Dans une application plus complexe avec de nombreux modèles SQLAlchemy plus grands, ce ne serait pas le cas. Une meilleure solution consiste à utiliser un module appelé Marshmallow pour faire le travail à votre place.
Marshmallow vous aide à créer un PersonSchema classe, qui est comme SQLAlchemy Person classe que nous avons créée. Ici cependant, au lieu de mapper les tables de base de données et les noms de champs à la classe et à ses attributs, le PersonSchema class définit comment les attributs d'une classe seront convertis en formats compatibles JSON. Voici la définition de la classe Marshmallow pour les données dans notre person tableau :
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
La classe PersonSchema hérite de ma.ModelSchema , auquel vous accéderez lorsque vous commencerez à créer le code du programme. Pour l'instant, cela signifie PersonSchema hérite d'une classe de base Marshmallow appelée ModelSchema , fournissant des attributs et des fonctionnalités communs à toutes les classes qui en sont dérivées.
Le reste de la définition est le suivant :
-
class Metadéfinit une classe nomméeMetaau sein de votre classe. LeModelSchemaclasse que lePersonSchemala classe hérite de looks pour ceMetainterne class et l'utilise pour trouver le modèle SQLAlchemyPersonet ledb.session. C'est ainsi que Marshmallow trouve les attributs dans laPersonclass et le type de ces attributs afin qu'il sache comment les sérialiser/désérialiser. -
modelindique à la classe quel modèle SQLAlchemy utiliser pour sérialiser/désérialiser les données vers et depuis. -
db.sessionindique à la classe quelle session de base de données utiliser pour introspecter et déterminer les types de données d'attribut.
Où allez-vous avec cette définition de classe ? Vous voulez pouvoir sérialiser une instance d'un Person classe en données JSON, et pour désérialiser les données JSON et créer une Person instances de classe à partir de celui-ci.
Créer la base de données initialisée
SQLAlchemy gère de nombreuses interactions spécifiques à des bases de données particulières et vous permet de vous concentrer sur les modèles de données ainsi que sur leur utilisation.
Maintenant que vous allez réellement créer une base de données, comme mentionné précédemment, vous allez utiliser SQLite. Vous faites cela pour plusieurs raisons. Il est livré avec Python et n'a pas besoin d'être installé en tant que module séparé. Il enregistre toutes les informations de la base de données dans un seul fichier et est donc facile à configurer et à utiliser.
L'installation d'un serveur de base de données séparé comme MySQL ou PostgreSQL fonctionnerait bien, mais nécessiterait d'installer ces systèmes et de les rendre opérationnels, ce qui dépasse le cadre de cet article.
Étant donné que SQLAlchemy gère la base de données, à bien des égards, peu importe la base de données sous-jacente.
Vous allez créer un nouveau programme utilitaire appelé build_database.py pour créer et initialiser le SQLite people.db fichier de base de données contenant votre person tableau de la base de données. En cours de route, vous créerez deux modules Python, config.py et models.py , qui sera utilisé par build_database.py et le server.py modifié de la partie 1.
Voici où vous pouvez trouver le code source des modules que vous êtes sur le point de créer, qui sont présentés ici :
-
config.pyobtient les modules nécessaires importés dans le programme et configurés. Cela inclut Flask, Connexion, SQLAlchemy et Marshmallow. Parce qu'il sera utilisé à la fois parbuild_database.pyetserver.py, certaines parties de la configuration ne s'appliqueront qu'auserver.pyapplication. -
models.pyest le module où vous allez créer laPersonSQLAlchemy etPersonSchemaDéfinitions de classe Marshmallow décrites ci-dessus. Ce module dépend deconfig.pypour certains des objets qui y sont créés et configurés.
Module de configuration
Le config.py module, comme son nom l'indique, est l'endroit où toutes les informations de configuration sont créées et initialisées. Nous allons utiliser ce module à la fois pour notre build_database.py fichier programme et le server.py qui sera bientôt mis à jour fichier de l'article de la partie 1. Cela signifie que nous allons configurer Flask, Connexion, SQLAlchemy et Marshmallow ici.
Même si le build_database.py programme n'utilise pas Flask, Connexion ou Marshmallow, il utilise SQLAlchemy pour créer notre connexion à la base de données SQLite. Voici le code pour le config.py modules :
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Voici ce que fait le code ci-dessus :
-
Lignes 2 à 4 importez Connexion comme vous l'avez fait dans le
server.pyprogramme de la partie 1. Il importe égalementSQLAlchemyduflask_sqlalchemymodule. Cela donne à votre programme l'accès à la base de données. Enfin, il importeMarshmallowduflask_marshamllowmodule. -
Ligne 6 crée la variable
basedirpointant vers le répertoire dans lequel le programme s'exécute. -
Ligne 9 utilise le
basedirvariable pour créer l'instance de l'application Connexion et lui donner le chemin vers leswagger.ymlfichier. -
Ligne 12 crée une variable
app, qui est l'instance Flask initialisée par Connexion. -
Lignes 15 utilise l'
appvariable pour configurer les valeurs utilisées par SQLAlchemy. D'abord, il définitSQLALCHEMY_ECHOàTrue. Cela amène SQLAlchemy à faire écho aux instructions SQL qu'il exécute sur la console. Ceci est très utile pour déboguer les problèmes lors de la construction de programmes de base de données. Définissez ceci surFalsepour les environnements de production. -
Ligne 16 définit
SQLALCHEMY_DATABASE_URIàsqlite:////' + os.path.join(basedir, 'people.db'). Cela indique à SQLAlchemy d'utiliser SQLite comme base de données et un fichier nommépeople.dbdans le répertoire courant en tant que fichier de base de données. Différents moteurs de base de données, comme MySQL et PostgreSQL, auront différentsSQLALCHEMY_DATABASE_URIchaînes pour les configurer. -
Ligne 17 définit
SQLALCHEMY_TRACK_MODIFICATIONSàFalse, en désactivant le système d'événements SQLAlchemy, qui est activé par défaut. Le système d'événements génère des événements utiles dans les programmes événementiels, mais ajoute une surcharge importante. Puisque vous ne créez pas de programme événementiel, désactivez cette fonctionnalité. -
Ligne 19 crée la
dbvariable en appelantSQLAlchemy(app). Cela initialise SQLAlchemy en passant leapples informations de configuration viennent d'être définies. Ladbla variable est ce qui est importé dans lebuild_database.pyprogramme pour lui donner accès à SQLAlchemy et à la base de données. Il servira le même objectif dans leserver.pyprogramme etpeople.pymodule. -
Ligne 23 crée le
mavariable en appelantMarshmallow(app). Cela initialise Marshmallow et lui permet d'introspecter les composants SQLAlchemy attachés à l'application. C'est pourquoi Marshmallow est initialisé après SQLAlchemy.
Module Modèles
Le models.py module est créé pour fournir la Person et PersonSchema classes exactement comme décrit dans les sections ci-dessus sur la modélisation et la sérialisation des données. Voici le code de ce module :
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Voici ce que fait le code ci-dessus :
-
Ligne 1 importe le
datetimeobjet de ladatetimemodule fourni avec Python. Cela vous donne un moyen de créer un horodatage dans lePersonclasse. -
Ligne 2 importe la
dbetmavariables d'instance définies dans leconfig.pymodule. Cela donne au module l'accès aux attributs et méthodes SQLAlchemy attachés audbvariable, et les attributs et méthodes Marshmallow attachés aumavariables. -
Lignes 4 à 9 définir la
Personclass comme indiqué dans la section sur la modélisation des données ci-dessus, mais maintenant vous savez où se trouve ledb.Modeldont la classe hérite. Cela donne laPersonles fonctionnalités de la classe SQLAlchemy, comme une connexion à la base de données et l'accès à ses tables. -
Lignes 11 à 14 définir le
PersonSchemaclass as was discussed in the data serialzation section above. This class inherits fromma.ModelSchemaand gives thePersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People Les données. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodule. -
Line 3 imports the
Personclass definition from themodels.pymodule. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()appel. This creates the database by using thedbinstance imported from theconfigmodule. Ladbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonclasse. After it is instantiated, you call thedb.session.add(p)une fonction. This uses the database connection instancedbto access thesessionobjet. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionobject. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Remarque : At Line 22, no data has been added to the database. Everything is being saved within the session objet. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py dossier. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname value.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Description |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people table. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml file.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodule. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeopleliste. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Remarque : The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person base de données. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()instance. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person objet. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personisNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} section. This section of the UI gets a single person from the database and looks like this:
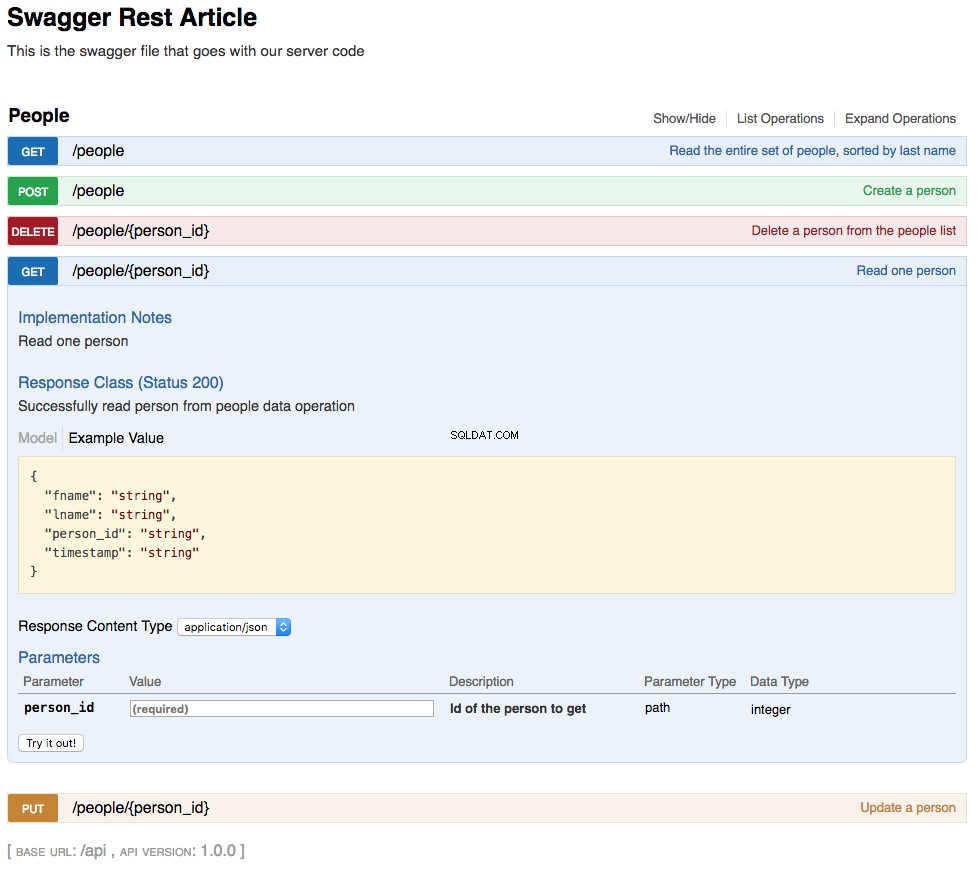
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Conclusion
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.



