Les groupes de disponibilité SQL Server 2012 AlwaysOn nécessitent un point de terminaison de mise en miroir de base de données pour chaque instance SQL Server qui hébergera un réplica de groupe de disponibilité et/ou une session de mise en miroir de base de données. Ce point de terminaison d'instance SQL Server est ensuite partagé par un ou plusieurs réplicas de groupe de disponibilité et/ou sessions de mise en miroir de bases de données et constitue le mécanisme de communication entre le réplica principal et les réplicas secondaires associés.
En fonction des charges de travail de modification des données sur le réplica principal, les exigences de débit de messagerie du groupe de disponibilité peuvent être non triviales. Cette activité est également sensible au trafic provenant d'une activité de groupe de non-disponibilité simultanée. Si le débit souffre en raison d'une bande passante dégradée et d'un trafic simultané, vous pouvez envisager d'isoler le trafic du groupe de disponibilité sur sa propre carte réseau dédiée pour chaque instance SQL Server hébergeant un réplica de disponibilité. Cet article décrira ce processus et décrira également brièvement ce que vous pourriez vous attendre à voir dans un scénario de débit dégradé.
Pour cet article, j'utilise un cluster de basculement Windows Server invité virtuel à cinq nœuds (WSFC). Chaque nœud du WSFC possède sa propre instance SQL Server autonome utilisant un stockage local non partagé. Chaque nœud dispose également d'une carte réseau virtuelle distincte pour la communication publique, d'une carte réseau virtuelle pour la communication WSFC et d'une carte réseau virtuelle que nous dédions à la communication du groupe de disponibilité. Pour les besoins de cet article, nous nous concentrerons sur les informations nécessaires pour les adaptateurs réseau dédiés du groupe de disponibilité sur chaque nœud :
| Nom du nœud WSFC | Adresses TCP/IPv4 de la carte réseau du groupe de disponibilité |
|---|---|
| SQL2K12-SVR1 | 192.168.20.31 |
| SQL2K12-SVR2 | 192.168.20.32 |
| SQL2K12-SVR3 | 192.168.20.33 |
| SQL2K12-SVR4 | 192.168.20.34 |
| SQL2K12-SVR5 | 192.168.20.35 |
La configuration d'un groupe de disponibilité à l'aide d'une carte réseau dédiée est presque identique à un processus de carte réseau partagée, uniquement pour "lier" le groupe de disponibilité à une carte réseau spécifique, je dois d'abord désigner le LISTENER_IP argument dans CREATE ENDPOINT commande, en utilisant les adresses IP susmentionnées pour mes cartes réseau dédiées. Vous trouverez ci-dessous la création de chaque point de terminaison sur les cinq nœuds WSFC :
:CONNECT SQL2K12-SVR1
USE [master];
GO
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022, LISTENER_IP = (192.168.20.31))
FOR DATA_MIRRORING (ROLE = ALL, ENCRYPTION = REQUIRED ALGORITHM AES);
GO
IF (SELECT state FROM sys.endpoints WHERE name = N'Hadr_endpoint') <> 0
BEGIN
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
END
GO
USE [master];
GO
GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [SQLSKILLSDEMOS\SQLServiceAcct];
GO
:CONNECT SQL2K12-SVR2
-- ...repeat for other 4 nodes... Après avoir créé ces points de terminaison associés à la carte réseau dédiée, le reste de mes étapes de configuration de la topologie du groupe de disponibilité n'est pas différent de celui d'un scénario de carte réseau partagée.
Après avoir créé mon groupe de disponibilité, si je commence à piloter la charge de modification des données sur les bases de données de disponibilité du réplica principal, je peux rapidement voir que le trafic de communication du groupe de disponibilité circule sur la carte réseau dédiée à l'aide du Gestionnaire des tâches dans l'onglet réseau (la première section est le débit pour la carte réseau du groupe de disponibilité dédié) :
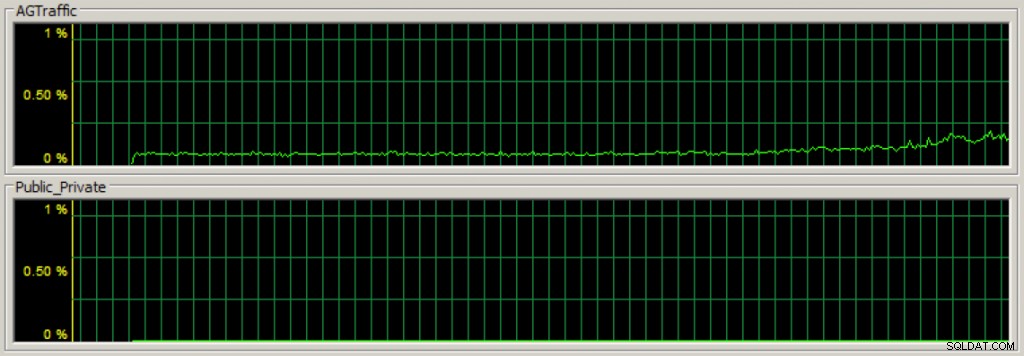
Et je peux également suivre les statistiques à l'aide de divers compteurs de performances. Dans l'image ci-dessous, la connexion réseau Inetl[R] PRO_1000 MT _2 est mon groupe de disponibilité dédié NIC et a la majorité du trafic NIC par rapport aux deux autres NIC :

Maintenant, avoir une carte réseau dédiée pour le trafic du groupe de disponibilité peut être un moyen d'isoler l'activité et d'améliorer théoriquement les performances, mais si votre carte réseau dédiée a une bande passante insuffisante, comme vous pouvez vous attendre à ce que les performances en souffrent et que la santé de la topologie du groupe de disponibilité se dégrade.
Par exemple, j'ai changé la carte réseau du groupe de disponibilité dédié sur le réplica principal en une bande passante de transfert sortante de 28,8 Kbps pour voir ce qui se passerait. Inutile de dire que ce n'était pas bon. Le débit de la carte réseau du groupe de disponibilité a chuté de manière significative :

En quelques secondes, l'état des différentes répliques s'est dégradé, quelques répliques passant à l'état "non synchronisé" :
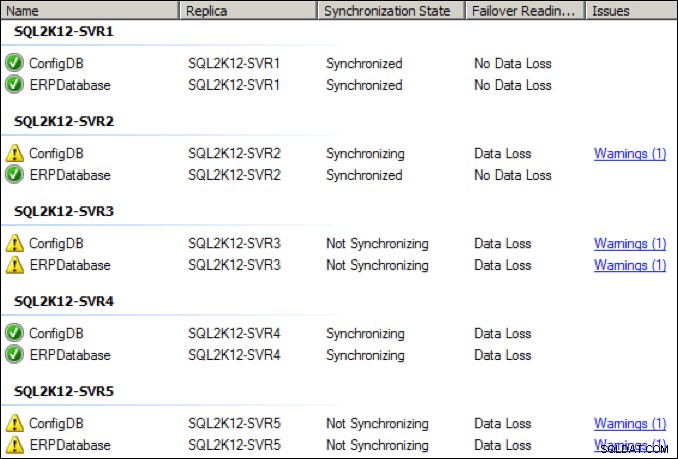
J'ai augmenté la carte réseau dédiée sur le réplica principal à 64 Kbit/s et après quelques secondes, il y a également eu un pic de rattrapage initial :

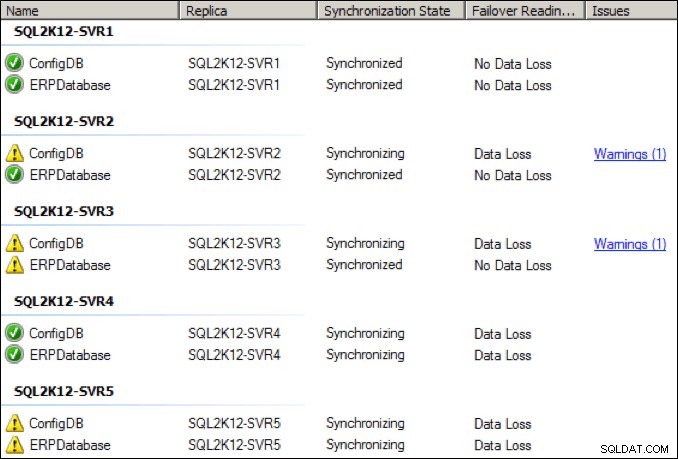
Bien que les choses se soient améliorées, j'ai été témoin de déconnexions périodiques et d'avertissements de santé à ce paramètre de débit NIC inférieur :
Qu'en est-il des statistiques d'attente associées sur le réplica principal ?
Lorsqu'il y avait beaucoup de bande passante sur la carte réseau dédiée et que toutes les répliques de disponibilité étaient dans un état sain, j'ai vu la distribution suivante pendant mes chargements de données sur une période de 2 minutes :
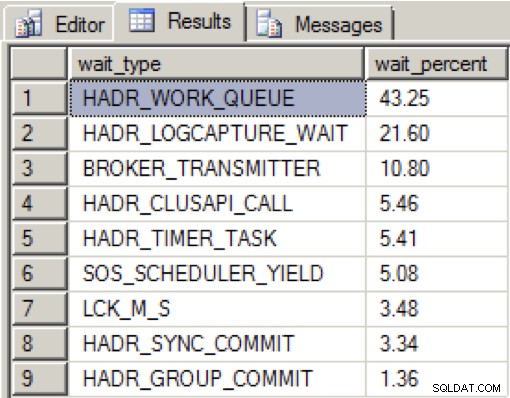
HADR_WORK_QUEUE représente un thread de travail d'arrière-plan attendu en attente d'un nouveau travail. HADR_LOGCAPTURE_WAIT représente une autre attente attendue pour que de nouveaux enregistrements de journal soient disponibles et, selon la documentation en ligne, est attendue si l'analyse du journal est rattrapée ou lit à partir du disque.
Lorsque j'ai suffisamment réduit le débit de la carte réseau pour amener le groupe de disponibilité dans un état non sain, la distribution du type d'attente était la suivante :
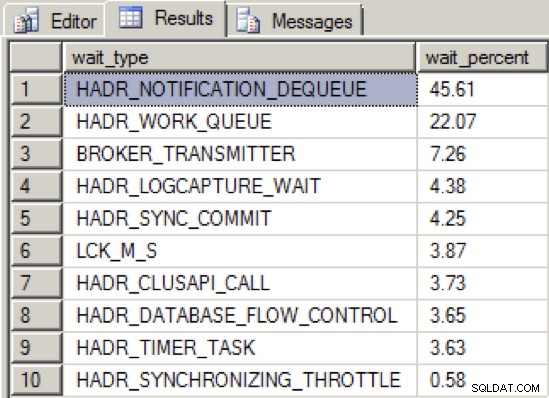
Nous voyons maintenant un nouveau type d'attente supérieur, HADR_NOTIFICATION_DEQUEUE . Il s'agit de l'un de ces types d'attente « à usage interne uniquement » tels que définis par la documentation en ligne, représentant une tâche en arrière-plan qui traite les notifications WSFC. Ce qui est intéressant, c'est que ce type d'attente n'indique pas directement un problème, et pourtant les tests montrent que ce type d'attente atteint le sommet en association avec un débit de messagerie de groupe de disponibilité dégradé.
Ainsi, l'essentiel est d'isoler l'activité de votre groupe de disponibilité sur une carte réseau dédiée peut être bénéfique si vous fournissez un débit réseau avec une bande passante suffisante. Cependant, si vous ne pouvez pas garantir une bonne bande passante même en utilisant un réseau dédié, la santé de la topologie de votre groupe de disponibilité en souffrira.