Les clés primaires et étrangères sont des caractéristiques fondamentales des bases de données relationnelles, comme indiqué à l'origine dans l'article d'E.F. Codd, « A Relational Model of Data for Large Shared Data Banks », publié en 1970. La citation souvent répétée est :« La clé, toute la clé, et rien que la clé, alors aide-moi Codd."
Contexte :clés primaires
Une clé primaire est une contrainte dans SQL Server, qui agit pour identifier de manière unique chaque ligne d'une table. La clé peut être définie comme une seule colonne non NULL ou une combinaison de colonnes non NULL qui génère une valeur unique et est utilisée pour appliquer l'intégrité de l'entité pour une table. Une table ne peut avoir qu'une seule clé primaire, et lorsqu'une contrainte de clé primaire est définie pour une table, un index unique est créé. Cet index sera un index clusterisé par défaut, sauf s'il est spécifié comme index non clusterisé lorsque la contrainte de clé primaire est définie.
Considérez le Sales.SalesOrderHeader tableau dans AdventureWorks2012 base de données. Cette table contient des informations de base sur une commande client, y compris la date de la commande et l'ID client, et chaque vente est identifiée de manière unique par un SalesOrderID , qui est la clé primaire de la table. Chaque fois qu'une nouvelle ligne est ajoutée à la table, la contrainte de clé primaire (nommée PK_SalesOrderHeader_SalesOrderID ) est vérifié pour s'assurer qu'aucune ligne n'existe déjà avec la même valeur pour SalesOrderID .
Clés étrangères
Séparées des clés primaires, mais très liées, se trouvent les clés étrangères. Une clé étrangère est une colonne ou une combinaison de colonnes identique à la clé primaire, mais dans une table différente. Les clés étrangères sont utilisées pour définir une relation et renforcer l'intégrité entre deux tables.
Pour continuer à utiliser l'exemple ci-dessus, le SalesOrderID existe en tant que clé étrangère dans Sales.SalesOrderDetail table, où des informations supplémentaires sur la vente sont stockées, telles que l'ID et le prix du produit. Lorsqu'une nouvelle vente est ajoutée au SalesOrderHeader table, il n'est pas nécessaire d'ajouter une ligne pour cette vente au SalesOrderDetail table Toutefois, lors de l'ajout d'une ligne au SalesOrderDetail table, une ligne correspondante pour le SalesOrderID doit existent dans le SalesOrderHeader tableau.
Inversement, lors de la suppression de données, une ligne pour un SalesOrderID spécifique peut être supprimé à tout moment du SalesOrderDetail table, mais pour qu'une ligne soit supprimée du SalesOrderHeader table, lignes associées de SalesOrderDetail devra d'abord être supprimé.
Contrairement aux contraintes de clé primaire, lorsqu'une contrainte de clé étrangère est définie pour une table, un index n'est pas créé par défaut par SQL Server. Cependant, il n'est pas rare que les développeurs et les administrateurs de bases de données les ajoutent manuellement. La clé étrangère peut faire partie d'une clé primaire composite pour la table, auquel cas un index clusterisé existerait avec la clé étrangère dans le cadre de la clé de clustering. Alternativement, les requêtes peuvent nécessiter un index qui inclut la clé étrangère et une ou plusieurs colonnes supplémentaires dans la table, de sorte qu'un index non clusterisé serait créé pour prendre en charge ces requêtes. De plus, les index sur les clés étrangères peuvent améliorer les performances des jointures de table impliquant la clé primaire et la clé étrangère, et ils peuvent avoir un impact sur les performances lorsque la valeur de la clé primaire est mise à jour ou si la ligne est supprimée.
Dans AdventureWorks2012 base de données, il y a une table, SalesOrderDetail , avec SalesOrderID comme clé étrangère. Pour le SalesOrderDetail table, SalesOrderID et SalesOrderDetailID se combinent pour former la clé primaire, prise en charge par un index clusterisé. Si le SalesOrderDetail la table n'avait pas d'index sur le SalesOrderID colonne, puis lorsqu'une ligne est supprimée de SalesOrderHeader , SQL Server devra vérifier qu'aucune ligne pour le même SalesOrderID valeur existe. Sans aucun index contenant le SalesOrderID colonne, SQL Server devrait effectuer une analyse complète de la table de SalesOrderDetail . Comme vous pouvez l'imaginer, plus la table référencée est grande, plus la suppression prendra de temps.
Un exemple
Nous pouvons le voir dans l'exemple suivant, qui utilise des copies des tables susmentionnées de AdventureWorks2012 base de données qui ont été étendues à l'aide d'un script qui peut être trouvé ici. Le script a été développé par Jonathan Kehayias (blog | @SQLPoolBoy) et crée un SalesOrderHeaderEnlarged table avec 1 258 600 lignes et un SalesOrderDetailEnlarged table avec 4 852 680 lignes. Une fois le script exécuté, la contrainte de clé étrangère a été ajoutée à l'aide des instructions ci-dessous. Notez que la contrainte est créée avec le ON DELETE CASCADE option. Avec cette option, lorsqu'une mise à jour ou une suppression est émise sur le SalesOrderHeaderEnlarged table, lignes dans la ou les tables correspondantes - dans ce cas, juste SalesOrderDetailEnlarged – sont mis à jour ou supprimés.
De plus, l'index clusterisé par défaut pour SalesOrderDetailEnglarged a été supprimé et recréé pour n'avoir que SalesOrderDetailID comme clé primaire, car elle représente une conception typique.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
Avec la contrainte de clé étrangère et aucun index de prise en charge, une seule suppression a été émise contre le SalesOrderHeaderEnlarged table, ce qui a entraîné la suppression d'une ligne de SalesOrderHeaderEnlarged et 72 lignes de SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
Les statistiques d'E/S et les informations de synchronisation ont montré ce qui suit :
Temps d'analyse et de compilation de SQL Server :Temps CPU =8 ms, temps écoulé =8 ms.
Table 'SalesOrderDetailEnlarged'. Nombre de balayages 1, lectures logiques 50647, lectures physiques 8, lectures anticipées 50667, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Tableau 'Table de travail'. Nombre de balayages 2, lectures logiques 7, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Table 'SalesOrderHeaderEnlarged'. Nombre de balayages 0, lectures logiques 15, lectures physiques 14, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Temps d'exécution SQL Server :
Temps CPU =1 045 ms, temps écoulé =1 898 ms.
À l'aide de SQL Sentry Plan Explorer, le plan d'exécution affiche une analyse d'index clusterisée par rapport à SalesOrderDetailEnlarged car il n'y a pas d'index sur SalesOrderID :
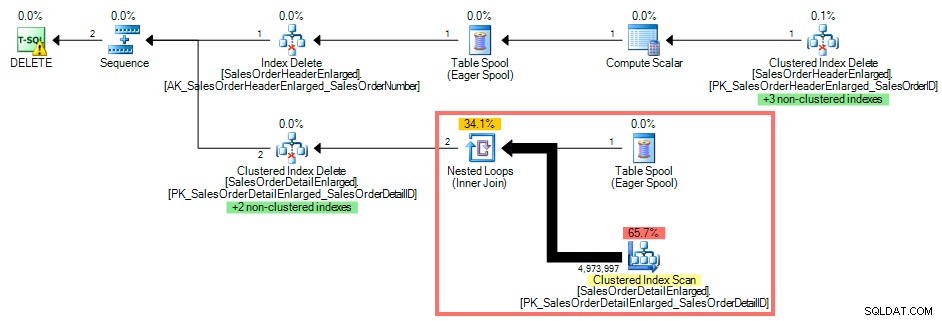
Plan de requête sans index sur la clé étrangère
L'index non clusterisé pour prendre en charge SalesOrderDetailEnlarged a ensuite été créé à l'aide de l'instruction suivante :
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Une autre suppression a été exécutée pour un SalesOrderID affectant une ligne dans SalesOrderHeaderEnlarged et 72 lignes dans SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
Les statistiques d'E/S et les informations de synchronisation ont montré une amélioration spectaculaire :
Temps d'analyse et de compilation de SQL Server :Temps CPU =0 ms, temps écoulé =7 ms.
Table 'SalesOrderDetailEnlarged'. Nombre de balayages 1, lectures logiques 48, lectures physiques 13, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Tableau 'Table de travail'. Nombre de balayages 2, lectures logiques 7, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Table 'SalesOrderHeaderEnlarged'. Nombre de balayages 0, lectures logiques 15, lectures physiques 15, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Temps d'exécution SQL Server :
Temps CPU =0 ms, temps écoulé =27 ms.
Et le plan de requête a montré une recherche d'index de l'index non clusterisé sur SalesOrderID , comme prévu :
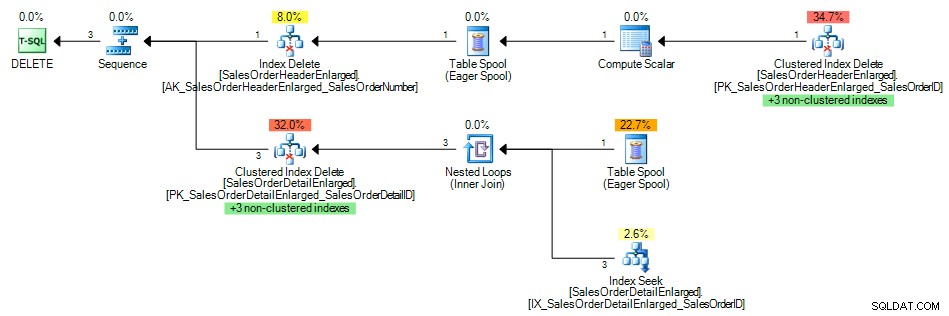
Plan de requête avec index sur la clé étrangère
Le temps d'exécution de la requête est passé de 1898 ms à 27 ms, soit une réduction de 98,58 %, et lit pour le SalesOrderDetailEnlarged le tableau est passé de 50647 à 48 – une amélioration de 99,9 %. Mis à part les pourcentages, considérez uniquement les E/S générées par la suppression. Le SalesOrderDetailEnlarged table n'est que de 500 Mo dans cet exemple, et pour un système avec 256 Go de mémoire disponible, une table prenant 500 Mo dans le cache tampon ne semble pas être une situation terrible. Mais une table de 5 millions de lignes est relativement petite; la plupart des grands systèmes OLTP ont des tables avec des centaines de millions de lignes. De plus, il n'est pas rare que plusieurs références de clé étrangère existent pour une clé primaire, où une suppression de la clé primaire nécessite des suppressions de plusieurs tables liées. Dans ce cas, il est possible de voir des durées prolongées pour les suppressions, ce qui n'est pas seulement un problème de performances, mais également un problème de blocage, en fonction du niveau d'isolement.
Conclusion
Il est généralement recommandé de créer un index qui mène sur la ou les colonnes de clé étrangère, pour prendre en charge non seulement les jointures entre les clés primaires et étrangères, mais également les mises à jour et les suppressions. Notez qu'il s'agit d'une recommandation générale, car il existe des scénarios extrêmes où l'index supplémentaire sur la clé étrangère n'a pas été utilisé en raison d'une taille de table extrêmement petite, et les mises à jour d'index supplémentaires ont en fait eu un impact négatif sur les performances. Comme pour toute modification de schéma, les ajouts d'index doivent être testés et surveillés après la mise en œuvre. Il est important de s'assurer que les index supplémentaires produisent les effets souhaités et n'ont pas d'impact négatif sur les performances de la solution. Il convient également de noter l'espace supplémentaire requis par les index pour les clés étrangères. Il est essentiel d'en tenir compte avant de créer les index, et s'ils offrent un avantage, ils doivent être pris en compte pour la planification des capacités à l'avenir.