Vos responsabilités en tant que DBA (ou DBCC CHECKDB . Vous pouvez y arriver en créant un plan de maintenance simple avec une "tâche de vérification de l'intégrité de la base de données" - cependant, dans mon esprit, il s'agit simplement de cocher une case.
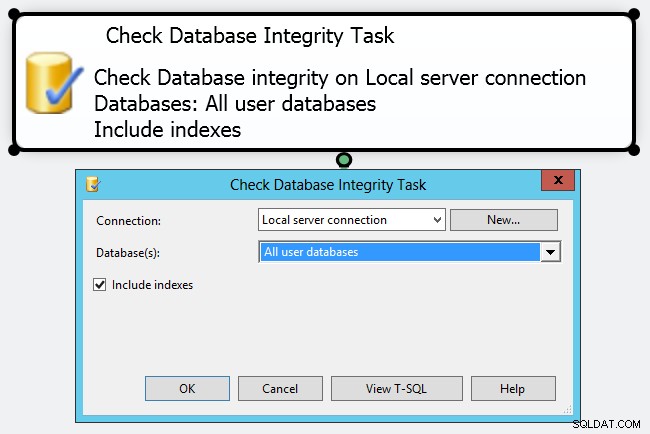
Si vous regardez de plus près, vous ne pouvez pas faire grand-chose pour contrôler le fonctionnement de la tâche. Même le panneau Propriétés assez étendu expose de nombreux paramètres pour le sous-plan de maintenance, mais pratiquement rien sur le DBCC commandes qu'il exécutera. Personnellement, je pense que vous devriez adopter une approche beaucoup plus proactive et contrôlée dans la façon dont vous effectuez votre CHECKDB opérations dans des environnements de production, en créant vos propres travaux et en fabriquant manuellement votre DBCC commandes. Vous pouvez adapter votre calendrier ou les commandes elles-mêmes à différentes bases de données. Par exemple, la base de données des membres ASP.NET n'est probablement pas aussi cruciale que votre base de données de ventes et pourrait tolérer des vérifications moins fréquentes et/ou moins approfondies.
Mais pour vos bases de données cruciales, j'ai pensé créer un article pour détailler certaines des choses que j'étudierais afin de minimiser les perturbations DBCC les commandes peuvent causer - et les mythes et le battage marketing dont vous devez vous méfier. Et je tiens à remercier Paul "Mr. DBCC" Randal (@PaulRandal) pour sa contribution précieuse - non seulement à ce message spécifique, mais également aux conseils sans fin qu'il fournit sur son blog, #sqlhelp et dans la formation SQLskills Immersion.
Veuillez prendre toutes ces idées avec un grain de sel et faites de votre mieux pour effectuer des tests adéquats dans votre environnement - toutes ces suggestions ne produiront pas de meilleures performances dans tous les environnements. Mais vous vous devez, à vous-même, à vos utilisateurs et à vos parties prenantes, d'au moins tenir compte de l'impact que votre CHECKDB opérations pourraient avoir, et prendre des mesures pour atténuer ces effets dans la mesure du possible - sans introduire de risques inutiles en ne vérifiant pas les bonnes choses.
Réduire le bruit et consommer toutes les erreurs
Peu importe où vous exécutez CHECKDB , utilisez toujours le WITH NO_INFOMSGS option. Cela supprime simplement toute la sortie non pertinente qui vous indique simplement le nombre de lignes dans chaque table ; si vous êtes intéressé par ces informations, vous pouvez les obtenir à partir de simples requêtes sur les DMV et non sur DBCC est en cours d'exécution. La suppression de la sortie rend beaucoup moins probable que vous manquiez un message critique enfoui dans toute cette sortie heureuse.
De même, vous devez toujours utiliser le WITH ALL_ERRORMSGS option, mais surtout si vous exécutez SQL Server 2008 RTM ou SQL Server 2005 (dans ces cas, vous pouvez voir la liste des erreurs par objet tronquée à 200). Pour tout CHECKDB opérations autres que des vérifications ad hoc rapides, vous devriez envisager de diriger la sortie vers un fichier. Management Studio est limité à 1000 lignes de sortie de DBCC CHECKDB , vous risquez donc de manquer certaines erreurs si vous dépassez ce chiffre.
Bien qu'il ne s'agisse pas strictement d'un problème de performances, l'utilisation de ces options vous évitera d'avoir à exécuter à nouveau le processus. Ceci est particulièrement important si vous êtes au milieu d'une reprise après sinistre.
Déchargez les vérifications logiques si possible
Dans la plupart des cas, CHECKDB passe la majorité de son temps à effectuer des vérifications logiques des données. Si vous avez la possibilité d'effectuer ces vérifications sur une copie conforme des données, vous pouvez concentrer vos efforts sur la structure physique de vos systèmes de production et utiliser le serveur secondaire pour gérer toutes les vérifications logiques et alléger la charge du serveur principal. Par serveur secondaire , je veux dire seulement ce qui suit :
- L'endroit où vous testez vos restaurations complètes – parce que vous testez vos restaurations, n'est-ce pas ?
D'autres personnes (notamment la force marketing géante qu'est Microsoft) pourraient vous avoir convaincu que d'autres formes de serveurs secondaires conviennent à DBCC chèques. Par exemple :
- un secondaire lisible par groupe de disponibilité AlwaysOn ;
- un instantané d'une base de données en miroir ;
- un journal livré secondaire ;
- Mise en miroir SAN ;
- ou d'autres variantes…
Malheureusement, ce n'est pas le cas, et aucun de ces secondaires n'est un endroit valide et fiable pour effectuer vos vérifications comme alternative au primaire. Seule une sauvegarde un pour un peut servir de copie conforme; tout ce qui repose sur des éléments tels que l'application de sauvegardes de journaux pour atteindre un état cohérent ne reflétera pas de manière fiable les problèmes d'intégrité sur le serveur principal.
Donc, plutôt que d'essayer de décharger vos vérifications logiques sur un secondaire et de ne jamais les effectuer sur le principal, voici ce que je suggère :
- Assurez-vous de tester fréquemment les restaurations de vos sauvegardes complètes. Et non, cela n'inclut pas
COPY_ONLYsauvegardes à partir d'un secondaire AG, pour les mêmes raisons que ci-dessus - cela ne serait valable que dans le cas où vous venez de lancer le secondaire avec une restauration complète. - Exécuter
DBCC CHECKDBsouvent contre le plein restaurer, avant de faire quoi que ce soit d'autre. Encore une fois, la relecture des enregistrements de journal à ce stade invalidera cette base de données en tant que copie fidèle de la source. - Exécuter
DBCC CHECKDBpar rapport à votre primaire, peut-être divisé d'une manière suggérée par Paul Randal, et/ou selon un horaire moins fréquent, et/ou en utilisantPHYSICAL_ONLYplus souvent qu'autrement. Cela peut dépendre de la fréquence et de la fiabilité de vos performances (2). - Ne présumez jamais que les vérifications par rapport au secondaire sont suffisantes. Même avec une réplique exacte de votre base de données primaire, des problèmes physiques peuvent toujours survenir sur le sous-système d'E/S de votre primaire et ne se propageront jamais au secondaire.
- Toujours analyser
DBCCproduction. Le simple fait de l'exécuter et de l'ignorer, pour le cocher dans une liste, est aussi utile que d'exécuter des sauvegardes et de revendiquer le succès sans jamais tester que vous pouvez réellement restaurer cette sauvegarde en cas de besoin.
Expérimentez avec les indicateurs de trace 2549, 2562 et 2566
J'ai effectué des tests approfondis de deux indicateurs de trace (2549 et 2562) et j'ai constaté qu'ils peuvent apporter des améliorations substantielles des performances, mais Lonny signale qu'ils ne sont plus nécessaires ou utiles. Si vous utilisez la version 2016 ou une version plus récente, ignorez toute cette section . Si vous utilisez une version plus ancienne, ces deux indicateurs de trace sont décrits de manière beaucoup plus détaillée dans KB #2634571, mais en gros :
- Indicateur de suivi 2549
- Cela optimise le processus checkdb en traitant chaque fichier de base de données individuel comme résidant sur un disque sous-jacent unique. Vous pouvez l'utiliser si votre base de données contient un seul fichier de données ou si vous savez que chaque fichier de base de données se trouve, en fait, sur un lecteur distinct. Si votre base de données contient plusieurs fichiers et qu'ils partagent une seule broche directement attachée, vous devez vous méfier de cet indicateur de trace, car il peut faire plus de mal que de bien.
IMPORTANT :sql.sasquatch signale une régression dans le comportement de cet indicateur de trace dans SQL Server 2014.
- Cela optimise le processus checkdb en traitant chaque fichier de base de données individuel comme résidant sur un disque sous-jacent unique. Vous pouvez l'utiliser si votre base de données contient un seul fichier de données ou si vous savez que chaque fichier de base de données se trouve, en fait, sur un lecteur distinct. Si votre base de données contient plusieurs fichiers et qu'ils partagent une seule broche directement attachée, vous devez vous méfier de cet indicateur de trace, car il peut faire plus de mal que de bien.
- Indicateur de suivi 2562
- Cet indicateur traite l'intégralité du processus checkdb comme un seul lot, au prix d'une utilisation plus élevée de tempdb (jusqu'à 5 % de la taille de la base de données).
- Utilise un meilleur algorithme pour déterminer comment lire les pages de la base de données, réduisant ainsi les conflits de verrouillage (en particulier pour
DBCC_MULTIOBJECT_SCANNER). Notez que cette amélioration spécifique se trouve dans le chemin du code SQL Server 2012, vous en bénéficierez donc même sans l'indicateur de trace. Cela peut éviter des erreurs telles que :
Le délai d'attente s'est produit lors de l'attente du verrouillage :classe 'DBCC_MULTIOBJECT_SCANNER'.
- Les deux indicateurs de trace ci-dessus sont disponibles dans les versions suivantes :
- Mise à jour cumulative 9+ de SQL Server 2008 Service Pack 2
(10.00.4330 -> 10.00.5499)Mise à jour cumulative 4+ de SQL Server 2008 Service Pack 3
(10.00.5775+)Mise à jour cumulative de SQL Server 2008 R2 RTM 11+
(10.50.1809 -> 10.50.2424)Mise à jour cumulative 4+ de SQL Server 2008 R2 Service Pack 1
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Service Pack 2
(10.50.4000+)SQL Server 2012, toutes les versions
(11.00.2100+) - Indicateur de suivi 2566
- Si vous utilisez toujours SQL Server 2005, cet indicateur de trace, introduit dans 2005 SP2 CU#9 (9.00.3282) (bien que non documenté dans l'article de la base de connaissances de cette mise à jour cumulative, KB #953752), tente de corriger les mauvaises performances de
DATA_PURITYvérifications sur les systèmes basés sur x64. À un moment donné, vous pouviez voir plus de détails dans KB # 945770, mais il semble que cet article ait été effacé à la fois du site de support de Microsoft et de la machine WayBack. Cet indicateur de trace ne devrait pas être nécessaire dans les versions plus modernes de SQL Server, car le problème dans le processeur de requêtes a été corrigé.
- Si vous utilisez toujours SQL Server 2005, cet indicateur de trace, introduit dans 2005 SP2 CU#9 (9.00.3282) (bien que non documenté dans l'article de la base de connaissances de cette mise à jour cumulative, KB #953752), tente de corriger les mauvaises performances de
Si vous envisagez d'utiliser l'un de ces indicateurs de trace, je vous recommande vivement de les définir au niveau de la session à l'aide de DBCC TRACEON plutôt que comme un indicateur de trace de démarrage. Non seulement cela vous permet de les désactiver sans avoir à cycler SQL Server, mais cela vous permet également de les implémenter uniquement lors de l'exécution de certains CHECKDB commandes, par opposition aux opérations utilisant n'importe quel type de réparation.
Réduire l'impact des E/S :optimiser tempdb
DBCC CHECKDB peut faire un usage intensif de tempdb, alors assurez-vous d'y planifier l'utilisation des ressources. C'est généralement une bonne chose à faire dans tous les cas. Pour CHECKDB vous voudrez allouer correctement de l'espace à tempdb ; la dernière chose que vous voulez est pour CHECKDB progress (et toute autre opération simultanée) pour devoir attendre une croissance automatique. Vous pouvez vous faire une idée des besoins en utilisant WITH ESTIMATEONLY , comme Paul l'explique ici. Sachez simplement que l'estimation peut être assez faible en raison d'un bogue dans SQL Server 2008 R2. De plus, si vous utilisez l'indicateur de trace 2562, assurez-vous de tenir compte des exigences d'espace supplémentaires.
Et bien sûr, tous les conseils typiques pour optimiser tempdb sur à peu près n'importe quel système sont également appropriés ici :assurez-vous que tempdb est sur son propre ensemble de fast broches, assurez-vous qu'il est dimensionné pour s'adapter à toutes les autres activités simultanées sans avoir à grandir, assurez-vous que vous utilisez un nombre optimal de fichiers de données, etc. Quelques autres ressources que vous pourriez envisager :
- Optimisation des performances de tempdb (MSDN)
- Planification des capacités pour tempdb (MSDN)
- Un mythe quotidien pour l'administrateur de bases de données SQL Server :(12/30) tempdb devrait toujours avoir un fichier de données par cœur de processeur
Réduire l'impact des E/S :contrôler l'instantané
Pour exécuter CHECKDB , les versions modernes de SQL Server tenteront de créer un instantané masqué de votre base de données sur le même lecteur (ou sur tous les lecteurs si vos fichiers de données s'étendent sur plusieurs lecteurs). Vous ne pouvez pas contrôler ce mécanisme, mais si vous voulez contrôler où CHECKDB fonctionne, créez d'abord votre propre instantané (Enterprise Edition requis) sur le lecteur de votre choix et exécutez le DBCC commande par rapport à l'instantané. Dans les deux cas, vous souhaiterez exécuter cette opération pendant un temps d'arrêt relatif, afin de minimiser l'activité de copie sur écriture qui passera par l'instantané. Et vous ne voudrez pas que ce calendrier entre en conflit avec des opérations d'écriture lourdes, comme la maintenance d'index ou ETL.
Vous avez peut-être vu des suggestions pour forcer CHECKDB pour fonctionner en mode hors ligne en utilisant le WITH TABLOCK option. Je déconseille fortement cette approche. Si votre base de données est activement utilisée, le choix de cette option ne fera que frustrer les utilisateurs. Et si la base de données n'est pas activement utilisée, vous n'économisez pas d'espace disque en évitant un instantané, puisqu'il n'y aura aucune activité de copie sur écriture à stocker.
Réduire l'impact des E/S :éviter les erreurs 665/1450/1452
Dans certains cas, vous pouvez rencontrer l'une des erreurs suivantes :
Le système d'exploitation a renvoyé l'erreur 1450 (des ressources système insuffisantes existent pour terminer le service demandé.) à SQL Server lors d'une écriture à l'offset 0x[…] dans le fichier avec le handle 0x[…]. Il s'agit généralement d'une condition temporaire et SQL Server continue de réessayer l'opération. Si la condition persiste, des mesures immédiates doivent être prises pour la corriger.
Le système d'exploitation a renvoyé l'erreur 665 (l'opération demandée n'a pas pu être effectuée en raison d'une limitation du système de fichiers) à SQL Server lors d'une écriture à l'offset 0x[…] dans le fichier '[fichier]'
Il y a quelques conseils ici pour réduire le risque de ces erreurs lors de CHECKDB opérations, et en réduisant leur impact en général - avec plusieurs correctifs disponibles, en fonction de votre système d'exploitation et de la version de SQL Server :
- Erreurs de fichiers fragmentés :1 450 ou 665 en raison de la fragmentation des fichiers :correctifs et solutions de contournement
- SQL Server signale l'erreur de système d'exploitation 1450 ou 1452 ou 665 (tentatives)
Réduire l'impact sur le processeur
DBCC CHECKDB est multithread par défaut (mais uniquement dans Enterprise Edition). Si votre système est lié au processeur, ou si vous voulez simplement CHECKDB pour utiliser moins de processeur au prix d'une exécution plus longue, vous pouvez envisager de réduire le parallélisme de différentes manières :
- Utilisez Resource Governor sur 2008 et versions ultérieures, tant que vous exécutez Enterprise Edition. Pour cibler uniquement les commandes DBCC pour un pool de ressources ou un groupe de charge de travail particulier, vous devrez écrire une fonction de classificateur qui peut identifier les sessions qui effectueront ce travail (par exemple, une connexion spécifique ou un job_id).
- Utilisez l'indicateur de trace 2528 pour désactiver le parallélisme pour
DBCC CHECKDB(ainsi queCHECKFILEGROUPetCHECKTABLE). L'indicateur de trace 2528 est décrit ici. Bien sûr, cela n'est valable que dans Enterprise Edition, car malgré ce que dit actuellement Books Online, la vérité est queCHECKDBne va pas en parallèle dans l'édition standard. - Alors que le
DBCCla commande elle-même ne prend pas en chargeMAXDOP(au moins avant SQL Server 2014 SP2), il respecte le paramètre globalmax degree of parallelism. Ce n'est probablement pas quelque chose que je ferais en production à moins que je n'aie pas d'autres options, mais c'est un moyen global de contrôler certainsDBCCcommandes si vous ne pouvez pas les cibler plus explicitement.
Nous avions demandé un meilleur contrôle du nombre de processeurs que DBCC CHECKDB utilise, mais ils ont été refusés à plusieurs reprises jusqu'à SQL Server 2014 SP2. Vous pouvez donc maintenant ajouter WITH MAXDOP = n à la commande.
Mes découvertes
Je voulais démontrer quelques-unes de ces techniques dans un environnement que je pouvais contrôler. J'ai installé AdventureWorks2012, puis je l'ai étendu à l'aide du script d'agrandissement AW écrit par Jonathan Kehayias (blog | @SQLPoolBoy), qui a augmenté la base de données à environ 7 Go. Ensuite, j'ai exécuté une série de CHECKDB commandes contre elle, et les a chronométrés. J'ai utilisé un simple DBCC CHECKDB à la vanille seul, puis toutes les autres commandes utilisées WITH NO_INFOMSGS, ALL_ERRORMSGS . Puis quatre tests avec (a) aucun indicateur de trace, (b) 2549, (c) 2562 et (d) à la fois 2549 et 2562. Ensuite, j'ai répété ces quatre tests, mais j'ai ajouté le PHYSICAL_ONLY option, qui contourne toutes les vérifications logiques. Les résultats (moyennés sur 10 tests) sont révélateurs :
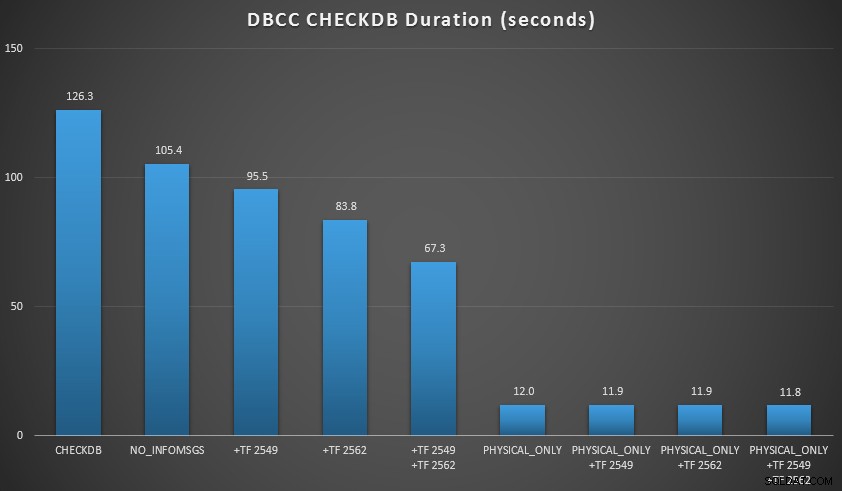
Résultats de CHECKDB par rapport à une base de données de 7 Go
Ensuite, j'ai étendu la base de données un peu plus, en faisant de nombreuses copies des deux tables agrandies, ce qui a conduit à une taille de base de données juste au nord de 70 Go, et j'ai refait les tests. Les résultats, à nouveau moyennés sur 10 tests :
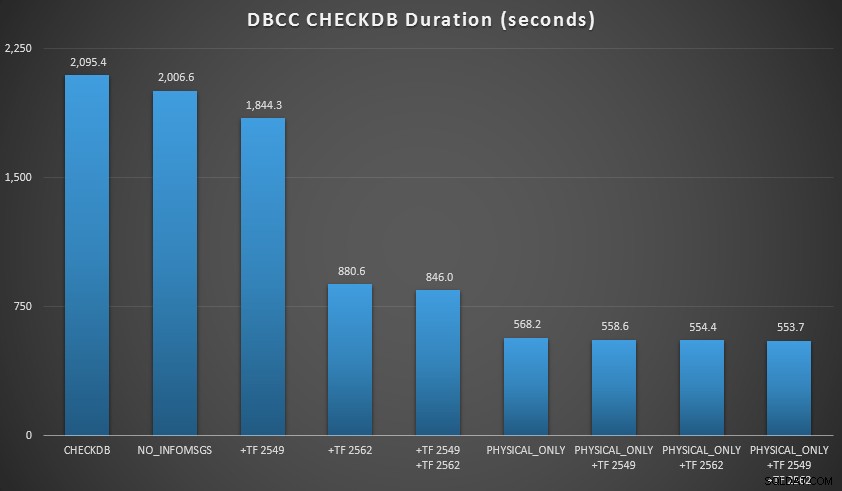
Résultats de CHECKDB par rapport à une base de données de 70 Go
Dans ces deux scénarios, j'ai appris ce qui suit (encore une fois, en gardant à l'esprit que votre kilométrage peut varier et que vous devrez effectuer vos propres tests pour tirer des conclusions significatives) :
- Lorsque je dois effectuer des vérifications logiques :
- Pour les bases de données de petite taille, le
NO_INFOMSGSL'option peut réduire considérablement le temps de traitement lorsque les contrôles sont exécutés dans SSMS. Sur les bases de données plus volumineuses, cependant, cet avantage diminue, car le temps et le travail consacrés à relayer les informations deviennent une partie insignifiante de la durée globale. 21 secondes sur 2 minutes est considérable; 88 secondes sur 35 minutes, pas tellement. - Les deux indicateurs de trace que j'ai testés ont eu un impact significatif sur les performances, ce qui représente une réduction du temps d'exécution de 40 à 60 % lorsque les deux étaient utilisés ensemble.
- Pour les bases de données de petite taille, le
- Quand je peux pousser les vérifications logiques vers un serveur secondaire (encore une fois, en supposant que j'effectue des vérifications logiques ailleurs par rapport à une copie conforme ):
- Je peux réduire le temps de traitement sur mon instance principale de 70 à 90 % par rapport à un
CHECKDBstandard appeler sans options. - Dans mon scénario, les indicateurs de trace avaient très peu d'impact sur la durée lors de l'exécution de
PHYSICAL_ONLYchèques.
- Je peux réduire le temps de traitement sur mon instance principale de 70 à 90 % par rapport à un
Bien sûr, et je ne saurais trop insister là-dessus, ce sont des bases de données relativement petites et utilisées uniquement pour que je puisse effectuer des tests répétés et mesurés dans un délai raisonnable. Ce serveur avait 80 processeurs logiques et 128 Go de RAM, et j'étais le seul utilisateur. La durée et l'interaction avec d'autres charges de travail sur le système peuvent fausser considérablement ces résultats. Voici un aperçu rapide de l'utilisation typique du CPU, en utilisant SQL Sentry, pendant l'un des CHECKDB opérations (et aucune des options n'a vraiment changé l'impact global sur le CPU, juste la durée) :
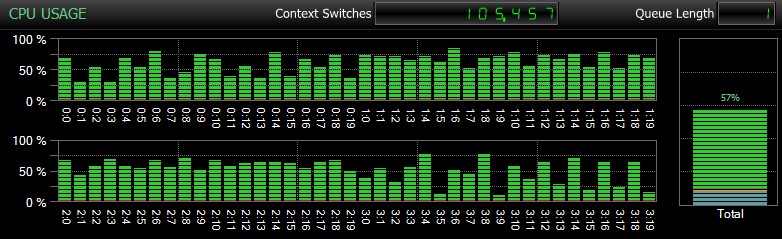
Impact CPU pendant CHECKDB – mode échantillon
Et voici une autre vue, montrant des profils CPU similaires pour trois exemples différents de CHECKDB opérations en mode historique (j'ai superposé une description des trois tests échantillonnés dans cette gamme):
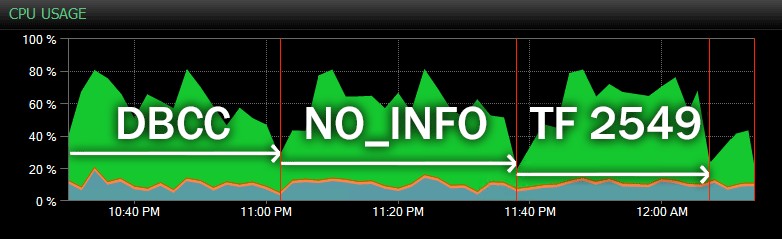
Impact CPU pendant CHECKDB – mode historique
Sur des bases de données encore plus grandes, hébergées sur des serveurs plus occupés, vous pouvez voir des effets différents, et votre kilométrage est très susceptible de varier. Veuillez donc faire preuve de diligence raisonnable et tester ces options et suivre les indicateurs lors d'une charge de travail simultanée typique avant de décider comment vous souhaitez aborder CHECKDB .
Conclusion
DBCC CHECKDB est une partie très importante mais souvent sous-évaluée de votre responsabilité en tant que DBA ou architecte, et cruciale pour la protection des données de votre entreprise. Ne prenez pas cette responsabilité à la légère et faites de votre mieux pour vous assurer de ne rien sacrifier dans le but de réduire l'impact sur vos instances de production. Plus important encore :regardez au-delà des fiches techniques marketing pour vous assurer que vous comprenez parfaitement la validité de ces promesses et si vous êtes prêt à parier les données de votre entreprise sur celles-ci. Lésiner sur certains chèques ou les décharger dans des emplacements secondaires non valides pourrait être un désastre imminent.
Vous devriez également envisager de lire ces articles PSS :
- Un CHECKDB plus rapide – Partie I
- Un CHECKDB plus rapide – Partie II
- Un CHECKDB plus rapide – Partie III
- Un CHECKDB plus rapide – Partie IV (UDT SQL CLR)
Et ce post de Brent Ozar :
- 3 façons d'exécuter DBCC CHECKDB plus rapidement
Enfin, si vous avez une question non résolue sur DBCC CHECKDB , publiez-le sur le hashtag #sqlhelp sur Twitter. Paul vérifie souvent cette balise et, puisque sa photo devrait apparaître dans l'article principal de Books Online, il est probable que si quelqu'un peut y répondre, il le peut. Si c'est trop complexe pour 140 caractères, vous pouvez demander ici (et je m'assurerai que Paul le voit à un moment donné), ou poster sur un site de forum tel que Database Administrators Stack Exchange.