L'ajout d'un index filtré peut avoir des effets secondaires surprenants sur les requêtes existantes, même lorsqu'il semble que le nouvel index filtré n'a aucun rapport. Cet article examine un exemple affectant les instructions DELETE qui entraînent de mauvaises performances et un risque accru de blocage.
Environnement de test
Le tableau suivant sera utilisé tout au long de cet article :
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); L'instruction suivante crée 499 999 lignes d'exemples de données :
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; Cela utilise une table de nombres comme source d'entiers consécutifs de 1 à 499 999. Si vous n'en avez pas dans votre environnement de test, le code suivant peut être utilisé pour en créer efficacement un contenant des entiers de 1 à 1 000 000 :
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); La base des tests ultérieurs consistera à supprimer des lignes de la table de test pour une StartDate particulière. Pour rendre le processus d'identification des lignes à supprimer plus efficace, ajoutez cet index non cluster :
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); Les exemples de données
Une fois ces étapes terminées, l'exemple ressemblera à ceci :
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
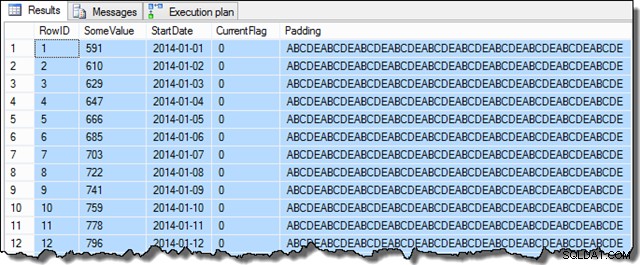
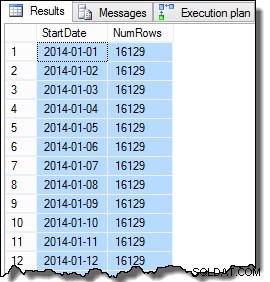
Les données de la colonne SomeValue peuvent être légèrement différentes en raison de la génération pseudo-aléatoire, mais cette différence n'est pas importante. Dans l'ensemble, les exemples de données contiennent 16 129 lignes pour chacune des 31 dates StartDate en janvier 2014 :
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
La dernière étape que nous devons effectuer pour rendre les données quelque peu réalistes consiste à définir la colonne CurrentFlag sur true pour le RowID le plus élevé pour chaque StartDate. Le script suivant accomplit cette tâche :
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; Le plan d'exécution de cette mise à jour comprend une combinaison Segment-Top pour localiser efficacement le RowID le plus élevé par jour :

Remarquez que le plan d'exécution ressemble peu à la forme écrite de la requête. Il s'agit d'un excellent exemple de la façon dont l'optimiseur fonctionne à partir de la spécification SQL logique, plutôt que d'implémenter le SQL directement. Au cas où vous vous poseriez la question, la bobine de table Eager de ce plan est requise pour la protection d'Halloween.
Supprimer une journée de données
Ok, donc une fois les préliminaires terminés, la tâche à accomplir consiste à supprimer des lignes pour une StartDate particulière. Il s'agit du type de requête que vous pouvez exécuter régulièrement à la première date d'une table, lorsque les données ont atteint la fin de leur durée de vie utile.
En prenant le 1er janvier 2014 comme exemple, la requête test de suppression est simple :
DELETE dbo.Data WHERE StartDate = '20140101';
Le plan d'exécution est également assez simple, mais mérite d'être examiné un peu en détail :

Analyse du plan
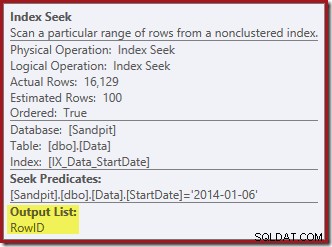
La recherche d'index à l'extrême droite utilise l'index non clusterisé pour rechercher des lignes pour la valeur StartDate spécifiée. Il renvoie uniquement les valeurs RowID qu'il trouve, comme le confirme l'info-bulle de l'opérateur :
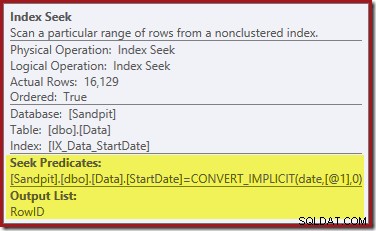
Si vous vous demandez comment l'index StartDate parvient à renvoyer le RowID, rappelez-vous que RowID est l'index cluster unique pour la table, il est donc automatiquement inclus dans l'index non cluster StartDate.
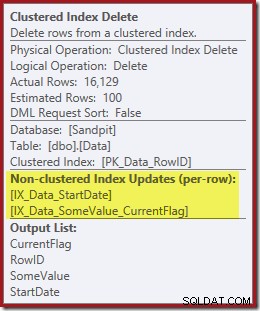
L'opérateur suivant dans le plan est la suppression de l'index clusterisé. Cela utilise la valeur RowID trouvée par Index Seek pour localiser les lignes à supprimer.
Le dernier opérateur du plan est une suppression d'index. Cela supprime les lignes de l'index non clusterisé IX_Data_StartDate qui sont liés au RowID supprimé par la suppression de l'index clusterisé. Pour localiser ces lignes dans l'index non clusterisé, le processeur de requêtes a besoin de StartDate (la clé de l'index non clusterisé).
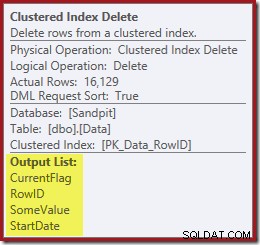
N'oubliez pas que l'Index Seek d'origine n'a pas renvoyé la date de début, uniquement le RowID. Alors, comment le processeur de requêtes obtient-il la StartDate pour la suppression de l'index ? Dans ce cas particulier, l'optimiseur a peut-être remarqué que la valeur StartDate est une constante et l'a optimisée, mais ce n'est pas ce qui s'est passé. La réponse est que l'opérateur Clustered Index Delete lit la valeur StartDate pour la ligne actuelle et l'ajoute au flux. Comparez la liste de sortie de la suppression d'index clusterisée ci-dessous, avec celle de la recherche d'index juste au-dessus :
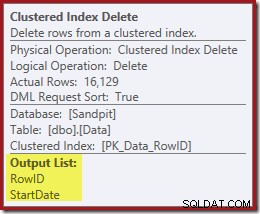
Il peut sembler surprenant de voir un opérateur Supprimer lire des données, mais c'est ainsi que cela fonctionne. Le processeur de requêtes sait qu'il devra localiser la ligne dans l'index clusterisé afin de la supprimer, il peut donc tout aussi bien différer la lecture des colonnes nécessaires pour maintenir les index non clusterisés jusqu'à ce moment, s'il le peut.
Ajouter un index filtré
Imaginez maintenant que quelqu'un a une requête cruciale sur cette table qui fonctionne mal. L'utile DBA effectue une analyse et ajoute l'index filtré suivant :
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; Le nouvel index filtré a l'effet souhaité sur la requête problématique, et tout le monde est content. Notez que le nouvel index ne référence pas du tout la colonne StartDate, nous ne nous attendons donc pas du tout à ce qu'il affecte notre requête day-delete.
Suppression d'un jour avec l'index filtré en place
Nous pouvons tester cette attente en supprimant les données une seconde fois :
DELETE dbo.Data WHERE StartDate = '20140102';
Soudainement, le plan d'exécution est passé à une analyse d'index clusterisée parallèle :

Notez qu'il n'y a pas d'opérateur de suppression d'index séparé pour le nouvel index filtré. L'optimiseur a choisi de conserver cet index dans l'opérateur Clustered Index Delete. Ceci est mis en évidence dans SQL Sentry Plan Explorer comme indiqué ci-dessus ("+1 index non clusterisés") avec tous les détails dans l'info-bulle :
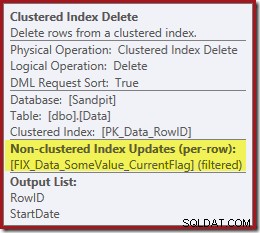
Si la table est volumineuse (pensez à un entrepôt de données), ce passage à une analyse parallèle peut être très important. Qu'est-il arrivé au joli Index Seek sur StartDate, et pourquoi un index filtré totalement indépendant a-t-il changé les choses de manière si spectaculaire ?
Rechercher le problème
Le premier indice vient de l'examen des propriétés de Clustered Index Scan :
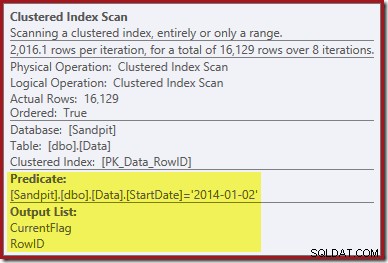
En plus de rechercher les valeurs RowID pour l'opérateur Clustered Index Delete à supprimer, cet opérateur lit maintenant les valeurs CurrentFlag. La nécessité de cette colonne n'est pas claire, mais elle commence au moins à expliquer la décision d'analyser :la colonne CurrentFlag ne fait pas partie de notre index non clusterisé StartDate.
Nous pouvons le confirmer en réécrivant la requête de suppression pour forcer l'utilisation de l'index non cluster StartDate :
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; Le plan d'exécution est plus proche de sa forme d'origine, mais il comporte désormais une recherche clé :
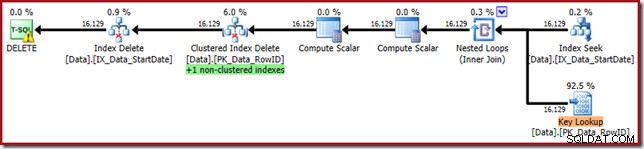
Les propriétés Key Lookup confirment que cet opérateur récupère les valeurs CurrentFlag :
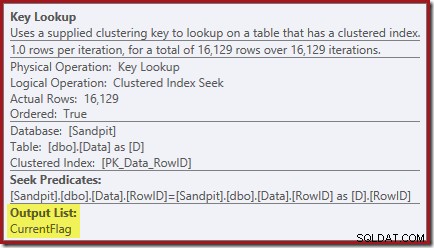
Vous avez peut-être aussi remarqué les triangles d'avertissement dans les deux derniers plans. Il manque des avertissements d'index :
Ceci est une confirmation supplémentaire que SQL Server souhaite voir la colonne CurrentFlag incluse dans l'index non clusterisé. La raison du passage à une analyse d'index clusterisée parallèle est maintenant claire :le processeur de requêtes décide que l'analyse de la table sera moins chère que l'exécution des recherches de clé.
Oui, mais pourquoi ?
Tout cela est très bizarre. Dans le plan d'exécution d'origine, SQL Server pouvait lire données de colonne supplémentaires nécessaires pour maintenir les index non clusterisés au niveau de l'opérateur Clustered Index Delete. La valeur de la colonne CurrentFlag est nécessaire pour maintenir l'index filtré, alors pourquoi SQL Server ne le gère-t-il pas simplement de la même manière ?
La réponse courte est que c'est possible, mais uniquement si l'index filtré est conservé dans un opérateur de suppression d'index séparé. Nous pouvons forcer cela pour la requête en cours en utilisant l'indicateur de trace non documenté 8790. Sans cet indicateur, l'optimiseur choisit de conserver chaque index dans un opérateur séparé ou dans le cadre de l'opération de table de base.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
Le plan d'exécution revient à la recherche de l'index non cluster StartDate :
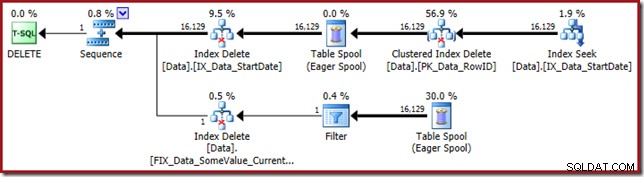
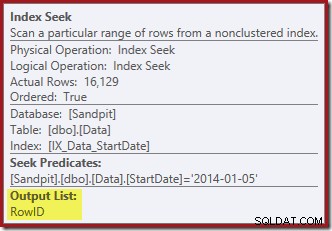
La recherche d'index renvoie uniquement les valeurs RowID (pas de CurrentFlag) :
Et la suppression de l'index clusterisé lit les colonnes nécessaires pour maintenir les index non-cluster, y compris CurrentFlag :
Ces données sont écrites avec impatience dans un spool de table, qui est rejoué pour chaque index qui doit être maintenu. Notez également l'opérateur de filtre explicite avant l'opérateur de suppression d'index pour l'index filtré.
Un autre modèle à surveiller
Ce problème n'entraîne pas toujours une analyse de table au lieu d'une recherche d'index. Pour en voir un exemple, ajoutez un autre index à la table de test :
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Notez que cet index n'est pas filtrée et n'implique pas la colonne StartDate. Maintenant, essayez à nouveau une requête de suppression de jour :
DELETE dbo.Data WHERE StartDate = '20140104';
L'optimiseur propose maintenant ce monstre :
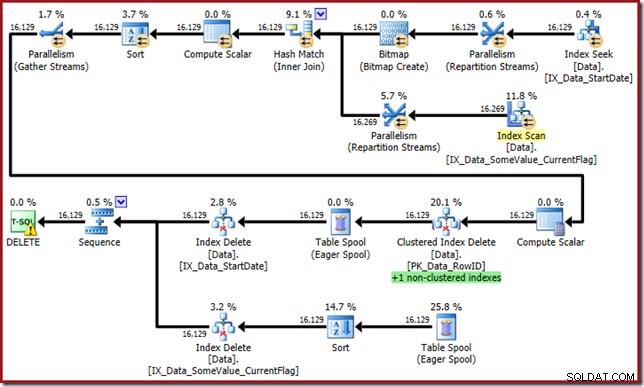
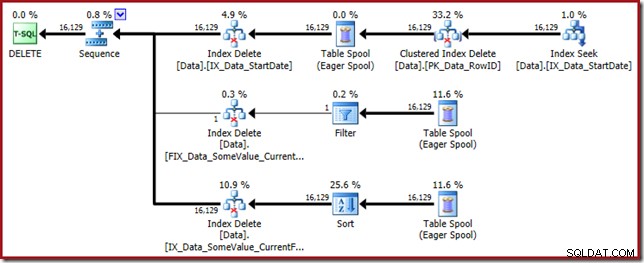
Ce plan de requête a un facteur de surprise élevé, mais la cause première est la même. La colonne CurrentFlag est toujours nécessaire, mais maintenant l'optimiseur choisit une stratégie d'intersection d'index pour l'obtenir au lieu d'une analyse de table. L'utilisation de l'indicateur de trace force un plan de maintenance par index et la cohérence est à nouveau restaurée (la seule différence est une relecture de spool supplémentaire pour maintenir le nouvel index) :
Seuls les index filtrés en sont la cause
Ce problème se produit uniquement si l'optimiseur choisit de conserver un index filtré dans un opérateur Clustered Index Delete. Les index non filtrés ne sont pas affectés, comme le montre l'exemple suivant. La première étape consiste à supprimer l'index filtré :
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Nous devons maintenant écrire la requête de manière à convaincre l'optimiseur de conserver tous les index dans Clustered Index Delete. Mon choix pour cela est d'utiliser une variable et un indice pour réduire les attentes de l'optimiseur en matière de nombre de lignes :
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); Le plan d'exécution est :
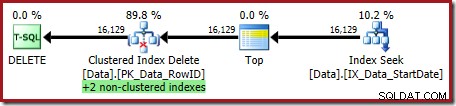
Les deux index non clusterisés sont maintenus par Clustered Index Delete :
L'Index Seek renvoie uniquement le RowID :
Les colonnes nécessaires à la maintenance de l'index sont récupérées en interne par l'opérateur de suppression; ces détails ne sont pas exposés dans la sortie du plan d'exposition (la liste de sortie de l'opérateur de suppression serait donc vide). J'ai ajouté un OUTPUT clause à la requête pour afficher la suppression de l'index clusterisé renvoyant à nouveau des données qu'il n'a pas reçues sur son entrée :
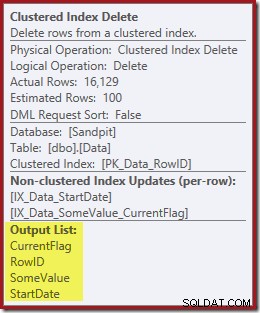
Réflexions finales
Il s'agit d'une limitation délicate à contourner. D'une part, nous ne souhaitons généralement pas utiliser d'indicateurs de trace non documentés dans les systèmes de production.
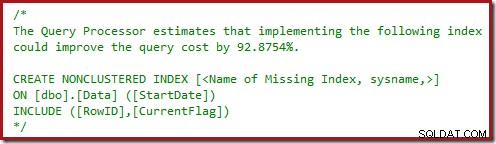
La "solution" naturelle consiste à ajouter les colonnes nécessaires à la maintenance de l'index filtré à tous index non-cluster pouvant être utilisés pour localiser les lignes à supprimer. Ce n'est pas une proposition très attrayante, d'un certain nombre de points de vue. Une autre alternative consiste simplement à ne pas utiliser d'index filtrés du tout, mais ce n'est pas non plus l'idéal.
Mon sentiment est que l'optimiseur de requête devrait envisager automatiquement une alternative de maintenance par index pour les index filtrés, mais son raisonnement semble être incomplet dans ce domaine pour le moment (et basé sur des heuristiques simples plutôt que sur un coût correct par index/par ligne alternative).
Pour mettre quelques chiffres autour de cette déclaration, le plan d'analyse d'index cluster parallèle choisi par l'optimiseur est arrivé à 5.5 unités dans mes tests. La même requête avec l'indicateur de trace estime un coût de 1,4 unités. Avec le troisième index en place, le plan d'intersection d'index parallèles choisi par l'optimiseur avait un coût estimé de 4,9 , alors que le plan d'indicateur de trace est arrivé à 2,7 unités (tous les tests sur SQL Server 2014 RTM CU1 build 12.0.2342 sous le modèle d'estimation de cardinalité 120 et avec l'indicateur de trace 4199 activé).
Je considère cela comme un comportement qui devrait être amélioré. Vous pouvez voter pour être d'accord ou pas avec moi sur cet élément Connect.