Il existe de nombreux cas d'utilisation pour générer une séquence de valeurs dans SQL Server. Je ne parle pas d'une IDENTITY persistante colonne (ou la nouvelle colonne SEQUENCE dans SQL Server 2012), mais plutôt un ensemble transitoire à utiliser uniquement pendant la durée de vie d'une requête. Ou même les cas les plus simples - comme simplement ajouter un numéro de ligne à chaque ligne dans un jeu de résultats - ce qui peut impliquer l'ajout d'un ROW_NUMBER() fonction à la requête (ou, mieux encore, dans le niveau de présentation, qui doit de toute façon parcourir les résultats ligne par ligne).
Je parle de cas un peu plus compliqués. Par exemple, vous pouvez avoir un rapport qui affiche les ventes par date. Une requête typique pourrait être :
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
Le problème avec cette requête est que, s'il n'y a pas de commandes un certain jour, il n'y aura pas de ligne pour ce jour. Cela peut entraîner de la confusion, des données trompeuses ou même des calculs incorrects (pensez aux moyennes quotidiennes) pour les consommateurs en aval des données.
Il est donc nécessaire de combler ces lacunes avec les dates qui ne sont pas présentes dans les données. Et parfois, les gens vont mettre leurs données dans une table #temp et utiliser un WHILE boucle ou un curseur pour remplir les dates manquantes une par une. Je ne montrerai pas ce code ici parce que je ne veux pas préconiser son utilisation, mais je l'ai vu partout.
Avant d'entrer trop en profondeur dans les dates, parlons d'abord des nombres, car vous pouvez toujours utiliser une séquence de nombres pour dériver une séquence de dates.
Tableau des nombres
J'ai longtemps été partisan du stockage d'une "table de nombres" auxiliaire sur disque (et, d'ailleurs, d'une table de calendrier également).
Voici une façon de générer un tableau de nombres simple avec 1 000 000 valeurs :
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
Pourquoi MAXDOP 1 ? Voir le billet de blog de Paul White et son article Connect relatif aux objectifs de ligne.
Cependant, de nombreuses personnes s'opposent à l'approche de la table auxiliaire. Leur argument :pourquoi stocker toutes ces données sur disque (et en mémoire) alors qu'ils peuvent générer les données à la volée ? Mon compteur est d'être réaliste et de réfléchir à ce que vous optimisez ; le calcul peut être coûteux, et êtes-vous sûr que le calcul d'une plage de nombres à la volée sera toujours moins cher ? En ce qui concerne l'espace, la table Numbers ne prend qu'environ 11 Mo compressés et 17 Mo non compressés. Et si la table est référencée assez fréquemment, elle doit toujours être en mémoire, ce qui rend l'accès rapide.
Jetons un coup d'œil à quelques exemples et à certaines des approches les plus courantes utilisées pour les satisfaire. J'espère que nous pourrons tous convenir que, même à 1 000 valeurs, nous ne voulons pas résoudre ces problèmes à l'aide d'une boucle ou d'un curseur.
Générer une séquence de 1 000 numéros
Commençons simplement, générons un ensemble de nombres de 1 à 1 000.
Tableau des nombres
Bien sûr, avec une table de nombres, cette tâche est assez simple :
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Forfait :
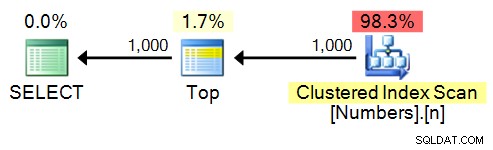
spt_values
Il s'agit d'une table utilisée par les procédures stockées internes à diverses fins. Son utilisation en ligne semble être assez répandue, même si elle est non documentée, non prise en charge, elle pourrait disparaître un jour, et parce qu'elle ne contient qu'un ensemble de valeurs fini, non unique et non contiguë. Il existe 2 164 valeurs uniques et 2 508 valeurs totales dans SQL Server 2008 R2; en 2012, il y en a 2 167 uniques et 2 515 au total. Cela inclut les doublons, les valeurs négatives et même si vous utilisez DISTINCT , beaucoup d'écarts une fois que vous avez dépassé le nombre 2 048. La solution consiste donc à utiliser ROW_NUMBER() pour générer une séquence contiguë, commençant à 1, basée sur les valeurs du tableau.
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
Forfait :

Cela dit, pour seulement 1 000 valeurs, vous pouvez écrire une requête un peu plus simple pour générer la même séquence :
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
Cela conduit à un plan plus simple, bien sûr, mais se décompose assez rapidement (une fois que votre séquence doit comporter plus de 2 048 lignes) :
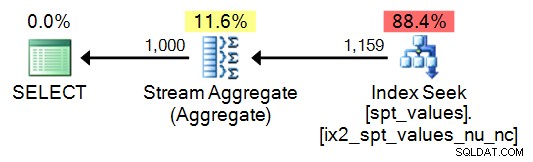
Dans tous les cas, je ne recommande pas l'utilisation de ce tableau; Je l'inclus à des fins de comparaison, uniquement parce que je sais à quel point cela existe et à quel point il peut être tentant de simplement réutiliser le code que vous rencontrez.
sys.all_objects
Une autre approche qui a été l'une de mes préférées au fil des ans consiste à utiliser sys.all_objects . Comme spt_values , il n'existe aucun moyen fiable de générer directement une séquence contiguë, et nous rencontrons les mêmes problèmes avec un ensemble fini (un peu moins de 2 000 lignes dans SQL Server 2008 R2 et un peu plus de 2 000 lignes dans SQL Server 2012), mais pour 1 000 lignes nous pouvons utiliser le même ROW_NUMBER() duper. La raison pour laquelle j'aime cette approche est que (a) on craint moins que cette vue ne disparaisse bientôt, (b) la vue elle-même est documentée et prise en charge, et (c) elle fonctionnera sur n'importe quelle base de données sur n'importe quelle version depuis SQL Server 2005 sans avoir à franchir les limites de la base de données (y compris les bases de données autonomes).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Forfait :

CTE empilés
Je crois qu'Itzik Ben-Gan mérite le crédit ultime pour cette approche; en gros, vous construisez un CTE avec un petit ensemble de valeurs, puis vous créez le produit cartésien contre lui-même afin de générer le nombre de lignes dont vous avez besoin. Et encore une fois, au lieu d'essayer de générer un ensemble contigu dans le cadre de la requête sous-jacente, nous pouvons simplement appliquer ROW_NUMBER() au résultat final.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; Forfait :
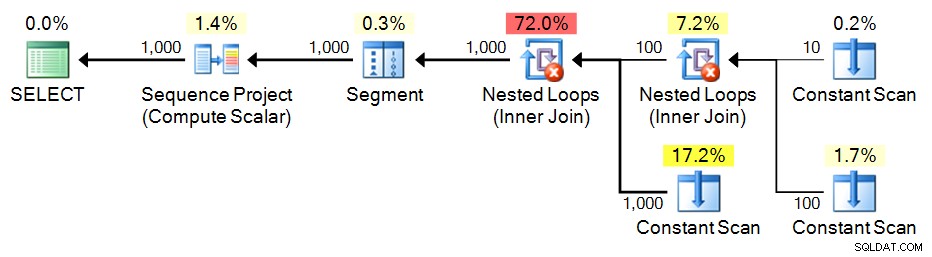
CTE récursif
Enfin, nous avons un CTE récursif, qui utilise 1 comme ancre et ajoute 1 jusqu'à ce que nous atteignions le maximum. Par sécurité, je précise le maximum à la fois dans WHERE clause de la partie récursive, et dans la MAXRECURSION paramètre. Selon le nombre de numéros dont vous avez besoin, vous devrez peut-être définir MAXRECURSION à 0 .
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); Forfait :
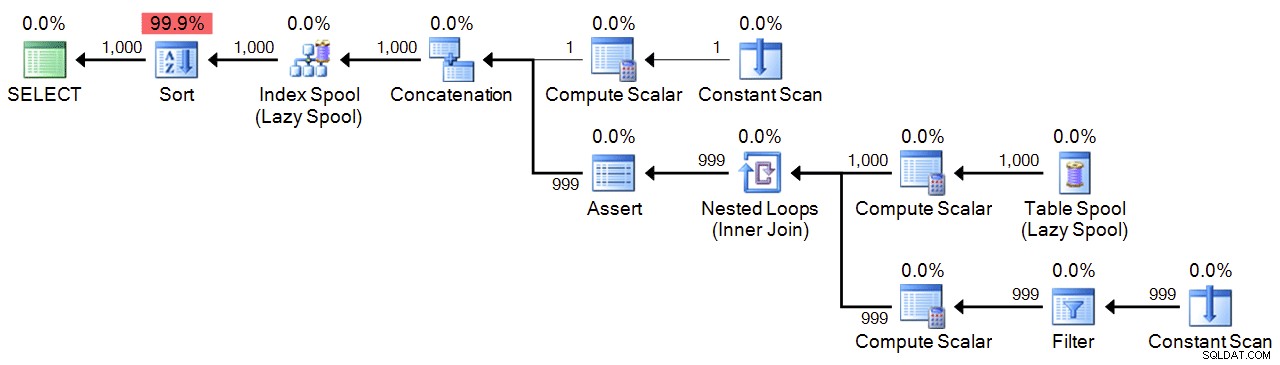
Performances
Bien sûr avec 1 000 valeurs les différences de performances sont négligeables, mais il peut être utile de voir comment fonctionnent ces différentes options :
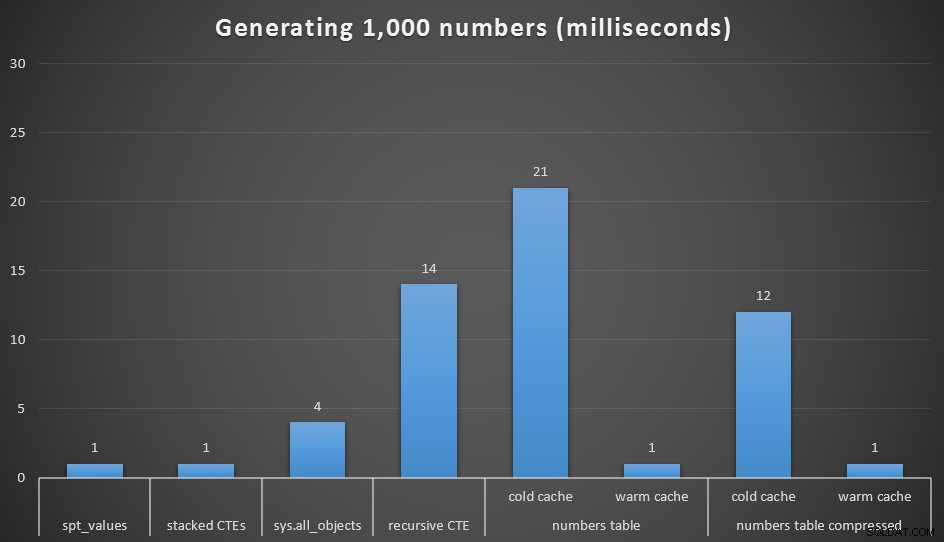
Durée d'exécution, en millisecondes, pour générer 1 000 nombres contigus
J'ai exécuté chaque requête 20 fois et j'ai pris des temps d'exécution moyens. J'ai aussi testé le dbo.Numbers table, dans les formats compressés et non compressés, et avec à la fois un cache froid et un cache chaud. Avec un cache chaud, il rivalise de très près avec les autres options les plus rapides (spt_values , non recommandé et CTE empilés), mais le premier coup est relativement cher (bien que je ris presque de l'appeler ainsi).
A suivre…
S'il s'agit de votre cas d'utilisation typique et que vous ne vous aventurez pas bien au-delà de 1 000 lignes, j'espère avoir montré les moyens les plus rapides de générer ces chiffres. Si votre cas d'utilisation est un nombre plus grand, ou si vous cherchez des solutions pour générer des séquences de dates, restez à l'écoute. Plus tard dans cette série, j'explorerai la génération de séquences de 50 000 et 1 000 000 nombres, et de plages de dates allant d'une semaine à un an.
[ Partie 1 | Partie 2 | Partie 3 ]



