La qualité d'un plan d'exécution dépend fortement de la précision du nombre estimé de lignes générées par chaque opérateur de plan. Si le nombre estimé de lignes est significativement faussé par rapport au nombre réel de lignes, cela peut avoir un impact significatif sur la qualité du plan d'exécution d'une requête. Une mauvaise qualité de plan peut être responsable d'E/S excessives, d'un processeur gonflé, d'une pression sur la mémoire, d'un débit réduit et d'une simultanéité globale réduite.
Par "qualité du plan" - je parle de la génération par SQL Server d'un plan d'exécution qui se traduit par des choix d'opérateurs physiques qui reflètent l'état actuel des données. En prenant de telles décisions sur la base de données précises, il y a de meilleures chances que la requête s'exécute correctement. Les valeurs estimées de cardinalité sont utilisées comme données d'entrée pour le calcul des coûts de l'opérateur, et lorsque les valeurs sont trop éloignées de la réalité, l'impact négatif sur le plan d'exécution peut être prononcé. Ces estimations sont transmises aux différents modèles de coût associés à la requête elle-même, et les mauvaises estimations de ligne peuvent avoir un impact sur diverses décisions, notamment la sélection d'index, les opérations de recherche ou d'analyse, l'exécution parallèle ou série, la sélection de l'algorithme de jointure, la jointure physique interne ou externe. sélection (par exemple, construction ou sonde), génération de spool, recherches de signets par rapport à l'accès complet en cluster ou à la table de tas, sélection de flux ou d'agrégat de hachage, et si une modification de données utilise ou non un plan large ou étroit.
Par exemple, supposons que vous ayez le SELECT suivant requête (à l'aide de la base de données de crédit) :
SELECT m.member_no, m.lastname, p.payment_no, p.payment_dt, p.payment_amt FROM dbo.member AS m INNER JOIN dbo.payment AS p ON m.member_no = p.member_no;
D'après la logique de requête, la forme de plan suivante correspond-elle à ce que vous vous attendez à voir ?
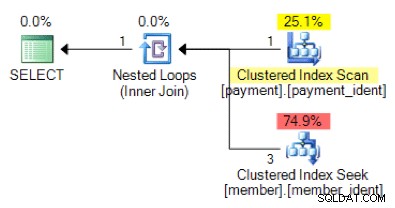
Et qu'en est-il de ce plan alternatif, où au lieu d'une boucle imbriquée, nous avons une correspondance de hachage ?
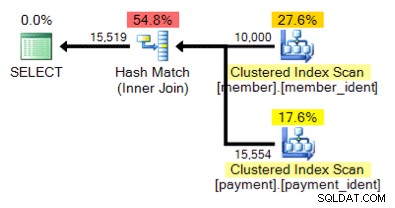
La réponse "correcte" dépend de quelques autres facteurs - mais un facteur majeur est le nombre de lignes dans chacun des tableaux. Dans certains cas, un algorithme de jointure physique est plus approprié qu'un autre. Si les hypothèses initiales d'estimation de la cardinalité ne sont pas correctes, votre requête utilise peut-être une approche non optimale.
Identifier Les problèmes d'estimation de cardinalité sont relativement simples. Si vous disposez d'un plan d'exécution réel, vous pouvez comparer les valeurs de nombre de lignes estimées et réelles pour les opérateurs et rechercher les écarts. SQL Sentry Plan Explorer simplifie cette tâche en vous permettant de voir les lignes réelles par rapport aux lignes estimées pour tous les opérateurs dans un seul onglet d'arborescence de plan au lieu d'avoir à survoler les opérateurs individuels dans le plan graphique :

Maintenant, les décalages ne se traduisent pas toujours par des plans de mauvaise qualité, mais si vous rencontrez des problèmes de performances avec une requête et que vous voyez de tels décalages dans le plan, c'est un domaine qui mérite alors une enquête plus approfondie.
L'identification des problèmes d'estimation de cardinalité est relativement simple, mais la résolution ne l'est souvent pas. Il existe un certain nombre de causes profondes expliquant pourquoi des problèmes d'estimation de cardinalité peuvent survenir, et je couvrirai dix des raisons les plus courantes dans cet article.
Statistiques manquantes ou périmées
De toutes les raisons des problèmes d'estimation de cardinalité, c'est celle que vous espérez à voir, car c'est souvent le plus facile à régler. Dans ce scénario, vos statistiques sont manquantes ou obsolètes. Vous pouvez avoir des options de base de données pour la création et les mises à jour automatiques de statistiques désactivées, "pas de recalcul" activé pour des statistiques spécifiques, ou avoir des tables suffisamment grandes pour que vos mises à jour automatiques de statistiques ne se produisent tout simplement pas assez fréquemment.
Problèmes d'échantillonnage
Il se peut que la précision de l'histogramme des statistiques soit inadéquate - par exemple, si vous avez une très grande table avec des biais de données importants et/ou fréquents. Vous devrez peut-être modifier votre échantillonnage par défaut ou, si cela ne vous aide pas, enquêtez à l'aide de tableaux séparés, de statistiques filtrées ou d'index filtrés.
Corrélations de colonnes masquées
L'optimiseur de requête suppose que les colonnes d'une même table sont indépendantes. Par exemple, si vous avez une colonne de ville et d'état, nous pouvons intuitivement savoir que ces deux colonnes sont corrélées, mais SQL Server ne le comprend pas à moins que nous ne l'aidions avec un index multi-colonnes associé, ou avec des multi-index créés manuellement. statistiques de colonne. Sans aider l'optimiseur avec la corrélation, la sélectivité de vos prédicats peut être exagérée.
Ci-dessous un exemple de deux prédicats corrélés :
SELECT lastname, firstname FROM dbo.member WHERE city = 'Minneapolis' AND state_prov - 'MN';
Je sais que 10 % de nos 10 000 lignes member table est éligible pour cette combinaison, mais l'optimiseur de requête suppose qu'il s'agit de 1 % des 10 000 lignes :
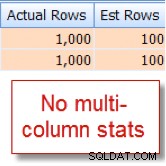
Maintenant, comparez cela avec l'estimation appropriée que je vois après avoir ajouté des statistiques multi-colonnes :
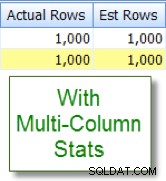
Comparaisons de colonnes intra-table
Des problèmes d'estimation de cardinalité peuvent survenir lors de la comparaison de colonnes au sein d'une même table. C'est un problème connu. Si vous devez le faire, vous pouvez améliorer les estimations de cardinalité des comparaisons de colonnes en utilisant à la place des colonnes calculées ou en réécrivant la requête pour utiliser des auto-jointures ou des expressions de table communes.
Utilisation des variables de tableau
Vous utilisez beaucoup les variables de table ? Les variables de table affichent une estimation de cardinalité de "1" - ce qui, pour un petit nombre de lignes seulement, peut ne pas être un problème, mais pour des ensembles de résultats volumineux ou volatils, cela peut avoir un impact significatif sur la qualité du plan de requête. Vous trouverez ci-dessous une capture d'écran de l'estimation d'un opérateur d'une ligne par rapport aux 1 600 000 lignes réelles du @charge variable de tableau :

S'il s'agit de votre cause principale, vous seriez bien avisé d'explorer des alternatives telles que des tables temporaires et/ou des tables intermédiaires permanentes lorsque cela est possible.
FDU scalaire et MSTV
Semblables aux variables de table, les fonctions table et scalaires multi-instructions sont une boîte noire du point de vue de l'estimation de la cardinalité. Si vous rencontrez des problèmes de qualité de plan à cause d'eux, envisagez les fonctions de table en ligne comme alternative - ou même extrayez entièrement la référence de la fonction et faites simplement référence aux objets directement.
Vous trouverez ci-dessous un plan estimé par rapport au plan réel lors de l'utilisation d'une fonction table à plusieurs instructions :
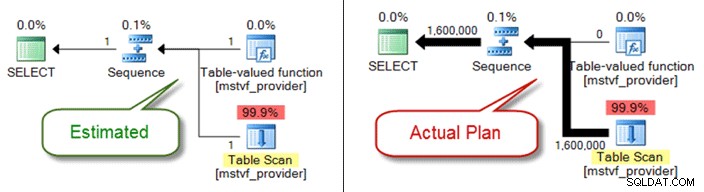
Problèmes de type de données
Les problèmes de type de données implicites associés aux conditions de recherche et de jointure peuvent entraîner des problèmes d'estimation de cardinalité. Ils peuvent également ronger subrepticement les ressources au niveau du serveur (processeur, E/S, mémoire), il est donc important de les traiter chaque fois que possible.
Prédicats complexes
Vous avez probablement déjà vu ce modèle - une requête avec un WHERE clause qui a chaque référence de colonne de table enveloppée dans diverses fonctions, opérations de concaténation, opérations mathématiques et plus encore. Et bien que toutes les fonctions d'encapsulation n'empêchent pas les estimations de cardinalité appropriées (comme pour LOWER , UPPER et GETDATE ) il existe de nombreuses façons d'enterrer votre prédicat au point que l'optimiseur de requête ne peut plus faire d'estimations précises.
Complexité des requêtes
Semblables aux prédicats enterrés, vos requêtes sont-elles extraordinairement complexes ? Je réalise que "complexe" est un terme subjectif, et votre évaluation peut varier, mais la plupart peuvent convenir que l'imbrication de vues dans des vues dans des vues qui font référence à des tables qui se chevauchent est susceptible d'être non optimale - en particulier lorsqu'elle est associée à plus de 10 jointures de table, références de fonction et les prédicats enterrés. Bien que l'optimiseur de requêtes fasse un travail admirable, ce n'est pas magique, et si vous avez des biais importants, la complexité des requêtes (requêtes au couteau suisse) peut certainement rendre presque impossible la dérivation d'estimations de lignes précises pour les opérateurs.
Requêtes distribuées
Utilisez-vous des requêtes distribuées avec des serveurs liés et rencontrez-vous d'importants problèmes d'estimation de cardinalité ? Si tel est le cas, assurez-vous de vérifier les autorisations associées au principal du serveur lié utilisé pour accéder aux données. Sans le minimum db_ddladmin rôle de base de données fixe pour le compte de serveur lié, ce manque de visibilité sur les statistiques distantes en raison d'autorisations insuffisantes peut être la source de vos problèmes d'estimation de cardinalité.
Et il y en a d'autres…
Il existe d'autres raisons pour lesquelles les estimations de cardinalité peuvent être faussées, mais je pense avoir couvert les plus courantes. Le point clé est de prêter attention aux biais associés aux requêtes connues et peu performantes. Ne présumez pas que le plan a été généré sur la base de conditions de nombre de lignes précises. Si ces chiffres sont faussés, vous devez d'abord essayer de résoudre ce problème.