Le basculement est la capacité d'un système à continuer à fonctionner même en cas de panne. Cela suggère que les fonctions du système sont assumées par des composants secondaires si les composants primaires échouent ou si cela est nécessaire. Donc, si vous le traduisez dans un environnement multi-cloud PostgreSQL, cela signifie que lorsque votre nœud principal échoue (ou une autre raison comme nous le mentionnerons dans la section suivante) dans votre fournisseur de cloud principal, vous devez être en mesure de promouvoir le nœud de secours. dans le secondaire pour maintenir les systèmes en marche.
En général, tous les fournisseurs de cloud vous offrent une option de basculement dans le même fournisseur de cloud, mais il se peut que vous deviez basculer vers un autre fournisseur de cloud différent. Bien sûr, vous pouvez le faire manuellement, mais vous pouvez également utiliser certaines des fonctionnalités de ClusterControl telles que le basculement automatique ou promouvoir l'action esclave pour le faire de manière simple et conviviale.
Dans ce blog, vous verrez pourquoi vous devriez avoir besoin d'un basculement, comment le faire manuellement et comment utiliser ClusterControl pour cette tâche. Nous supposerons que vous avez une installation ClusterControl en cours d'exécution et que votre cluster de base de données a déjà été créé dans deux fournisseurs de cloud différents.
À quoi sert le basculement ?
Il existe plusieurs utilisations possibles du basculement.
Échec du maître
Si votre nœud principal est en panne ou même si votre fournisseur de cloud principal rencontre des problèmes, vous devez basculer pour garantir la disponibilité de votre système. Dans ce cas, il peut être nécessaire de disposer d'un moyen automatique de le faire pour réduire les temps d'arrêt.
Migration
Si vous souhaitez migrer vos systèmes d'un fournisseur de cloud vers un autre en minimisant vos temps d'arrêt, vous pouvez utiliser le basculement. Vous pouvez créer une réplique dans le fournisseur de cloud secondaire, et une fois qu'elle est synchronisée, vous devez arrêter votre système, promouvoir votre réplique et basculer, avant de pointer votre système vers le nouveau nœud principal dans le fournisseur de cloud secondaire.
Maintenance
Si vous devez effectuer une tâche de maintenance sur votre nœud principal PostgreSQL, vous pouvez promouvoir votre réplique, effectuer la tâche et reconstruire votre ancien nœud principal en tant que nœud de secours.
Après cela, vous pouvez promouvoir l'ancien nœud principal et répéter le processus de reconstruction sur le nœud de secours, en revenant à l'état initial.
De cette façon, vous pouvez travailler sur votre serveur, sans courir le risque d'être hors ligne ou de perdre des informations lors de l'exécution d'une tâche de maintenance.
Mises à niveau
Il est possible de mettre à niveau votre version de PostgreSQL (depuis PostgreSQL 10) ou même de mettre à niveau votre système d'exploitation en utilisant la réplication logique sans temps d'arrêt, comme cela peut être fait avec d'autres moteurs.
Les étapes seraient les mêmes que pour migrer vers un nouveau fournisseur de cloud, sauf que votre réplica serait dans une version plus récente de PostgreSQL ou du système d'exploitation et que vous devez utiliser la réplication logique car vous ne pouvez pas utiliser le streaming réplication entre différentes versions.
Le basculement ne concerne pas seulement la base de données, mais aussi l'application. Comment savent-ils à quelle base de données se connecter ? Vous ne voulez probablement pas avoir à modifier votre application, car cela ne fera que prolonger votre temps d'arrêt, vous pouvez donc configurer un équilibreur de charge qui, lorsque votre nœud principal est en panne, pointera automatiquement vers le serveur qui a été promu.
Avoir une seule instance Load Balancer n'est pas la meilleure option car elle peut devenir un point de défaillance unique. Par conséquent, vous pouvez également implémenter le basculement pour l'équilibreur de charge, à l'aide d'un service tel que Keepalived. De cette façon, si vous rencontrez un problème avec votre Load Balancer principal, Keepalived migrera l'IP virtuelle vers votre Load Balancer secondaire, et tout continuera à fonctionner de manière transparente.
Une autre option est l'utilisation du DNS. En promouvant le nœud de secours dans le fournisseur de cloud secondaire, vous modifiez directement l'adresse IP du nom d'hôte qui pointe vers le nœud principal. De cette façon, vous évitez d'avoir à modifier votre application, et bien que cela ne puisse pas se faire automatiquement, c'est une alternative si vous ne souhaitez pas mettre en place un Load Balancer.
Comment basculer PostgreSQL manuellement
Avant d'effectuer un basculement manuel, vous devez vérifier l'état de la réplication. Il se peut que, lorsque vous avez besoin d'un basculement, le nœud de secours ne soit pas à jour, en raison d'une panne de réseau, d'une charge élevée ou d'un autre problème, vous devez donc vous assurer que votre nœud de secours dispose de tous (ou presque toutes les informations. Si vous avez plusieurs nœuds de secours, vous devez également vérifier lequel est le nœud le plus avancé et le choisir pour le basculement.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Lorsque vous choisissez le nouveau nœud principal, vous pouvez d'abord exécuter la commande pg_lsclusters pour obtenir les informations sur le cluster :
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logEnsuite, il vous suffit d'exécuter la commande pg_ctlcluster avec l'action de promotion :
$ pg_ctlcluster 12 main promoteAu lieu de la commande précédente, vous pouvez exécuter la commande pg_ctl de cette manière :
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedEnsuite, votre nœud de secours sera promu au rang de nœud principal et vous pourrez le valider en exécutant la requête suivante dans votre nouveau nœud principal :
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Si le résultat est « f », il s'agit de votre nouveau nœud principal.
Maintenant, vous devez modifier l'adresse IP de la base de données principale dans votre application, Load Balancer, DNS ou l'implémentation que vous utilisez, ce qui, comme nous l'avons mentionné, la modification manuelle augmentera le temps d'arrêt. Vous devez également vous assurer que votre connectivité entre les fournisseurs de cloud fonctionne correctement, que l'application peut accéder au nouveau nœud principal, que l'utilisateur de l'application dispose des privilèges pour y accéder à partir d'un autre fournisseur de cloud et que vous devez reconstruire le ou les nœuds de secours dans le fournisseur de cloud distant ou même local, pour répliquer à partir du nouveau principal, sinon vous n'aurez pas de nouvelle option de basculement si nécessaire.
Comment basculer PostgreSQL à l'aide de ClusterControl
ClusterControl possède un certain nombre de fonctionnalités liées à la réplication PostgreSQL et au basculement automatisé. Nous supposerons que votre serveur ClusterControl est installé et qu'il gère votre environnement PostgreSQL multi-cloud.
Avec ClusterControl, vous pouvez ajouter autant de nœuds de secours ou de nœuds Load Balancer que nécessaire sans aucune restriction IP réseau. Cela signifie qu'il n'est pas nécessaire que le nœud de secours se trouve dans le même réseau de nœud principal ou même dans le même fournisseur de cloud. En termes de basculement, ClusterControl vous permet de le faire manuellement ou automatiquement.
Basculement manuel
Pour effectuer un basculement manuel, allez dans ClusterControl -> Select Cluster -> Nodes, et dans les Node Actions de l'un de vos nœuds de secours, sélectionnez "Promote Slave".
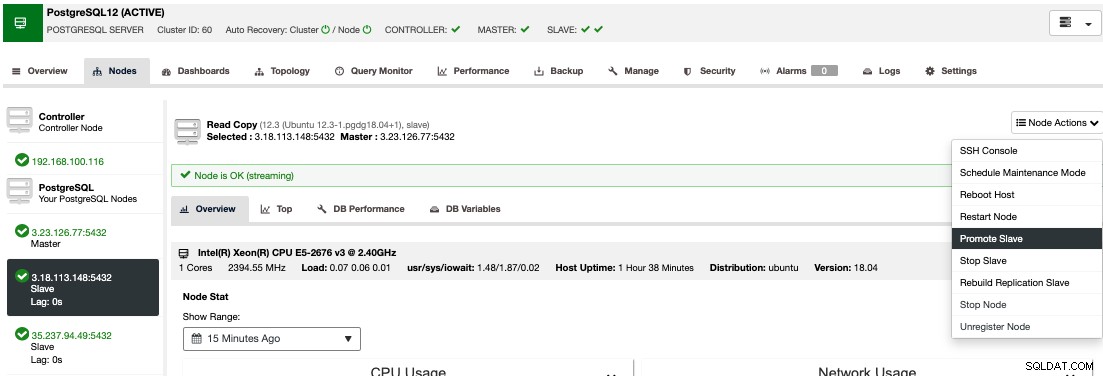
Ainsi, après quelques secondes, votre nœud de secours devient primaire, et ce qui était votre principal auparavant, est transformé en un de secours. Ainsi, si votre réplique se trouvait chez un autre fournisseur de cloud, votre nouveau nœud principal sera là, opérationnel.
Basculement automatique
En cas de basculement automatique, ClusterControl détecte les défaillances dans le nœud principal et promeut un nœud de secours avec les données les plus récentes en tant que nouveau nœud principal. Cela fonctionne également sur le reste des nœuds de secours pour qu'ils se répliquent à partir de ce nouveau nœud principal.

Lorsque l'option "Récupération automatique" est activée, ClusterControl effectuera un basculement automatique en tant que ainsi que vous informer du problème. De cette façon, vos systèmes peuvent récupérer en quelques secondes et sans votre intervention.
ClusterControl vous offre la possibilité de configurer une liste blanche/noire pour définir comment vous souhaitez que vos serveurs soient pris en compte (ou non) lors de la sélection d'un candidat principal.
ClusterControl effectue également plusieurs vérifications sur le processus de basculement, par exemple, par défaut, si vous parvenez à récupérer votre ancien nœud principal défaillant, il ne sera pas réintroduit automatiquement dans le cluster, ni en tant que nœud principal ni en veille, vous devrez le faire manuellement. Cela évitera la possibilité de perte de données ou d'incohérence dans le cas où votre veille (que vous avez promue) a été retardée au moment de l'échec. Vous voudrez peut-être également analyser le problème en détail, mais en l'ajoutant à votre cluster, vous risquez de perdre des informations de diagnostic.
Équilibreurs de charge
Comme nous l'avons mentionné précédemment, l'équilibreur de charge est un outil important à prendre en compte pour votre basculement, en particulier si vous souhaitez utiliser le basculement automatique dans la topologie de votre base de données.
Pour que le basculement soit transparent à la fois pour l'utilisateur et pour l'application, vous avez besoin d'un composant intermédiaire, car il ne suffit pas de promouvoir un nouveau nœud principal. Pour cela, vous pouvez utiliser HAProxy + Keepalived.
Pour implémenter cette solution avec ClusterControl, accédez aux Actions de cluster -> Ajouter un équilibreur de charge -> HAProxy sur votre cluster PostgreSQL. Dans le cas où vous souhaitez implémenter le basculement pour votre Load Balancer, vous devez configurer au moins deux instances HAProxy, puis vous pouvez configurer Keepalived (Cluster Actions -> Add Load Balancer -> Keepalived). Vous trouverez plus d'informations sur cette mise en œuvre dans cet article de blog.
Après cela, vous aurez la topologie suivante :

HAProxy est configuré par défaut avec deux ports différents, un en lecture-écriture et un un en lecture seule.
Dans le port de lecture-écriture, vous avez votre nœud principal en ligne et le reste des nœuds hors ligne. Dans le port en lecture seule, les nœuds principal et de secours sont en ligne. De cette façon, vous pouvez équilibrer le trafic de lecture entre les nœuds. Lors de l'écriture, le port de lecture-écriture sera utilisé, qui pointera vers le nœud principal actuel.

Lorsque HAProxy détecte que l'un des nœuds, principal ou de secours, est n'est pas accessible, il le marque automatiquement comme étant hors ligne. HAProxy ne lui enverra aucun trafic. Cette vérification est effectuée par des scripts de vérification de l'état configurés par ClusterControl au moment du déploiement. Ceux-ci vérifient si les instances sont actives, si elles sont en cours de récupération ou sont en lecture seule.
Lorsque ClusterControl promeut un nouveau nœud principal, HAProxy marque l'ancien comme étant hors ligne (pour les deux ports) et met le nœud promu en ligne dans le port de lecture-écriture. De cette façon, vos systèmes continuent de fonctionner normalement.
Si le HAProxy actif (qui a attribué une adresse IP virtuelle à laquelle vos systèmes se connectent) échoue, Keepalived migre automatiquement cette IP virtuelle vers le HAProxy passif. Cela signifie que vos systèmes peuvent alors continuer à fonctionner normalement.
Réplication de cluster à cluster dans le cloud
Pour avoir un environnement Multi-Cloud, vous pouvez utiliser l'action ClusterControl Add Slave sur votre cluster PostgreSQL, mais aussi la fonctionnalité Cluster-to-Cluster Replication. Pour le moment, cette fonctionnalité a une limitation pour PostgreSQL qui vous permet d'avoir un seul nœud distant, mais nous travaillons à supprimer cette limitation prochainement dans une future version.
Pour le déployer, vous pouvez consulter la section "Réplication de cluster à cluster dans le cloud" dans cet article de blog.

Lorsqu'il est en place, vous pouvez promouvoir le cluster distant qui générera un cluster PostgreSQL indépendant avec un nœud principal exécuté sur le fournisseur de cloud secondaire.

Donc, au cas où vous en auriez besoin, vous aurez le même cluster en cours d'exécution dans un nouveau fournisseur de cloud en quelques secondes.
Conclusion
Avoir un processus de basculement automatique est obligatoire si vous voulez avoir le moins de temps d'arrêt possible, et l'utilisation de différentes technologies comme HAProxy et Keepalived améliorera ce basculement.
Les fonctionnalités de ClusterControl que nous avons mentionnées ci-dessus vous permettront de basculer rapidement entre différents fournisseurs de cloud et de gérer la configuration de manière simple et conviviale.
La chose la plus importante à prendre en considération avant d'effectuer un processus de basculement entre différents fournisseurs de cloud est la connectivité. Vous devez vous assurer que votre application ou vos connexions à la base de données fonctionneront comme d'habitude en utilisant le fournisseur de cloud principal mais aussi le fournisseur de cloud secondaire en cas de basculement, et, pour des raisons de sécurité, vous devez restreindre le trafic uniquement à partir de sources connues, donc uniquement entre le Cloud Fournisseurs et ne pas l'autoriser à partir d'une source externe.