Les gens se demandent s'ils doivent faire de leur mieux pour éviter les exceptions ou simplement laisser le système les gérer. J'ai vu plusieurs discussions où les gens se demandent s'ils doivent faire tout ce qu'ils peuvent pour empêcher une exception, car la gestion des erreurs est "coûteuse". Il ne fait aucun doute que la gestion des erreurs n'est pas gratuite, mais je prédis qu'une violation de contrainte est au moins aussi efficace que de vérifier d'abord une violation potentielle. Cela peut être différent pour une violation de clé d'une violation de contrainte statique, par exemple, mais dans cet article, je vais me concentrer sur la première.
Les principales approches que les gens utilisent pour gérer les exceptions sont :
- Laissez simplement le moteur s'en charger et renvoyez toute exception à l'appelant.
- Utilisez
BEGIN TRANSACTIONetROLLBACKsi@@ERROR <> 0. - Utilisez
TRY/CATCHavecROLLBACKdans leCATCHbloc (SQL Server 2005+).
Et beaucoup adoptent l'approche selon laquelle ils devraient vérifier s'ils vont d'abord encourir la violation, car il semble plus propre de gérer le doublon vous-même que de forcer le moteur à le faire. Ma théorie est que vous devriez faire confiance mais vérifier; par exemple, considérez cette approche (principalement du pseudo-code) :
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
Nous savons que le IF NOT EXISTS check ne garantit pas que quelqu'un d'autre n'aura pas inséré la ligne au moment où nous arrivons à INSERT (sauf si nous plaçons des verrous agressifs sur la table et/ou utilisons SERIALIZABLE ), mais la vérification externe nous empêche d'essayer de commettre un échec, puis de devoir revenir en arrière. Nous restons en dehors de tout TRY/CATCH structure si nous savons déjà que le INSERT échouera, et il serait logique de supposer que - au moins dans certains cas - cela sera plus efficace que d'entrer le TRY/CATCH structure inconditionnellement. Cela n'a guère de sens dans un seul INSERT scénario, mais imaginez un cas où il se passe plus de choses dans ce TRY bloquer (et plus de violations potentielles que vous pourriez vérifier à l'avance, ce qui signifie encore plus de travail que vous pourriez autrement avoir à effectuer, puis revenir en arrière si une violation ultérieure se produisait).
Maintenant, il serait intéressant de voir ce qui se passerait si vous utilisiez un niveau d'isolation autre que celui par défaut (quelque chose que je traiterai dans un prochain article), en particulier avec la concurrence. Pour cet article, cependant, je voulais commencer lentement et tester ces aspects avec un seul utilisateur. J'ai créé une table appelée dbo.[Objects] , un tableau très simpliste :
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
Je voulais remplir cette table avec 100 000 lignes d'exemples de données. Pour rendre les valeurs de la colonne de nom uniques (puisque le PK est la contrainte que je voulais violer), j'ai créé une fonction d'assistance qui prend un certain nombre de lignes et une chaîne minimale. La chaîne minimale serait utilisée pour s'assurer que soit (a) l'ensemble a commencé au-delà de la valeur maximale dans la table des objets, soit (b) l'ensemble a commencé à la valeur minimale dans la table des objets. (Je les spécifierai manuellement pendant les tests, vérifiés simplement en inspectant les données, bien que j'aurais probablement pu intégrer cette vérification dans la fonction.)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
Ceci applique un CROSS JOIN de sys.all_objects sur lui-même, en ajoutant un row_number unique à chaque nom, de sorte que les 10 premiers résultats ressemblent à ceci :
Remplir le tableau avec 100 000 lignes était simple :
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
Maintenant, puisque nous allons insérer de nouvelles valeurs uniques dans la table, j'ai créé une procédure pour effectuer un nettoyage au début et à la fin de chaque test - en plus de supprimer toutes les nouvelles lignes que nous avons ajoutées, cela nettoiera également le cache et les tampons. Pas quelque chose que vous voulez coder dans une procédure sur votre système de production, bien sûr, mais tout à fait bien pour les tests de performances locaux.
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
J'ai également créé une table de journal pour garder une trace des heures de début et de fin de chaque test :
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
Enfin, la procédure stockée de test gère une variété de choses. Nous avons trois méthodes différentes de gestion des erreurs, comme décrit dans les puces ci-dessus :"JustInsert", "Rollback" et "TryCatch" ; nous avons également trois types d'insertion différents :(1) toutes les insertions réussissent (toutes les lignes sont uniques), (2) toutes les insertions échouent (toutes les lignes sont des doublons) et (3) la moitié des insertions réussissent (la moitié des lignes sont uniques et l'autre moitié les lignes sont des doublons). Couplé à cela, il existe deux approches différentes :vérifier la violation avant de tenter l'insertion, ou simplement continuer et laisser le moteur déterminer si elle est valide. Je pensais que cela donnerait une bonne comparaison des différentes techniques de gestion des erreurs combinées à différentes probabilités de collisions pour voir si un pourcentage de collision élevé ou faible aurait un impact significatif sur les résultats.
Pour ces tests, j'ai choisi 40 000 lignes comme nombre total de tentatives d'insertion et, dans la procédure, j'effectue une union de 20 000 lignes uniques ou non uniques avec 20 000 autres lignes uniques ou non uniques. Vous pouvez voir que j'ai codé en dur les chaînes de coupure dans la procédure ; veuillez noter que sur votre système, ces coupures se produiront presque certainement à un endroit différent.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
Nous pouvons maintenant appeler cette procédure avec divers arguments pour obtenir le comportement différent que nous recherchons, en essayant d'insérer 40 000 valeurs (et en sachant, bien sûr, combien doivent réussir ou échouer dans chaque cas). Pour chaque "méthode de gestion des erreurs" (essayez simplement l'insertion, utilisez begin tran/rollback ou try/catch) et chaque type d'insertion (tous réussis, à moitié réussis et aucun réussi), combinés avec la vérification ou non de la violation d'abord, cela nous donne 18 combinaisons :
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;
Après avoir exécuté ceci (cela prend environ 8 minutes sur mon système), nous avons quelques résultats dans notre journal. J'ai exécuté le lot entier cinq fois pour m'assurer que nous obtenions des moyennes décentes et pour lisser les anomalies. Voici les résultats :
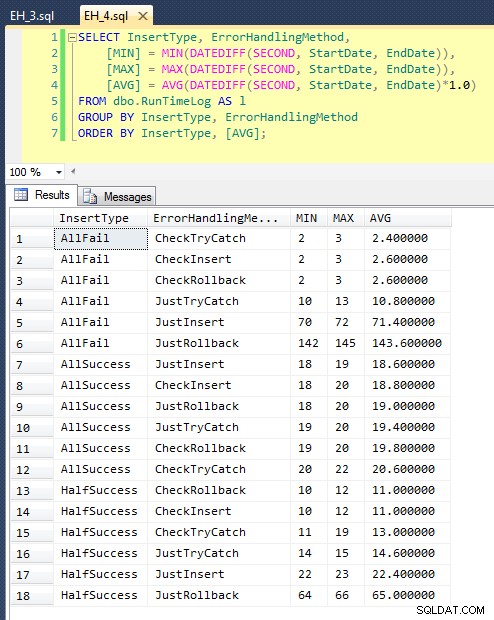
Le graphique qui trace toutes les durées à la fois montre quelques valeurs aberrantes sérieuses :
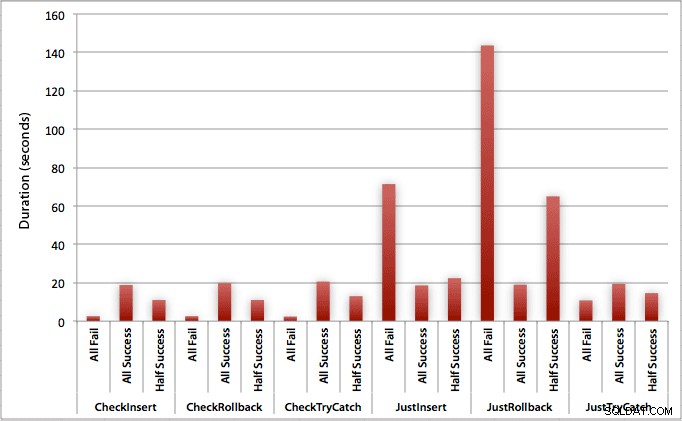
Vous pouvez voir que, dans les cas où nous nous attendons à un taux d'échec élevé (dans ce test, 100%), commencer une transaction et revenir en arrière est de loin l'approche la moins attrayante (3,59 millisecondes par tentative), tout en laissant simplement le moteur monter une erreur est environ deux fois moins grave (1,785 millisecondes par tentative). Le deuxième plus mauvais interprète était le cas où nous commençons une transaction puis l'annulons, dans un scénario où nous nous attendons à ce qu'environ la moitié des tentatives échouent (en moyenne 1,625 millisecondes par tentative). Les 9 cas sur le côté gauche du graphique, où nous vérifions d'abord la violation, ne se sont pas aventurés au-dessus de 0,515 millisecondes par tentative.
Cela dit, les graphiques individuels pour chaque scénario (% élevé de réussite, % élevé d'échec et 50-50) montrent vraiment l'impact de chaque méthode.
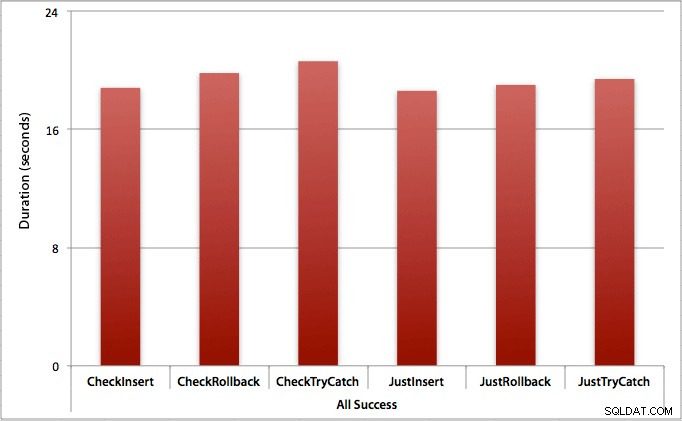
Où toutes les insertions réussissent
Dans ce cas, nous constatons que la surcharge liée à la vérification préalable de la violation est négligeable, avec une différence moyenne de 0,7 seconde sur l'ensemble du lot (ou 125 microsecondes par tentative d'insertion) :
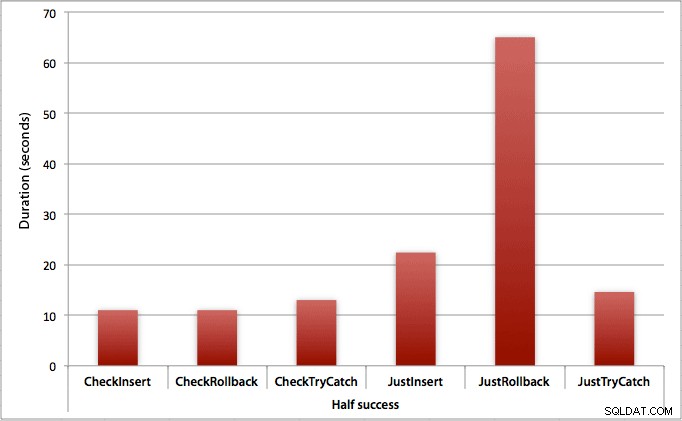
Où seulement la moitié des insertions réussissent
Lorsque la moitié des insertions échouent, nous constatons un grand saut dans la durée des méthodes d'insertion/annulation. Le scénario dans lequel nous démarrons une transaction et l'annulons est environ 6 fois plus lent sur le lot par rapport à la première vérification (1,625 millisecondes par tentative contre 0,275 millisecondes par tentative). Même la méthode TRY/CATCH est 11 % plus rapide lorsque nous vérifions en premier :
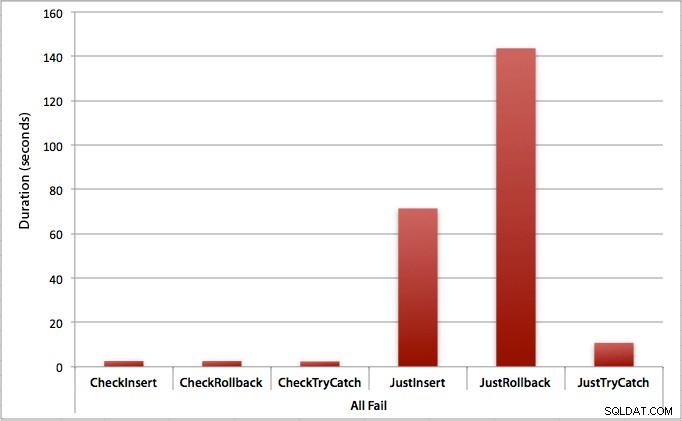
Où toutes les insertions échouent
Comme vous pouvez vous y attendre, cela montre l'impact le plus prononcé de la gestion des erreurs et les avantages les plus évidents de la vérification en premier. La méthode de restauration est presque 70 fois plus lente dans ce cas lorsque nous ne vérifions pas par rapport à lorsque nous le faisons (3,59 ms par tentative contre 0,065 ms par tentative) :
Qu'est-ce que cela nous dit? Si nous pensons que nous allons avoir un taux d'échec élevé, ou si nous n'avons aucune idée de ce que sera notre taux d'échec potentiel, alors vérifier d'abord pour éviter les violations dans le moteur vaudra énormément la peine. Même dans le cas où nous avons une insertion réussie à chaque fois, le coût de la première vérification est marginal et facilement justifié par le coût potentiel des erreurs de traitement ultérieures (à moins que votre taux d'échec anticipé ne soit exactement de 0 %).
Donc, pour l'instant, je pense que je m'en tiendrai à ma théorie selon laquelle, dans des cas simples, il est logique de vérifier une violation potentielle avant de dire à SQL Server d'aller de l'avant et d'insérer quand même. Dans un prochain article, j'examinerai l'impact sur les performances de divers niveaux d'isolement, de la simultanéité et peut-être même de quelques autres techniques de gestion des erreurs.
[En passant, j'ai écrit une version condensée de cet article en tant que conseil pour mssqltips.com en février.]