La notion de bon ou de mauvais design est relative. Dans le même temps, il existe des normes de programmation qui, dans la plupart des cas, garantissent l'efficacité, la maintenabilité et la testabilité. Par exemple, dans les langages orientés objet, il s'agit de l'utilisation de l'encapsulation, de l'héritage et du polymorphisme. Il existe un ensemble de modèles de conception qui, dans un certain nombre de cas, ont un effet positif ou négatif sur la conception de l'application en fonction de la situation. D'autre part, il y a des contraires, ce qui conduit parfois au problème de conception.
Cette conception comporte généralement les indicateurs suivants (un ou plusieurs à la fois) :
- Rigidité (il est difficile de modifier le code, car un simple changement affecte de nombreux endroits );
- Immobilité (il est compliqué de découper le code en modules utilisables dans d'autres programmes) ;
- Viscosité (il est assez difficile de développer ou de tester le code );
- Complexité inutile (il y a une fonctionnalité inutilisée dans le code) ;
- Répétitions inutiles (Copier/Coller) ;
- Mauvaise lisibilité (il est difficile de comprendre à quoi sert le code et de le maintenir) ;
- Fragilité (il est facile de casser la fonctionnalité même avec de petits changements).
Vous devez être en mesure de comprendre et de distinguer ces fonctionnalités afin d'éviter un problème de conception ou de prévoir les conséquences possibles de son utilisation. Ces indicateurs sont décrits dans le livre « Agile Principles, Patterns, And Practices in C# » de Robert Martin. Cependant, il y a une brève description et aucun exemple de code dans cet article ainsi que dans d'autres articles de revue.
Nous allons éliminer cet inconvénient en nous attardant sur chaque fonctionnalité.
Rigidité
Comme il a été mentionné, un code rigide est difficile à modifier, même les plus petites choses. Cela peut ne pas être un problème si le code n'est pas modifié souvent ou pas du tout. Ainsi, le code s'avère être assez bon. Cependant, s'il est nécessaire de modifier le code et difficile à faire, cela devient un problème, même si cela fonctionne.
L'un des cas de rigidité populaires consiste à spécifier explicitement les types de classe au lieu d'utiliser des abstractions (interfaces, classes de base, etc.). Ci-dessous, vous pouvez trouver un exemple du code :
class A
{
B _b;
public A()
{
_b = new B();
}
public void Foo()
{
// Do some custom logic.
_b.DoSomething();
// Do some custom logic.
}
}
class B
{
public void DoSomething()
{
// Do something
}
} Ici, la classe A dépend beaucoup de la classe B. Ainsi, si à l'avenir vous avez besoin d'utiliser une autre classe à la place de la classe B, cela nécessitera de changer la classe A et conduira à la retester. De plus, si la classe B affecte d'autres classes, la situation deviendra beaucoup plus compliquée.
La solution de contournement est une abstraction qui consiste à introduire l'interface IComponent via le constructeur de la classe A. Dans ce cas, elle ne dépendra plus de la classe particulière  et ne dépendra que de l'interface IComponent. La classe В doit à son tour implémenter l'interface IComponent.
interface IComponent
{
void DoSomething();
}
class A
{
IComponent _component;
public A(IComponent component)
{
_component = component;
}
void Foo()
{
// Do some custom logic.
_component.DoSomething();
// Do some custom logic.
}
}
class B : IComponent
{
void DoSomething()
{
// Do something
}
} Donnons un exemple précis. Supposons qu'il existe un ensemble de classes qui enregistrent les informations - ProductManager et Consumer. Leur tâche est de stocker un produit dans la base de données et de le commander en conséquence. Les deux classes consignent les événements pertinents. Imaginez qu'au début, il y avait un journal dans un fichier. Pour ce faire, la classe FileLogger a été utilisée. De plus, les classes étaient situées dans différents modules (assemblages).
// Module 1 (Client)
static void Main()
{
var product = new Product("milk");
var productManager = new ProductManager();
productManager.AddProduct(product);
var consumer = new Consumer();
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
public class ProductManager
{
private readonly FileLogger _logger = new FileLogger();
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly FileLogger _logger = new FileLogger();
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (Logger implementation)
public class FileLogger
{
const string FileName = "log.txt";
public void Log(string message)
{
// Write the message to the file.
}
} Si au début, il suffisait d'utiliser uniquement le fichier, puis qu'il devient nécessaire de se connecter à d'autres référentiels, tels qu'une base de données ou un service de collecte et de stockage de données basé sur le cloud, nous devrons alors modifier toutes les classes dans la logique métier. module (Module 2) qui utilise FileLogger. Après tout, cela peut s'avérer difficile. Pour résoudre ce problème, nous pouvons introduire une interface abstraite pour travailler avec l'enregistreur, comme indiqué ci-dessous.
// Module 1 (Client)
static void Main()
{
var logger = new FileLogger();
var product = new Product("milk");
var productManager = new ProductManager(logger);
productManager.AddProduct(product);
var consumer = new Consumer(logger);
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
class ProductManager
{
private readonly ILogger _logger;
public ProductManager(ILogger logger)
{
_logger = logger;
}
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly ILogger _logger;
public Consumer(ILogger logger)
{
_logger = logger;
}
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (interfaces)
public interface ILogger
{
void Log(string message);
}
// Module 4 (Logger implementation)
public class FileLogger : ILogger
{
const string FileName = "log.txt";
public virtual void Log(string message)
{
// Write the message to the file.
}
} Dans ce cas, lors d'un changement de type de logger, il suffit de modifier le code client (Main), qui initialise le logger et l'ajoute au constructeur de ProductManager et Consumer. Ainsi, nous avons fermé les classes de logique métier à partir de la modification du type de logger au besoin.
En plus des liens directs vers les classes utilisées, nous pouvons surveiller la rigidité dans d'autres variantes qui peuvent entraîner des difficultés lors de la modification du code. Il peut y en avoir un ensemble infini. Cependant, nous essaierons de donner un autre exemple. Supposons qu'il existe un code qui affiche la zone d'un motif géométrique sur la console.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[] { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
private static double GetShapeArea(Shape shape)
{
if (shape is Rectangle)
{
return ((Rectangle)shape).W * ((Rectangle)shape).H;
}
if (shape is Circle)
{
return 2 * Math.PI * ((Circle)shape).R * ((Circle)shape).R;
}
throw new InvalidOperationException("Not supported shape");
}
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
if (shape is Rectangle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Rectangle's area is {area}");
}
if (shape is Circle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Circle's area is {area}");
}
}
}
}
public class Shape
{ }
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
}
public class Circle : Shape
{
public double R { get; set; }
} Comme vous pouvez le voir, lors de l'ajout d'un nouveau motif, nous devrons changer les méthodes de la classe ShapeHelper. L'une des options consiste à passer l'algorithme de rendu dans les classes de motifs géométriques (Rectangle et Cercle), comme indiqué ci-dessous. De cette façon, nous isolerons la logique pertinente dans les classes correspondantes réduisant ainsi la responsabilité de la classe ShapeHelper avant d'afficher les informations sur la console.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[]() { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
shape.Report();
}
}
}
public abstract class Shape
{
public abstract void Report();
}
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
public override void Report()
{
double area = W * H;
Console.WriteLine($"Rectangle's area is {area}");
}
}
public class Circle : Shape
{
public double R { get; set; }
public override void Report()
{
double area = 2 * Math.PI * R * R;
Console.WriteLine($"Circle's area is {area}");
}
} En conséquence, nous avons en fait fermé la classe ShapeHelper pour les modifications qui ajoutent de nouveaux types de modèles en utilisant l'héritage et le polymorphisme.
Immobilité
Nous pouvons surveiller l'immobilité lors de la division du code en modules réutilisables. En conséquence, le projet peut cesser de se développer et d'être compétitif.
À titre d'exemple, considérons un programme de bureau dont le code entier est implémenté dans le fichier d'application exécutable (.exe) et a été conçu de manière à ce que la logique métier ne soit pas construite dans des modules ou des classes séparés. Plus tard, le développeur a dû faire face aux exigences commerciales suivantes :
- Modifier l'interface utilisateur en la transformant en application Web ;
- Pour publier les fonctionnalités du programme sous la forme d'un ensemble de services Web disponibles pour les clients tiers à utiliser dans leurs propres applications.
Dans ce cas, ces exigences sont difficiles à respecter, car tout le code se trouve dans le module exécutable.
L'image ci-dessous montre un exemple d'une conception immobile contrairement à celle qui n'a pas cet indicateur. Ils sont séparés par une ligne pointillée. Comme vous pouvez le voir, l'allocation du code sur des modules réutilisables (Logic), ainsi que la publication de la fonctionnalité au niveau des services Web, permettent de l'utiliser dans diverses applications clientes (App), ce qui est un avantage indéniable.
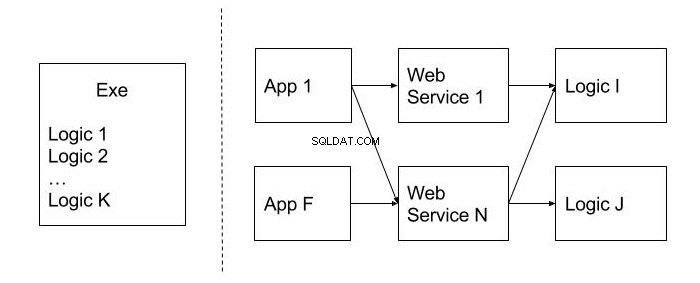
L'immobilité peut aussi être appelée une conception monolithique. Il est difficile de le diviser en unités plus petites et utiles du code. Comment pouvons-nous éluder ce problème? Au stade de la conception, il est préférable de réfléchir à la probabilité d'utiliser telle ou telle fonctionnalité dans d'autres systèmes. Il est préférable de placer le code qui devrait être réutilisé dans des modules et des classes séparés.
Viscosité
Il existe deux types :
- Viscosité de développement
- Viscosité de l'environnement
Nous pouvons voir la viscosité du développement tout en essayant de suivre la conception de l'application sélectionnée. Cela peut arriver lorsqu'un programmeur doit répondre à trop d'exigences alors qu'il existe un moyen de développement plus simple. De plus, la viscosité du développement peut être observée lorsque le processus d'assemblage, de déploiement et de test n'est pas efficace.
Comme exemple simple, nous pouvons considérer le travail avec des constantes qui doivent être placées (By Design) dans un module séparé (Module 1) pour être utilisées par d'autres composants (Module 2 et Module 3).
// Module 1 (Constants)
static class Constants
{
public const decimal MaxSalary = 100M;
public const int MaxNumberOfProducts = 100;
}
// Finance Module
#using Module1
static class FinanceHelper
{
public static bool ApproveSalary(decimal salary)
{
return salary <= Constants.MaxSalary;
}
}
// Marketing Module
#using Module1
class ProductManager
{
public void MakeOrder()
{
int productsNumber = 0;
while(productsNumber++ <= Constants.MaxNumberOfProducts)
{
// Purchase some product
}
}
} Si pour une raison quelconque le processus d'assemblage prend beaucoup de temps, il sera difficile pour les développeurs d'attendre qu'il se termine. De plus, il convient de noter que le module constant contient des entités mixtes qui appartiennent à différentes parties de la logique métier (modules financier et marketing). Ainsi, le module constant peut être modifié assez souvent pour des raisons indépendantes les unes des autres, ce qui peut entraîner des problèmes supplémentaires tels que la synchronisation des modifications.
Tout cela ralentit le processus de développement et peut stresser les programmeurs. Les variantes de la conception moins visqueuse seraient soit de créer des modules constants séparés - par un pour le module correspondant de logique métier - soit de passer les constantes au bon endroit sans prendre un module séparé pour elles.
Un exemple de la viscosité de l'environnement peut être le développement et le test de l'application sur la machine virtuelle cliente distante. Parfois, ce flux de travail devient insupportable en raison d'une connexion Internet lente, de sorte que le développeur peut systématiquement ignorer les tests d'intégration du code écrit, ce qui peut éventuellement entraîner des bogues côté client lors de l'utilisation de cette fonctionnalité.
Complexité inutile
Dans ce cas, la conception a en fait des fonctionnalités inutilisées. Ce fait peut compliquer le support et la maintenance du programme, ainsi qu'augmenter le temps de développement et de test. Par exemple, considérez le programme qui nécessite la lecture de certaines données de la base de données. Pour ce faire, le composant DataManager a été créé, qui est utilisé dans un autre composant.
class DataManager
{
object[] GetData()
{
// Retrieve and return data
}
} Si le développeur ajoute une nouvelle méthode à DataManager pour écrire des données dans la base de données (WriteData), qui ne sera probablement pas utilisée à l'avenir, cela représentera également une complexité inutile.
Un autre exemple est une interface à toutes fins. Par exemple, nous allons considérer une interface avec la seule méthode Process qui accepte un objet de type string.
interface IProcessor
{
void Process(string message);
} Si la tâche consistait à traiter un certain type de message avec une structure bien définie, il serait alors plus facile de créer une interface strictement typée, plutôt que de demander aux développeurs de désérialiser cette chaîne dans un type de message particulier à chaque fois.
L'utilisation excessive de modèles de conception dans des cas où cela n'est pas du tout nécessaire peut également conduire à une conception de viscosité.
Pourquoi perdre votre temps à écrire un code potentiellement inutilisé ? Parfois, l'assurance qualité consiste à tester ce code, car il est en fait publié et ouvert à l'utilisation par des clients tiers. Cela retarde également le temps de sortie. Inclure une fonctionnalité pour le futur n'a de valeur que si son bénéfice potentiel dépasse les coûts de son développement et de ses tests.
Répétition inutile
Peut-être que la plupart des développeurs ont rencontré ou rencontreront cette fonctionnalité, qui consiste à copier plusieurs fois la même logique ou le même code. La principale menace est la vulnérabilité de ce code lors de sa modification - en réparant quelque chose à un endroit, vous risquez d'oublier de le faire à un autre. De plus, il faut plus de temps pour apporter des modifications par rapport à la situation où le code ne contient pas cette fonctionnalité.
Les répétitions inutiles peuvent être dues à la négligence des développeurs, ainsi qu'à la rigidité/fragilité de la conception alors qu'il est beaucoup plus difficile et risqué de ne pas répéter le code plutôt que de le faire. Cependant, dans tous les cas, la répétabilité n'est pas une bonne idée, et il est nécessaire d'améliorer constamment le code, en passant des parties réutilisables aux méthodes et classes communes.
Mauvaise lisibilité
Vous pouvez surveiller cette fonctionnalité lorsqu'il est difficile de lire un code et de comprendre pourquoi il a été créé. Les raisons d'une mauvaise lisibilité peuvent être le non-respect des exigences d'exécution du code (syntaxe, variables, classes), une logique d'implémentation compliquée, etc.
Vous trouverez ci-dessous l'exemple du code difficile à lire, qui implémente la méthode avec la variable booléenne.
void Process_true_false(string trueorfalsevalue)
{
if (trueorfalsevalue.ToString().Length == 4)
{
// That means trueorfalsevalue is probably "true". Do something here.
}
else if (trueorfalsevalue.ToString().Length == 5)
{
// That means trueorfalsevalue is probably "false". Do something here.
}
else
{
throw new Exception("not true of false. that's not nice. return.")
}
} Ici, nous pouvons souligner plusieurs problèmes. Premièrement, les noms de méthodes et de variables ne sont pas conformes aux conventions généralement acceptées. Deuxièmement, la mise en œuvre de la méthode n'est pas la meilleure.
Peut-être vaut-il la peine de prendre une valeur booléenne plutôt qu'une chaîne. Cependant, il est préférable de le convertir en une valeur booléenne au début de la méthode, plutôt que d'utiliser la méthode de détermination de la longueur de la chaîne.
Troisièmement, le texte de l'exception ne correspond pas au style officiel. En lisant de tels textes, on peut avoir l'impression que le code est créé par un amateur (pourtant, il peut y avoir un point en litige). La méthode pourrait être réécrite comme suit si elle prend une valeur booléenne :
public void Process(bool value)
{
if (value)
{
// Do something.
}
else
{
// Do something.
}
} Voici un autre exemple de refactoring si vous avez encore besoin de prendre une chaîne :
public void Process(string value)
{
bool bValue = false;
if (!bool.TryParse(value, out bValue))
{
throw new ArgumentException($"The {value} is not boolean");
}
if (bValue)
{
// Do something.
}
else
{
// Do something.
}
} Il est recommandé d'effectuer une refactorisation avec le code difficile à lire, par exemple, lorsque sa maintenance et son clonage entraînent de multiples bugs.
Fragilité
La fragilité d'un programme signifie qu'il peut facilement planter lorsqu'il est modifié. Il existe deux types de plantages :les erreurs de compilation et les erreurs d'exécution. Les premiers peuvent être un revers de rigidité. Ces derniers sont les plus dangereux car ils se produisent du côté client. Ils sont donc un indicateur de la fragilité.
Pas de doute, l'indicateur est relatif. Quelqu'un corrige le code très soigneusement et le risque de plantage est assez faible, tandis que d'autres le font à la hâte et avec négligence. Néanmoins, un code différent avec les mêmes utilisateurs peut entraîner un nombre différent d'erreurs. Probablement, on peut dire que plus il est difficile de comprendre le code et de s'appuyer sur le temps d'exécution du programme, plutôt que sur l'étape de compilation, plus le code est fragile.
De plus, la fonctionnalité qui ne va pas être modifiée plante souvent. Il peut souffrir du fort couplage de la logique des différents composants.
Prenons l'exemple particulier. Ici, la logique d'autorisation de l'utilisateur avec un certain rôle (défini comme paramètre roulé) pour accéder à une ressource particulière (définie comme resourceUri) se trouve dans la méthode statique.
static void Main()
{
if (Helper.Authorize(1, "/pictures"))
{
Console.WriteLine("Authorized");
}
}
class Helper
{
public static bool Authorize(int roleId, string resourceUri)
{
if (roleId == 1 || roleId == 10)
{
if (resourceUri == "/pictures")
{
return true;
}
}
if (roleId == 1 || roleId == 2 && resourceUri == "/admin")
{
return true;
}
return false;
}
} Comme vous pouvez le voir, la logique est compliquée. Il est évident que l'ajout de nouveaux rôles et ressources le brisera facilement. Par conséquent, un certain rôle peut obtenir ou perdre l'accès à une ressource. La création de la classe Resource qui stocke en interne l'identifiant de la ressource et la liste des rôles pris en charge, comme indiqué ci-dessous, réduirait la fragilité.
static void Main()
{
var picturesResource = new Resource() { Uri = "/pictures" };
picturesResource.AddRole(1);
if (picturesResource.IsAvailable(1))
{
Console.WriteLine("Authorized");
}
}
class Resource
{
private List<int> _roles = new List<int>();
public string Uri { get; set; }
public void AddRole(int roleId)
{
_roles.Add(roleId);
}
public void RemoveRole(int roleId)
{
_roles.Remove(roleId);
}
public bool IsAvailable(int roleId)
{
return _roles.Contains(roleId);
}
} Dans ce cas, pour ajouter de nouvelles ressources et de nouveaux rôles, il n'est pas du tout nécessaire de modifier le code de la logique d'autorisation, c'est-à-dire qu'il n'y a en fait rien à casser.
Qu'est-ce qui peut aider à détecter les erreurs d'exécution ? La réponse est les tests manuels, automatiques et unitaires. Mieux le processus de test est organisé, plus il est probable que le code fragile se produise du côté client.
Souvent, la fragilité est le revers d'autres identifiants de mauvaise conception tels que la rigidité, la mauvaise lisibilité et les répétitions inutiles.
Conclusion
Nous avons essayé d'esquisser et de décrire les principaux identifiants d'une mauvaise conception. Certains d'entre eux sont interdépendants. Vous devez comprendre que la question de la conception n'entraîne pas toujours inévitablement des difficultés. Cela indique seulement qu'ils peuvent se produire. Moins ces identifiants sont surveillés, plus cette probabilité est faible.