Dans cet article de blog, nous analyserons 6 scénarios de défaillance différents dans les systèmes de base de données de production, allant des problèmes de serveur unique aux plans de basculement multi-centres de données. Nous vous guiderons à travers les procédures de récupération et de basculement pour le scénario respectif. J'espère que cela vous permettra de bien comprendre les risques auxquels vous pourriez être confronté et les éléments à prendre en compte lors de la conception de votre infrastructure.
Schéma de base de données corrompu
Commençons par l'installation d'un seul nœud - une configuration de base de données sous la forme la plus simple. Facile à mettre en œuvre, au moindre coût. Dans ce scénario, vous exécutez plusieurs applications sur le serveur unique où chacun des schémas de base de données appartient à une application différente. L'approche de récupération d'un seul schéma dépend de plusieurs facteurs.
- Ai-je une sauvegarde ?
- Ai-je une sauvegarde et à quelle vitesse puis-je la restaurer ?
- Quel type de moteur de stockage est utilisé ?
- Ai-je une sauvegarde compatible PITR (récupération ponctuelle) ?
La corruption des données peut être identifiée par mysqlcheck.
mysqlcheck -uroot -p <DATABASE>Remplacez DATABASE par le nom de la base de données et remplacez TABLE par le nom de la table que vous souhaitez vérifier :
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck vérifie la base de données et les tables spécifiées. Si une table passe la vérification, mysqlcheck affiche OK pour la table. Dans l'exemple ci-dessous, nous pouvons voir que le tableau salaires nécessite une récupération.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKPour une installation à nœud unique sans serveurs DR supplémentaires, l'approche principale consiste à restaurer les données à partir de la sauvegarde. Mais ce n'est pas la seule chose que vous devez considérer. Avoir plusieurs schémas de base de données sous la même instance pose un problème lorsque vous devez arrêter votre serveur pour restaurer les données. Une autre question est de savoir si vous pouvez vous permettre de restaurer toutes vos bases de données jusqu'à la dernière sauvegarde. Dans la plupart des cas, cela ne serait pas possible.
Il y a quelques exceptions ici. Il est possible de restaurer une seule table ou base de données à partir de la dernière sauvegarde lorsque la récupération à un instant donné n'est pas nécessaire. Un tel processus est plus compliqué. Si vous avez mysqldump, vous pouvez en extraire votre base de données. Si vous exécutez des sauvegardes binaires avec xtradbackup ou mariabackup et que vous avez activé la table par fichier, alors c'est possible.
Voici comment vérifier si vous avez activé une table par option de fichier.
mysql> SET GLOBAL innodb_file_per_table=1; Avec innodb_file_per_table activé, vous pouvez stocker des tables InnoDB dans un fichier .ibd tbl_name. Contrairement au moteur de stockage MyISAM, avec ses fichiers tbl_name .MYD et tbl_name .MYI séparés pour les index et les données, InnoDB stocke les données et les index ensemble dans un seul fichier .ibd. Pour vérifier votre moteur de stockage, vous devez exécuter :
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';ou directement depuis la console :
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: Pour restaurer des tables à partir de xtradbackup, vous devez passer par un processus d'exportation. La sauvegarde doit être préparée avant de pouvoir être restaurée. L'exportation se fait au stade de la préparation. Une fois qu'une sauvegarde complète est créée, exécutez la procédure de préparation standard avec le drapeau supplémentaire --export :
innobackupex --apply-log --export /u01/backupCela créera des fichiers d'exportation supplémentaires que vous utiliserez plus tard dans la phase d'importation. Pour importer une table sur un autre serveur, créez d'abord une nouvelle table avec la même structure que celle qui sera importée sur ce serveur :
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;supprimer le tablespace :
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Copiez ensuite les fichiers mytable.ibd et mytable.exp dans le répertoire d'accueil de la base de données et importez son tablespace :
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Cependant, pour le faire de manière plus contrôlée, la recommandation serait de restaurer une sauvegarde de base de données dans une autre instance/serveur et de copier ce qui est nécessaire sur le système principal. Pour ce faire, vous devez exécuter l'installation de l'instance mysql. Cela pourrait être fait sur la même machine - mais nécessite plus d'efforts pour configurer de manière à ce que les deux instances puissent s'exécuter sur la même machine - par exemple, cela nécessiterait des paramètres de communication différents.
Vous pouvez combiner à la fois la restauration des tâches et l'installation à l'aide de ClusterControl.
ClusterControl vous guidera à travers les sauvegardes disponibles sur site ou dans le cloud, vous permettra de choisir l'heure exacte d'une restauration ou la position précise du journal, et d'installer une nouvelle instance de base de données si nécessaire.
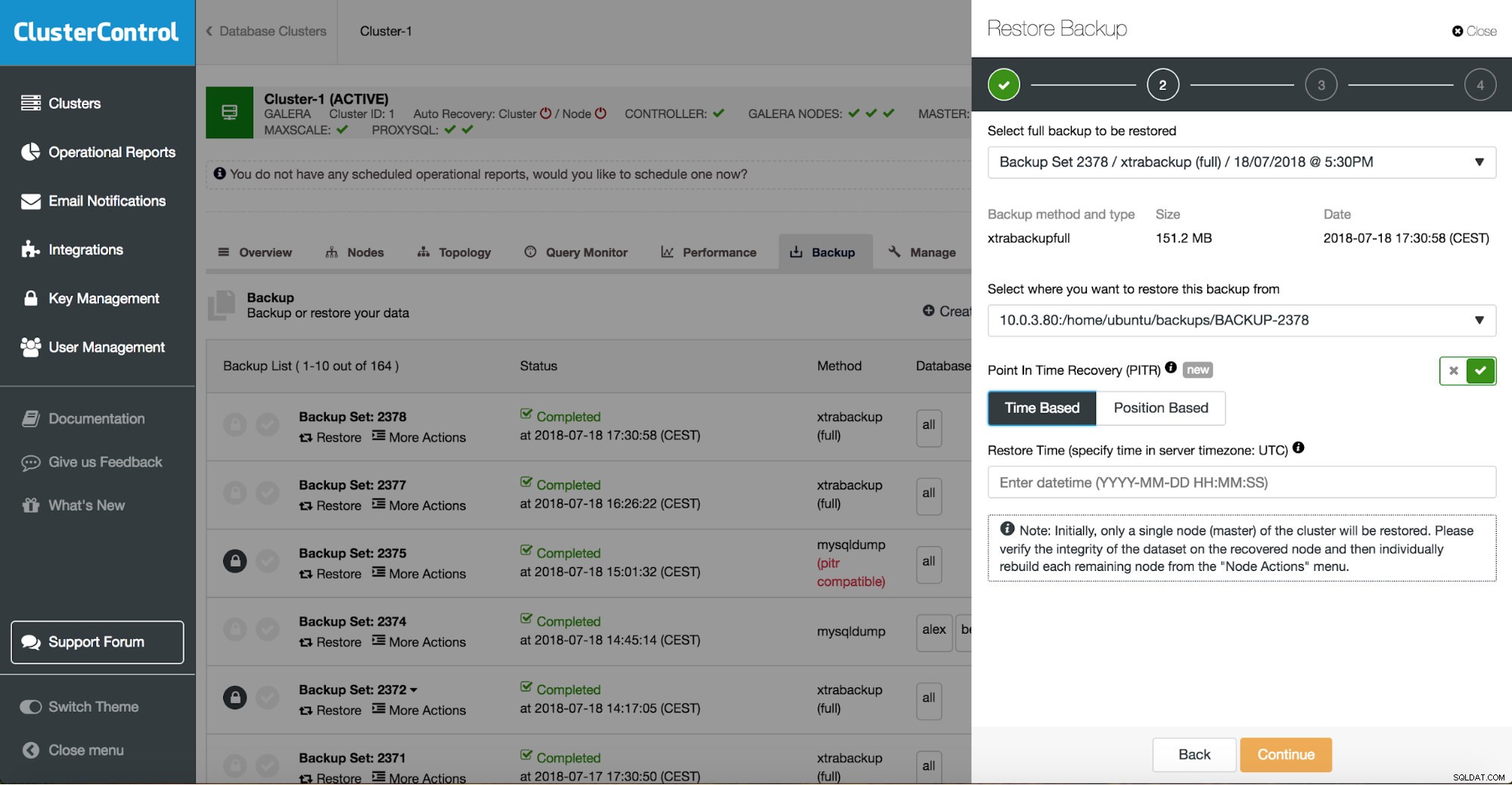 Récupération ponctuelle de ClusterControl
Récupération ponctuelle de ClusterControl 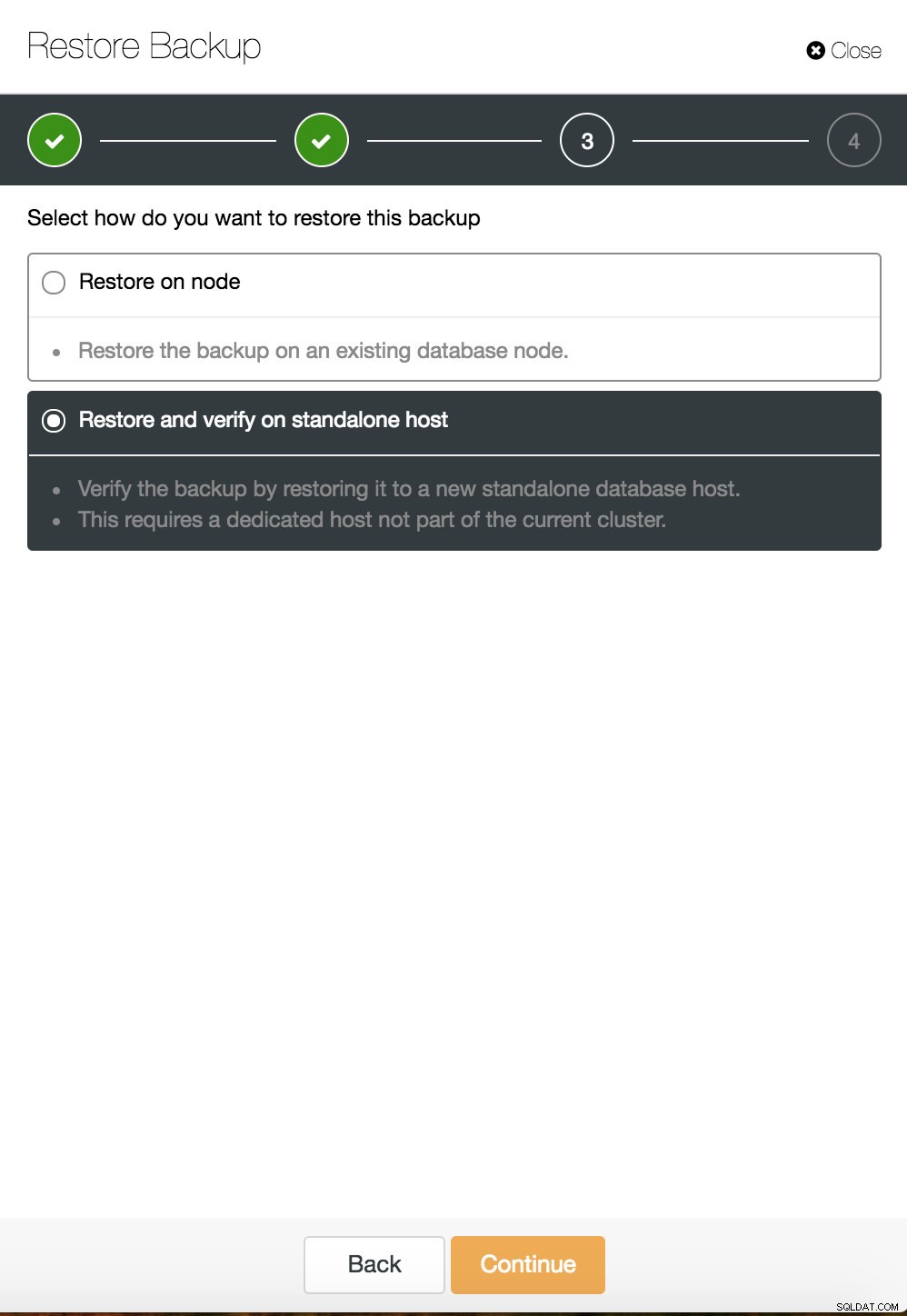 Restauration et vérification de ClusterControl sur un hôte autonome
Restauration et vérification de ClusterControl sur un hôte autonome 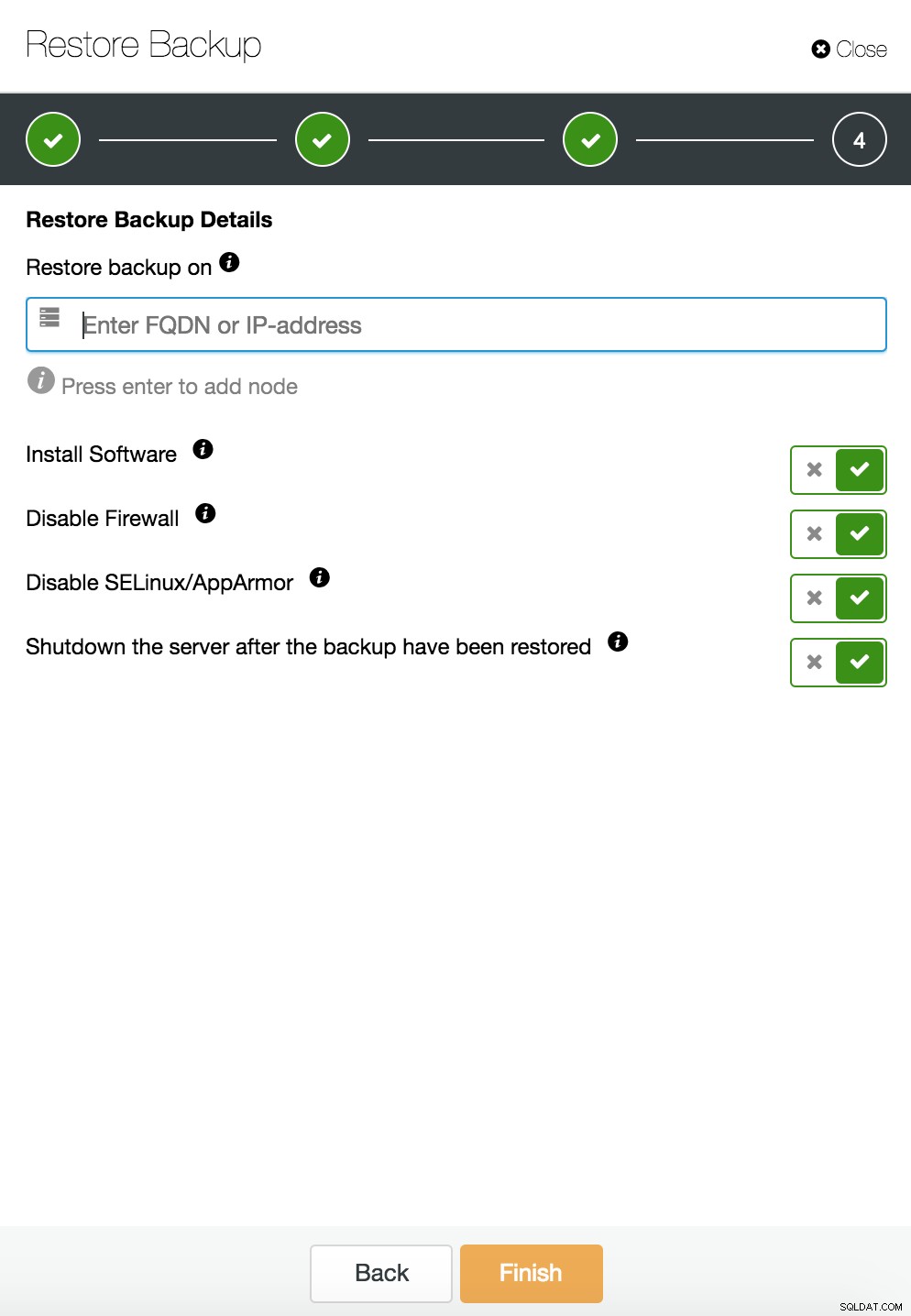 Restauration et vérification de CusterControl sur un hôte autonome. Possibilités d'installation.
Restauration et vérification de CusterControl sur un hôte autonome. Possibilités d'installation. Vous pouvez trouver plus d'informations sur la récupération de données dans le blog Ma base de données MySQL est corrompue... Que dois-je faire maintenant ?
Instance de base de données corrompue sur le serveur dédié
Les défauts de la plate-forme sous-jacente sont souvent la cause de la corruption de la base de données. Votre instance MySQL s'appuie sur un certain nombre d'éléments pour stocker et récupérer des données :sous-système de disque, contrôleurs, canaux de communication, pilotes et micrologiciels. Un crash peut affecter des parties de vos données, des binaires mysql ou même des fichiers de sauvegarde que vous stockez sur le système. Pour séparer différentes applications, vous pouvez les placer sur des serveurs dédiés.
Différents schémas d'application sur des systèmes distincts sont une bonne idée si vous pouvez vous le permettre. On peut dire qu'il s'agit d'un gaspillage de ressources, mais il est possible que l'impact commercial soit moindre si une seule d'entre elles tombe en panne. Mais même dans ce cas, vous devez protéger votre base de données contre la perte de données. Stocker la sauvegarde sur le même serveur n'est pas une mauvaise idée tant que vous avez une copie ailleurs. De nos jours, le stockage dans le cloud est une excellente alternative à la sauvegarde sur bande.
ClusterControl vous permet de conserver une copie de votre sauvegarde dans le cloud. Il prend en charge le téléchargement vers les 3 principaux fournisseurs de cloud - Amazon AWS, Google Cloud et Microsoft Azure.
Lorsque vous avez restauré votre sauvegarde complète, vous souhaiterez peut-être la restaurer à un certain moment. La récupération ponctuelle mettra le serveur à jour à une heure plus récente que celle où la sauvegarde complète a été effectuée. Pour ce faire, vous devez activer vos journaux binaires. Vous pouvez vérifier les journaux binaires disponibles avec :
mysql> SHOW BINARY LOGS;Et le fichier journal actuel avec :
SHOW MASTER STATUS;Ensuite, vous pouvez capturer des données incrémentielles en transmettant des journaux binaires dans un fichier sql. Les opérations manquantes peuvent alors être ré-exécutées.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outLa même chose peut être faite dans ClusterControl.
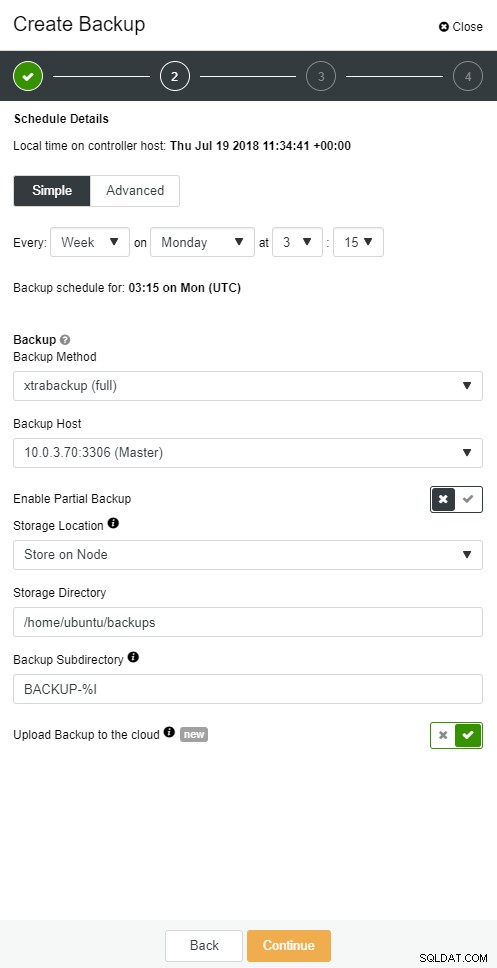 Sauvegarde cloud ClusterControl
Sauvegarde cloud ClusterControl 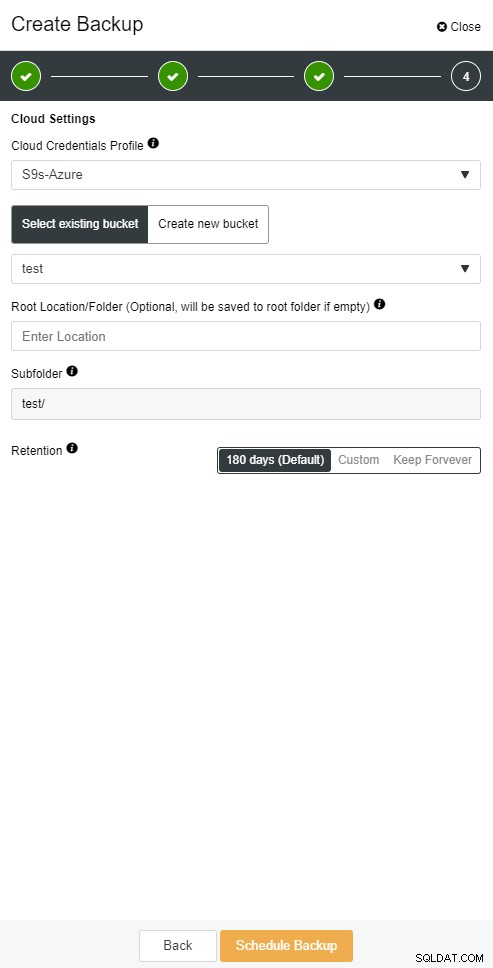 Sauvegarde cloud ClusterControl
Sauvegarde cloud ClusterControl L'esclave de la base de données tombe en panne
Ok, vous avez donc votre base de données en cours d'exécution sur un serveur dédié. Vous avez créé une planification de sauvegarde sophistiquée avec une combinaison de sauvegardes complètes et incrémentielles, les avez téléchargées sur le cloud et stocké la dernière sauvegarde sur des disques locaux pour une récupération rapide. Vous avez différentes politiques de conservation des sauvegardes :plus courtes pour les sauvegardes stockées sur des pilotes de disque locaux et étendues pour vos sauvegardes dans le cloud.
Il semble que vous soyez bien préparé pour un scénario catastrophe. Mais en ce qui concerne le temps de restauration, il se peut qu'il ne réponde pas aux besoins de votre entreprise.
Vous avez besoin d'une fonction de basculement rapide. Un serveur qui sera opérationnel et qui appliquera les journaux binaires du maître où les écritures se produisent. La réplication maître/esclave ouvre un nouveau chapitre dans le scénario de basculement. C'est une méthode rapide pour redonner vie à votre application si votre master tombe en panne.
Mais il y a peu de choses à considérer dans le scénario de basculement. L'une consiste à configurer un esclave à réplication retardée, afin que vous puissiez réagir aux commandes Fat Finger qui ont été déclenchées sur le serveur maître. Un serveur esclave peut être en retard sur le maître d'au moins un laps de temps spécifié. Le délai par défaut est de 0 seconde. Utilisez l'option MASTER_DELAY pour CHANGE MASTER TO pour définir le délai sur N secondes :
CHANGE MASTER TO MASTER_DELAY = N;La deuxième consiste à activer le basculement automatisé. Il existe de nombreuses solutions de basculement automatisé sur le marché. Vous pouvez configurer un basculement automatique avec des outils de ligne de commande tels que MHA, MRM, mysqlfailover ou GUI Orchestrator et ClusterControl. Lorsqu'il est correctement configuré, il peut réduire considérablement votre panne.
ClusterControl prend en charge le basculement automatisé pour les réplications MySQL, PostgreSQL et MongoDB ainsi que les solutions de cluster multi-maîtres Galera et NDB.
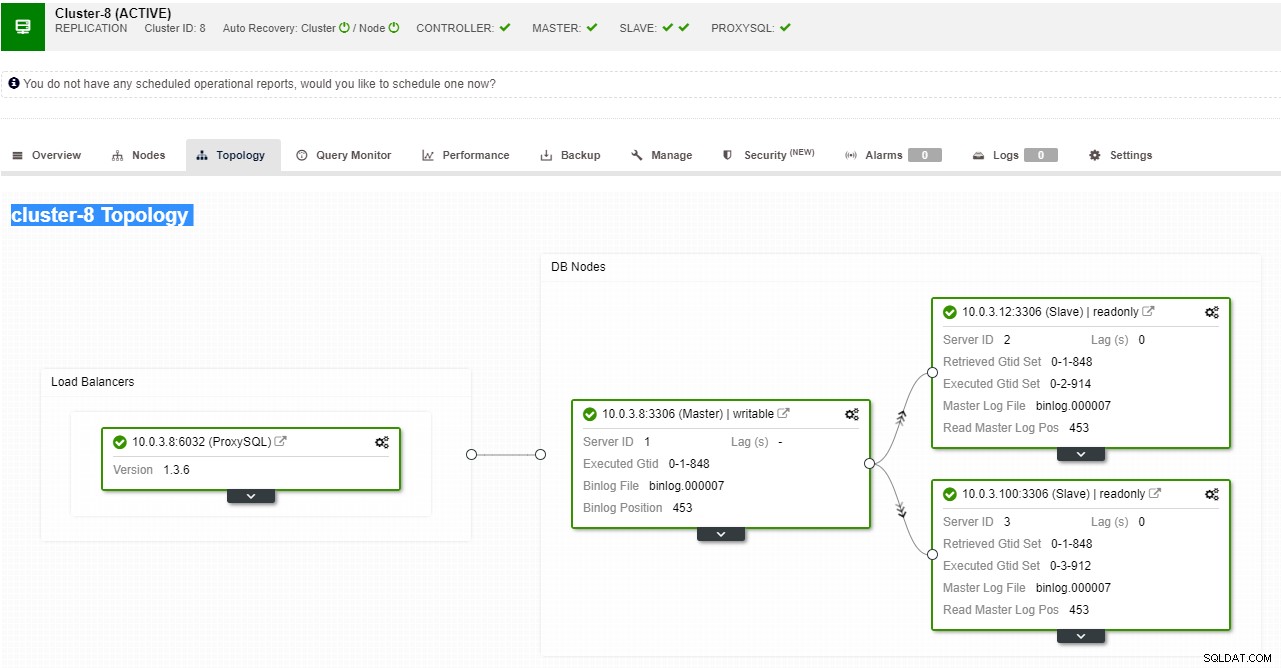 Vue de topologie de réplication ClusterControl
Vue de topologie de réplication ClusterControl Lorsqu'un nœud esclave tombe en panne et que le serveur est très en retard, vous pouvez reconstruire votre serveur esclave. Le processus de reconstruction de l'esclave est similaire à la restauration à partir d'une sauvegarde.
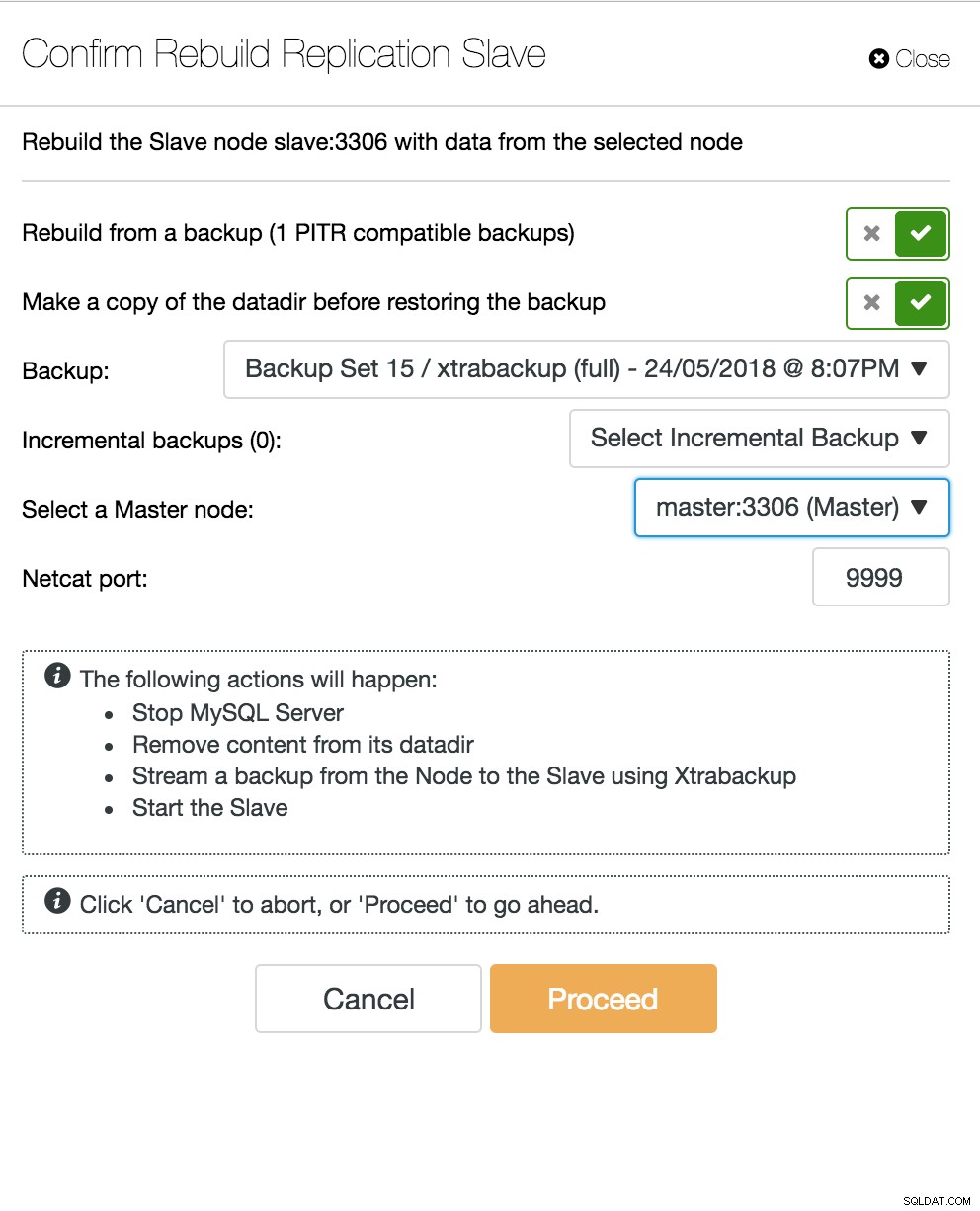 ClusterControl reconstruit l'esclave
ClusterControl reconstruit l'esclave Le serveur multi-maître de la base de données tombe en panne
Maintenant, lorsque vous avez un serveur esclave agissant comme un nœud DR et que votre processus de basculement est bien automatisé et testé, votre vie DBA devient plus confortable. C'est vrai, mais il y a encore quelques énigmes à résoudre. La puissance de calcul n'est pas gratuite, et votre équipe commerciale peut vous demander de mieux utiliser votre matériel, vous voudrez peut-être utiliser votre serveur esclave non seulement comme serveur passif, mais aussi pour servir les opérations d'écriture.
Vous pouvez alors envisager une solution de réplication multimaître. Galera Cluster est devenu une option courante pour MySQL et MariaDB à haute disponibilité. Et bien qu'il soit maintenant connu comme un substitut crédible aux architectures maître-esclave MySQL traditionnelles, il ne s'agit pas d'un remplacement instantané.
Le cluster Galera a une architecture sans partage. Au lieu de disques partagés, Galera utilise une réplication basée sur la certification avec une communication de groupe et un ordre de transaction pour réaliser une réplication synchrone. Un cluster de bases de données devrait pouvoir survivre à la perte d'un nœud, bien que cela soit réalisé de différentes manières. Dans le cas de Galera, l'aspect critique est le nombre de nœuds. Galera a besoin d'un quorum pour rester opérationnel. Un cluster à trois nœuds peut survivre au crash d'un nœud. Avec plus de nœuds dans votre cluster, vous pouvez survivre à plus de pannes.
Le processus de récupération est automatisé, vous n'avez donc pas besoin d'effectuer d'opérations de basculement. Cependant, la bonne pratique serait de tuer les nœuds et de voir à quelle vitesse vous pouvez les ramener. Afin de rendre cette opération plus efficace, vous pouvez modifier la taille du cache galera. Si la taille du cache galera n'est pas correctement planifiée, votre prochain nœud de démarrage devra effectuer une sauvegarde complète au lieu de ne manquer que les jeux d'écriture dans le cache.
Le scénario de basculement est aussi simple que de démarrer l'instance. Sur la base des données du cache galera, le nœud de démarrage effectuera SST (restauration à partir d'une sauvegarde complète) ou IST (applique les ensembles d'écriture manquants). Cependant, cela est souvent lié à l'intervention humaine. Si vous souhaitez automatiser l'ensemble du processus de basculement, vous pouvez utiliser la fonctionnalité de récupération automatique de ClusterControl (au niveau du nœud et du cluster).
 Récupération automatique du cluster ClusterControl
Récupération automatique du cluster ClusterControl Estimer la taille du cache galera :
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;Pour rendre le basculement plus cohérent, vous devez activer gcache.recover=yes dans mycnf. Cette option réactivera le galera-cache au redémarrage. Cela signifie que le nœud peut agir en tant que DONATEUR et servir les ensembles d'écriture manquants (facilitant IST, au lieu d'utiliser SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Le nœud proxy SQL tombe en panne
Si vous avez une configuration IP virtuelle, tout ce que vous avez à faire est de pointer votre application vers l'adresse IP virtuelle et tout devrait être correct en termes de connexion. Il ne suffit pas que vos instances de base de données s'étendent sur plusieurs centres de données, vous avez toujours besoin de vos applications pour y accéder. Supposons que vous ayez augmenté le nombre de réplicas en lecture, vous souhaiterez peut-être également implémenter des adresses IP virtuelles pour chacun de ces réplicas en lecture pour des raisons de maintenance ou de disponibilité. Cela peut devenir un pool encombrant d'adresses IP virtuelles que vous devez gérer. Si l'un de ces réplicas en lecture tombe en panne, vous devez réattribuer l'adresse IP virtuelle à l'hôte différent, sinon votre application se connectera à un hôte en panne ou, dans le pire des cas, à un serveur en retard avec des données obsolètes.
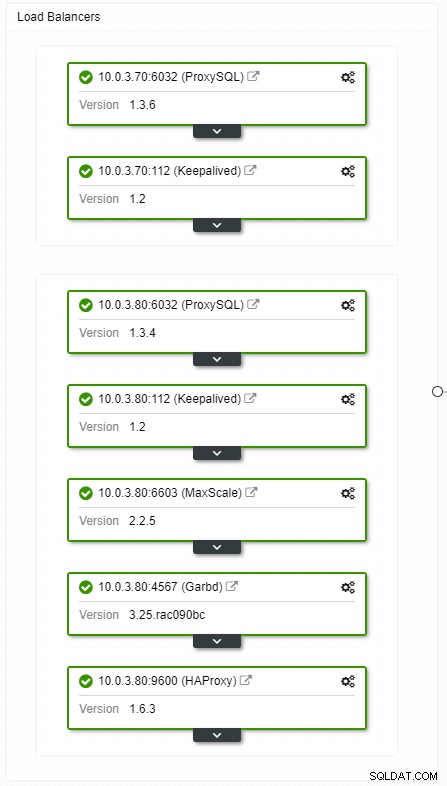 Vue de la topologie des équilibreurs de charge HA ClusterControl
Vue de la topologie des équilibreurs de charge HA ClusterControl Les plantages ne sont pas fréquents, mais plus probables que les pannes de serveurs. Si pour une raison quelconque, un esclave tombe en panne, quelque chose comme ProxySQL redirigera tout le trafic vers le maître, avec le risque de le surcharger. Lorsque l'esclave récupère, le trafic est redirigé vers lui. Habituellement, un tel temps d'arrêt ne devrait pas prendre plus de quelques minutes, de sorte que la gravité globale est moyenne, même si la probabilité est également moyenne.
Pour que les composants de votre équilibreur de charge soient redondants, vous pouvez utiliser keepalived.
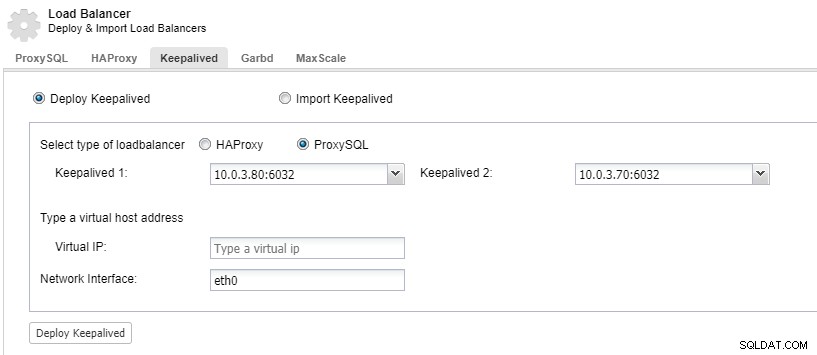 ClusterControl :Déployer keepalived pour l'équilibreur de charge ProxySQL
ClusterControl :Déployer keepalived pour l'équilibreur de charge ProxySQL Le centre de données tombe en panne
Le principal problème avec la réplication est qu'il n'y a pas de mécanisme majoritaire pour détecter une défaillance du centre de données et servir un nouveau maître. L'une des solutions consiste à utiliser Orchestrator/Raft. Orchestrator est un superviseur de topologie qui peut contrôler les basculements. Lorsqu'il est utilisé avec Raft, Orchestrator prend en compte le quorum. L'une des instances d'Orchestrator est élue en tant que leader et exécute les tâches de récupération. La connexion entre le nœud de l'orchestrateur n'est pas corrélée aux validations de la base de données transactionnelle et est clairsemée.
Orchestrator/Raft peut utiliser des instances supplémentaires qui effectuent la surveillance de la topologie. Dans le cas d'un partitionnement réseau, les instances partitionnées d'Orchestrator n'entreprendront aucune action. La partie du cluster Orchestrator qui a le quorum élira un nouveau maître et apportera les modifications de topologie nécessaires.
ClusterControl est utilisé pour la gestion, la mise à l'échelle et, ce qui est le plus important, la récupération de nœud - Orchestrator gère les basculements, mais si un esclave tombe en panne, ClusterControl s'assurera qu'il sera récupéré. Orchestrator et ClusterControl seraient situés dans la même zone de disponibilité, séparés des nœuds MySQL, pour s'assurer que leur activité ne sera pas affectée par les divisions du réseau entre les zones de disponibilité du centre de données.