Introduction
Les développeurs sont souvent invités à utiliser des procédures stockées afin d'éviter les soi-disant requêtes ad hoc ce qui peut entraîner un gonflement inutile du cache du plan. Vous voyez, lorsque le code SQL récurrent est écrit de manière incohérente ou lorsqu'il y a du code qui génère du SQL dynamique à la volée, SQL Server a tendance à créer un plan d'exécution pour chaque exécution individuelle. Cela peut réduire les performances globales de :
Exiger une phase de compilation pour chaque exécution de code.
Glissement du cache de plan avec trop de poignées de plan qui ne peuvent pas être réutilisées.
Optimiser pour les charges de travail ad hoc
Une façon de gérer ce problème dans le passé consiste à optimiser l'instance pour les charges de travail ad hoc. Cela ne peut être utile que si la plupart des bases de données ou les bases de données les plus importantes de l'instance exécutent principalement Ad Hoc SQL.
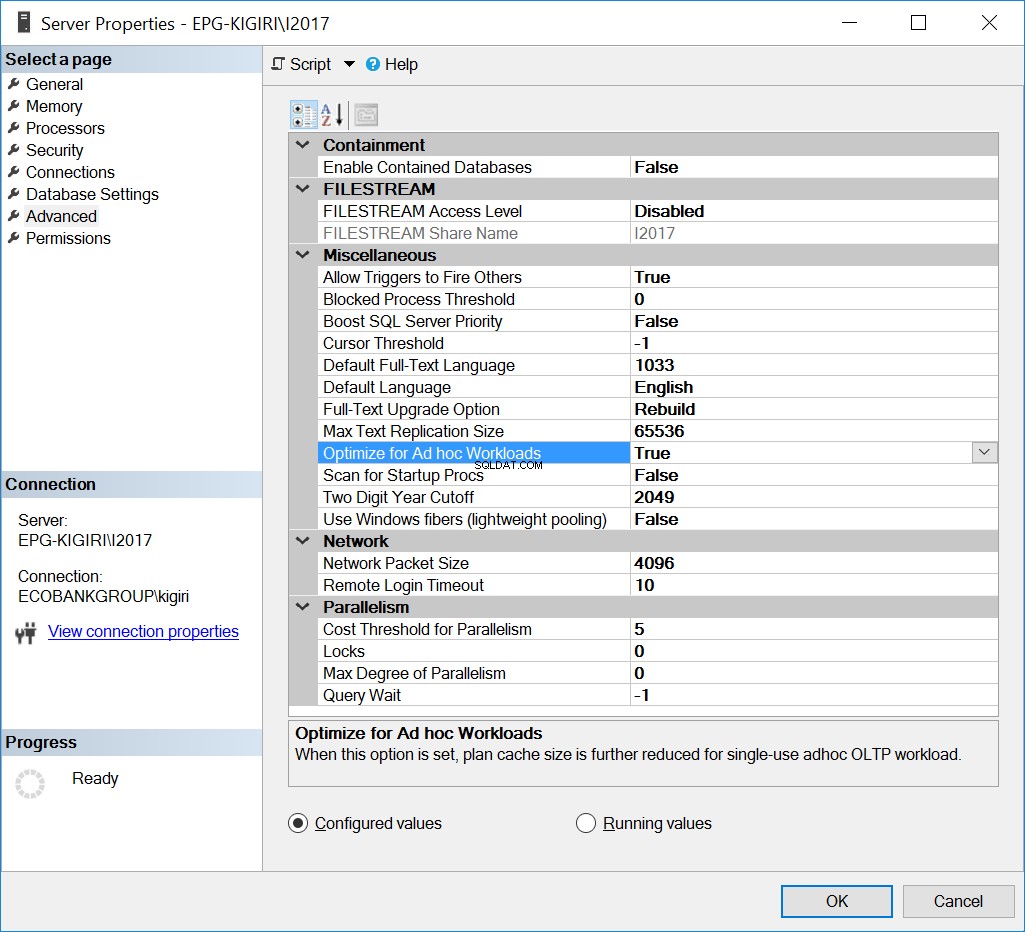
Fig. 1 Optimiser pour les charges de travail ad hoc
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
Essentiellement, cette option indique à SQL Server d'enregistrer une version partielle du plan connue sous le nom de stub de plan compilé. Le talon occupe beaucoup moins d'espace que l'ensemble du plan.
Comme alternative à cette méthode, certaines personnes abordent le problème assez brutalement et vident le cache du plan de temps en temps. Ou, de manière plus prudente, videz les "plans à usage unique" en utilisant DBCC FREESYSTEMCACHE. Vider tout le cache du plan a ses inconvénients, comme vous le savez peut-être déjà.
Utilisation de procédures stockées et de paramètres
En utilisant des procédures stockées, on peut pratiquement éliminer le problème causé par Ad Hoc SQL. Une procédure stockée n'est compilée qu'une seule fois et le même plan est réutilisé pour les exécutions ultérieures de requêtes SQL identiques ou similaires. Lorsque des procédures stockées sont utilisées pour implémenter la logique métier, la principale différence dans les requêtes SQL qui seront éventuellement exécutées par SQL Server réside dans les paramètres passés au moment de l'exécution. Puisque le plan est déjà en place et prêt à être utilisé, SQL Server utilisera le même plan quel que soit le paramètre passé.
Données asymétriques
Dans certains scénarios, les données que nous traitons ne sont pas réparties uniformément. Nous pouvons le démontrer - d'abord, nous devrons créer un tableau :
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Notre tableau contient des données sur les membres du club de différents pays. Un grand nombre de membres du club viennent du Ghana, tandis que deux autres nations comptent respectivement dix et deux membres. Pour rester concentré sur l'agenda et par souci de simplicité, je n'ai utilisé que trois pays et le même nom pour les membres venant du même pays. De plus, j'ai ajouté un index clusterisé dans la colonne ID et un index non clusterisé dans la colonne CountryCode pour démontrer l'effet de différents plans d'exécution pour différentes valeurs.
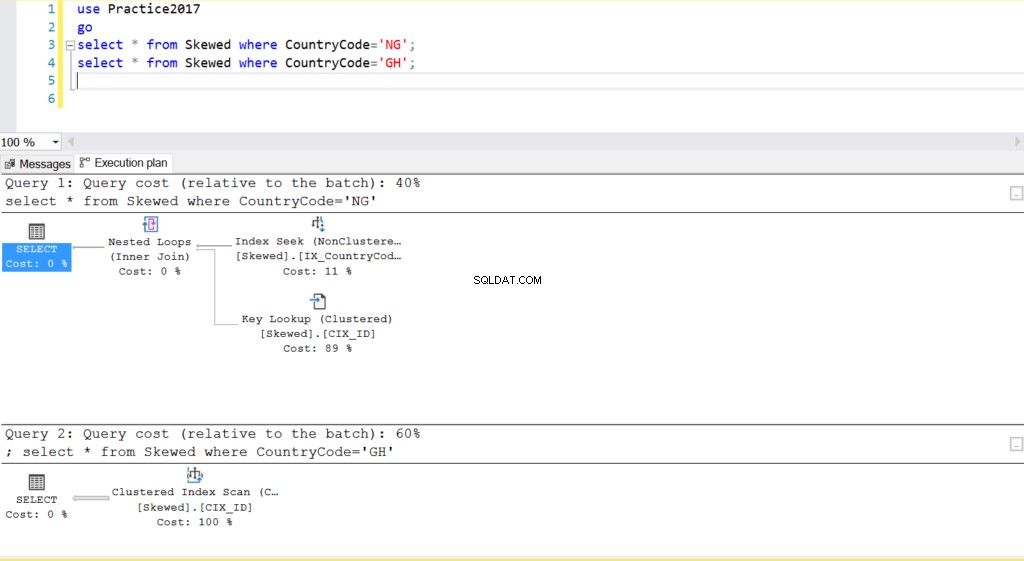
Fig. 2 Plans d'exécution pour deux requêtes
Lorsque nous interrogeons la table pour les enregistrements où CountryCode est NG et GH, nous constatons que SQL Server utilise deux plans d'exécution différents dans ces cas. Cela se produit parce que le nombre de lignes attendu pour CountryCode='NG' est de 10, tandis que celui de CountryCode='GH' est de 10000. SQL Server détermine le plan d'exécution préférable en fonction des statistiques de la table. Si le nombre de lignes attendu est élevé par rapport au nombre total de lignes dans la table, SQL Server décide qu'il est préférable d'effectuer simplement une analyse complète de la table plutôt que de se référer à un index. Avec un nombre estimé de lignes beaucoup plus petit, l'index devient utile.
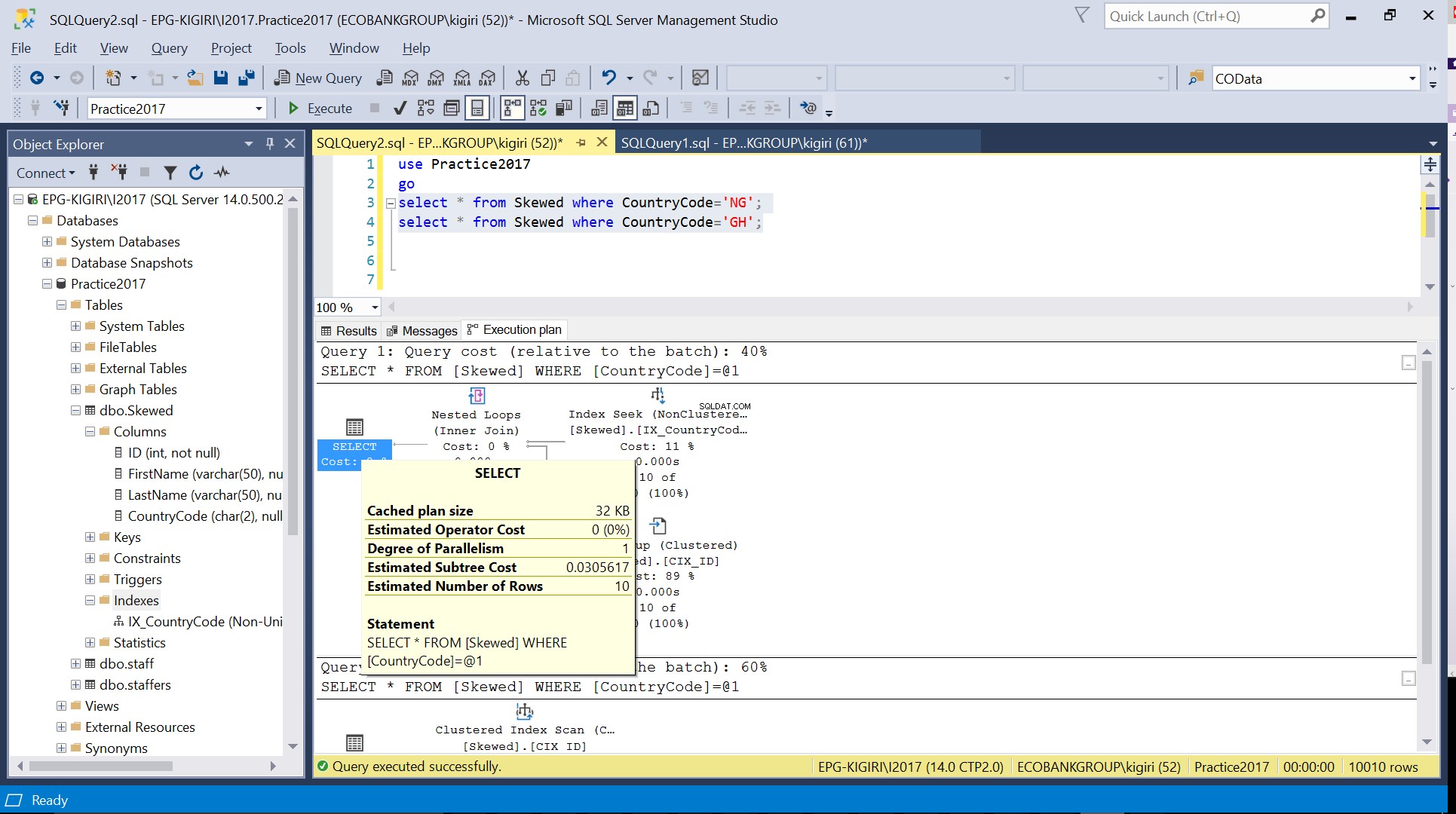
Fig. 3 Estimation du nombre de lignes pour CountryCode=’NG’
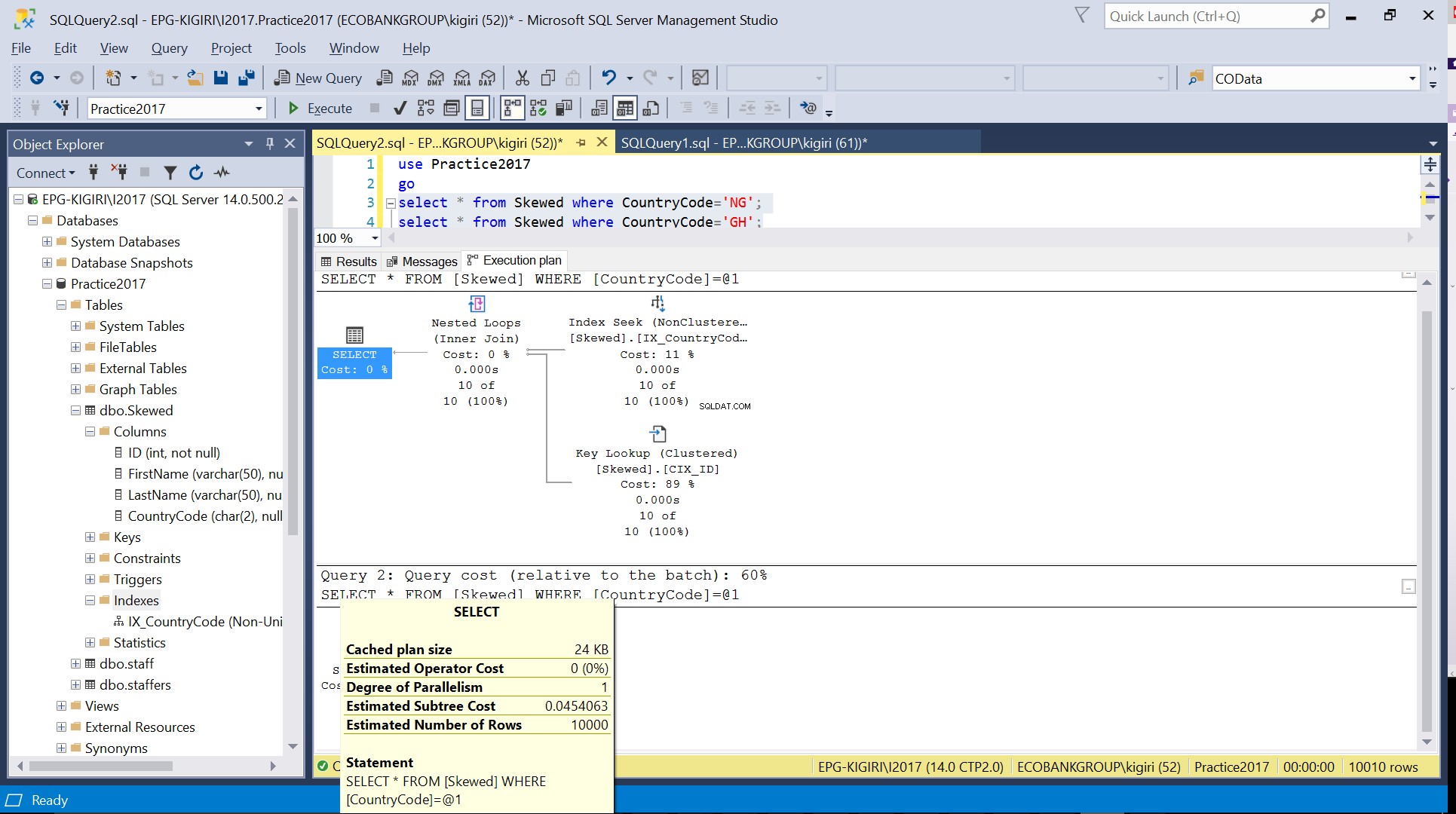
Fig. 4 Estimation du nombre de lignes pour CountryCode=’GH’
Saisir des procédures stockées
Nous pouvons créer une procédure stockée pour récupérer les enregistrements que nous voulons en utilisant la même requête. La seule différence cette fois est que nous passons CountryCode en paramètre (voir Listing 3). Ce faisant, nous découvrons que le plan d'exécution est le même quel que soit le paramètre que nous passons. Le plan d'exécution qui sera utilisé est déterminé par le plan d'exécution renvoyé lors du premier appel de la procédure stockée. Par exemple, si nous exécutons d'abord la procédure avec CountryCode='GH', elle utilisera une analyse complète de la table à partir de ce moment. Si nous vidons ensuite le cache de la procédure et exécutons d'abord la procédure avec CountryCode='NG', elle utilisera à l'avenir des analyses basées sur l'index.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
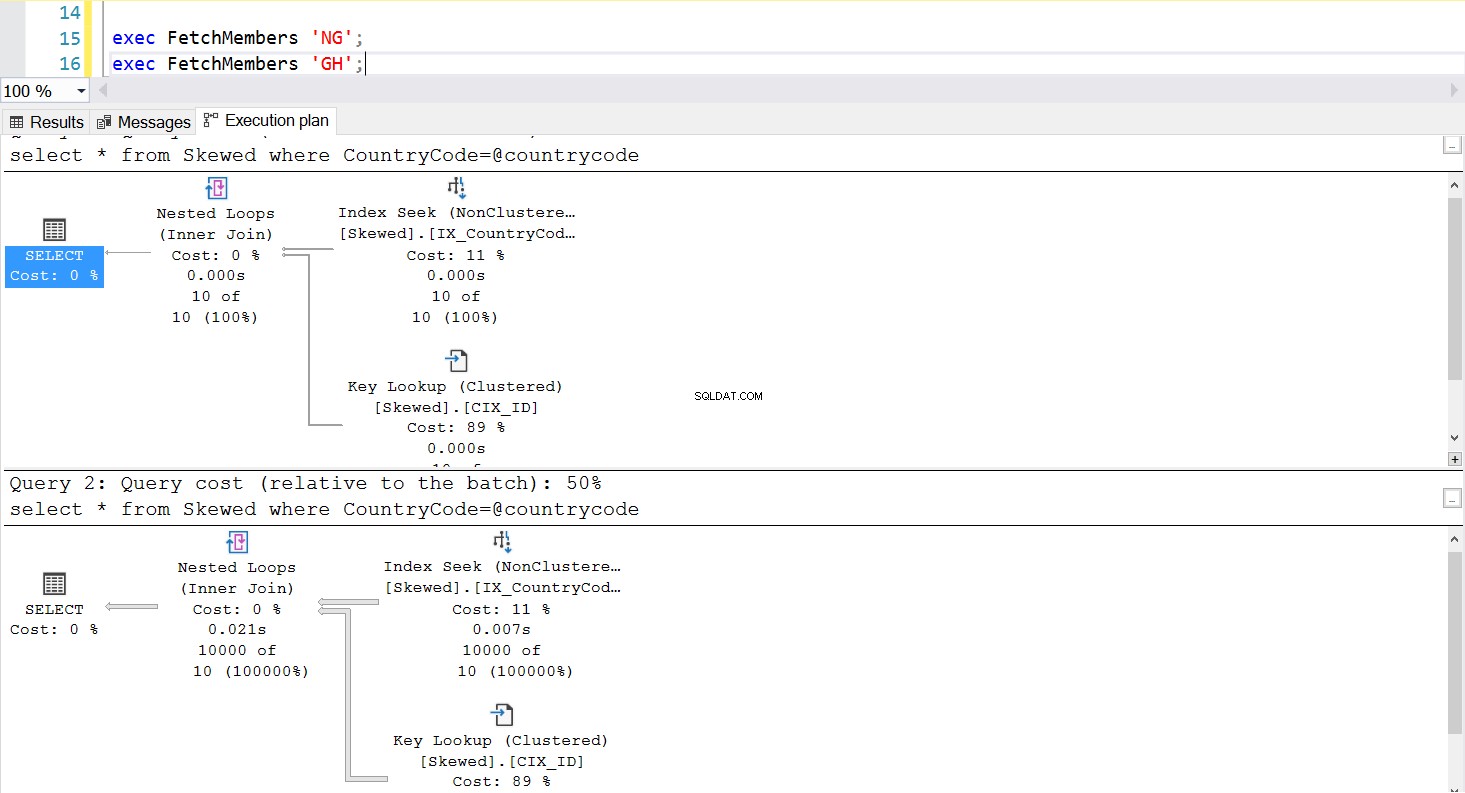
Fig. 5 Plan d'exécution de la recherche d'index lorsque "NG" est utilisé en premier
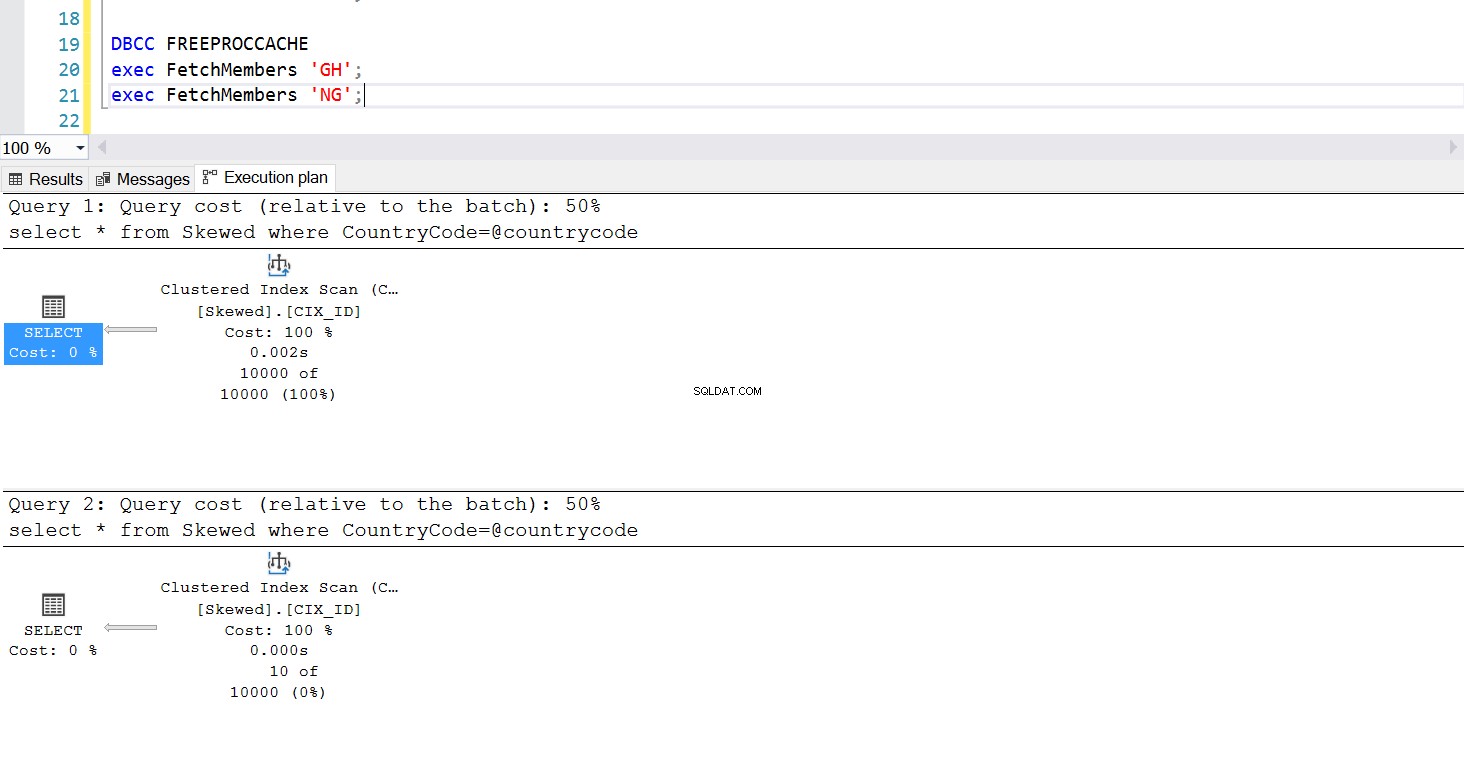
Fig. 6 Plan d'exécution de l'analyse de l'index clusterisé lorsque "GH" est utilisé en premier
L'exécution de la procédure stockée se comporte comme prévu :le plan d'exécution requis est utilisé de manière cohérente. Cependant, cela peut être un problème car un plan d'exécution n'est pas adapté à toutes les requêtes si les données sont faussées. L'utilisation d'un index pour récupérer une collection de lignes presque aussi grande que la table entière n'est pas efficace - ni l'utilisation d'une analyse complète pour récupérer uniquement un petit nombre de lignes. C'est le problème de reniflage de paramètres.
Solutions possibles
Une manière courante de gérer le problème de reniflage de paramètres consiste à invoquer délibérément une recompilation chaque fois que la procédure stockée est exécutée. C'est bien mieux que de vider le cache du plan - sauf si vous souhaitez vider le cache de cette requête SQL spécifique, ce qui est tout à fait possible. Jetez un œil à une version mise à jour de la procédure stockée. Cette fois, il utilise OPTION (RECOMPILE) pour gérer le problème. La figure 6 nous montre que, chaque fois que la nouvelle procédure stockée est exécutée, elle utilise un plan approprié au paramètre que nous passons.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
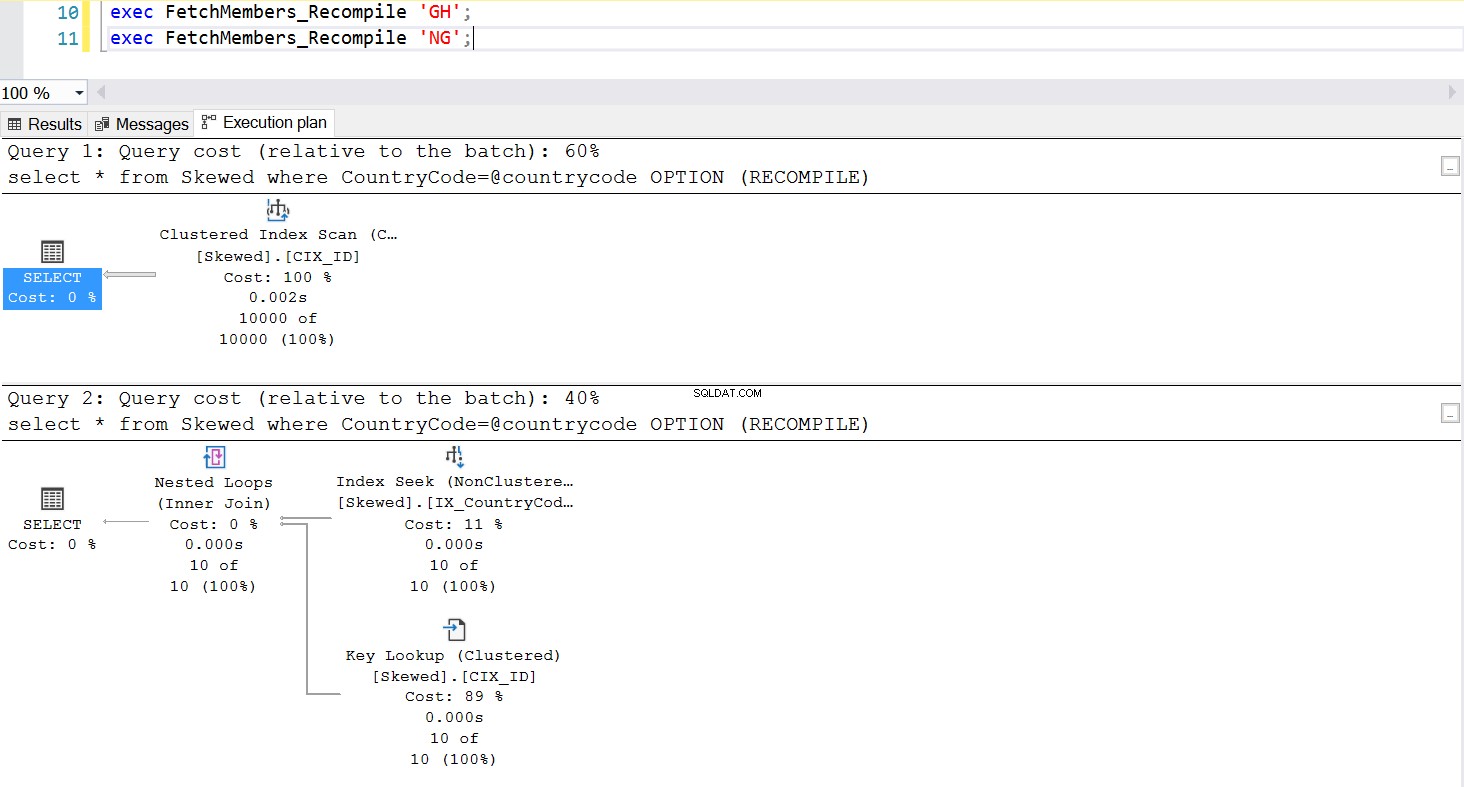
Fig. 7 Comportement de la procédure stockée avec OPTION (RECOMPILE)
Conclusion
Dans cet article, nous avons examiné comment des plans d'exécution cohérents pour les procédures stockées peuvent devenir un problème lorsque les données que nous traitons sont faussées. Nous l'avons également démontré dans la pratique et avons découvert une solution commune au problème. J'ose dire que cette connaissance est inestimable pour les développeurs qui utilisent SQL Server. Il existe un certain nombre d'autres solutions à ce problème - Brent Ozar a approfondi le sujet et a mis en évidence des détails et des solutions plus approfondis lors du SQLDay Poland 2017. J'ai répertorié le lien correspondant dans la section de référence.
Références
Planifier le cache et optimiser les charges de travail ad hoc
Identifier et résoudre les problèmes de détection des paramètres