Il y a peu de chances que vous ayez raté l'idée même de l'économie du partage, que cela vous plaise ou non. Popularisé par des entreprises comme Airbnb, Uber, Lyft et bien d'autres, il permet aux gens de gagner de l'argent en louant leurs affaires inutilisées. Voyons le modèle de données derrière une telle application.
Vous avez une chambre libre ? Inscrivez-vous avec Airbnb et gagnez de l'argent supplémentaire en le louant. Vous avez une voiture et du temps libre ? Devenez chauffeur Uber. Et ainsi de suite - l'idée derrière ces entreprises et bien d'autres comme elles est presque la même. Il s'agit de partager une ressource avec (principalement) des inconnus, avec un avantage pour les deux parties. Le propriétaire reçoit de l'argent pour sa propriété inutilisée, tandis que le client fait généralement une bonne affaire. cela devrait être une situation gagnant-gagnant.
Bien sûr, nous avons besoin d'une plate-forme pour connecter les propriétaires avec les clients et pour garder une trace des détails importants. Aujourd'hui, nous allons présenter un modèle de données qui pourrait gérer la tâche. Installez-vous confortablement dans votre fauteuil et profitez du voyage à travers le modèle de données de l'économie du partage.
De quoi avons-nous besoin dans notre modèle de données ?
L'idée de louer une propriété lorsque nous ne l'utilisons pas semble très judicieuse. Premièrement, le bien est utilisé conformément à sa destination; deuxièmement, la location générera une sorte de revenu supplémentaire. Cela peut être de l'argent, mais aussi un échange (par exemple, quelqu'un à New York échange un appartement avec quelqu'un à Paris pendant une semaine).
Les modèles sans espèces sont vraiment cool et ils dépendent généralement de la compréhension mutuelle, de la bonne volonté et de l'honnêteté. Cependant, cet article se concentrera sur les modèles d'économie de partage qui nécessitent un paiement. Ce n'est pas aussi romantique que les modèles sans numéraire, mais le modèle de paiement est assez efficace.
Nous avons besoin d'un moyen très simple pour un grand nombre de propriétaires d'atteindre un grand nombre de clients intéressés et vice versa. C'est la première exigence de notre modèle de données. Nous aurons des comptes d'utilisateurs et au moins deux rôles distincts :propriétaire et client.
La prochaine chose dont nous avons besoin est que notre application répertorie toutes les propriétés disponibles. Pour Airbnb, il s'agirait d'appartements ; pour Uber, ce serait des voitures. Cet article se concentrera davantage sur la location d'appartements (un modèle de données de type Airbnb), mais je garderai le modèle suffisamment général pour qu'il puisse facilement être converti en tout autre service d'économie de partage souhaité.
Pour chaque propriétaire, nous devrons définir le lieu où il opère. Pour les appartements, c'est assez évident (la ville où se trouve l'appartement). Pour les services de transport, cela dépendra de l'emplacement actuel de la voiture et/ou de son propriétaire.
Pour chaque propriété ou ressource, nous devrons suivre les périodes d'utilisation et les demandes/réservations. Cela nous permettra de trouver des propriétés disponibles lors d'une nouvelle demande et de calculer le taux d'occupation et le prix. Nous pourrons également utiliser d'autres programmes pour analyser ces données et produire d'autres statistiques.
Le modèle de données
Le modèle de données se compose de cinq domaines :
Countries & citiesUsers & rolesServices & documentsRequestsProvided services
Nous présenterons chaque domaine dans le même ordre qu'il est répertorié.
Section 1 :Pays et villes
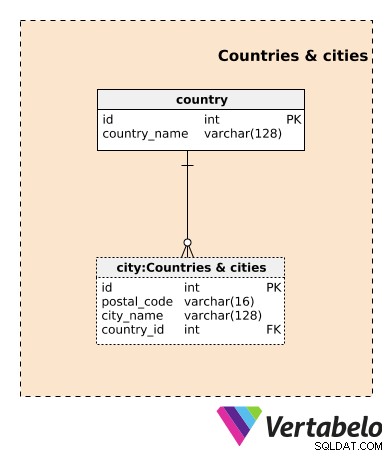
Nous allons commencer par les Countries & cities Domaine. Bien qu'elles ne soient pas spécifiques à ce modèle de données, ces tables sont très importantes. Les services liés à l'immobilier sont généralement orientés géographiquement. Notre modèle est étroitement lié à la location d'un type de logement, de sorte que l'emplacement physique est crucial ici. Bien sûr, cet emplacement ne changera généralement pas. Il y a des cas très particuliers qui pourraient entraîner le changement d'emplacement d'une propriété, mais je traiterais ce logement sur son nouvel emplacement comme une propriété complètement nouvelle.
Pour les applications de voiture et/ou de chauffeur comme Uber, l'emplacement actuel de la voiture et du chauffeur est également très important. Contrairement aux locations d'appartements de style Airbnb, ces emplacements peuvent changer fréquemment.
Le country table contient une liste de noms UNIQUES des pays où nous opérons. La city table contient une liste de toutes les villes où nous opérons. La combinaison UNIQUE pour ce tableau est la combinaison de postal_code , city_name , et country_id les attributs.
Ces deux tables peuvent contenir de nombreux attributs supplémentaires, mais je les ai intentionnellement omis car ils n'ajouteront aucune valeur à ce modèle.
Section 2 :Utilisateurs et rôles
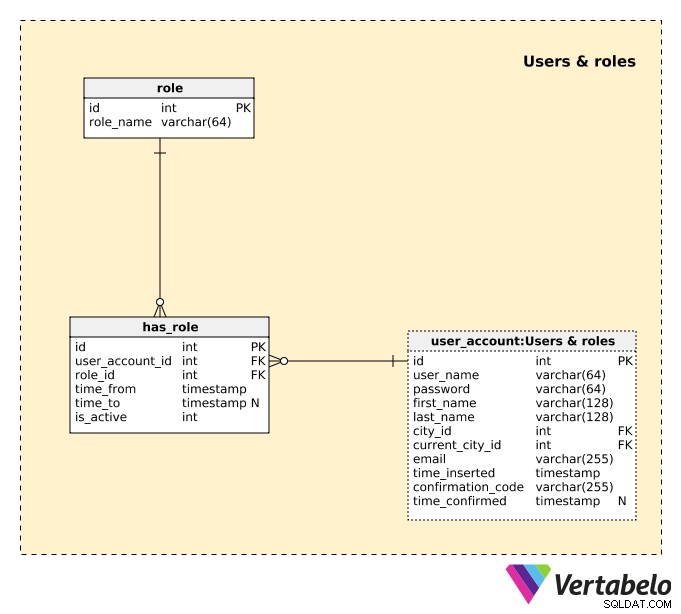
La prochaine chose que nous devons faire est de définir les utilisateurs et leurs comportements ou rôles dans notre application. Pour ce faire, nous utiliserons les trois tables du Users & roles domaine.
Une liste de tous les utilisateurs se trouve dans le user_account table. Pour chaque utilisateur, nous stockerons les détails suivants :
user_name– Le nom UNIQUE que l'utilisateur a choisi pour accéder à notre application.password– Une valeur de hachage du mot de passe choisi par l'utilisateur.first_nameetlast_name– Le prénom et le nom de l'utilisateur.city_id– Une référence à lacityoù se trouve habituellement l'utilisateur.current_city_id– Une référence à lacityoù se trouve actuellement l'utilisateur.email– L'adresse e-mail de l'utilisateur.time_inserted– L'horodatage auquel cet enregistrement a été inséré dans la table.confirmation_code– Un code généré lors du processus d'inscription pour confirmer l'adresse e-mail de l'utilisateur.time_confirmed– L'horodatage de la confirmation de l'adresse e-mail. Cet attribut contient une valeur NULL jusqu'à ce que la confirmation passe.
L'utilisateur aura des droits différents dans l'application en fonction de son rôle. Il est également possible qu'un utilisateur puisse avoir plus d'un rôle actif en même temps, par ex. ils pourraient être le propriétaire d'une propriété et le client d'une autre propriété. Dans ce cas, l'utilisateur utilisera les mêmes informations de connexion et aura la possibilité de basculer entre les rôles. Chaque rôle aura son propre écran dans l'application.
Une liste de tous les rôles possibles est stockée dans le role dictionnaire. Chaque rôle est UNIQUEMENT défini par son role_name . Par souci de simplicité, nous ne pouvons nous attendre qu'à deux rôles :"propriétaire" et "client".
Un utilisateur peut se voir attribuer le même rôle plusieurs fois au cours de périodes différentes. Un tel cas serait si l'utilisateur louait son appartement inutilisé et décidait ensuite de ne pas louer son appartement parce qu'il en avait besoin. Cependant, après quelques mois, le même utilisateur a décidé de relouer son appartement. Dans ce cas, nous désactiverions leur rôle, puis nous le réactiverions.
Une liste de tous les rôles qui ont été attribués aux utilisateurs est stockée dans le has_role table. Pour chaque enregistrement de cette table, nous stockerons :
user_account_id– L'identifiant de l'user.role_id– L'ID durole.time_from– L'horodatage auquel ce rôle a été inséré dans le système.time_to– L'horodatage auquel ce rôle a été désactivé. Cela contiendra une valeur NULL tant que le rôle est toujours actif.is_active– Est défini sur False lorsque le rôle est désactivé pour une raison quelconque.
Lors de l'insertion d'un nouvel enregistrement dans cette table, nous devons vérifier les enregistrements qui se chevauchent. Cela nous permet d'éviter de rendre le même rôle valide deux fois au cours de la même période.
Section 3 :Services et documents
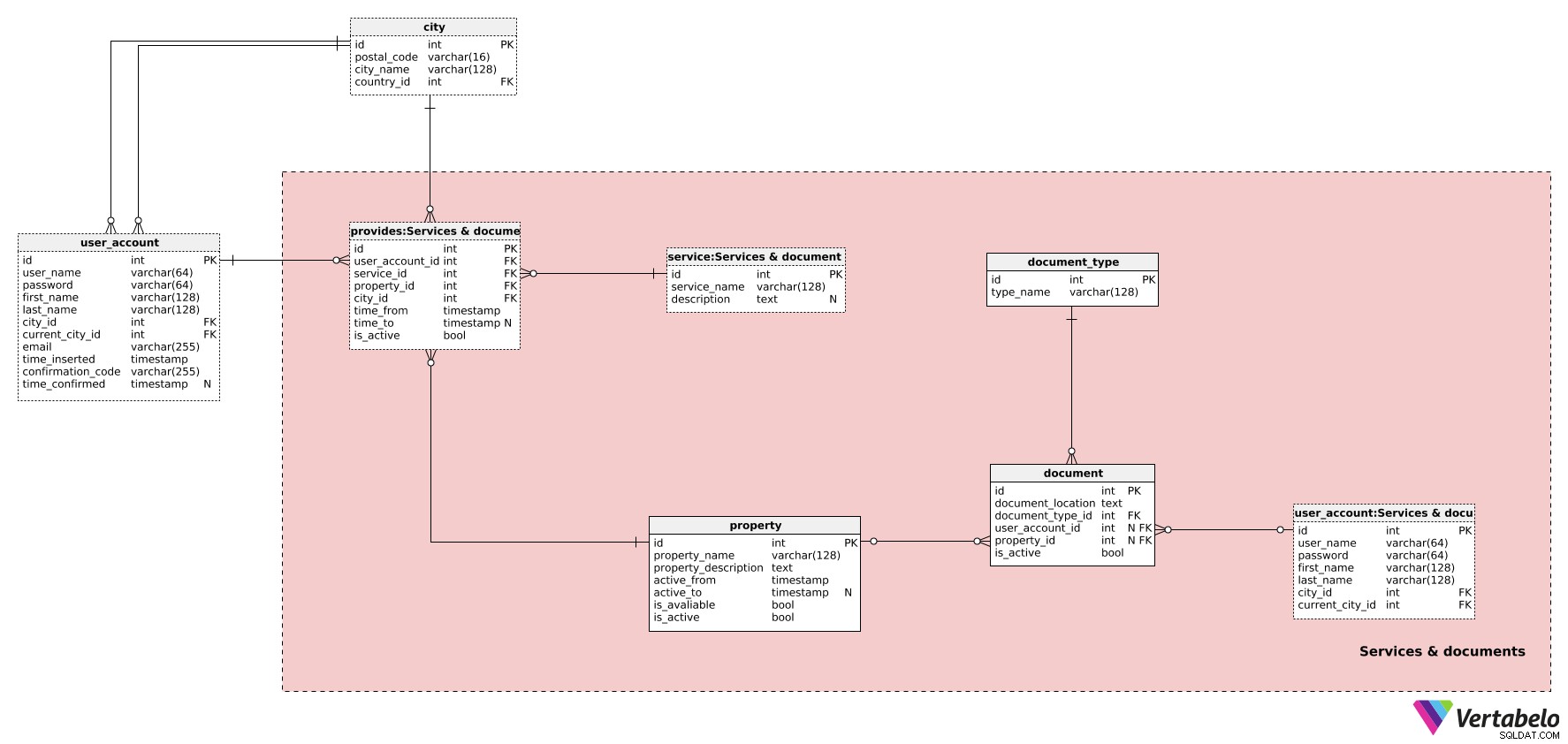
La prochaine chose que nous devons définir sont les services fournis par les utilisateurs. Nous devrons également garder une trace de tous les documents connexes. Pour ce faire, nous aurons besoin des tableaux dans les Services & documents domaine.
Commençons par la property table. Les propriétés sont quels que soient les objets de notre service :habitations, voitures, vélos, etc. Nous pouvons nous attendre à ce que les utilisateurs prennent soin de leurs propres propriétés. Pour chaque propriété, nous devrons définir :
property_name– Le pseudonyme de cette propriété, choisi par l'utilisateur. Ce nom est utilisé lors de l'affichage de la propriété aux clients potentiels sur l'application. Il doit être bref et descriptif et distinguer cette propriété des autres propriétés.property_description– Description textuelle supplémentaire en format non structuré. Nous pouvons nous attendre à un tas de détails ici - essentiellement tout, de la taille de l'appartement à la question de savoir si les clients recevront un verre de bienvenue à leur arrivée. Les boissons de bienvenue dans les services de transport sont beaucoup moins susceptibles de se produire.active_frometactive_to– La période pendant laquelle cette propriété était active dans notre système. Leactive_tol'attribut contiendra la valeur NULL jusqu'à ce que la propriété soit désactivée.is_available– Un indicateur indiquant si cette propriété est disponible à un moment précis ou non.is_active– Un indicateur indiquant si cette propriété est toujours active dans notre système. La valeur de cet attribut sera définie sur False au même instantactive_toest défini.
Nous allons maintenant passer au service dictionnaire. C'est ici que nous définirons tous les types de services possibles, comme "location à long terme", "location à court terme", "transport", etc. Il contient le nom UNIQUE du type de service et une description , si nécessaire.
Nous conserverons les propriétés, services et utilisateurs associés dans le provides table. Il stockera les périodes pendant lesquelles une propriété était disponible. Dans le cas du transport, cela nous indiquerait quand une voiture et un chauffeur travaillaient réellement pour notre entreprise. Dans le cas des locations d'appartements, cela nous indiquerait quand une propriété était disponible. Pour chaque enregistrement ici, nous aurons :
user_account_id– L'identifiant de l'utilisateur fournissant ce service.service_id– L'identifiant duservicetype fourni.property_id– Référence lapropertyutilisé.time_fromettime_to– Lorsque cette propriété a été utilisée pour fournir ce service. Letime_tol'attribut contiendra une valeur NULL jusqu'à ce que cet enregistrement soit désactivé.is_active– Est défini sur False une fois que cette propriété ne sera plus utilisée ou lorsque cet utilisateur cessera de fournir ce service. Ceci est défini au même moment oùtime_toest défini.
Les deux autres tableaux de ce domaine sont liés aux documents. (La table user_account n'est qu'une copie de l'original, utilisée ici pour éviter le chevauchement des relations.) Notre société travaillera avec de nombreux propriétaires et il n'y aura presque aucune chance de tout vérifier en personne. Une façon d'assurer la qualité du service est d'avoir tout bien documenté.
La première table liée aux documents est le document_type table. Ce dictionnaire simple contient une liste de type_name UNIQUES valeurs. Nous pouvons nous attendre à des valeurs telles que "photo de la propriété" et "ID du propriétaire" ici.
Une liste de tous les documents est stockée dans le document table. Ces documents peuvent être liés à des comptes d'utilisateurs, à des propriétés ou aux deux. Pour chaque document, nous stockerons :
document_location– Le chemin d'accès complet à ce document.document_type_id– Une référence audocument_typedictionnaire.user_account_id– Une référence auuser_accounttable. Cet attribut ne contiendra une valeur que lorsque le document est lié à l'utilisateur ou si le document est lié à la propriété mais que l'utilisateur possède également cette propriété.property_id– Une référence à la propriété associée .is_active– Indique si ce document est toujours actif (valide) ou non.
Section 4 :Demandes
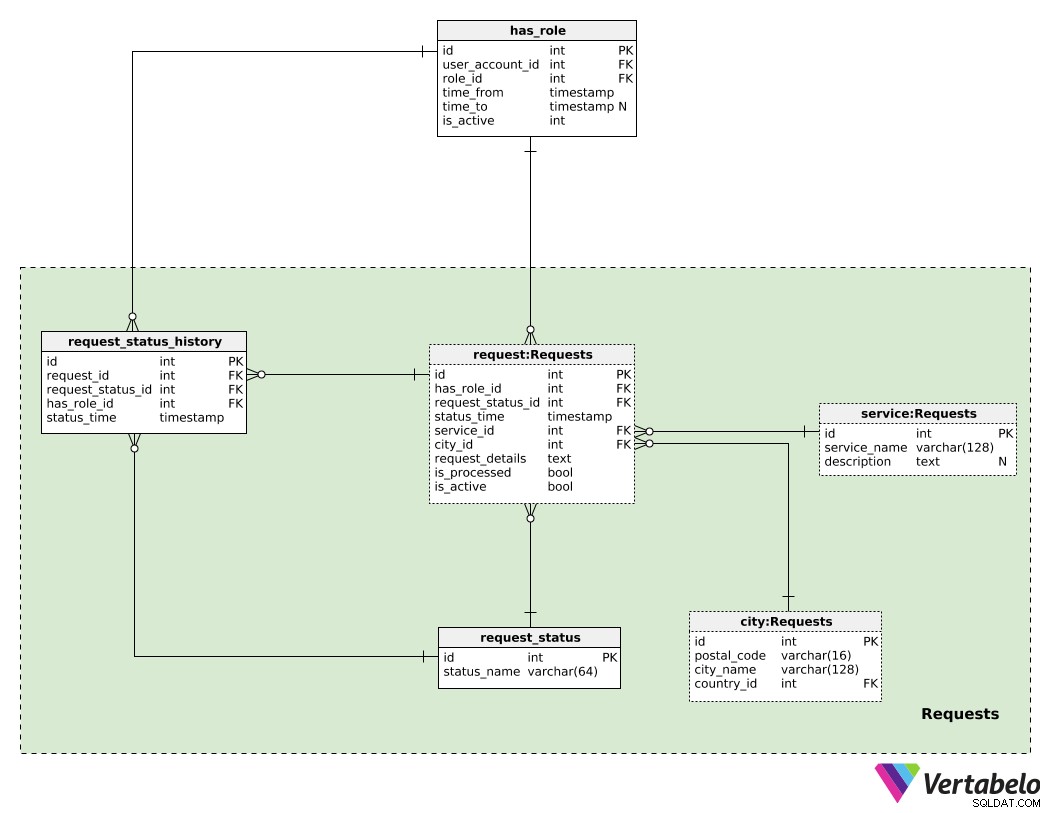
Avant de pouvoir fournir un service, nous devons obtenir des demandes d'utilisateurs. Dans les locations d'appartements, le client fera sa demande pour le bien souhaité après avoir recherché les annonces et trouvé le logement qu'il souhaite. Dans le cas des services de transport, les demandes sont passées par les clients via une application mobile (par exemple, ils sont à l'aéroport et ont besoin d'un trajet dans 20 minutes). Nous parlerons de la façon dont nous traitons les demandes dans la section suivante ; pour l'instant, voyons comment nous les gérons.
La table centrale dans ce domaine est la request table. Pour chaque demande, nous stockons :
has_role_id– Une référence à l'utilisateur (et son rôle actuel, via lehas_roletable) qui a fait cette demande.request_status_id– Une référence à l'état actuel de cette demande.status_time– L'horodatage auquel ce statut a été attribué.service_id– L'identifiant duservicerequis avec cette demande.city_id– Une référence à lacityoù ce service est requis.request_details– Tous les détails supplémentaires de la demande, dans un format textuel non structuré.is_processed– Un indicateur indiquant si cette demande a été traitée (c'est-à-dire attribuée au fournisseur de services).is_active- Cet indicateur sera défini sur False uniquement si un client a annulé sa demande ou si la demande a été annulée par l'application pour une raison quelconque.
Une liste de tous les statuts possibles est stockée dans le request_status dictionnaire avec status_name comme valeur UNIQUE (et unique). Nous pouvons nous attendre à des valeurs telles que "demande placée", "propriété réservée", "attribué au conducteur", "conduite en cours" et "terminée".
Le request_status_history table stockera l'historique de tous les statuts liés aux demandes. Pour chaque enregistrement de cette table, nous stockerons l'ID de la demande associée (request_id ), l'ID de statut (request_status_id ), l'ID de compte utilisateur et le rôle que l'utilisateur avait lorsqu'il a défini ce statut (has_role_id ). Nous enregistrerons également le moment où chaque statut a été attribué (status_time ).
Section 5 :Services fournis
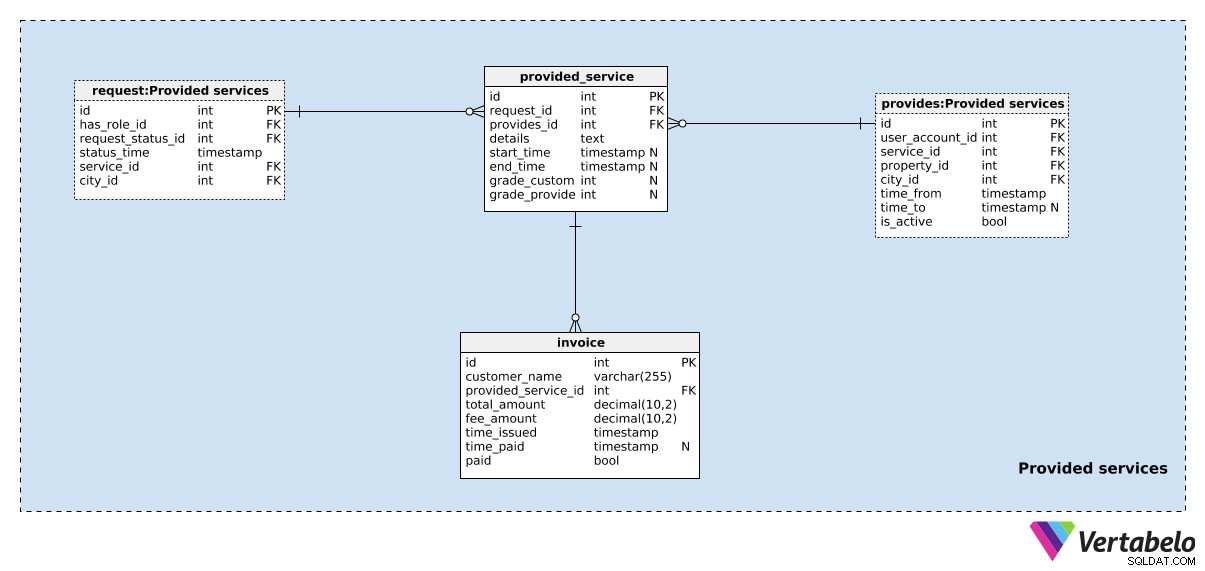
Une fois la demande placée, nous devons la traiter. Une demande sera soit automatiquement attribuée au fournisseur de services approprié (en fonction du type de service demandé, de l'emplacement, etc.), soit acceptée manuellement par le fournisseur de services. Nous n'avons besoin que de deux tables supplémentaires pour gérer cela.
Le premier est le provided_service table. Pour chaque enregistrement, nous inclurons :
request_id– L'ID de larequest.provides_id– Une référence auprovidestableau indiquant le fournisseur de services et la propriété inclus dans cette action.details– Tous les détails supplémentaires, sous forme de texte structuré. Cette structure peut inclure des balises et des valeurs qui décrivent les détails de la demande. Pour un trajet, cela signifierait le point de départ et d'arrivée, la distance parcourue, etc.start_timeetend_time– La période pendant laquelle ce service a été fourni. Ces deux valeurs seront définies lorsque le service vient de démarrer et de se terminer.grade_customeretgrade_provider– Notes attribuées par le client et le fournisseur de services pour ce service.
La dernière table de notre modèle est la invoice table. Nous facturerons les clients (customer_name ) pour les services fournis (provided_service_id ). Pour chaque facture, nous devons connaître le total_amount , tous les frais payés (fee_amount ), lorsque la facture a été émise (time_issued ), et quand il a été payé (time_paid ) Le champ payé sert d'indicateur indiquant si une facture a été payée.
Que pensez-vous de notre modèle de données sur l'économie du partage ?
Aujourd'hui, nous avons discuté d'un modèle de données qui pourrait être utilisé par une entreprise comme Airbnb ou Uber. L'épine dorsale d'un tel modèle d'entreprise sont les clients et les fournisseurs de services. Il y a un certain nombre de détails que je pourrais ajouter à ce modèle. Pourtant, j'ai décidé de ne pas le faire car le modèle deviendrait rapidement trop grand. Pensez-vous que j'aurais dû ajouter quelque chose ? Si oui, dites-le moi dans les commentaires ci-dessous.