J'ai déjà blogué sur les raisons pour lesquelles je n'aime pas sp_updatestats. J'ai récemment trouvé une autre raison pour laquelle ce n'est pas mon ami. TL;DR :Il ne met pas à jour les statistiques sur les vues indexées. Maintenant, la documentation ne prétend pas que c'est le cas, donc il n'y a pas de bogue ici. La documentation MSDN indique clairement :
Exécute UPDATE STATISTICS sur toutes les tables définies par l'utilisateur et internes de la base de données actuelle.Mais… combien d'entre vous ont pensé à vos vues indexées et se sont demandé si elles avaient été mises à jour ? J'avoue que non. J'oublie les vues indexées, ce qui est dommage car elles peuvent être vraiment puissantes lorsqu'elles sont utilisées de manière appropriée. Ils peuvent également être un cauchemar à démêler lorsque vous dépannez, mais je ne vais pas discuter de leur utilisation aujourd'hui. Je veux juste que vous sachiez qu'ils ne sont pas mis à jour par sp_updatestats et que vous voyez quelles options vous avez.
Configuration
Puisque les World Series viennent de se terminer, nous allons utiliser la base de données Baseball pour nos tests. Vous pouvez le télécharger à partir de la page des ressources SQLskills. Une fois restaurée, nous allons créer une copie de la table dbo.Players, nommée dbo.PlayerInfo, y charger quelques milliers de lignes, puis créer une vue indexée qui joint notre nouvelle table à la table PitchingPost :
USE [BaseballData];
GO
CREATE TABLE [dbo].[PlayerInfo](
[lahmanID] [int] NOT NULL,
[playerID] [varchar](10) NULL DEFAULT (NULL),
[managerID] [varchar](10) NULL DEFAULT (NULL),
[hofID] [varchar](10) NULL DEFAULT (NULL),
[birthYear] [int] NULL DEFAULT (NULL),
[birthMonth] [int] NULL DEFAULT (NULL),
[birthDay] [int] NULL DEFAULT (NULL),
[birthCountry] [varchar](50) NULL DEFAULT (NULL),
[birthState] [varchar](2) NULL DEFAULT (NULL),
[birthCity] [varchar](50) NULL DEFAULT (NULL),
[deathYear] [int] NULL DEFAULT (NULL),
[deathMonth] [int] NULL DEFAULT (NULL),
[deathDay] [int] NULL DEFAULT (NULL),
[deathCountry] [varchar](50) NULL DEFAULT (NULL),
[deathState] [varchar](2) NULL DEFAULT (NULL),
[deathCity] [varchar](50) NULL DEFAULT (NULL),
[nameFirst] [varchar](50) NULL DEFAULT (NULL),
[nameLast] [varchar](50) NULL DEFAULT (NULL),
[nameNote] [varchar](255) NULL DEFAULT (NULL),
[nameGiven] [varchar](255) NULL DEFAULT (NULL),
[nameNick] [varchar](255) NULL DEFAULT (NULL),
[weight] [int] NULL DEFAULT (NULL),
[height] [int] NULL,
[bats] [varchar](1) NULL DEFAULT (NULL),
[throws] [varchar](1) NULL DEFAULT (NULL),
[debut] [varchar](10) NULL DEFAULT (NULL),
[finalGame] [varchar](10) NULL DEFAULT (NULL),
[college] [varchar](50) NULL DEFAULT (NULL),
[lahman40ID] [varchar](9) NULL DEFAULT (NULL),
[lahman45ID] [varchar](9) NULL DEFAULT (NULL),
[retroID] [varchar](9) NULL DEFAULT (NULL),
[holtzID] [varchar](9) NULL DEFAULT (NULL),
[bbrefID] [varchar](9) NULL DEFAULT (NULL),
PRIMARY KEY CLUSTERED
([lahmanID] ASC) ON [PRIMARY]
) ON [PRIMARY];
GO
INSERT INTO [dbo].[PlayerInfo]
([lahmanID]
,[playerID]
,[managerID]
,[hofID]
,[birthYear]
,[birthMonth]
,[birthDay]
,[birthCountry]
,[birthState]
,[birthCity]
,[deathYear]
,[deathMonth]
,[deathDay]
,[deathCountry]
,[deathState]
,[deathCity]
,[nameFirst]
,[nameLast]
,[nameNote]
,[nameGiven]
,[nameNick]
,[weight]
,[height]
,[bats]
,[throws]
,[debut]
,[finalGame]
,[college]
,[lahman40ID]
,[lahman45ID]
,[retroID]
,[holtzID]
,[bbrefID])
SELECT [lahmanID]
,[playerID]
,[managerID]
,[hofID]
,[birthYear]
,[birthMonth]
,[birthDay]
,[birthCountry]
,[birthState]
,[birthCity]
,[deathYear]
,[deathMonth]
,[deathDay]
,[deathCountry]
,[deathState]
,[deathCity]
,[nameFirst]
,[nameLast]
,[nameNote]
,[nameGiven]
,[nameNick]
,[weight]
,[height]
,[bats]
,[throws]
,[debut]
,[finalGame]
,[college]
,[lahman40ID]
,[lahman45ID]
,[retroID]
,[holtzID]
,[bbrefID]
FROM [dbo].[Players]
WHERE [lahmanID] <= 10000;
CREATE VIEW [PlayerPostSeason]
WITH SCHEMABINDING
AS
SELECT
[p].[lahmanID],
[p].[nameFirst],
[p].[nameLast],
[p].[debut],
[p].[finalGame],
[pp].[yearID],
[pp].[round],
[pp].[teamID],
[pp].[W],
[pp].[L],
[pp].[G]
FROM [dbo].[PlayerInfo] [p]
JOIN [dbo].[PitchingPost] [pp] ON [p].[playerID] = [pp].[playerID];
CREATE UNIQUE CLUSTERED INDEX [CI_PlayerPostSeason] ON [PlayerPostSeason] ([lahmanID], [yearID], [round]);
CREATE NONCLUSTERED INDEX [NCI_PlayerPostSeason_Name] ON [PlayerPostSeason] ([nameFirst], [nameLast]); Si nous vérifions les statistiques des index clusterisés et non clusterisés, nous constatons qu'ils existent :
DBCC SHOW_STATISTICS ('PlayerPostSeason', CI_PlayerPostSeason) WITH STAT_HEADER;
GO
DBCC SHOW_STATISTICS ('PlayerPostSeason', NCI_PlayerPostSeason_Name) WITH STAT_HEADER;
GO
 Statistiques de la vue d'index après la création initiale
Statistiques de la vue d'index après la création initiale
Nous allons maintenant insérer plus de lignes dans PlayerInfo :
INSERT INTO [dbo].[PlayerInfo]
([lahmanID]
,[playerID]
,[managerID]
,[hofID]
,[birthYear]
,[birthMonth]
,[birthDay]
,[birthCountry]
,[birthState]
,[birthCity]
,[deathYear]
,[deathMonth]
,[deathDay]
,[deathCountry]
,[deathState]
,[deathCity]
,[nameFirst]
,[nameLast]
,[nameNote]
,[nameGiven]
,[nameNick]
,[weight]
,[height]
,[bats]
,[throws]
,[debut]
,[finalGame]
,[college]
,[lahman40ID]
,[lahman45ID]
,[retroID]
,[holtzID]
,[bbrefID])
SELECT [lahmanID]
,[playerID]
,[managerID]
,[hofID]
,[birthYear]
,[birthMonth]
,[birthDay]
,[birthCountry]
,[birthState]
,[birthCity]
,[deathYear]
,[deathMonth]
,[deathDay]
,[deathCountry]
,[deathState]
,[deathCity]
,[nameFirst]
,[nameLast]
,[nameNote]
,[nameGiven]
,[nameNick]
,[weight]
,[height]
,[bats]
,[throws]
,[debut]
,[finalGame]
,[college]
,[lahman40ID]
,[lahman45ID]
,[retroID]
,[holtzID]
,[bbrefID]
FROM [dbo].[Players]
WHERE [lahmanID] > 10000; Et si nous vérifions sys.dm_db_stats_properties, nous pouvons voir les modifications de lignes :
SELECT
[sch].[name] AS [Schema],
[so].[name] AS [ObjectName],
[so].[type] AS [ObjectType],
[ss].[name] AS [Statistic],
[sp].[last_updated] AS [StatsLastUpdated] ,
[sp].[rows] AS [RowsInTable] ,
[sp].[rows_sampled] AS [RowsSampled] ,
[sp].[modification_counter] AS [RowModifications]
FROM [sys].[objects] [so]
JOIN [sys].[stats] [ss] ON [so].[object_id] = [ss].[object_id]
JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id]
OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id],
[ss].[stats_id]) sp
WHERE [so].[name] = 'PlayerPostSeason';
 Lignes modifiées dans la vue indexée, via sys.dm_db_stats_properties
Lignes modifiées dans la vue indexée, via sys.dm_db_stats_properties
Et juste pour le plaisir, si nous vérifions sys.sysindexes, nous pouvons également voir les modifications :
SELECT [so].[name], [si].[name], [si].[rowcnt], [si].[rowmodctr] FROM [sys].[sysindexes] [si] JOIN [sys].[objects] [so] ON [si].[id] = [so].[object_id] WHERE [so].[name] = 'PlayerPostSeason';
 Lignes modifiées dans la vue indexée, via sys.sysindexes
Lignes modifiées dans la vue indexée, via sys.sysindexes
Maintenant, sys.sysindexes est obsolète, mais si vous vous souvenez de mon post précédent, c'est ce que sp_updatestats utilise pour voir ce qui a été modifié. Mais… la liste d'objets pour sys.indexes est pilotée par la requête sur sys.objects, qui, si vous vous en souvenez, filtre sur les tables utilisateur ('U') et les tables internes ('IT'). Il n'inclut pas les vues ("V") dans ce filtre. Ainsi, lorsque nous exécutons sp_updatestats et vérifions la sortie (non incluse par souci de brièveté), il n'y a aucune mention de notre vue PlayerPostSeason.
Par conséquent, si vous avez des vues indexées et que vous comptez sur sp_updatestats pour mettre à jour vos statistiques, vos statistiques de vue ne sont pas mises à jour. Cependant, je suppose que la plupart d'entre vous ont activé l'option de mise à jour automatique des statistiques pour vos bases de données. C'est bien, car avec cette option, les statistiques de vue seront mises à jour si elles ont été invalidées. Nous savons que nous avons apporté plus de 2000 modifications aux index sur PlayerPostSeason. Si nous interrogeons par un prénom sélectif, notre plan de requête doit utiliser l'index NCI_PlayerPostSeason_Name, et comme les statistiques sont obsolètes, elles doivent être mises à jour. Vérifions :
SELECT * FROM [PlayerPostSeason] WHERE [nameFirst] = 'Madison'; GO
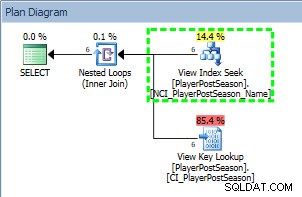 Plan de requête de SELECT sur un index non cluster
Plan de requête de SELECT sur un index non cluster
Nous pouvons voir dans le plan que l'index non clusterisé NCI_PlayerPostSeason_Name a été utilisé, et si nous vérifions les statistiques :
 Statistiques après mise à jour automatique
Statistiques après mise à jour automatique
Effectivement, les statistiques de l'index non clusterisé ont été mises à jour. Mais bien sûr, nous ne voulons pas compter sur la mise à jour automatique pour gérer les statistiques, nous voulons être proactifs. Nous avons deux options :
- Tâche de maintenance
- Script personnalisé
La tâche de maintenance des statistiques de mise à jour fait mettre à jour les statistiques de vue. Ce n'est pas spécifiquement appelé n'importe où dans l'interface utilisateur, mais si nous créons un plan de maintenance avec la tâche de mise à jour des statistiques et que nous l'exécutons, les statistiques de la vue indexée sont mises à jour. L'inconvénient de la tâche de maintenance des statistiques de mise à jour est qu'il s'agit d'une approche à la masse. Il met à jour tous statistiques, qu'elles soient nécessaires ou non (c'est presque aussi mauvais que sp_updatestats). Je préfère un script personnalisé, où SQL Server ne met à jour que ce qui a été modifié. Si vous n'aimez pas lancer votre propre script, vous pouvez utiliser le script d'Ola Hallengren. Il est courant de mettre à jour les statistiques dans le cadre de vos reconstructions et réorganisations d'index. Par exemple, avec le script d'Ola dans le travail de l'Agent SQL, vous auriez :
sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q "EXECUTE [dbo].[IndexOptimize] @Databases ='BaseballData', @FragmentationLow =NULL, @FragmentationMedium ='INDEX_REORGANIZE', @FragmentationHigh ='INDEX_REBUILD ', @FragmentationLevel1 =5, @FragmentationLevel2 =30, @UpdateStatistics ='ALL', @OnlyModifiedStatistics ='Y', @LogToTable ='Y'" -bAvec cette option, si les statistiques ont été modifiées, elles seront mises à jour, et si nous vérifions la procédure stockée [dbo].[IndexOptimize] nous pouvons voir où Ola vérifie les modifications :
-- Has the data in the statistics been modified since the statistics was last updated?
IF @CurrentStatisticsID IS NOT NULL AND @UpdateStatistics IS NOT NULL AND @OnlyModifiedStatistics = 'Y'
BEGIN
SET @CurrentCommand10 = ''
IF @LockTimeout IS NOT NULL SET @CurrentCommand10 = 'SET LOCK_TIMEOUT ' + CAST(@LockTimeout * 1000 AS nvarchar) + '; '
IF (@Version >= 10.504000 AND @Version < 11) OR @Version >= 11.03000
BEGIN
SET @CurrentCommand10 = @CurrentCommand10 + 'USE ' + QUOTENAME(@CurrentDatabaseName)
+ '; IF EXISTS(SELECT * FROM sys.dm_db_stats_properties (@ParamObjectID, @ParamStatisticsID)
WHERE modification_counter > 0) BEGIN SET @ParamStatisticsModified = 1 END'
END
ELSE
BEGIN
SET @CurrentCommand10 = @CurrentCommand10 + 'IF EXISTS(SELECT * FROM '
+ QUOTENAME(@CurrentDatabaseName) + '.sys.sysindexes sysindexes
WHERE sysindexes.[id] = @ParamObjectID AND sysindexes.[indid] = @ParamStatisticsID
AND sysindexes.[rowmodctr] <> 0) BEGIN SET @ParamStatisticsModified = 1 END'
END Pour les versions qui prennent en charge le DMF sys.dm_db_stats_properties, Ola le vérifie pour toutes les statistiques qui ont été modifiées, et pour les versions qui ne prennent pas en charge le nouveau DMF sys.dm_db_stats_properties, la table système sys.sysindexes est vérifiée. Mon seul reproche ici est que le script se comporte de la même manière que sp_updatestats :si au moins une ligne a été modifiée, la statistique sera mise à jour.
Si vous n'êtes pas en train d'écrire votre propre code pour gérer les statistiques, je vous recommande de vous en tenir au script d'Ola. Mais si vous souhaitez cibler un peu plus vos mises à jour, je vous recommande d'utiliser sys.dm_db_stats_properties. Ce DMF est uniquement disponible pour SQL Server 2008R2 SP2 et supérieur, et SQL Server 2012 SP1 et supérieur, donc si vous utilisez une version inférieure, vous devrez utiliser sys.indexes. Mais pour ceux d'entre vous qui ont accès à sys.dm_db_stats_properties, voici une requête pour vous aider à démarrer :
SELECT
[sch].[name] AS [Schema],
[so].[name] AS [ObjectName],
[so].[type] AS [ObjectType],
[ss].[name] AS [Statistic],
[sp].[last_updated] AS [StatsLastUpdated] ,
[sp].[rows] AS [RowsInTable] ,
[sp].[rows_sampled] AS [RowsSampled] ,
CAST(100 * [sp].[rows_sampled] / [sp].[rows] AS DECIMAL (18, 2)) AS [PercentSampled],
[sp].[modification_counter] AS [RowModifications] ,
CAST(100 * [sp].[modification_counter] / [sp].[rows] AS DECIMAL(18, 2)) AS [PercentChange]
FROM [sys].[objects] AS [so]
INNER JOIN [sys].[stats] AS [ss] ON [so].[object_id] = [ss].[object_id]
INNER JOIN [sys].[schemas] AS [sch] ON [so].[schema_id] = [sch].[schema_id]
OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) AS [sp]
WHERE [so].[type] IN ('U','V')
AND ((CAST(100 * [sp].[modification_counter] / [sp].[rows] AS DECIMAL(18,2)) >= 10.0))
ORDER BY CAST(100 * [sp].[modification_counter] / [sp].[rows] AS DECIMAL(18, 2)) DESC; Notez qu'avec sys.objects nous filtrons sur les tables et les vues; vous pouvez le modifier pour inclure les tables système. Vous pouvez ensuite modifier le prédicat pour récupérer uniquement les lignes en fonction du pourcentage de lignes modifiées, ou peut-être une combinaison du pourcentage de modification et du nombre de lignes (pour les tables avec des millions ou des milliards de lignes, ce pourcentage peut être inférieur à celui des petites tables).
Résumé
Le message à retenir ici est assez clair :je ne recommande pas d'utiliser sp_updatestats pour gérer les statistiques. Les statistiques sont mises à jour lorsqu'une ou plusieurs lignes ont changé (ce qui est un seuil extrêmement bas pour la mise à jour des statistiques) et les statistiques des vues indexées ne sont pas mis à jour. Ce n'est pas une méthode complète et efficace pour gérer les statistiques… et la tâche de mise à jour des statistiques dans un plan de maintenance n'est pas beaucoup mieux. Il met à jour les statistiques de vue indexées, mais il met à jour chaque statistique, quelles que soient les modifications. Un script personnalisé est vraiment la voie à suivre, mais comprenez que le script d'Ola Hallengren, si vous mettez à jour en fonction de la modification, se met également à jour lorsque seule la ligne a été modifiée (mais il obtient au moins les vues indexées). En fin de compte, pour un meilleur contrôle, cherchez à lancer votre propre script de gestion des statistiques. Je vous ai donné la requête de base pour commencer. Si vous pouvez réserver quelques heures pour pratiquer votre écriture T-SQL, puis le tester, vous aurez un script personnalisé fonctionnel prêt pour vos bases de données avant les vacances.