Depuis la sortie de ClusterControl 1.2.11 en 2015, MariaDB MaxScale est pris en charge en tant qu'équilibreur de charge de base de données. Au fil des ans, MaxScale a grandi et mûri, ajoutant plusieurs fonctionnalités riches. Récemment, MariaDB MaxScale 2.2 a été publié et introduit plusieurs nouvelles fonctionnalités, notamment la gestion du basculement du cluster de réplication.
MariaDB MaxScale permet des déploiements maître/esclave avec haute disponibilité, basculement automatique, basculement manuel et réintégration automatique. Si le maître tombe en panne, MariaDB MaxScale peut automatiquement promouvoir l'esclave le plus récent en maître. Si le maître défaillant est récupéré, MariaDB MaxScale peut automatiquement le reconfigurer en tant qu'esclave du nouveau maître. De plus, les administrateurs peuvent effectuer un basculement manuel pour changer de maître à la demande.
Dans nos blogs précédents, nous avons expliqué comment déployer MaxScale à l'aide de ClusterControl ainsi que le déploiement de MariaDB MaxScale sur Docker. Pour ceux qui ne sont pas encore familiarisés avec MariaDB MaxScale, il s'agit d'un plug-in avancé de proxy de base de données pour les serveurs de base de données MariaDB. Maxscale se situe entre les applications clientes et les serveurs de base de données, acheminant les requêtes des clients et les réponses des serveurs. Il surveille également les serveurs, remarquant rapidement tout changement dans l'état du serveur ou la topologie de réplication.
Bien que Maxscale partage certaines des caractéristiques d'autres technologies d'équilibrage de charge comme ProxySQL, cette nouvelle fonctionnalité de basculement (qui fait partie de son mécanisme de surveillance et d'autodétection) se démarque. Dans ce blog, nous allons discuter de cette nouvelle fonction passionnante de Maxscale.
Présentation du mécanisme de basculement MariaDB MaxScale
Détection principale
Le moniteur est désormais moins susceptible de changer soudainement de serveur maître, même si un autre serveur a plus d'esclaves que le maître actuel. Le DBA peut forcer une resélection de maître en mettant le maître actuel en lecture seule, ou en supprimant tous ses esclaves si le maître est en panne.
Un seul serveur peut avoir l'indicateur d'état Maître à la fois, même dans une configuration multimaître. Les autres serveurs du groupe multimaître reçoivent les indicateurs d'état Relay Master et Slave.
Basculer la sélection automatique du nouveau maître
La commande de basculement peut maintenant être appelée avec uniquement le nom de l'instance du moniteur comme paramètre. Dans ce cas, le moniteur sélectionnera automatiquement un serveur pour la promotion.
Détection du décalage de réplication
La mesure du décalage de réplication lit désormais simplement Seconds_Behind_Master -champ de la sortie d'état d'esclave des esclaves. L'esclave calcule cette valeur en comparant l'horodatage de l'événement binlog que l'esclave est en train de traiter à sa propre horloge. Si un esclave a plusieurs connexions esclaves, le plus petit décalage est utilisé.
Basculement automatique après détection d'un espace disque insuffisant
Avec les versions récentes de MariaDB Server, le moniteur peut désormais vérifier l'espace disque sur le backend et détecter si le serveur est faible. Lorsque cela se produit, le moniteur peut être configuré pour basculer automatiquement à partir d'un maître à faible espace disque. Les esclaves peuvent également être mis en mode maintenance. L'espace disque est également un facteur pris en compte lors de la sélection du nouveau master à promouvoir.
Voir switchover_on_low_disk_space et maintenance_on_low_disk_space pour plus d'informations.
Fonctionnalité de réinitialisation de la réplication
La réinitialisation-réplication La commande monitor supprime toutes les connexions esclaves et les journaux binaires, puis configure la réplication. Utile lorsque les données sont synchronisées mais que les gtid ne le sont pas.
Gestion des événements planifiés en cas de basculement/basculement/rejoindre
Les événements serveur lancés par le thread du planificateur d'événements sont désormais gérés lors des opérations de modification de cluster. Voir handle_server_events pour plus d'informations.
Assistance maître externe
Le moniteur peut détecter si un serveur du cluster réplique à partir d'un maître externe (un serveur qui n'est pas surveillé par le moniteur MaxScale). Si le serveur de réplication est le serveur maître du cluster, le cluster lui-même est considéré comme ayant un maître externe.
Si un basculement/basculement se produit, le nouveau serveur maître est configuré pour répliquer à partir du serveur maître externe du cluster. Le nom d'utilisateur et le mot de passe pour la réplication sont définis dans replication_user et replication_password. L'adresse et le port utilisés sont ceux affichés par SHOW ALL SLAVES STATUS sur l'ancien serveur maître du cluster. En cas de basculement, l'ancien maître arrête également la réplication à partir du serveur externe pour préserver la topologie.
Après le basculement, le nouveau maître réplique à partir du maître externe. Si l'ancien maître défaillant revient en ligne, il se réplique également à partir du serveur externe. Pour normaliser la situation, activez auto_rejoin ou exécutez manuellement une jointure. Cela redirigera l'ancien maître vers le maître actuel du cluster.
En quoi le basculement est-il utile et applicable ?
Le basculement vous aide à minimiser les temps d'arrêt, à effectuer une maintenance quotidienne ou à gérer une maintenance désastreuse et indésirable qui peut parfois se produire à des moments malheureux. Avec la capacité de MaxScale à isoler les applications clientes des serveurs de base de données principaux, il ajoute des fonctionnalités précieuses qui aident à minimiser les temps d'arrêt.
Le plug-in de surveillance MaxScale surveille en permanence l'état des serveurs de base de données principaux. Le plug-in de routage de MaxScale utilise ensuite ces informations d'état pour toujours acheminer les requêtes vers les serveurs de base de données principaux qui sont en service. Il est alors capable d'envoyer des requêtes aux clusters de base de données backend, même si certains des serveurs d'un cluster sont en maintenance ou connaissent une panne.
La haute configurabilité de MaxScale permet aux modifications de la configuration du cluster de rester transparentes pour les applications clientes. Par exemple, si un nouveau serveur doit être administrativement ajouté ou supprimé d'un cluster maître-esclave, vous pouvez simplement ajouter la configuration MaxScale à la liste des serveurs des plugins de moniteur et de routeur via la console CLI maxadmin. L'application cliente sera totalement inconsciente de ce changement et continuera à envoyer des requêtes de base de données au port d'écoute de MaxScale.
La mise en maintenance d'un serveur de base de données est simple et facile. Effectuez simplement la commande suivante en utilisant maxctrl et MaxScale arrêtera d'envoyer des requêtes à ce serveur. Par exemple,
maxctrl: set server DB_785 maintenance
OKPuis en vérifiant l'état des serveurs comme suit,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Une fois en mode maintenance, MaxScale arrêtera d'acheminer toute nouvelle requête vers le serveur. Pour les requêtes en cours, MaxScale ne tuera pas ces sessions, mais lui permettra plutôt de terminer son exécution et n'interrompra aucune requête en cours en mode maintenance. Notez également que le mode de maintenance n'est pas persistant. Si MaxScale redémarre lorsqu'un nœud est en mode maintenance, une nouvelle instance de MariaDB MaxScale ne respectera pas ce mode. Si plusieurs instances MariaDB MaxScale sont configurées pour utiliser le nœud, leur mode de maintenance doit être défini dans chaque instance MariaDB MaxScale. Cependant, si plusieurs services au sein d'une instance MariaDB MaxScale utilisent le serveur, il vous suffit de définir le mode de maintenance une seule fois sur le serveur pour que tous les services prennent note du changement de mode.
Une fois votre maintenance terminée, nettoyez simplement le serveur avec la commande suivante. Par exemple,
maxctrl: clear server DB_785 maintenance
OKEn vérifiant s'il est revenu à la normale, exécutez simplement la commande lister les serveurs .
Vous pouvez également appliquer certaines actions administratives via l'interface utilisateur de ClusterControl. Voir l'exemple de capture d'écran ci-dessous :
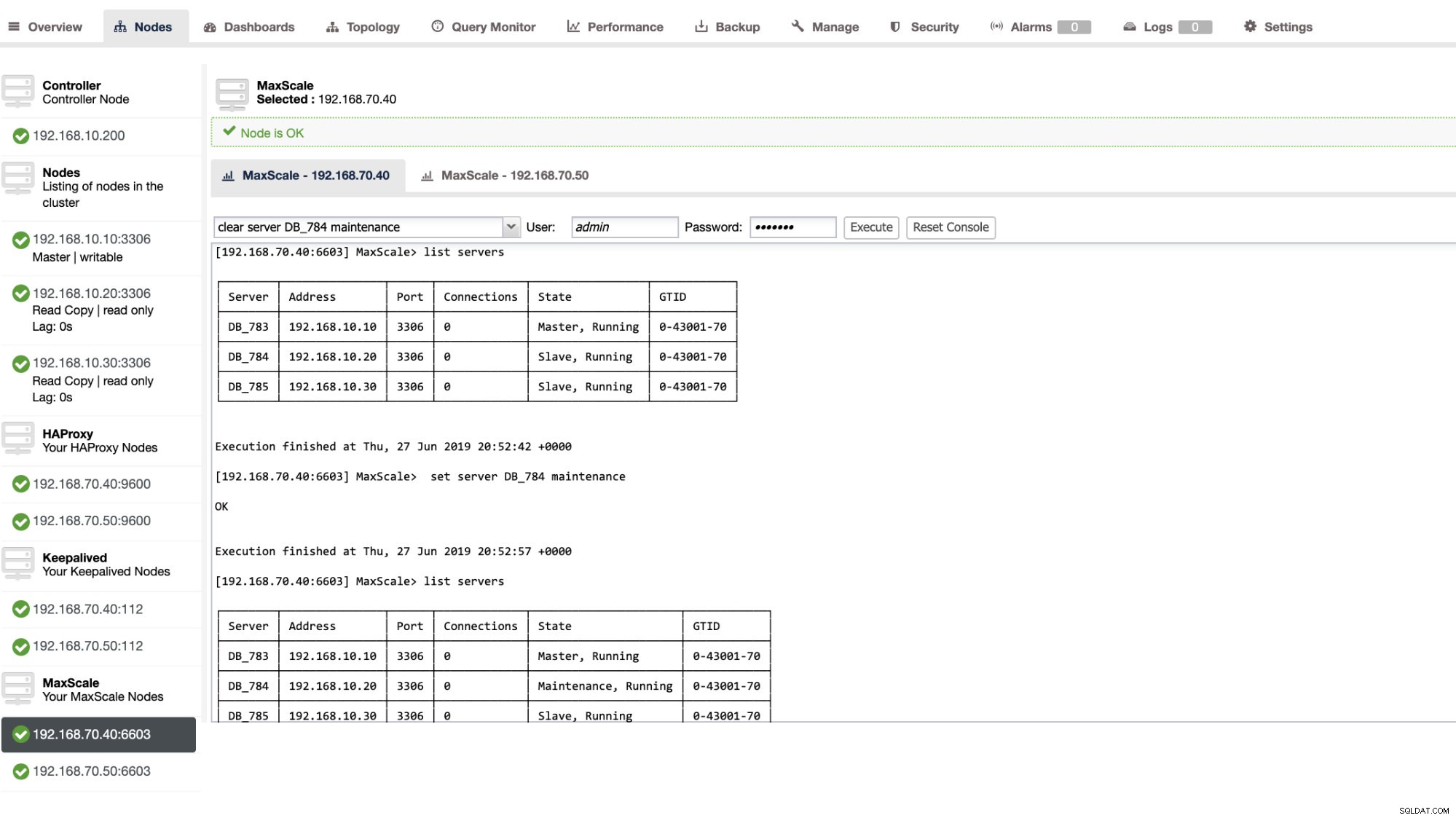
Basculement MaxScale en action
Le basculement automatique
Le basculement MaxScale de MariaDB fonctionne très efficacement et reconfigure l'esclave en conséquence, comme prévu. Dans ce test, nous avons l'ensemble de fichiers de configuration suivant qui a été créé et géré par ClusterControl. Voir ci-dessous :
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonNotez que seul le auto_failover et auto_rejoin sont les variables que j'ai ajoutées car ClusterControl ne l'ajoutera pas par défaut une fois que vous aurez configuré un équilibreur de charge MaxScale (consultez ce blog pour savoir comment configurer MaxScale à l'aide de ClusterControl). N'oubliez pas que vous devez redémarrer MariaDB MaxScale une fois que vous avez appliqué les modifications dans votre fichier de configuration. Courez,
systemctl restart maxscaleet vous êtes prêt à partir.
Avant de procéder au test de basculement, vérifions d'abord l'état du cluster :
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Ça a l'air génial !
J'ai tué le maître avec juste la pure commande killer KILL -9 $(pidof mysqld) dans mon nœud maître et voir, sans surprise, le moniteur a été rapide à le remarquer et à déclencher le basculement. Consultez les journaux comme suit :
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Examinons maintenant la santé de son cluster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Le nœud 192.168.10.10 qui était auparavant le maître a été arrêté. J'ai essayé de redémarrer et de voir si la réintégration automatique se déclencherait, et comme vous l'avez remarqué dans le journal au moment 2019-06-28 06:39:20.165, il a été si rapide de saisir l'état du nœud, puis de configurer automatiquement la configuration sans aucun problème pour l'administrateur de base de données pour l'activer.
Maintenant, en vérifiant enfin son état, il semble parfaitement fonctionner comme prévu. Voir ci-dessous :
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Mon ex-maître a été réparé et récupéré et je veux changer de poste
Passer à votre ancien maître n'est pas non plus un problème. Vous pouvez l'utiliser avec maxctrl (ou maxadmin dans les versions précédentes de MaxScale) ou via l'interface utilisateur de ClusterControl (comme démontré précédemment).
Référons-nous simplement à l'état précédent de la santé du cluster de réplication plus tôt, et voulions faire basculer le 192.168.10.10 (actuellement esclave) vers son état maître. Avant de continuer, vous devrez peut-être d'abord identifier le moniteur que vous allez utiliser. Vous pouvez le vérifier avec la commande suivante ci-dessous :
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Une fois que vous l'avez, vous pouvez exécuter la commande suivante ci-dessous pour basculer :
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKVérifiez ensuite à nouveau l'état du cluster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Ça a l'air parfait !
Les journaux vous montreront de manière détaillée comment cela s'est passé et sa série d'actions pendant le basculement. Voir les détails ci-dessous :
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]Dans le cas d'un mauvais basculement, il ne se poursuivra pas et générera donc une erreur, comme indiqué dans le journal ci-dessus. Ainsi, vous serez en sécurité et pas de surprises effrayantes du tout.
Rendre votre MaxScale hautement disponible
Bien que ce soit un peu hors sujet en ce qui concerne le basculement, je voulais ajouter ici quelques points précieux concernant la haute disponibilité et son lien avec le basculement de MariaDB MaxScale.
Rendre votre MaxScale hautement disponible est un élément important en cas de panne de votre système, de corruption de disque ou de corruption de machine virtuelle. Ces situations sont inévitables et peuvent affecter l'état de votre configuration de basculement automatisé lorsque ces cycles de maintenance inattendus se produisent.
Pour un environnement de type cluster de réplication, cela est très avantageux et fortement recommandé pour une configuration MaxScale spécifique. L'objectif est qu'une seule instance MaxScale soit autorisée à modifier le cluster à un moment donné. Si vous avez configuré avec Keepalived, c'est là que les instances avec le statut de MASTER. MaxScale lui-même ne connaît pas son état, mais avec maxctrl (ou maxadmin dans les versions précédentes) peut définir une instance MaxScale en mode passif. À partir de la version 2.2.2, un MaxScale passif se comporte de la même manière qu'un actif, à la différence près qu'il n'effectuera pas de basculement, de basculement ou de réintégration. Même les versions manuelles de ces commandes se termineront par une erreur. Les différences entre les modes passif/actif peuvent être étendues à l'avenir, alors restez à l'écoute de ces changements dans MaxScale. Pour ce faire, procédez comme suit :
maxctrl: alter maxscale passive true
OKVous pouvez le vérifier par la suite en exécutant la commande ci-dessous :
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Si vous souhaitez découvrir comment configurer la haute disponibilité avec Keepalived, veuillez consulter cet article de MariaDB.
Gestion des VIP
De plus, comme MaxScale n'a pas de gestion VIP intégrée, vous pouvez utiliser Keepalived pour gérer cela pour vous. Vous pouvez simplement utiliser l'adresse IP virtuelle attribuée au nœud d'état MASTER. Cela est susceptible de proposer une gestion IP virtuelle, tout comme MHA le fait avec la variable master_failover_script. Comme mentionné précédemment, consultez cet article de blog sur la configuration de Keepalived with MaxScale par MariaDB.
Conclusion
MariaDB MaxScale est riche en fonctionnalités et possède de nombreuses fonctionnalités, non seulement en tant que proxy et équilibreur de charge, mais il offre également le mécanisme de basculement que les grandes organisations recherchent. Il s'agit presque d'un logiciel unique, mais il comporte bien sûr des limitations qu'une certaine application pourrait avoir besoin de comparer à d'autres équilibreurs de charge tels que ProxySQL.
ClusterControl offre également un mécanisme de basculement automatique et de détection automatique du maître, ainsi qu'une récupération de cluster et de nœud avec la possibilité de déployer Maxscale et d'autres technologies d'équilibrage de charge.
Chacun de ces outils a ses caractéristiques et fonctionnalités diverses, mais MariaDB MaxScale est bien pris en charge dans ClusterControl et peut être déployé de manière réalisable avec Keepalived, HAProxy pour vous aider à accélérer votre tâche de routine quotidienne.