Publié à l'origine sur Serverless le 2 juillet 2019

Exposer une base de données simple via une API GraphQL nécessite beaucoup de code personnalisé et d'infrastructure :vrai ou faux ?
Pour ceux qui ont répondu "vrai", nous sommes là pour vous montrer que la création d'API GraphQL est en fait assez facile, avec quelques exemples concrets pour illustrer pourquoi et comment.
(Si vous savez déjà à quel point il est facile de créer des API GraphQL avec Serverless, vous en trouverez également beaucoup dans cet article.)
GraphQL est un langage de requête pour les API Web. Il existe une différence essentielle entre une API REST conventionnelle et les API basées sur GraphQL :avec GraphQL, vous pouvez utiliser une seule requête pour récupérer plusieurs entités à la fois. Cela se traduit par des chargements de page plus rapides et permet une structure plus simple pour vos applications frontales, ce qui se traduit par une meilleure expérience Web pour tout le monde. Si vous n'avez jamais utilisé GraphQL auparavant, nous vous suggérons de consulter ce didacticiel GraphQL pour une introduction rapide.
Le framework Serverless convient parfaitement aux API GraphQL :avec Serverless, vous n'avez pas à vous soucier de l'exécution, de la gestion et de la mise à l'échelle de vos propres serveurs d'API dans le cloud, et vous n'aurez pas besoin d'écrire de scripts d'automatisation de l'infrastructure. En savoir plus sur Serverless ici. En outre, Serverless offre une excellente expérience de développement indépendante des fournisseurs et une communauté solide pour vous aider à créer vos applications GraphQL.
De nombreuses applications de notre expérience quotidienne contiennent des fonctionnalités de réseautage social, et ce type de fonctionnalité peut vraiment bénéficier de la mise en œuvre de GraphQL au lieu du modèle REST, où il est difficile d'exposer des structures avec des entités imbriquées, comme les utilisateurs et leurs messages Twitter. Avec GraphQL, vous pouvez créer un point de terminaison API unifié qui vous permet d'interroger, d'écrire et de modifier toutes les entités dont vous avez besoin à l'aide d'une seule requête API.
Dans cet article, nous examinons comment créer une API GraphQL simple à l'aide du framework sans serveur, Node.js, et de l'une des nombreuses solutions de base de données hébergées disponibles via Amazon RDS :MySQL, PostgreSQL et le travail semblable à MySQL Amazon Aurora.
Suivez cet exemple de dépôt sur GitHub, et allons-y !
Construire une API GraphQL avec un backend de base de données relationnelle
Dans notre exemple de projet, nous avons décidé d'utiliser les trois bases de données (MySQL, PostgreSQL et Aurora) dans la même base de code. Nous savons que c'est exagéré même pour une application de production, mais nous voulions vous époustoufler avec la façon dont nous construisons à l'échelle du Web. 😉
Mais sérieusement, nous avons surchargé le projet juste pour nous assurer que vous trouviez un exemple pertinent qui s'applique à votre base de données préférée. Si vous souhaitez voir des exemples avec d'autres bases de données, veuillez nous en informer dans les commentaires.
Définir le schéma GraphQL
Commençons par définir le schéma de l'API GraphQL que nous voulons créer, ce que nous faisons dans le fichier schema.gql à la racine de notre projet en utilisant la syntaxe GraphQL. Si vous n'êtes pas familier avec cette syntaxe, jetez un œil aux exemples sur cette page de documentation GraphQL.
Pour commencer, nous ajoutons les deux premiers éléments au schéma :une entité Utilisateur et une entité Publication, en les définissant comme suit afin que chaque Utilisateur puisse être associé à plusieurs entités Publication :
tapez Utilisateur
UUID :chaîne
Nom :Chaîne
Messages :[Message]
}
tapez Message {/h1>
UUID :chaîne
Texte :Chaîne
}
Nous pouvons maintenant voir à quoi ressemblent les entités User et Post. Plus tard, nous veillerons à ce que ces champs puissent être stockés directement dans nos bases de données.
Ensuite, définissons comment les utilisateurs de l'API interrogeront ces entités. Bien que nous puissions utiliser les deux types GraphQL User et Post directement dans nos requêtes GraphQL, il est préférable de créer des types d'entrée à la place pour garder le schéma simple. Nous allons donc de l'avant et ajoutons deux de ces types d'entrée, un pour les publications et un pour les utilisateurs :
saisir UserInput
Nom :Chaîne
Messages :[PostInput]
}
saisir PostInput {/h1>
Texte :Chaîne
}
Définissons maintenant les mutations, les opérations qui modifient les données stockées dans nos bases de données via notre API GraphQL. Pour cela, nous créons un type Mutation. La seule mutation que nous utiliserons pour l'instant est createUser. Comme nous utilisons trois bases de données différentes, nous ajoutons une mutation pour chaque type de base de données. Chacune des mutations accepte l'entrée UserInput et renvoie une entité User :
Nous souhaitons également fournir un moyen d'interroger les utilisateurs. Nous créons donc un type de requête avec une requête par type de base de données. Chaque requête accepte une chaîne qui est l'UUID de l'utilisateur, renvoyant l'entité utilisateur qui contient son nom, son UUID et une collection de chaque Pos``t associé :
Enfin, nous définissons le schéma et pointons vers les types Query et Mutation :
schema { query: Query mutation: Mutation }
Nous avons maintenant une description complète de notre nouvelle API GraphQL ! Vous pouvez voir l'intégralité du fichier ici.
Définition des gestionnaires pour l'API GraphQL
Maintenant que nous avons une description de notre API GraphQL, nous pouvons écrire le code dont nous avons besoin pour chaque requête et mutation. Nous commençons par créer un fichier handler.js à la racine du projet, juste à côté du fichier schema.gql que nous avons créé précédemment.
La première tâche de handler.js consiste à lire le schéma :
La constante typeDefs contient désormais les définitions de nos entités GraphQL. Ensuite, nous spécifions où le code de nos fonctions va vivre. Pour que les choses restent claires, nous allons créer un fichier séparé pour chaque requête et mutation :
La constante des résolveurs contient désormais les définitions de toutes les fonctions de notre API. Notre prochaine étape consiste à créer le serveur GraphQL. Vous souvenez-vous de la bibliothèque graphql-yoga dont nous avions besoin ci-dessus ? Nous utiliserons cette bibliothèque ici pour créer facilement et rapidement un serveur GraphQL fonctionnel :
Enfin, nous exportons le gestionnaire GraphQL avec le gestionnaire GraphQL Playground (ce qui nous permettra d'essayer notre API GraphQL dans un navigateur Web) :
Bon, nous en avons fini avec le fichier handler.js pour le moment. Ensuite :écrire du code pour toutes les fonctions qui accèdent aux bases de données.
Écriture du code pour les requêtes et les mutations
Nous avons maintenant besoin de code pour accéder aux bases de données et alimenter notre API GraphQL. À la racine de notre projet, nous créons la structure suivante pour nos fonctions de résolution MySQL, avec les autres bases de données à suivre :
Requêtes courantes
Dans le dossier Common, nous remplissons le fichier mysql.js avec ce dont nous aurons besoin pour la mutation createUser et la requête getUser :une requête init, pour créer des tables pour les utilisateurs et les messages s'ils n'existent pas encore ; et une requête utilisateur, pour renvoyer les données d'un utilisateur lors de la création et de la requête pour un utilisateur. Nous l'utiliserons à la fois dans la mutation et dans la requête.
La requête init crée les tables Users et Posts comme suit :
La requête getUser renvoie l'utilisateur et ses publications :
Ces deux fonctions sont exportées ; nous pouvons ensuite y accéder dans le fichier handler.js.
Écrire la mutation
Il est temps d'écrire le code de la mutation createUser, qui doit accepter le nom du nouvel utilisateur, ainsi qu'une liste de tous les messages qui lui appartiennent. Pour ce faire, nous créons le fichier resolver/Mutation/mysql_createUser.js avec une seule fonction func exportée pour la mutation :
La fonction de mutation doit faire les choses suivantes, dans l'ordre :
-
Connectez-vous à la base de données en utilisant les informations d'identification dans les variables d'environnement de l'application.
-
Insérez l'utilisateur dans la base de données à l'aide du nom d'utilisateur, fourni comme entrée pour la mutation.
-
Insérez également tous les messages associés à l'utilisateur, fournis en entrée de la mutation.
-
Renvoyer les données utilisateur créées.
Voici comment nous accomplissons cela dans le code :
Vous pouvez voir le fichier complet qui définit la mutation ici.
Écrire la requête
La requête getUser a une structure similaire à la mutation que nous venons d'écrire, mais celle-ci est encore plus simple. Maintenant que la fonction getUser se trouve dans l'espace de noms commun, nous n'avons plus besoin de SQL personnalisé dans la requête. Nous créons donc le fichier resolver/Query/mysql_getUser.js comme suit :
Vous pouvez voir la requête complète dans ce fichier.
Tout rassembler dans le fichier serverless.yml
Prenons du recul. Nous avons actuellement les éléments suivants :
-
Un schéma d'API GraphQL.
-
Un fichier handler.js.
-
Un fichier pour les requêtes de base de données courantes.
-
Un fichier pour chaque mutation et requête.
La dernière étape consiste à connecter tout cela ensemble via le fichier serverless.yml. Nous créons un serverless.yml vide à la racine du projet et commençons par définir le fournisseur, la région et le runtime. Nous appliquons également le rôle LambdaRole IAM (que nous définissons plus loin ici) à notre projet :
Nous définissons ensuite les variables d'environnement pour les informations d'identification de la base de données :
Notez que toutes les variables font référence à la section personnalisée, qui vient ensuite et contient les valeurs réelles des variables. Notez que le mot de passe est un mot de passe terrible pour votre base de données et devrait être remplacé par quelque chose de plus sécurisé (peut-être p@ssw0rd 😃) :
Quelles sont ces références après Fn ::GettAtt, demandez-vous ? Ceux-ci font référence aux ressources de la base de données :
Le fichier resource/MySqlRDSInstance.yml définit tous les attributs de l'instance MySQL. Vous pouvez retrouver son contenu complet ici.
Enfin, dans le fichier serverless.yml, nous définissons deux fonctions, graphql et playground. La fonction graphql va gérer toutes les requêtes API, et le point de terminaison du terrain de jeu créera une instance de GraphQL Playground pour nous, ce qui est un excellent moyen d'essayer notre API GraphQL dans un navigateur Web :
La prise en charge de MySQL pour notre application est maintenant terminée !
Vous pouvez trouver le contenu complet du fichier serverless.yml ici.
Ajout de la prise en charge d'Aurora et de PostgreSQL
Nous avons déjà créé toute la structure dont nous avons besoin pour prendre en charge d'autres bases de données dans ce projet. Pour ajouter la prise en charge d'Aurora et de Postgres, nous n'avons qu'à définir le code de leurs mutations et requêtes, ce que nous faisons comme suit :
-
Ajoutez un fichier de requêtes communes pour Aurora et pour Postgres.
-
Ajoutez la mutation createUser pour les deux bases de données.
-
Ajoutez la requête getUser pour les deux bases de données.
-
Ajoutez la configuration dans le fichier serverless.yml pour toutes les variables d'environnement et les ressources nécessaires pour les deux bases de données.
À ce stade, nous avons tout ce dont nous avons besoin pour déployer notre API GraphQL, optimisée par MySQL, Aurora et PostgreSQL.
Déployer et tester l'API GraphQL
Le déploiement de notre API GraphQL est simple.
-
Nous exécutons d'abord npm install pour mettre nos dépendances en place.
-
Ensuite, nous exécutons npm run deploy, qui configure toutes nos variables d'environnement et effectue le déploiement.
-
Sous le capot, cette commande exécute un déploiement sans serveur en utilisant le bon environnement.
C'est ça! Dans la sortie de l'étape de déploiement, nous verrons le point de terminaison URL de notre application déployée. Nous pouvons envoyer des requêtes POST à notre API GraphQL en utilisant cette URL, et notre Playground (avec lequel nous jouerons dans une seconde) est disponible en utilisant GET sur la même URL.
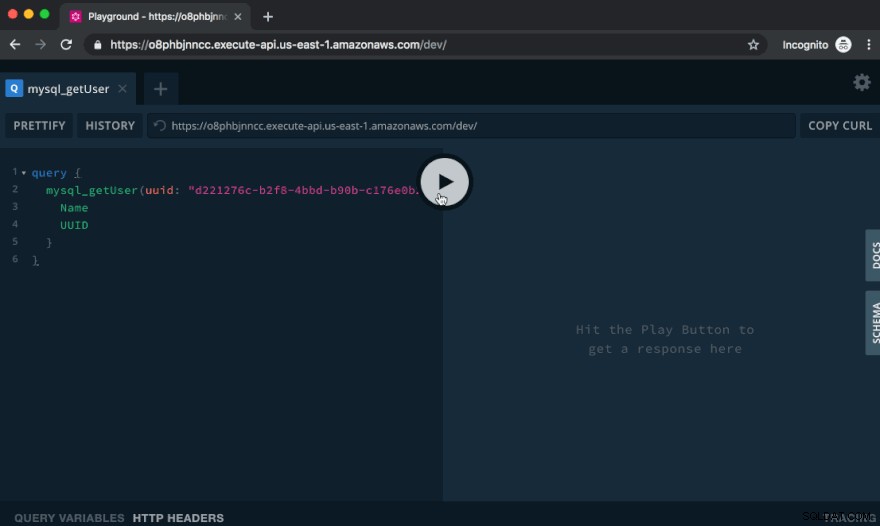
Tester l'API dans le GraphQL Playground
Le terrain de jeu GraphQL, qui est ce que vous voyez lorsque vous visitez cette URL dans le navigateur, est un excellent moyen d'essayer notre API.
Créons un utilisateur en exécutant la mutation suivante :
mutation { mysql_createUser( input: { Name: "Cicero" Posts: [ { Text: "Lorem ipsum dolor sit amet, consectetur adipiscing elit." } { Text: "Proin consequat mauris orci, ut consequat purus efficitur vel." } ] } ) { Name UUID } }
Dans cette mutation, nous appelons l'API mysql_createUser, fournissons le texte des messages du nouvel utilisateur et indiquons que nous voulons récupérer le nom de l'utilisateur et l'UUID comme réponse.
Collez le texte ci-dessus dans le côté gauche du Playground et cliquez sur le bouton Play. Sur la droite, vous verrez le résultat de la requête :
Interrogeons maintenant cet utilisateur :
query { mysql_getUser(uuid: "f5593682-6bf1-466a-967d-98c7e9da844b") { Name UUID } }
Cela nous renvoie le nom et l'UUID de l'utilisateur que nous venons de créer. Soigné!
Nous pouvons faire de même avec les autres backends, PostgreSQL et Aurora. Pour cela, il suffit de remplacer les noms de la mutation par postgres_createUser ou aurora_createUser, et les requêtes par postgres_getUser ou aurora_getUser. Essayez-le vous-même ! (Gardez à l'esprit que les utilisateurs ne sont pas synchronisés entre les bases de données, vous ne pourrez donc interroger que les utilisateurs que vous avez créés dans chaque base de données spécifique.)
Comparaison des implémentations MySQL, PostgreSQL et Aurora
Pour commencer, les mutations et les requêtes se ressemblent exactement sur Aurora et MySQL, puisqu'Aurora est compatible avec MySQL. Et il n'y a que des différences de code minimes entre ces deux et l'implémentation de Postgres.
En fait, pour les cas d'utilisation simples, la plus grande différence entre nos trois bases de données est qu'Aurora n'est disponible qu'en tant que cluster. La plus petite configuration Aurora disponible comprend toujours un réplica en lecture seule et un réplica en écriture, nous avons donc besoin d'une configuration en cluster même pour ce déploiement Aurora de base.
Aurora offre des performances plus rapides que MySQL et PostgreSQL, principalement en raison des optimisations SSD qu'Amazon a apportées au moteur de base de données. Au fur et à mesure que votre projet grandit, vous constaterez probablement qu'Aurora offre une meilleure évolutivité de la base de données, une maintenance plus facile et une meilleure fiabilité par rapport aux configurations MySQL et PostgreSQL par défaut. Mais vous pouvez également apporter certaines de ces améliorations à MySQL et PostgreSQL si vous réglez vos bases de données et ajoutez la réplication.
Pour les projets de test et les terrains de jeux, nous recommandons MySQL ou PostgreSQL. Ceux-ci peuvent s'exécuter sur des instances RDS db.t2.micro, qui font partie de l'offre gratuite d'AWS. Aurora n'offre pas actuellement d'instances db.t2.micro, vous paierez donc un peu plus pour utiliser Aurora pour ce projet de test.
Une dernière remarque importante
N'oubliez pas de supprimer votre déploiement sans serveur une fois que vous avez fini d'essayer l'API GraphQL afin de ne pas continuer à payer pour les ressources de base de données que vous n'utilisez plus.
Vous pouvez supprimer la pile créée dans cet exemple en exécutant npm run remove à la racine du projet.
Bonne expérience !
Résumé
Dans cet article, nous vous avons expliqué comment créer une API GraphQL simple, en utilisant trois bases de données différentes à la fois ; bien que ce ne soit pas quelque chose que vous feriez jamais dans la réalité, cela nous a permis de comparer des implémentations simples des bases de données Aurora, MySQL et PostgreSQL. Nous avons vu que l'implémentation pour les trois bases de données est à peu près la même dans notre cas simple, à l'exception de différences mineures dans la syntaxe et les configurations de déploiement.
Vous pouvez trouver l'exemple de projet complet que nous avons utilisé dans ce dépôt GitHub. Le moyen le plus simple d'expérimenter le projet consiste à cloner le référentiel et à le déployer à partir de votre ordinateur à l'aide de npm run deploy.
Pour plus d'exemples d'API GraphQL utilisant Serverless, consultez le dépôt serverless-graphql.
Si vous souhaitez en savoir plus sur l'exécution d'API GraphQL sans serveur à grande échelle, vous pourriez apprécier notre série d'articles "Exécuter un point de terminaison GraphQL évolutif et fiable avec Serverless"
Peut-être que GraphQL n'est tout simplement pas votre truc et que vous préférez déployer une API REST ? Nous avons ce qu'il vous faut :consultez cet article de blog pour quelques exemples.
Des questions? Commentez ce message ou créez une discussion dans notre forum.
Publié à l'origine sur https://www.serverless.com.