Vous souhaitez apprendre à concevoir un système de base de données et mapper un processus métier à un modèle de données ? Alors ce poste est pour vous.
Dans cet article, vous verrez comment concevoir un schéma de base de données simple pour une société de recrutement. Après avoir lu ce didacticiel, vous serez en mesure de comprendre comment les schémas de base de données sont conçus pour les applications du monde réel.
Processus métier du système de recrutement
Avant de concevoir une base de données ou un modèle de données, il est impératif de comprendre le processus métier de base de ce système. Le schéma de base de données que nous allons créer est destiné à une société ou une équipe de recrutement imaginaire. Voyons d'abord les étapes nécessaires à l'embauche de nouveaux employés :
- Les entreprises contactent des agences de recrutement pour embaucher en leur nom. Dans certains cas, les entreprises recrutent directement leurs employés.
- La personne responsable du recrutement lance le processus de recrutement. Ce processus peut comporter plusieurs étapes, telles que la sélection initiale, un test écrit, le premier entretien, l'entretien de suivi, la décision d'embauche proprement dite, etc.
- Une fois que les recruteurs se sont mis d'accord sur un processus particulier - et cela peut changer selon le client, l'entreprise ou le poste en question - l'offre d'emploi est publiée sur différentes plateformes.
- Les candidats commencent à postuler pour le poste.
- Les candidats sont présélectionnés et invités à un test ou à un premier entretien.
- Les candidats se présentent pour le test/l'entretien.
- Les tests sont notés par les recruteurs. Dans certains cas, les tests sont transmis à des spécialistes pour notation.
- Les entretiens des candidats sont notés par un ou plusieurs recruteurs.
- Les candidats sont évalués sur la base de tests et d'entretiens.
- La décision d'embauche est prise.
Un schéma de base de données du système de recrutement
Compte tenu du processus susmentionné, notre schéma de base de données est divisé en cinq domaines :
ProcessJobsApplication, Applicant, and DocumentsTest and InterviewsRecruiters and Application Evaluation
Nous examinerons chacun de ces domaines en détail, dans l'ordre dans lequel ils sont répertoriés. Ci-dessous, vous pouvez voir l'intégralité du modèle de données.
Processus
La catégorie de processus contient des informations relatives aux processus de recrutement. Il contient trois tables :process , step , et process_step . Nous allons examiner chacun d'eux.
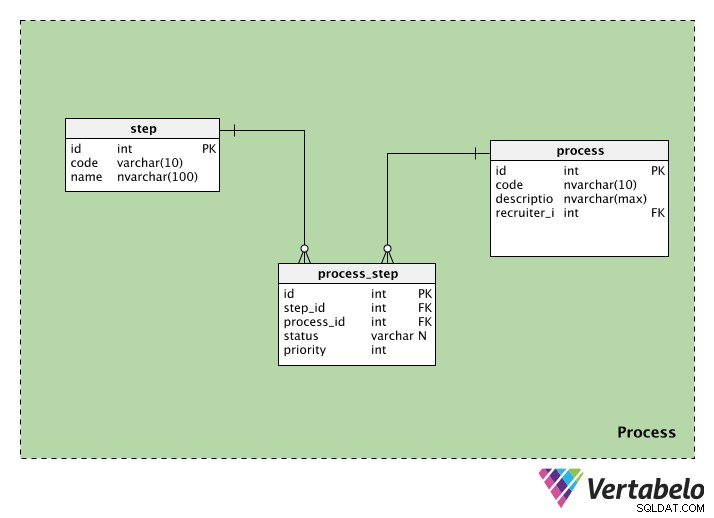
Le process table stocke des informations sur chaque processus de recrutement. Chaque processus aura un identifiant spécial, un code et une description de ce processus. Nous aurons également le recruiter_id de la personne qui initie le processus.
L'step Le tableau contient des informations sur les étapes suivies tout au long de ce processus de recrutement. Chaque étape a un id et un code Nom. La colonne de nom peut avoir des valeurs telles que "présélection initiale", "test écrit", "entretien RH", etc.
Puisqu'un processus peut avoir plusieurs étapes et qu'une étape peut faire partie de plusieurs processus, nous avons besoin d'une table de correspondance. Le process_step table contient des informations sur chaque étape (dans step_id ) et le processus auquel il appartient (dans process_id ). Nous avons également un statut, qui nous indique le statut de cette étape dans ce processus ; cela peut être NULL si l'étape n'a pas encore été démarrée. Enfin, nous avons une priority , qui nous indique dans quel ordre exécuter les étapes. Les étapes avec la plus haute priority valeur sera exécutée en premier.
Emplois
Ensuite, nous avons les Jobs domaine, qui stocke toutes les informations relatives au(x) poste(s) pour lequel(s) nous recrutons. Le schéma de cette catégorie ressemble à ceci :
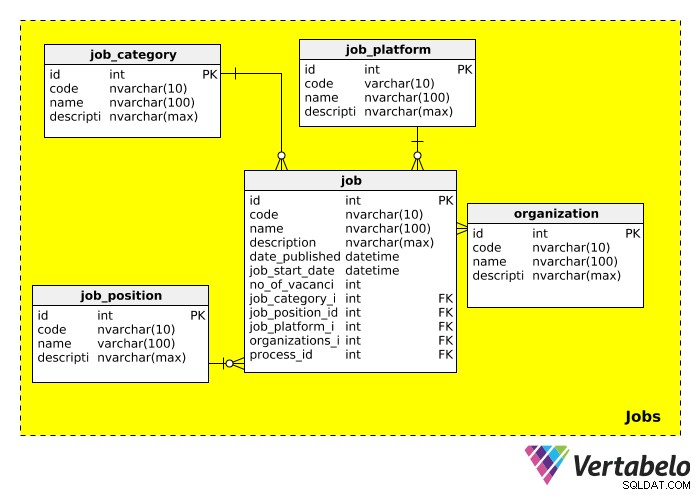
Expliquons chacun des tableaux en détail.
Le job_category tableau décrit en gros le type d'emploi. On pourrait s'attendre à voir des catégories d'emplois comme "IT", "management", "finance", "éducation", etc.
Le job_position table contient le titre du poste réel. Étant donné qu'un titre peut être publié pour plusieurs emplois (par exemple, "IT Manager", "Sales Manager"), nous avons créé un tableau séparé pour les postes. Nous pourrions nous attendre à voir des valeurs telles que « chef d'équipe informatique », « vice-président » et « responsable » dans ce tableau.
La job_platform Le tableau fait référence au support utilisé pour annoncer l'offre d'emploi. Par exemple, un emploi pourrait être affiché sur Facebook, un babillard d'emploi en ligne ou dans un journal local. Un lien vers cette offre d'emploi peut être ajouté dans la description domaine.
L'organization table stocke des informations sur toutes les entreprises qui ont déjà utilisé cette base de données dans le cadre de leur processus d'embauche. Évidemment, ce tableau est important lorsqu'on recrute pour une autre entreprise.
Le dernier tableau de ce domaine, job , contient la description de poste réelle. La plupart des attributs sont explicites. Il convient de noter que ce tableau comporte de nombreuses clés étrangères, ce qui signifie qu'il peut être utilisé pour rechercher la catégorie, le poste, la plate-forme, l'organisation d'embauche et le processus de recrutement lié à cette offre d'emploi.
Candidature, candidat et documents
La troisième partie du schéma se compose des tables qui stockent des informations sur les candidats, leurs candidatures et tous les documents accompagnant les candidatures.
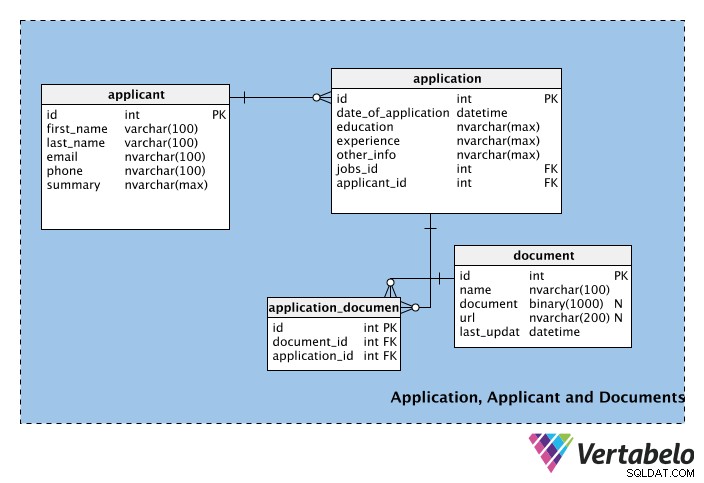
Le premier tableau, applicant , stocke les informations personnelles des candidats, telles que leur prénom, nom, e-mail, numéro de téléphone, etc. Le champ de résumé peut être utilisé pour stocker un bref profil du candidat (c'est-à-dire un paragraphe).
Le tableau suivant contient des informations pour chaque application , y compris sa date. Le tableau contient également l'experience et education Colonnes. Ces colonnes pourraient faire partie du applicant tableau, mais un candidat peut ou non vouloir afficher une qualification scolaire ou une expérience professionnelle particulière sur chaque candidature qu'il soumet. Par conséquent, ces colonnes font partie de l'application table. Les other_info La colonne stocke toute autre information relative à l'application. Dans l'application , jobs_id et candidate_id sont des clés étrangères des tables job et candidate, respectivement.
Étant donné qu'il peut y avoir plusieurs candidatures pour chaque emploi, mais que chaque candidature ne concerne qu'un seul emploi, il y aura une relation un-à-plusieurs entre les Jobs et applications les tables. De même, un candidat peut soumettre plusieurs candidatures (c'est-à-dire pour différents emplois), mais chaque candidature provient d'un seul participant ; nous avons mis en place une autre relation un-à-plusieurs entre les applicants et applications tables pour gérer cela.
Le document table gère les pièces justificatives que les candidats peuvent joindre à leur candidature. Il peut s'agir de CV, de curriculum vitae, de lettres de référence, de lettres de motivation, etc. Notez que ce tableau a une colonne binaire nommée document, qui stockera le fichier au format binaire. Un lien vers le document peut être stocké dans l'url domaine; la colonne name stocke le nom du document, et last_update signifie la version la plus récente téléchargée par le demandeur. Notez que les deux document et url sont nullables ; aucune des deux n'est obligatoire et un candidat peut choisir d'utiliser l'une ou l'autre ou les deux méthodes pour ajouter des informations à sa candidature.
Toutes les demandes ne seront pas accompagnées d'un document. Un document peut être joint à plusieurs demandes et une demande peut avoir plusieurs pièces justificatives. Cela signifie qu'il existe une relation plusieurs à plusieurs entre l'application et document les tables. Pour gérer cette relation, la table de correspondance application_document a été créé.
Tests et entretiens
Passons maintenant aux tableaux qui stockent les informations sur les tests et les entretiens liés au processus de recrutement.
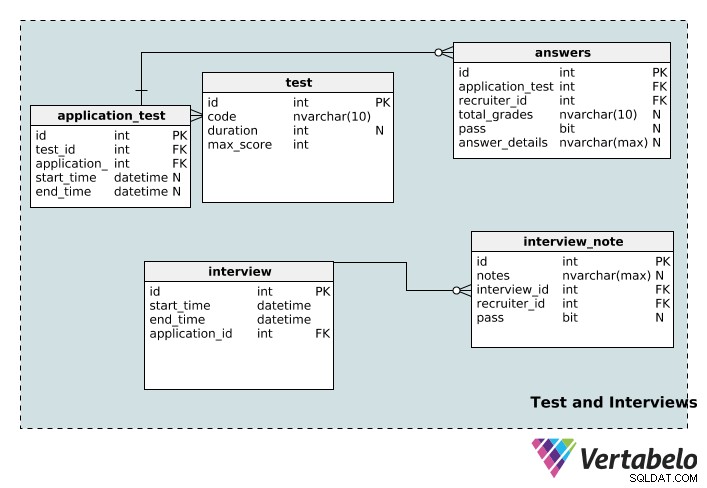
Le test la table stocke les détails du test, y compris son id unique , code nom, sa duration en minutes, et le maximum score possible pour ce test.
Une application peut être associée à plusieurs tests et un test peut être associé à plusieurs applications. Encore une fois, nous avons une table de recherche pour implémenter cette relation :application_test . Le start_time et end_time les colonnes sont nullables, car un test peut ne pas avoir de durée, d'heure de début ou d'heure de fin spécifique.
Un test peut être noté par plusieurs recruteurs et un recruteur peut noter plusieurs tests. Les answers table est la table qui rend cela possible. Les total_grades La colonne enregistre les résultats du candidat au test et la colonne de réussite indique simplement si cette personne a réussi ou échoué. Les détails de chaque test individuel sont enregistrés dans le answer_details colonne. Notez que ces trois colonnes acceptent les valeurs NULL ; un test de candidature peut être attribué à un recruteur qui ne l'a pas encore noté. De plus, un recruteur peut se voir attribuer un test avant qu'il ne soit réellement passé.
L'interview table stocke les informations de base (le start_time , end_time , un id unique , et le application_id correspondant ) pour chaque entretien. Un entretien ne peut être associé qu'à une seule candidature. D'autre part, une application peut avoir plusieurs entretiens. Par conséquent, une relation un-à-plusieurs existe entre l'application et la table d'entretien.
Une entrevue peut être menée par plusieurs évaluateurs, et un évaluateur peut prendre plusieurs entrevues. C'est une autre relation plusieurs-à-plusieurs, nous avons donc créé la table de recherche interview_note . Il stocke des informations sur l'entretien (dans interview_id ), le recruteur (en recruiter_id ) et les notes du recruteur sur l'entretien. Les recruteurs peuvent également enregistrer si le candidat a réussi ou non l'entretien dans la colonne de réussite, qui est nulle.
Évaluation et statut des candidatures des recruteurs
La dernière partie de notre modèle de recrutement stocke des informations sur les recruteurs, les statuts des candidatures et les évaluations des candidatures.
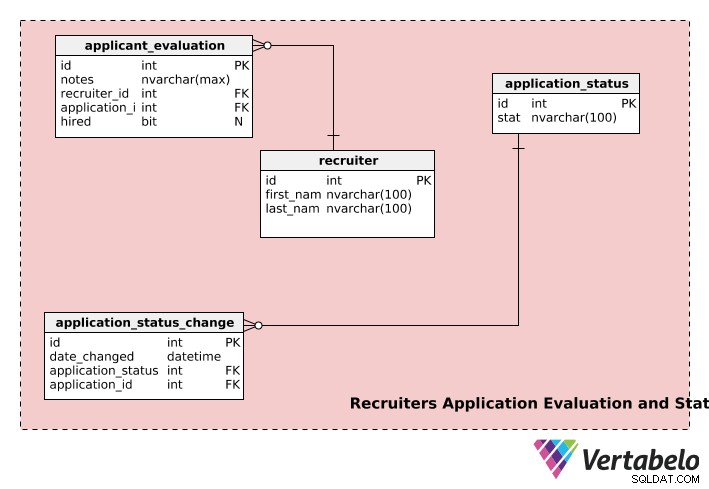
Les recruiters table stocke le first_name de chaque recruteur , last_name , et un id unique Numéro.
Le application_evaluation table contient des informations sur les évaluations des candidatures. En plus du application_id et recruiter_id , il contient les commentaires du recruteur (dans notes ) et la décision finale d'embauche, le cas échéant, dans hired . Une candidature peut être évaluée par plusieurs recruteurs et un recruteur peut évaluer plusieurs candidatures, de sorte que le recruiter et l'application table ont une relation un-à-plusieurs avec application_evaluation table.
Une candidature peut passer par plusieurs étapes au cours du processus d'embauche, par ex. "non soumise", "en cours d'examen", "en attente de décision", "décision prise", etc. Une candidature aura le statut "non_soumise" lorsque l'utilisateur a lancé une candidature mais ne l'a pas soumise aux recruteurs pour examen. Une fois la demande soumise, le statut passe à « en cours d'examen », et ainsi de suite. Le application_status table est utilisée pour stocker ces informations.
Le application_status_change Le tableau est utilisé pour conserver un enregistrement des changements de statut pour toutes les candidatures soumises. Le date_changed La colonne stocke la date du changement de statut. Ce tableau peut être utile si vous souhaitez analyser le temps de traitement pour chaque étape de différentes applications. De plus, le statut d'une colonne particulière peut être récupéré à l'aide de application_id colonne de application_status_change table.
Un cas d'utilisation simple pour le recrutement
Voyons comment notre base de données pourrait aider le processus de recrutement.
Supposons qu'une entreprise vous ait chargé d'embaucher un responsable informatique ayant une expérience en programmation. Notre base de données peut nous aider à embaucher une telle personne en exécutant les étapes suivantes :
- La première étape consiste à démarrer un nouveau processus de recrutement. Pour ce faire, les données sont saisies dans le
processetstepsles tables. Un recruteur peut ajouter autant d'étapes qu'il le souhaite. - Au cours de la tâche ci-dessus, le recruteur peut créer un nouvel emploi et entrer les détails dans le
job,job_category,job_position, etorganizationles tables. Enfin, une offre d'emploi sera placée sur l'une des plateformes stockées dans lejob_platformtableau. - Ensuite, les candidats créeront un profil en soumettant leurs données au
applicanttable. Ensuite, ils lanceront une nouvelle application en saisissant plus de données dans l'applicationtableau. - Les candidats peuvent également joindre des documents à leur candidature. Ces données seront stockées dans le
documentetapplication_documenttableaux. - Si un utilisateur souhaite postuler à plusieurs offres d'emploi, il répétera les étapes 3 et 4.
- Une fois la candidature soumise, le statut de la candidature sera défini sur "soumis" (ou un autre nom de statut choisi par le recruteur).
- Le recruteur évaluera la candidature et saisira ses commentaires dans le
application_evaluationtable. A ce stade, la colonne embauché ne contiendra aucune information. - Une fois qu'un nombre suffisant de candidatures est reçu, le recruteur exécutera l'étape suivante indiquée dans le
process_steptableau. - Si l'étape suivante consiste à administrer une sorte de test, le recruteur créera un test en ajoutant des données dans le
testtableau. - Le ou les tests créés à l'étape 9 seront affectés à une application particulière. Les informations qui attribuent chaque test à chaque application seront stockées dans le
application_testtable. Notez qu'à chaque étape, le statut de la demande changera constamment. Cela sera enregistré dans leapplication_status_changetableau. - Une fois que le candidat a terminé le test, les notes de chaque test de candidature seront notées par le recruteur et saisies dans le
answertableau. - Une fois le test passé, l'étape suivante à partir du
process_steptable sera exécutée. Disons que la prochaine étape est l'entretien. - Les données de l'entretien seront saisies dans l'
interviewtable. Le recruteur saisira ses commentaires et dira si la personne a réussi l'entretien ou non. Cela sera stocké dans leinterview_notetableau. - Si le
processtable contient d'autres étapes d'interview et de test, elles seront exécutées jusqu'à ce que la dernière étape soit atteinte. - La dernière étape du
process_steptable est normalement la décision d'embauche. Si le candidat réussit ses tests et entretiens et que l'entreprise décide de l'embaucher, les données sont saisies dans la colonne d'embauche de l'application_evaluationtable et la personne est embauchée.
Que pensez-vous du modèle de données de notre système de recrutement ?
Dans cet article, nous avons vu comment créer un schéma de base de données très simple pour un système de recrutement. Nous avons divisé le schéma en quatre catégories, puis expliqué chacune d'elles en détail. Enfin, nous avons exécuté un cas d'utilisation pour montrer que notre schéma peut réellement aider à recruter un employé.
Les travaux de conception de bases de données sont en plein essor. Vous souhaitez ajouter à vos compétences en matière de base de données ? Que vous soyez un nouveau venu cherchant à apprendre les bases de SQL ou un professionnel chevronné souhaitant se lancer dans la création de tables en SQL | Cours interactif | Vertabelo Academy" target="_blank">conception de bases de données, consultez les cours à votre rythme de LearnSQL.com.