Comment toutes ces données sur l'opinion publique sont-elles stockées ? Nous vérifions un modèle de données de sondage d'opinion.
Tout le monde veut savoir ce que pense le public, des politiciens et des entreprises aux particuliers qui veulent savoir ce que les autres pensent sur un certain sujet. Ce type de travail est généralement effectué par des agences spécialisées dans ce type de recherche.
Aujourd'hui, nous allons examiner un modèle de données qu'une telle agence pourrait utiliser pour stocker toutes les données de sondage pertinentes, des questions et des réponses prédéfinies aux commentaires réels. Ces données seraient ensuite utilisées pour créer divers rapports. Alors, commençons.
Idée
Les sondages peuvent être créés n'importe où. Ils pourraient être bien planifiés et inclure un échantillon représentatif du public (basé sur la démographie). Ou vous pouvez les faire sur place, par ex. si vous voulez prédire les résultats des élections sur la base d'un échantillon (comme un sondage de sortie), vous demanderez probablement aux gens du bureau de vote comment ils ont voté.
D'autre part, si vous souhaitez créer le même sondage avant l'élection, vous sélectionnerez probablement un échantillon et contacterez les personnes par téléphone ou en personne. Habituellement, il n'y a que quelques questions pour ce type de sondage - certaines pour couvrir les données démographiques et d'autres pour couvrir ce qui nous intéresse vraiment.
Les sondages peuvent également être beaucoup plus complexes, par ex. si vous souhaitez connaître l'opinion publique sur un certain produit, couvrant tout, de ses performances à son emballage.
Dans cet article, je ne discuterai pas de la manière de sélectionner un échantillon de personnes ; je vais plutôt me concentrer sur le sondage lui-même, ses questions et les réponses.
Modèle de données
Modèle de données des agences d'opinion publique
Le modèle se compose de trois domaines :
PollsQuestions & AnswersResult
Nous décrirons chaque domaine dans l'ordre dans lequel il est répertorié.
Sondages
Avant de commencer à poser des questions, nous devons définir ce qui nous intéresse. Nous définirons les sondages et les questionnaires dans cette section, puis ajouterons des questions et des réponses dans la suivante.
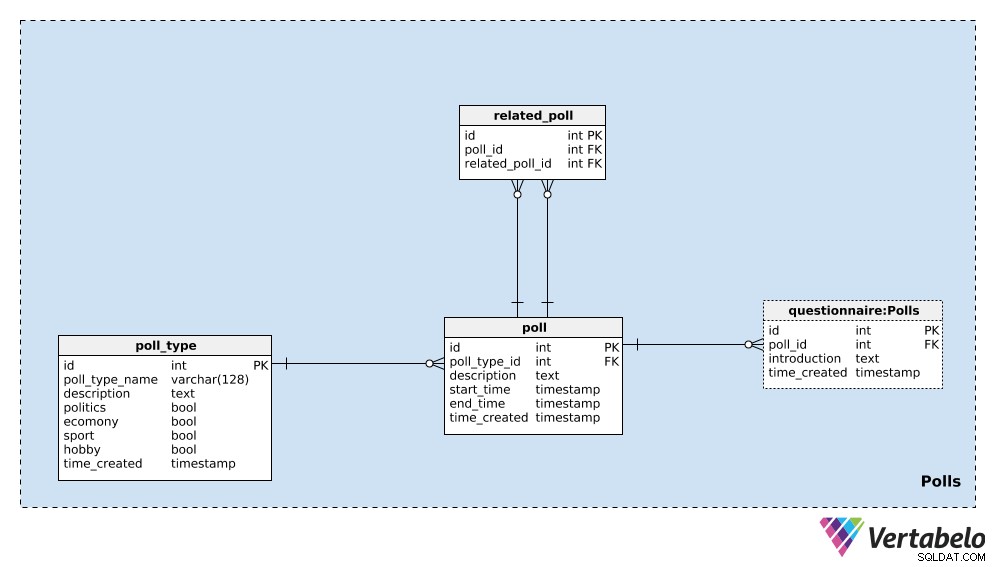
Nous allons commencer par le poll_type dictionnaire. Nous pouvons nous attendre à répéter principalement des sondages du même type. Le type le plus courant est probablement les sondages électoraux, mais nous voulons pouvoir ajouter de nouveaux types de sondages en cours de route. Pour chaque type de sondage, nous stockerons un poll_type_name UNIQUE et utilisez la description attribut pour fournir des détails supplémentaires.
Quatre drapeaux – politics , economy , sport , et hobby – sont utilisés pour indiquer le type de sondage. Un sondage pourrait couvrir un ou plusieurs de ces sujets; si nécessaire, nous pourrions diviser ces catégories dans un dictionnaire séparé et avoir une relation plusieurs à plusieurs entre ce dictionnaire et le poll_type tableau.
Le dernier attribut de ce tableau est time_created . Il indique le moment où une ligne est insérée dans ce tableau.
La prochaine chose que nous devons faire est de définir un seul poll . Il s'agit d'une instance unique, par ex. "Élection présidentielle américaine de 2020 – Sondage d'avril 2020" . Pour chaque sondage, nous stockerons les détails suivants :
poll_type_id– Une référence aupoll_type.description– Tous les détails liés à ce sondage, au format texte.start_timeetend_time- Les heures de début et de fin définies, pendant lesquelles ce sondage est effectué.time_created– Le moment réel où ce sondage a été créé.
Les sondages peuvent être liés les uns aux autres. Dans l'exemple de l'"élection présidentielle américaine 2020 - sondage d'avril 2020" , nous pourrions faire le même sondage le mois prochain pour voir les opinions les plus actuelles. Nous appellerions cela "Élection présidentielle américaine 2020 - Sondage de mai 2020" . Ces deux sondages sont liés car leurs résultats montrent des tendances. Pour établir cette relation, nous utiliserons le related_poll table dans notre modèle. Il contient uniquement la paire UNIQUE de poll_id – related_poll_id , désignant le scrutin et son prédécesseur.
Notez que nous pourrions utiliser cette table pour stocker tous les sondages qui sont liés de quelque manière que ce soit, pas seulement les prédécesseurs/successeurs. Si nous voulions définir différentes relations, nous aurions besoin d'ajouter un autre dictionnaire - mais nous n'irons pas dans cette direction dans cet article.
Le dernier tableau de ce domaine est le questionnaire table. Dans la plupart des cas, chaque sondage aura exactement un questionnaire, mais je veux laisser l'option que nous pourrions en avoir plus d'un si nécessaire. Par conséquent, j'ai utilisé un tableau séparé. Dans ce tableau, nous stockerons uniquement l'ID du sondage associé (poll_id ), une introduction décrivant ce questionnaire, et l'horodatage auquel l'enregistrement a été inséré (time_created ).
Questions et réponses
Nous sommes maintenant prêts à créer tous les détails du questionnaire. Nous pouvons également lister toutes les questions que nous voulons poser ainsi que toutes les réponses prédéfinies.
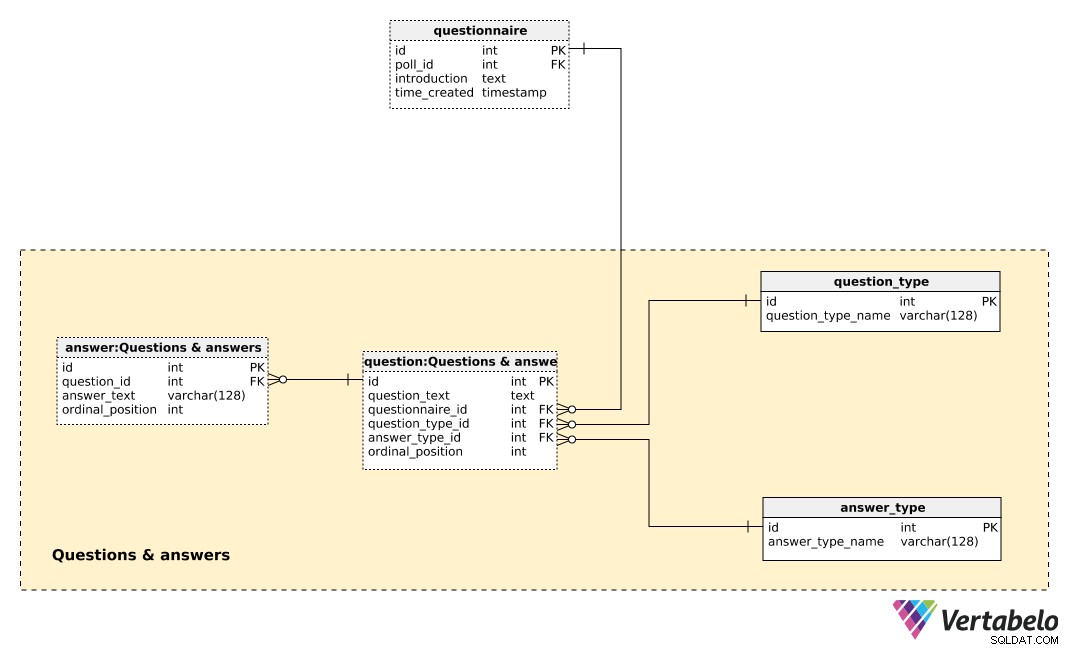
Le tableau central dans ce domaine est la question table. Chaque question est définie par les détails suivants :
question_text– Un texte qui sera affiché à chaque personne interrogée.questionnaire_id– Une référence désignant le questionnaire de cette question.question_type_id– Une référence indiquant lequestion_type, qui est désigné UNIQUEMENT par lequestion_type_name. Ce sont essentiellement des catégories, par ex. "démographie", "opinion", "contrôle", etc. Cela nous permettrait de séparer les questions démographiques et d'opinion et de trouver une corrélation entre elles.answer_type_id– Une référence au type de réponse qui sera utilisé pour cette question. Chaqueanswer_typeest UNIQUEMENT défini par leanswer_type_nameet indique comment la réponse est affichée. Certains types attendus sont "ouvert", "liste", "case à cocher" et "multiple".ordinal_position– Cette valeur indique la position de cette question dans le questionnaire. Avec lequestionnaire_id, il constitue la clé alternative de cette table.
Une liste de toutes les réponses prédéfinies est stockée dans le answer table. Si le type de question n'est pas ouvert (c'est-à-dire que le texte ne sera pas saisi par l'individu), nous aurons un ensemble de réponses prédéfinies. Pour chaque réponse, nous définirons la question à laquelle elle appartient (question_id ), le answer_text , et la ordinal_position de cette réponse à l'intérieur de cette question. Encore une fois, une paire UNIQUE – cette fois question_id – ordinal_position – forme la clé alternative de cette table.
Résultat
Dans les deux domaines précédents, nous avons défini tout ce dont nous avons besoin pour créer le sondage et commencer à poser des questions. Nous devons maintenant définir une structure de données pour stocker les réponses réelles.
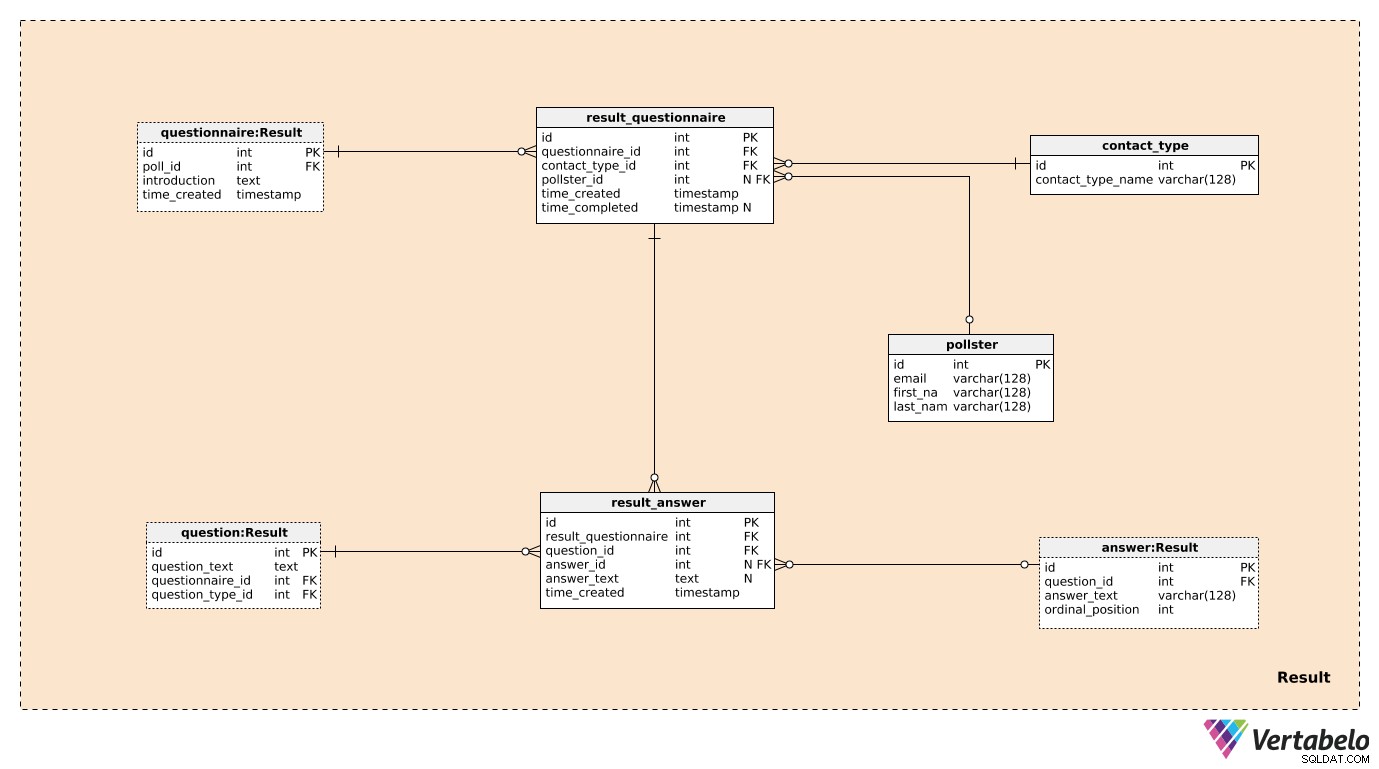
Trois des sept tableaux du Result domaine ont été précédemment mentionnés et décrits. Ce sont des questionnaire , question , et answer . Les quatre tables restantes sont utilisées pour stocker ce qui nous intéresse vraiment.
Nous allons créer un enregistrement dans le result_questionnaire tableau pour chaque individu participant au sondage. Le questionnaire_id fournissez à esus toutes les informations sur le sondage concerné. Le contact_type_id est une référence au contact_type dictionnaire. Les valeurs de ce tableau décrivent la façon dont nous avons interagi avec cette personne. Ces valeurs sont UNIQUEMENT définies par le contact_type_name valeur et pourrait être quelque chose comme « téléphone », « en personne », « e-mail », « formulaire Web », etc.
Le pollster_id l'attribut est une référence au pollster tableau, qui fournit les informations sur qui a mené ce sondage réel. Pour chaque pollster , nous ne conserverons que leur e-mail UNIQUE et leur first_name et last_name . Le time_created l'attribut indique l'heure réelle à laquelle cet enregistrement a été créé, tandis que l'attribut time_completed seront fixés au moment où cette enquête sera terminée. (En attendant, il sera NULL).
La dernière table du modèle est le result_answer table. Comme son nom l'indique, c'est ici que nous stockerons les réponses réelles que nous avons obtenues des personnes interrogées. Pour chaque enregistrement de ce tableau, nous aurons :
result_questionnaire_id– Une référence au questionnaire pertinent.question_id– Une référence désignant la question à laquelle répond cette réponse.answer_id– Une référence à la réponse qui a été utilisée pour répondre à cette question. Cet attribut contiendra une valeur NULL lorsque la question est de type "ouverte" (car il n'y avait pas de réponses prédéfinies parmi lesquelles choisir).answer_text– Le texte qui a été inséré pour répondre à cette question. Cet attribut contiendra une valeur lorsque la question était « ouverte »; dans tous les autres cas, ce sera NULL.time_created– L'heure réelle à laquelle cette réponse a été insérée dans notre système.
Améliorations possibles
Jusqu'à présent, nous avons expliqué comment stocker les données de sondage. Nous n'avons pas discuté de ce que nous ferions des données après la clôture du sondage. Nous pouvons nous attendre à ne plus avoir besoin des anciennes données à l'avenir, du moins pas dans notre base de données opérationnelle. Par conséquent, nous pourrions faire deux choses :
- Stocker un résumé de sondage dans une table séparée dans la base de données opérationnelle. Cela garderait ces informations à notre disposition si nous voulions voir ce qui s'est passé avec un sondage similaire.
- Stocker toutes les données de sondage dans une base de données de sauvegarde ayant la même structure que la base de données opérationnelle. Cela nous permettrait d'accéder aux détails lorsque nous en avions besoin.
Nous pourrions également créer un entrepôt de données pour stocker les résultats des sondages, mais cela ne serait pas nécessaire si nous avions déjà effectué les tâches décrites dans les deux puces.
Que pensez-vous de notre modèle de données de sondage d'opinion ?
Nous aimerions connaître votre opinion sur ce que nous pourrions changer pour améliorer le modèle de données des sondages d'opinion. Avez-vous de l'expérience dans l'industrie? Pensez-vous que nous avons raté quelque chose? Souhaitez-vous ajouter ou supprimer quelque chose ? Au plaisir d'entendre vos opinions.