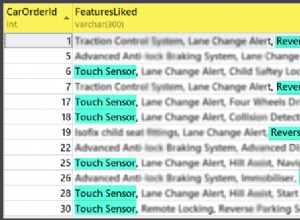
BigQuery est un entrepôt de données géré et sans serveur dans Google Cloud, conçu pour permettre une analyse évolutive sur des pétaoctets de données. Il s'agit d'une plate-forme de base de données relationnelle en tant que service (PaaS) qui prend en charge les requêtes SQL ANSI. En tant que tel, il fonctionne avec le logiciel IRI.
BigQuery est un entrepôt de données géré et sans serveur dans Google Cloud, conçu pour permettre une analyse évolutive sur des pétaoctets de données. Il s'agit d'une plate-forme de base de données relationnelle en tant que service (PaaS) qui prend en charge les requêtes SQL ANSI. En tant que tel, il fonctionne avec le logiciel IRI.
La connexion de Google BigQuery RDB à IRI Workbench et au programme de traitement back-end SortCL est simple et permet le déplacement et la manipulation de ses données structurées via des produits IRI compatibles. Cela signifie IRI CoSort, FieldShield, NextForm et RowGen, ou la plate-forme IRI Voracity qui les inclut tous.
La connectivité suit le même paradigme que toutes les autres bases de données relationnelles prises en charge par IRI. Cela signifie le téléchargement et l'installation des pilotes ODBC et JDBC, la configuration (utilisation et test avec vos informations d'identification), l'enregistrement et la validation.
Comme Workbench est basé sur Eclipse, il a besoin d'une connexion JDBC pour afficher le schéma BigQuery et analyser les métadonnées de la table. Et pour transmettre des données entre BigQuery et le moteur de manipulation de données SortCL, un pilote ODBC est également nécessaire. Le résultat final pourrait être ceci :

Google s'est associé à Magnitude Simba pour fournir des pilotes ODBC et JDBC pour se connecter à BigQuery. Au moment d'écrire ces lignes, cependant, son pilote JDBC manque des fonctions clés dont Workbench a besoin. Pour contourner ce problème, utilisez le pilote JDBC de CData.
Cet article fournit des instructions détaillées permettant au logiciel IRI d'accéder à BigQuery.
Comptes de service dans BigQuery
BigQuery autorise l'accès aux ressources sur la base d'une identité vérifiée, qui nécessite un ID utilisateur sous la forme d'un compte de service et d'une clé/mot de passe. Pour créer une identité validée, connectez-vous à BigQuery, accédez à Comptes de service sous IAM et administrateur, puis créez un compte :

Le premier champ crée le nom du compte de service, pour ma configuration, je l'ai appelé iri-simba. Le deuxième champ sera automatiquement rempli avec une adresse e-mail de compte de service en utilisant le nom que vous avez choisi. Le dernier champ peut être ignoré. Cliquez sur Créer et continuer.
Maintenant qu'un compte de service est créé, nous pouvons passer au type d'autorisations que ce compte peut avoir. Cliquez sur Sélectionner un rôle et recherchez BigQuery pour ajouter des rôles spécifiques pour la base de données.

En survolant chaque rôle, vous obtiendrez une description rapide du type d'accès que ce rôle donnera au compte de service ; trouver une explication plus détaillée ici. Cela permet un meilleur contrôle sur l'octroi d'autorisations à des utilisateurs spécifiques, comme la possibilité d'afficher des tables, de créer des requêtes ou de s'exécuter en tant qu'administrateur.
J'ai choisi le rôle d'utilisateur BigQuery, qui permettra à ce compte de service d'afficher et de manipuler des tables. L'option "Autoriser l'utilisateur à accéder à ce compte de service" est ignorée. Cliquez sur Terminé vous ramène à la page principale du compte de service où vous pouvez voir le compte :

Passons à la deuxième partie, créons la clé qui sera associée au nouveau compte de service. Dans le champ Action, cliquez sur Gérer les clés pour créer la clé du compte de service, soit en ajoutant votre propre clé, soit en la faisant créer pour vous.
Si Google crée votre clé, il vous présentera deux options de type de clé, JSON ou P12. Choisissez le type JSON car cette clé sera également utilisée pour le pilote JDBC qui utilise le format JSON.
Lorsque la clé JSON est créée, elle sera téléchargée sur l'ordinateur. Vous pouvez le placer où vous voulez, mais souvenez-vous du chemin car il sera utilisé lors de la configuration des pilotes ODBC et JDBC.
Maintenant que le compte de service a été créé et dispose d'une clé qui servira de mot de passe, passons au téléchargement de la connexion ODBC et à sa configuration.
ODBC – Téléchargement et configuration
J'utilise un système d'exploitation Windows et je choisis la version Windows 64 bits pour la compatibilité avec l'exécutable CoSort V10.5 SortCL. Une fois que vous avez suivi les instructions et accepté le contrat de licence pour le programme d'installation Simba, ouvrez l'administrateur de source de données ODBC (64 bits) pour configurer la connexion.

Ajoutez simplement et recherchez le pilote nommé "Pilote ODBC Simba pour Google BigQuery".

Avec le pilote sélectionné, la page de configuration devrait ressembler à ceci :

Ici, la configuration est vraiment simple, en commençant par le nom de la source de données.
J'ai choisi le nom Google BigQuery, mais vous pouvez choisir n'importe quel nom pour votre cas d'utilisation.
Pour l'authentification, conservez l'option par défaut Compte de service et passez à l'e-mail. Ici, vous pouvez copier et coller l'e-mail du compte de service qui a été créé précédemment dans cet article.
Le champ ci-dessous (Key File Path) utilise le chemin d'accès au fichier de clé JSON comme entrée. En bas où il est indiqué Catalogue (Projet), cliquez sur le menu déroulant. Si tout est configuré correctement, il doit afficher le nom du projet et du nœud contenant les jeux de données et les tables.
Vous pouvez faire la même chose pour l'option Jeu de données, cliquez sur le menu déroulant pour sélectionner un jeu de données spécifique ou laissez ce champ vide pour voir tous les jeux de données de ce projet. Testez enfin la connexion pour vous assurer que tout fonctionne correctement.
Lorsque ODBC est configuré, nous pouvons configurer le pilote JDBC.
JDBC – Téléchargement et configuration
Téléchargez le pilote JDBC à partir de CData ici. Une fois l'installation terminée, il y aura un dossier appelé GoogleBigQueryJDBCDriver avec un setup.jar à l'intérieur.
Le fichier setup.jar installera tous les fichiers nécessaires au fonctionnement de la connexion JDBC. Il contient également un fichier JAR spécial pour aider à créer l'URL de connexion pour le pilote JDBC.
Une fois que setup.jar a terminé l'installation, nous devons préparer les configurations dans Workbench. Dans l'explorateur de sources de données (à l'intérieur de Workbench), ajoutez une nouvelle connexion en cliquant sur Nouveau profil de connexion .

Une pop apparaîtra (comme l'image ci-dessous) et donnera plusieurs options sur le type de connexions qui peuvent être créées. Sélectionnez le JDBC générique et donnez-lui un nom tel que BigQuery, cela le rendra facile à repérer dans l'explorateur de sources de données.

La page suivante vous demandera de configurer le pilote et de fournir les détails de connexion. Cliquez sur Nouvelle définition de pilote qui ressemble à une boussole avec un signe plus vert.

La page suivante vous permet de donner un nom spécifique au pilote si vous le souhaitez. En passant à l'onglet Liste JAR, c'est là que les fichiers JAR requis sont ajoutés pour que le pilote JDBC fonctionne.
Si l'emplacement par défaut a été utilisé lors de l'installation des fichiers du pilote JDBC, il doit se trouver dans le dossier Program Files avec le nom CData. Dans le dossier lib se trouve un fichier Jar appelé cdata.jdbc.googlebigquery.GoogleBigQueryDriver , ajoutez ce pot à la liste et passez à l'onglet Propriétés.
*Le chemin par défaut est visible dans l'image ci-dessous en cas de problème pour localiser le fichier jar*

Dans l'onglet Propriétés, nous devons créer une URL de connexion, donner un nom à la base de données et spécifier la classe de pilote. En vous concentrant d'abord sur la création de l'URL de connexion, dans l'explorateur de fichiers, localisez le fichier jar qui vient d'être ajouté et exécutez-le.
Cela aidera à créer l'URL de connexion dans le format suggéré par CData. Comme le montre l'image ci-dessous, il y a des propriétés sur la gauche qui doivent être définies afin de créer l'URL de connexion.

CData dispose d'une documentation sur les propriétés à définir en fonction de la manière dont l'utilisateur a choisi de s'authentifier. Étant donné que nous nous authentifions avec un compte de service, les propriétés qui doivent être définies sont répertoriées ci-dessous.
- AuthScheme – Définir sur OAuthJWT
- ID de projet :situé sur la page d'accueil de BigQuery
- InitiateOAuth – Définir sur GETANDREFRESH
- OAuthJWTCertType – Définir sur GOOGLEJSON
- OAuthJWTCert – Chemin d'accès au fichier .json fourni par Google
Une fois toutes les propriétés définies, testez la connexion pour vous assurer que tout fonctionne. En cas de succès, copiez la chaîne de connexion en bas. Si vous quittez sans copier l'URL de connexion, vous devrez redéfinir les propriétés.
De retour dans Workbench, collez l'URL à côté de la propriété URL de connexion et ajoutez le nom de la base de données pour la propriété Nom de la base de données. Pour la propriété Classe de pilote, il y a un bouton avec trois points dans le champ vide.
Cliquez dessus et cela vous donnera la possibilité d'entrer le nom de la classe de pilote ou de lui faire scanner la liste JAR pour le pilote. Une fois que tout est terminé, cela devrait ressembler à ceci :

Cliquez sur OK et vous serez renvoyé à la page "Spécifier un pilote et les détails de connexion". Il n'est pas nécessaire d'ajouter un nom d'utilisateur ou un mot de passe car toutes les informations sont dans l'URL de connexion. Testez la connexion une dernière fois et cliquez sur Terminer.
Le profil de connexion sera désormais visible dans l'explorateur de sources de données et les schémas/tables seront visibles une fois que vous aurez fait un clic droit sur le profil et choisi de se connecter.

La dernière tâche consiste à créer un registre de connexion de données qui mappe le DSN au profil de connexion qui vient d'être créé. Allez dans le menu IRI, sélectionnez les préférences et localisez le registre de connexion de données comme le suggère l'image ci-dessous.

A gauche se trouve le DSN et à droite se trouvent les profils de connexion. Localisez le DSN créé dans la section ODBC ci-dessus et cliquez sur Modifier…. Sélectionnez le DSN, la version et le profil de connexion.

Étant donné que le DSN a les informations d'identification enregistrées dans l'URL de connexion, il n'est pas nécessaire de s'authentifier avec un utilisateur/mot de passe. Cliquez sur OK et Appliquer et fermer pour quitter le menu.
Vous avez maintenant terminé les étapes de connectivité de la base de données pour Google BigQuery. Si vous avez besoin d'aide, envoyez un e-mail à support@iri.com.