La discussion sur la différence de préférence entre FOREACH et FOR n'est pas nouvelle. Nous savons tous que FOREACH est plus lent, mais nous ne savons pas tous pourquoi.
Quand j'ai commencé à apprendre .NET, une personne m'a dit que FOREACH est deux fois plus lent que FOR. Il a dit cela sans aucun fondement. Je l'ai pris pour acquis.
Finalement, j'ai décidé d'explorer la différence de performance des boucles FOREACH et FOR et d'écrire cet article pour discuter des nuances.
Examinons le code suivant :
foreach (var item in Enumerable.Range(0, 128))
{
Console.WriteLine(item);
}Le FOREACH est une syntaxe sucre. Dans ce cas particulier, le compilateur le transforme en le code suivant :
IEnumerator<int> enumerator = Enumerable.Range(0, 128).GetEnumerator();
try
{
while (enumerator.MoveNext())
{
int item = enumerator.Current;
Console.WriteLine(item);
}
}
finally
{
if (enumerator != null)
{
enumerator.Dispose();
}
}Sachant cela, nous pouvons supposer la raison pour laquelle FOREACH est plus lent que FOR :
- Un nouvel objet est en cours de création. Il s'appelle Créateur.
- La méthode MoveNext est appelée à chaque itération.
- Chaque itération accède à la propriété Current.
C'est ça! Cependant, tout n'est pas aussi simple qu'il y paraît.
Heureusement (ou malheureusement), C#/CLR peut effectuer des optimisations au moment de l'exécution. Le pro est que le code fonctionne plus rapidement. L'inconvénient :les développeurs doivent être conscients de ces optimisations.
Le tableau est un type profondément intégré dans CLR, et CLR fournit un certain nombre d'optimisations pour ce type. La boucle FOREACH est une entité itérable, qui est un aspect clé de la performance. Plus loin dans l'article, nous verrons comment parcourir des tableaux et des listes à l'aide de la méthode statique Array.ForEach et de la méthode List.ForEach.
Méthodes de test
static double ArrayForWithoutOptimization(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
for (int i = 0; i < array.Length; i++)
sum += array[i];
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForWithOptimization(int[] array)
{
int length = array.Length;
int sum = 0;
var watch = Stopwatch.StartNew();
for (int i = 0; i < length; i++)
sum += array[i];
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForeach(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
foreach (var item in array)
sum += item;
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForEach(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
Array.ForEach(array, i => { sum += i; });
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}Conditions d'essai :
- L'option "Optimiser le code" est activée.
- Le nombre d'éléments est égal à 100 000 000 (à la fois dans le tableau et dans la liste).
- Spécification du PC :Intel Core i-5 et 8 Go de RAM.
Tableaux
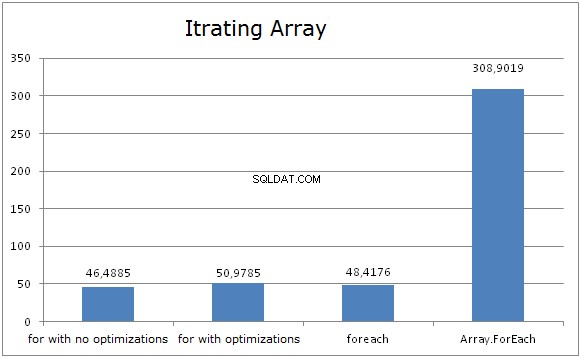
Le diagramme montre que FOR et FOREACH passent le même temps lors de l'itération dans les tableaux. Et c'est parce que l'optimisation CLR convertit FOREACH en FOR et utilise la longueur du tableau comme limite d'itération maximale. Peu importe que la longueur du tableau soit mise en cache ou non (lorsque vous utilisez FOR), le résultat est presque le même.
Cela peut sembler étrange, mais la mise en cache de la longueur du tableau peut affecter les performances. Lors de l'utilisation de tableau .Length comme limite d'itération, JIT teste l'index pour atteindre la bordure droite au-delà du cycle. Cette vérification n'est effectuée qu'une seule fois.
Il est très facile de détruire cette optimisation. Le cas où la variable est mise en cache n'est guère optimisé.
Tableau.foreach ont montré les pires résultats. Sa mise en œuvre est assez simple :
public static void ForEach<T>(T[] array, Action<T> action)
{
for (int index = 0; index < array.Length; ++index)
action(array[index]);
}Alors pourquoi tourne-t-il si lentement ? Il utilise FOR sous le capot. Eh bien, la raison est d'appeler le délégué ACTION. En fait, une méthode est appelée à chaque itération, ce qui diminue les performances. De plus, les délégués ne sont pas invoqués aussi rapidement que nous le souhaiterions.
Listes

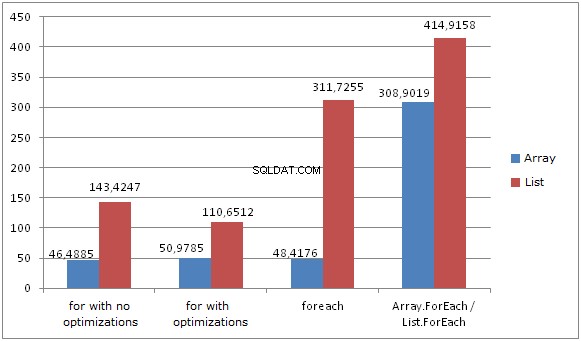
Le résultat est complètement différent. Lors de l'itération de listes, FOR et FOREACH affichent des résultats différents. Il n'y a pas d'optimisation. FOR (avec mise en cache de la longueur de la liste) affiche le meilleur résultat, tandis que FOREACH est plus de 2 fois plus lent. C'est parce qu'il traite de MoveNext et Current sous le capot. List.ForEach ainsi que Array.ForEach affichent le pire résultat. Les délégués sont toujours appelés virtuellement. L'implémentation de cette méthode ressemble à ceci :
public void ForEach(Action<T> action)
{
int num = this._version;
for (int index = 0; index < this._size && num == this._version; ++index)
action(this._items[index]);
if (num == this._version)
return;
ThrowHelper.ThrowInvalidOperationException(ExceptionResource.InvalidOperation_EnumFailedVersion);
}Chaque itération appelle le délégué Action. Il vérifie également si la liste est modifiée et si c'est le cas, une exception est levée.
La liste utilise en interne un modèle basé sur un tableau et la méthode ForEach utilise l'index du tableau pour itérer, ce qui est beaucoup plus rapide que d'utiliser l'indexeur.
Numéros spécifiques
- La boucle FOR sans mise en cache de longueur et FOREACH fonctionnent légèrement plus rapidement sur les tableaux que FOR avec mise en cache de longueur.
- Tableau.Pour chaque performances est environ 6 fois plus lent que les performances FOR / FOREACH.
- La boucle FOR sans mise en cache de la longueur fonctionne 3 fois plus lentement sur les listes que sur les tableaux.
- La boucle FOR avec mise en cache de la longueur fonctionne 2 fois plus lentement sur les listes que sur les tableaux.
- La boucle FOREACH fonctionne 6 fois plus lentement sur les listes que sur les tableaux.
Voici un classement pour les listes :
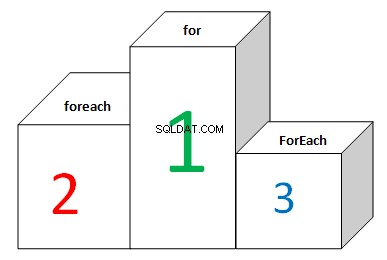
Et pour les tableaux :
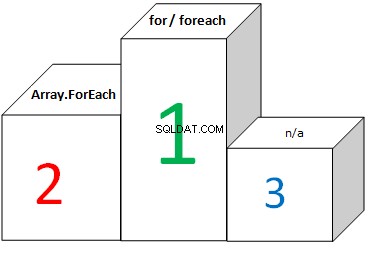
Conclusion
J'ai vraiment apprécié cette enquête, en particulier le processus d'écriture, et j'espère que vous l'avez également apprécié. Il s'est avéré que FOREACH est plus rapide sur les tableaux que FOR avec la poursuite de la longueur. Sur les structures de liste, FOREACH est plus lent que FOR.
Le code a meilleure apparence lors de l'utilisation de FOREACH, et les processeurs modernes permettent de l'utiliser. Cependant, si vous avez besoin d'optimiser fortement votre base de code, il est préférable d'utiliser FOR.
Qu'en pensez-vous, quelle boucle tourne le plus vite, FOR ou FOREACH ?