Ceci est la 4ème et dernière partie de la série Benchmarking Managed PostgreSQLCloud Solutions . Au moment d'écrire ces lignes, Microsoft Azure PostgreSQL était à la version 10.7, plus récente que les deux concurrents :Amazon Aurora PostgreSQL à la version 10.6 et Google Cloud SQL pour PostgreSQL à la version 9.6.
Microsoft a décidé d'exécuter Azure PostgreSQL sur Windows :
postgres=> select version();
version
------------------------------------------------------------
PostgreSQL 10.7, compiled by Visual C++ build 1800, 64-bit
(1 row)Pour ce test particulier qui n'a pas trop bien fonctionné, et je risque de deviner que Microsoft est bien conscient des limitations, la raison pour laquelle sous l'égide de PostgreSQL, ils proposent également une version d'aperçu de la version Citus Data de PostgreSQL. L'approche ressemble aux saveurs AWS PostgreSQL, RDS et Aurora respectivement.
En passant, lors de la configuration de mon compte Azure, j'ai été surpris par le manque d'authentification 2FA/MFA (Two-Factor/Multi-Factor) que j'ai pris comme acquis avec AWS Virtual MFA d'Amazon et la vérification en 2 étapes de Google. Microsoft propose l'authentification MFA uniquement aux entreprises clientes abonnées à Active Directory ou Office 365. Étant donné que Citus Cloud applique 2FA pour la base de données de production, Microsoft n'est peut-être pas si loin de l'implémenter dans Azure.
TL;DR
Il n'y a pas de résultats pour Azure. Sur l'instance de base de données à 8 cœurs, identique en nombre de cœurs à ceux utilisés sur AWS et G Cloud, les tests ont échoué en raison d'erreurs de base de données. Sur une instance à 16 cœurs, pgbench s'est terminé et sysbench est allé jusqu'à créer les 3 premières tables, auquel cas j'ai interrompu le processus. Bien que j'étais prêt à consacrer une quantité raisonnable d'efforts, de temps et d'argent à l'exécution des tests et à la documentation des erreurs et de leurs causes, l'objectif de cet exercice était d'exécuter le test de référence. Par conséquent, je n'ai jamais envisagé de poursuivre un dépannage avancé ou de contacter Assistance Azure, et je n'ai pas non plus terminé le test sysbench sur la base de données à 16 cœurs.
Instances cloud
Client
L'instance client Azure la plus proche de l'instance AWS sélectionnée au début de cette série de blogs était une instance E32s v3 avec les spécifications suivantes :
- vCPU :32 (16 cœurs x 2 threads/cœur)
- RAM :256 Gio
- Stockage :SSD Azure Premium
- Réseau :mise en réseau accélérée jusqu'à 30 Gbit/s
Voici une capture d'écran du portail avec les détails de l'instance :
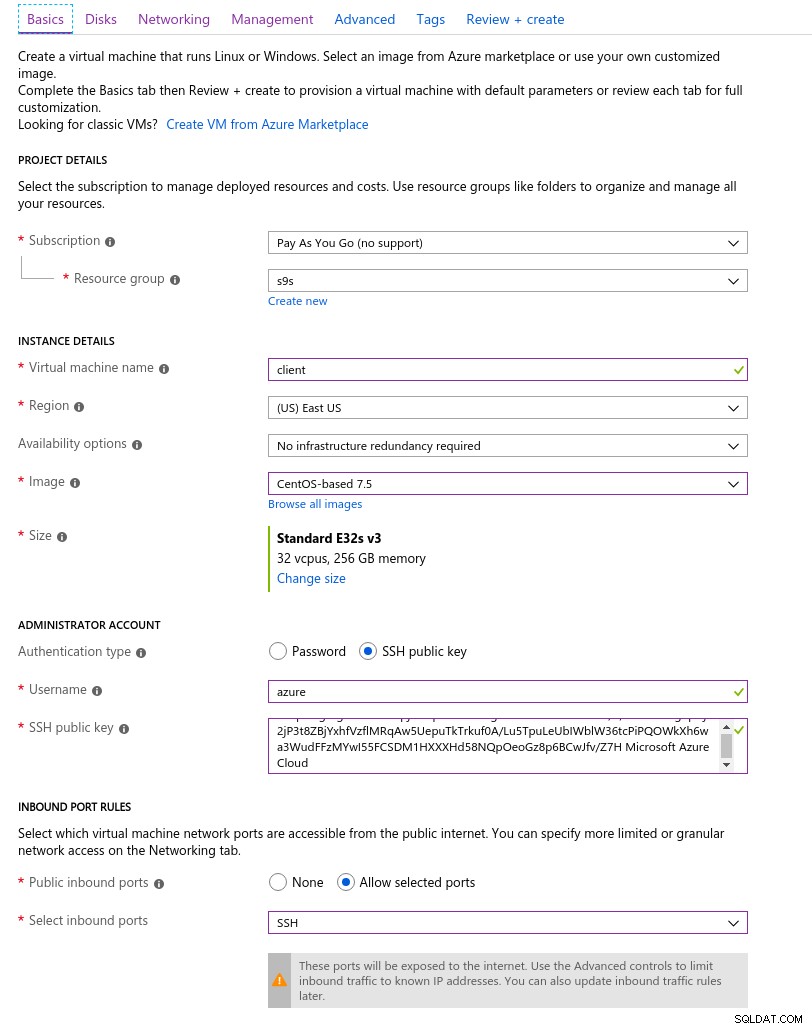 Détails de l'instance client
Détails de l'instance client La mise en réseau accélérée est activée par défaut lors du choix de l'une des machines virtuelles prises en charge :
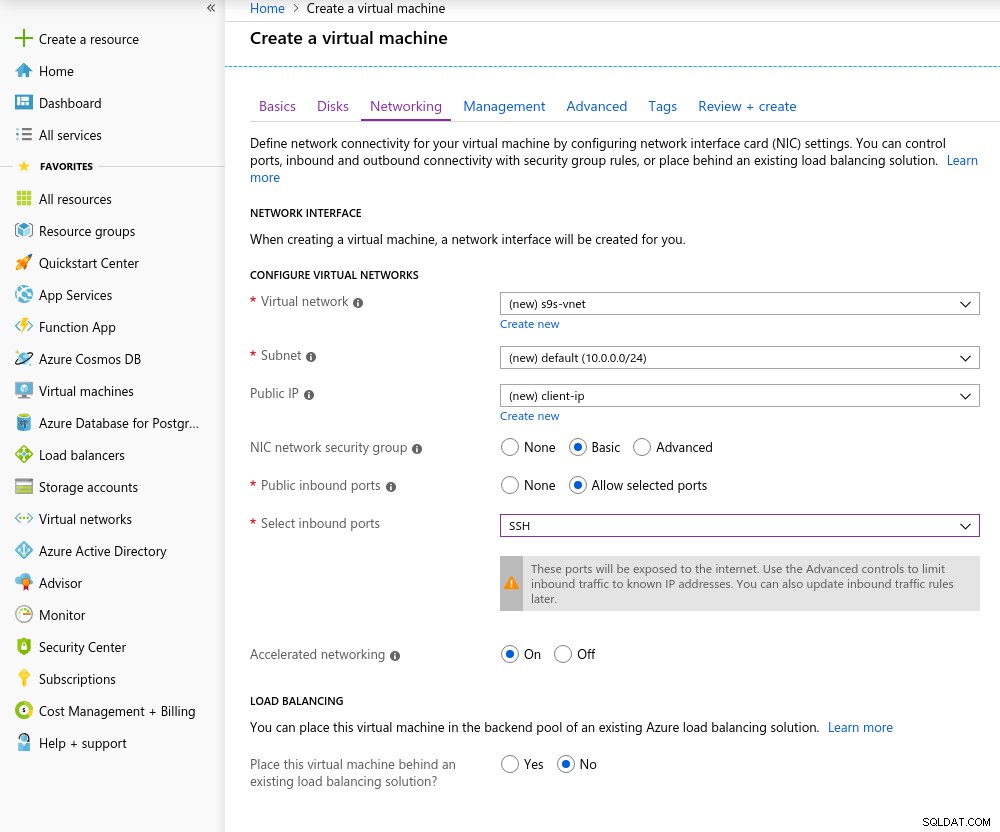 Mise en réseau accélérée activée
Mise en réseau accélérée activée Comme c'est la règle dans le cloud, pour obtenir les meilleures performances réseau, le client et le serveur doivent être situés dans la même zone de disponibilité, ce que j'ai fait en configurant l'environnement dans l'East US AZ.
Comme pour Google Cloud, une augmentation de quota doit être demandée pour les instances de plus de 10 cœurs. Microsoft a rendu cela vraiment facile. Une fois le passage à un compte payant, j'ai reçu la confirmation d'approbation avant de pouvoir terminer ma réponse dans le ticket expliquant pourquoi je demande l'augmentation.
Base de données
En sélectionnant la taille de l'instance, j'ai essayé de faire correspondre les spécifications des instances utilisées sur AWS et Google Cloud :
- processeur virtuel :8
- RAM :80 Gio (maximum)
- Stockage :6 000 IOPS (taille de 2 Tio à 3 IOPS/Go)
- Réseau :2 000 Mo/s
La faible taille de la mémoire provient de la formule de mémoire par vCore utilisée pour allouer la mémoire :
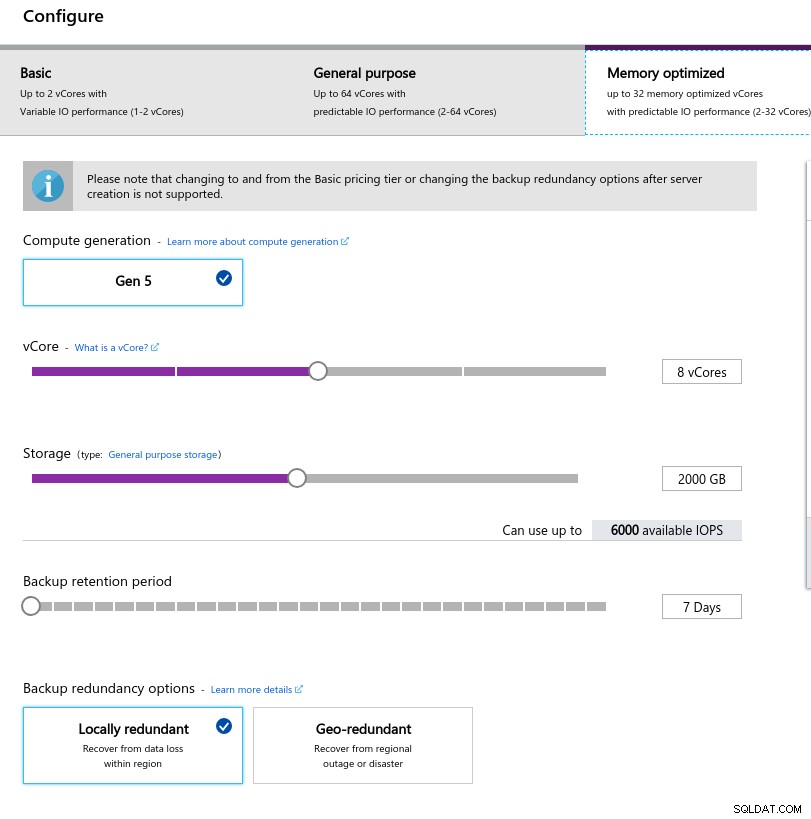 Configuration de l'instance de base de données
Configuration de l'instance de base de données À l'instar de Google Cloud, et contrairement à AWS, plus le stockage est important, plus les IOPS sont élevées, avec une augmentation du rapport de 3:1. Cependant, une fois que la taille atteint 2 Tio, les IOPS sont plafonnées à 6 000 IOPS.
Exécution des benchmarks
Configuration
La configuration a suivi le processus décrit dans les parties précédentes de la série de blogs, avec le correctif de synchronisation AWS pgbench pour 11.1 s'appliquant proprement à Azure PostgreSQL version 10.7. Les correctifs peuvent également être obtenus à partir des contributions d'AWS Labs au référentiel PostgreSQL Github.
Au cours de l'exécution des benchmarks, j'ai utilisé le script suivant qui suit simplement le guide Amazon et, dans ce cas, est adapté à la version PostgreSQL dans Azure (10.7). La machine cliente exécute CentOS 7.5 :
#!/bin/bash
set -eE
trap "exit 1" ERR
yum -y install \
wget ant git php gnuplot gcc make readline-devel zlib-devel \
postgresql-jdbc bzr automake libtool patch libevent-devel \
openssl-devel ncurses-devel
wget https://ftp.postgresql.org/pub/source/v10.7/postgresql-10.7.tar.gz
rm -rf postgresql-10.7
tar -xzf postgresql-10.7.tar.gz
cd postgresql-10.7
wget https://s3.amazonaws.com/aurora-pgbench-patches/pgbench-init-timing.patch
patch --verbose -p1 -b < pgbench-init-timing.patch
./configure
make -j 4 all
make install
cd ..
rm -rf sysbench
git clone -b 0.5 https://github.com/akopytov/sysbench.git
cd sysbench
./autogen.sh
CFLAGS="-L/usr/local/pgsql/lib/ -I /usr/local/pgsql/include/" \
| ./configure \
--with-pgsql \
--without-mysql \
--with-pgsql-includes=/usr/local/pgsql/include/ \
--with-pgsql-libs=/usr/local/pgsql/lib/
make
make install
cd sysbench/tests
make install
sed -i \
'/^export PGHOST=/,/^export LD_LIBRARY_PATH.*pgsql/d' \
~/.bashrc
cat << "__eot__" >> ~/.bashrc
export PGHOST=CHANGEME
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=/usr/local/pgsql/bin:/usr/local/bin:$PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
__eot__
echo "All done."Une fois le script terminé, modifiez .bashrc pour définir les variables d'environnement PostgreSQL. Azure est particulier quant au format du nom d'utilisateur PostgreSQL en s'attendant à un format {username}@{host} plutôt que l'omniprésent {username} :
[example@sqldat.com scripts]# psql
psql: FATAL: Invalid Username specified. Please check the Username and retry connection. The Username should be in <example@sqldat.com> format.Avant de commencer les tests, vérifiez que nous utilisons la bonne version des outils clients :
[example@sqldat.com scripts]# psql --version
psql (PostgreSQL) 10.7[example@sqldat.com scripts]# pgbench --version
pgbench (PostgreSQL) 10.7[example@sqldat.com scripts]# sysbench --version
sysbench 0.5pgench
Initialisez la base de données pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…et quelques minutes plus tard :
[example@sqldat.com scripts]# pgbench -i --fillfactor=90 --scale=10000
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.04 s, remaining 426.44 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 427.22 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.18 s, remaining 600.63 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 530.99 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.30 s, remaining 595.12 s)
...
584300000 of 1000000000 tuples (58%) done (elapsed 2421.82 s, remaining 1723.01 s)
584400000 of 1000000000 tuples (58%) done (elapsed 2421.86 s, remaining 1722.32 s)
584500000 of 1000000000 tuples (58%) done (elapsed 2422.81 s, remaining 1722.29 s)
584600000 of 1000000000 tuples (58%) done (elapsed 2422.84 s, remaining 1721.60 s)
584700000 of 1000000000 tuples (58%) done (elapsed 2422.88 s, remaining 1720.92 s)
584800000 of 1000000000 tuples (58%) done (elapsed 2425.06 s, remaining 1721.76 s)
584900000 of 1000000000 tuples (58%) done (elapsed 2425.09 s, remaining 1721.07 s)
585000000 of 1000000000 tuples (58%) done (elapsed 2425.28 s, remaining 1720.50 s)
...
999700000 of 1000000000 tuples (99%) done (elapsed 4142.69 s, remaining 1.24 s)
999800000 of 1000000000 tuples (99%) done (elapsed 4142.95 s, remaining 0.83 s)
999900000 of 1000000000 tuples (99%) done (elapsed 4142.98 s, remaining 0.41 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 4143.92 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 14805.73 s (insert 4146.94 s, commit 0.02 s, vacuum 6581.15 s, index 4077.61 s)
done.Jusqu'ici, tout va bien.
Un coup d'œil rapide à la base de données pour confirmer qu'elle est prête :
example@sqldat.com:5432 postgres> \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Table space | Description
-------------------+-----------------+----------+----------------------------+----------------------------+-------------------------------------+-----------+------------+--------------------------------------------
azure_maintenance | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | azure_superuser=CTc/azure_superuser | No Access | pg_default |
azure_sys | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | | 12 MB | pg_default |
postgres | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | | 160 GB | pg_default | default administrative connection database
template0 | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | =c/azure_superuser +| 7865 kB | pg_default | unmodifiable empty database
| | | | | azure_superuser=CTc/azure_superuser | | |
template1 | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | =c/azure_superuser +| 7865 kB | pg_default | default template for new databases
| | | | | azure_superuser=CTc/azure_superuser | | |
(5 rows)Étant donné qu'Azure n'autorise pas la modification de max_connections et étant donné que pour l'instance sélectionnée, la limite est plafonnée à 960, nous allons devoir ajuster le nombre de clients pgbench en conséquence :
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
could not translate host name "postgresql-10-7.postgres.database.azure.com" to address: Name or service not known
connection to database "postgres" failed:
could not translate host name "postgresql-10-7.postgres.database.azure.com" to address: Name or service not knownEt voilà, le premier contretemps.
Une vérification rapide de la résolution DNS de l'hôte ne révèle aucun problème :
[example@sqldat.com scripts]# dig +short $PGHOST
cr1.eastus1-a.control.database.windows.net.
191.238.6.43[example@sqldat.com scripts]# cat /etc/resolv.conf
; generated by /usr/sbin/dhclient-script
search 11jv1qvdjs5utlhtlyb5vdyeth.bx.internal.cloudapp.net
nameserver 168.63.129.16Un examen de mon journal d'écran montre que près de la moitié des connexions ont été interrompues :
~$ cat screenlog.1 | nl | grep 'could not translate host name "postgresql-10-7.*Name or service not known' | wc -l
469pg_stat_activity raconte une histoire plus détaillée :nous avons atteint un pic à 950 connexions :
example@sqldat.com:5432 postgres> select now(), count(*) from pg_stat_activity where usename = 'postgres' and application_name = 'pgbench'; now | count
-------------------------------+-------
2019-05-03 23:39:18.200291+00 | 950
(1 row)… cependant, la surveillance de la requête ci-dessus montre une chute soudaine du nombre de connexions de 950 à 628, en seulement 10 secondes :
example@sqldat.com:5432 postgres> \watch 10
Fri 03 May 2019 11:41:05 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:41:05.044025+00 | 950
(1 row)
...
Fri 03 May 2019 11:43:10 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:10.512766+00 | 950
(1 row)
Fri 03 May 2019 11:43:20 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:17.419011+00 | 628
(1 row)
Fri 03 May 2019 11:43:30 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:31.434638+00 | 613
(1 row)Pour contourner le problème DNS, j'ai attribué à PGHOST l'adresse IP de l'hôte :
[example@sqldat.com scripts]# set | grep PG
PGDATABASE=postgres
PGHOST=191.238.6.43
example@sqldat.com
PGPORT=5432
example@sqldat.comAvec cette solution de contournement en place, j'ai redémarré le test :
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
progress: 61.1 s, 457.7 tps, lat 559.138 ms stddev 1755.888
progress: 120.1 s, 78.8 tps, lat 3883.772 ms stddev 10551.545
progress: 180.1 s, 17.6 tps, lat 50831.708 ms stddev 31214.512
progress: 240.1 s, 15.2 tps, lat 42474.763 ms stddev 32702.050
progress: 300.1 s, 16.1 tps, lat 43584.559 ms stddev 29818.142
progress: 360.1 s, 26.5 tps, lat 36914.096 ms stddev 37152.588
progress: 420.0 s, 33.4 tps, lat 27542.926 ms stddev 37075.457
progress: 480.0 s, 20.2 tps, lat 47149.060 ms stddev 47087.474
progress: 540.0 s, 13.5 tps, lat 55609.260 ms stddev 60394.287
progress: 600.0 s, 36.5 tps, lat 49566.853 ms stddev 99155.598
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 950
number of threads: 950
duration: 600 s
number of transactions actually processed: 44293
latency average = 12493.888 ms
latency stddev = 40490.231 ms
tps = 60.907130 (including connections establishing)
tps = 64.213520 (excluding connections establishing)À première vue, les choses semblaient s'être bien déroulées, cependant, les valeurs de latence extrêmement élevées, associées aux problèmes DNS antérieurs et au client activé par «réseau accéléré», suggèrent que quelque chose ne va pas au niveau du réseau, et c'est probablement le cas. cause de faibles résultats tps. Mais le pire reste à venir.
Téléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blancsysbench
Commencez par créer les tables :
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepare
After a little while:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
FATAL: PQexec() failed: 7 server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
FATAL: failed query: CREATE TABLE sbtest1 (
id SERIAL NOT NULL,
k INTEGER DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY (id)
)
FATAL: failed to execute function `prepare': 3Cela n'avait pas l'air bien du tout, alors j'ai vérifié les journaux PostgreSQL :
2019-05-03 23:51:12 UTC-5ccbbe4f.88-WARNING: worker took too long to start; canceled
2019-05-03 23:51:14 UTC-5ccbbe4f.84-PANIC: could not write to log file 000000010000001F000000CD at offset 13664256, length 8192: Invalid argument
+++ NT HARD ERROR (0xd0000144) +++
Parameter 0: 0xffffffffc0000005
Parameter 1: 0x1b80f0f73b
Parameter 2: 0x1
Parameter 3: 0x0Bien que le service doive se rétablir tout seul, j'ai décidé de redémarrer l'instance afin d'accélérer le processus.
2019-05-04 00:43:23 UTC-5ccce02a.2c-HINT: Is another postmaster already running on port 20108? If not, wait a few seconds and retry.
2019-05-04 00:43:23 UTC-5ccce02a.2c-LOG: could not bind IPv6 address "::": A socket operation was attempted to an unreachable host.
2019-05-04 00:43:23 UTC-5ccce02a.2c-LOG: listening on IPv4 address "0.0.0.0", port 20108
2019-05-04 00:43:24 UTC-5ccce02a.2c-LOG: database system is ready to accept connections
...
2019-05-05 00:03:35 UTC-5cce2856.2c-HINT: Is another postmaster already running on port 20326? If not, wait a few seconds and retry.
2019-05-05 00:03:35 UTC-5cce2856.2c-LOG: could not bind IPv6 address "::": A socket operation was attempted to an unreachable host.
2019-05-05 00:03:35 UTC-5cce2856.2c-LOG: listening on IPv4 address "0.0.0.0", port 20326
2019-05-05 00:03:38 UTC-5cce285a.3c-FATAL: the database system is starting up
2019-05-05 00:03:38 UTC-5cce285a.3c-LOG: connection received: host=127.0.0.1 port=47247 pid=60
2019-05-05 00:03:49 UTC-5cce2865.40-FATAL: the database system is starting up
2019-05-05 00:03:49 UTC-5cce2865.40-LOG: connection received: host=127.0.0.1 port=47284 pid=64
2019-05-05 00:03:59 UTC-5cce286f.44-FATAL: the database system is starting up
2019-05-05 00:03:59 UTC-5cce286f.44-LOG: connection received: host=127.0.0.1 port=47312 pid=68
2019-05-05 00:04:00 UTC-5cce2856.2c-LOG: database system is ready to accept connections
2019-05-05 00:04:00 UTC-5cce2870.38-LOG: database system was shut down at 2019-05-05 00:03:34 UTCÀ ce stade, j'ai également activé les informations sur les performances des requêtes :
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: parameter "pgms_wait_sampling.query_capture_mode" changed to "ALL"
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: parameter "pg_qs.query_capture_mode" changed to "TOP"
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: received SIGHUP, reloading configuration files
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: received SIGHUP, reloading configuration files
2019-05-05 00:04:13 UTC-5cce287a.6c-ERROR: database "azure_sys" already exists
2019-05-05 00:04:13 UTC-5cce287a.6c-STATEMENT: CREATE DATABASE azure_sys TEMPLATE template0Avant de redémarrer la tâche sysbench, je voulais m'assurer que la base de données était saine, et j'ai donc lancé un deuxième test pgbench :
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.Selon le moniteur de requêtes pg_stat_activity, le serveur est mort lorsque le nombre de connexions a atteint 710 :
example@sqldat.com:5432 postgres> \watch 1
Sun 05 May 2019 12:44:11 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:44:11.010413+00 | 220
(1 row)
Sun 05 May 2019 12:44:12 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:44:12.041667+00 | 231
(1 row)
...
now | count
------------------------------+-------
2019-05-05 00:47:33.16533+00 | 710
(1 row)
Sun 05 May 2019 12:47:40 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:47:40.524662+00 | 710
(1 row)Et à partir des journaux PostgreSQL, nous apprenons que quelque chose s'est passé le long du tuyau de connexion :
2019-05-05 00:44:11 UTC-5cce31da.c60-LOG: connection received: host=40.114.85.62 port=50925 pid=3168
2019-05-05 00:44:11 UTC-5cce31db.c58-LOG: connection received: host=40.114.85.62 port=55256 pid=3160
2019-05-05 00:44:11 UTC-5cce31db.c5c-LOG: connection received: host=40.114.85.62 port=34526 pid=3164
2019-05-05 00:44:11 UTC-5cce31db.c64-LOG: connection received: host=40.114.85.62 port=1178 pid=3172
...
2019-05-05 00:47:32 UTC-5cce329a.146c-LOG: connection received: host=40.114.85.62 port=41769 pid=5228
2019-05-05 00:47:33 UTC-5cce3287.1404-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3288.1428-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3289.1434-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3291.1448-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce32a3.1484-LOG: connection received: host=40.114.85.62 port=50296 pid=5252
2019-05-05 00:47:33 UTC-5cce32a5.1488-LOG: connection received: host=40.114.85.62 port=28304 pid=5256
2019-05-05 00:47:39 UTC-5cce31d2.a24-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31d5.ae8-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31e3.ee4-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31e9.1054-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce3291.1444-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:40 UTC-5cce31cd.8ec-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.Confronté à la limitation de max_connections et aux problèmes rencontrés lors des tests pgbench et sysbench, j'ai commencé à me demander si une base de données à 16 cœurs présenterait le même comportement.
Instance de base de données à 16 cœurs
Sur une instance de base de données à 16 cœurs, la limite max_connections est suffisamment élevée pour accueillir 1 000 clients :
example@sqldat.com:5432 postgres> show max_connections ;
max_connections
-----------------
1900
(1 row)Cela m'a permis d'exécuter les mêmes commandes de référence que celles que j'utilisais sur les précédents fournisseurs de cloud.
Le benchmark s'est terminé avec succès et les résultats sont affichés ci-dessous :
pgbench
- Initialisation :
[example@sqldat.com scripts]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.08 s, remaining 807.39 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 628.37 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.16 s, remaining 527.89 s) ... 600100000 of 1000000000 tuples (60%) done (elapsed 2499.90 s, remaining 1665.90 s) 600200000 of 1000000000 tuples (60%) done (elapsed 2500.07 s, remaining 1665.33 s) ... 999900000 of 1000000000 tuples (99%) done (elapsed 4170.91 s, remaining 0.42 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 4171.29 s, remaining 0.00 s) vacuum... set primary keys... total time: 13701.50 s (insert 4173.33 s, commit 0.05 s, vacuum 7098.74 s, index 2429.39 s) done. - Exécuter :
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048 starting vacuum...end. progress: 81.4 s, 5639.1 tps, lat 80.094 ms stddev 73.213 progress: 120.0 s, 4091.0 tps, lat 224.161 ms stddev 608.523 progress: 180.0 s, 6932.1 tps, lat 145.143 ms stddev 228.925 progress: 240.0 s, 7287.9 tps, lat 136.521 ms stddev 156.643 progress: 300.0 s, 7567.8 tps, lat 132.722 ms stddev 158.754 progress: 360.0 s, 8077.9 tps, lat 123.801 ms stddev 139.033 progress: 420.0 s, 6076.9 tps, lat 163.886 ms stddev 201.121 progress: 480.0 s, 5376.2 tps, lat 186.678 ms stddev 191.270 progress: 540.0 s, 4864.0 tps, lat 205.696 ms stddev 164.261 progress: 600.0 s, 3759.3 tps, lat 266.073 ms stddev 542.717 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 3614386 latency average = 152.935 ms latency stddev = 248.593 ms tps = 6002.082008 (including connections establishing) tps = 6513.306467 (excluding connections establishing)
Cela s'est relativement bien passé, cependant, il n'y a aucun moyen valable de comparer ces résultats avec ceux d'AWS et de G Cloud, car nous ne testons pas sur une plate-forme similaire. Mais c'est assez bon pour nous amener au point suivant.
sysbench
Comme les tests pgbench se sont terminés avec succès, j'ai décidé de tirer pleinement parti du crédit Azure de 200 $ et de confirmer que sysbench va plus loin que l'exécution précédente sur l'instance à 8 cœurs :
sysbench \
--test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=191.238.6.43 \
--pgsql-db=postgres \
example@sqldat.com \
example@sqldat.com \
--pgsql-port=5432 \
--oltp-tables-count=250 \
--oltp-table-size=450000 prepare
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
Creating secondary indexes on 'sbtest2'...
Creating table 'sbtest3'...
Inserting 450000 records into 'sbtest3'
Creating secondary indexes on 'sbtest3'...
Creating table 'sbtest4'...Cela semblait bien fonctionner, et comme je me rapprochais de mon budget, j'ai décidé d'arrêter la tâche.
Hyperscale (Citus)
Bien qu'elle ne soit pas prête pour la production, cette option méritait d'être examinée, car elle fournit des fonctionnalités avancées non disponibles dans AWS et G Cloud.
À la suite de l'acquisition de Citus Data, Microsoft propose une version préliminaire de son produit phare PostgreSQL, sous le nom d'Hyperscale (Citus).
L'assistant de portail facilite la configuration d'un environnement autrement compliqué :
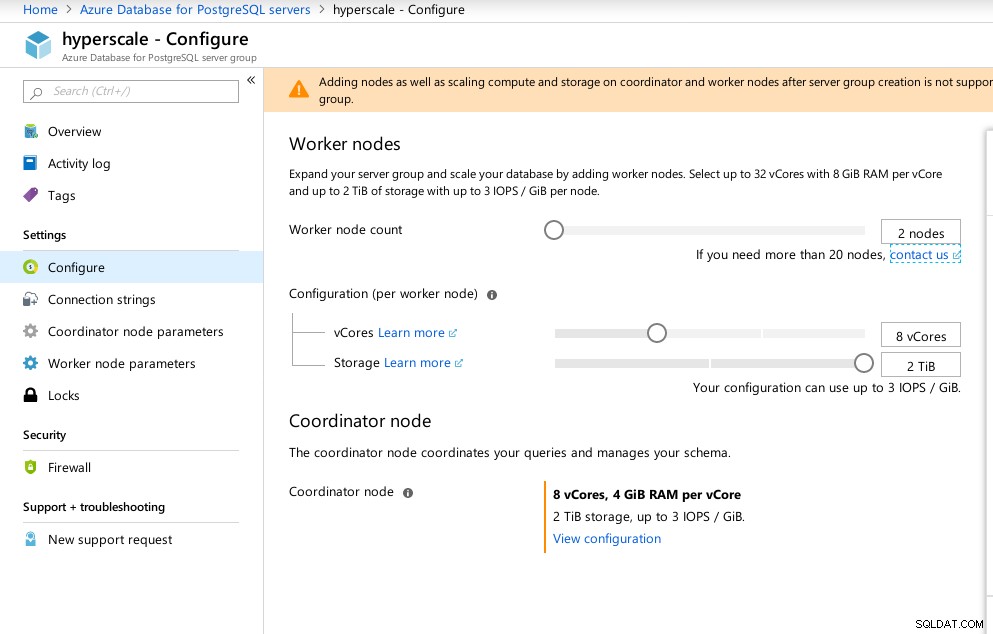 Configuration Azure Hyperscale (Citus)
Configuration Azure Hyperscale (Citus) J'ai noté que contrairement à Azure PostgreSQL qui tourne sous Windows, Hyperscale tourne sous Linux :
example@sqldat.com:5432 citus> select version();
version
----------------------------------------------------------------------------------------------------------------
PostgreSQL 11.2 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609, 64-bit
(1 row)Malheureusement, alors qu'Hyperscale promettait un voyage passionnant, je ne pouvais pas pour le moment continuer à exécuter les tests car max_connections est actuellement plafonné à 300, sans possibilité d'ajustement, bien que la capacité soit documentée pour le Citus PosgreSQL natif :
example@sqldat.com:5432 citus> show max_connections ;
max_connections
-----------------
300
(1 row)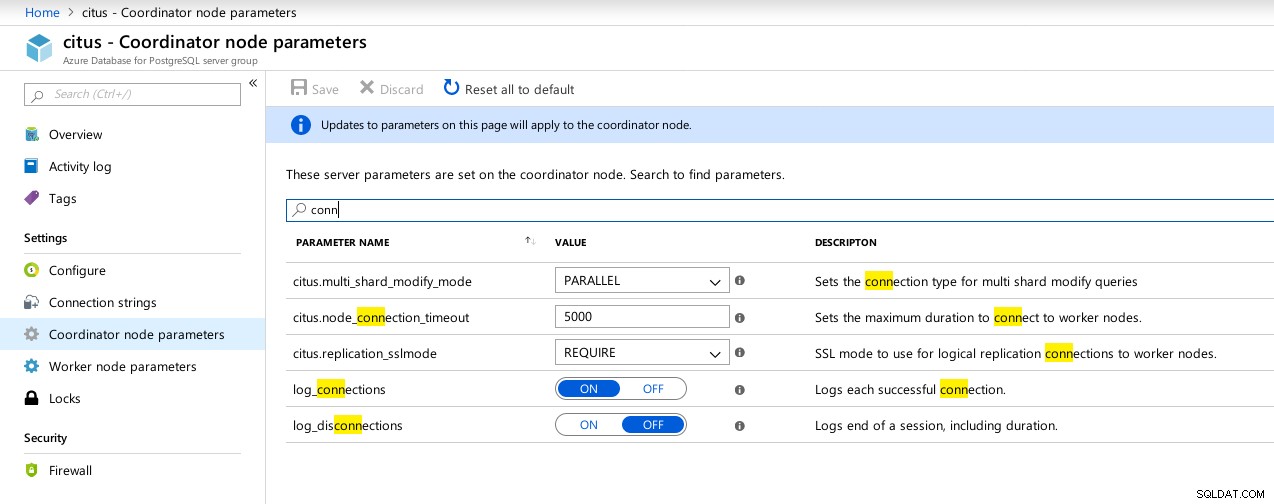 Connexions du coordinateur Hyperscale (Citus) Paramètres disponibles
Connexions du coordinateur Hyperscale (Citus) Paramètres disponibles 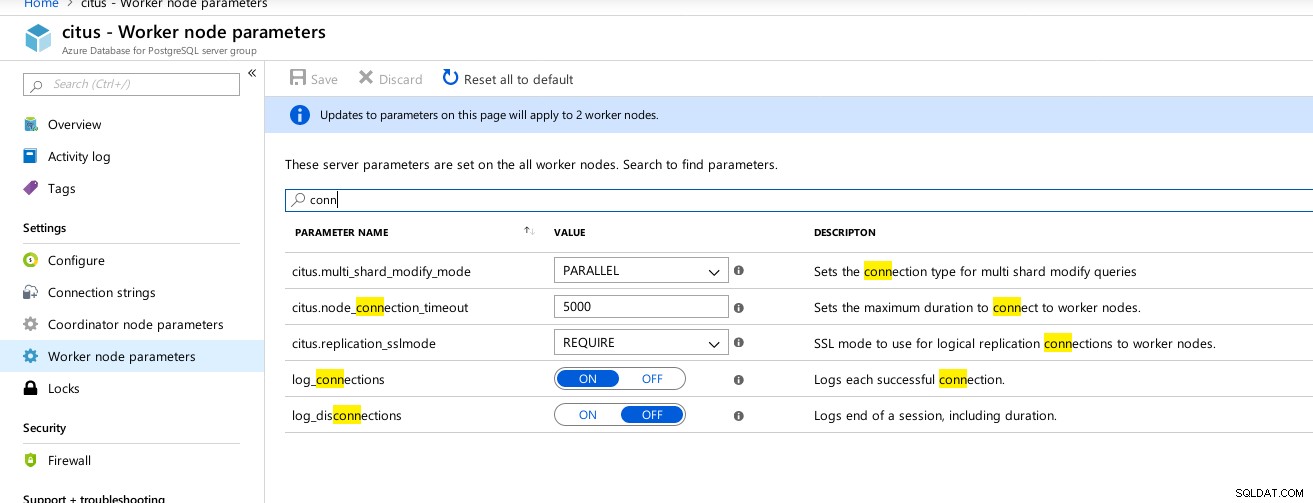 Travailleurs Hyperscale (Citus) :max_connections non disponible
Travailleurs Hyperscale (Citus) :max_connections non disponible Métriques de référence
Quelques mesures indiquant les performances et le comportement du client et du serveur :
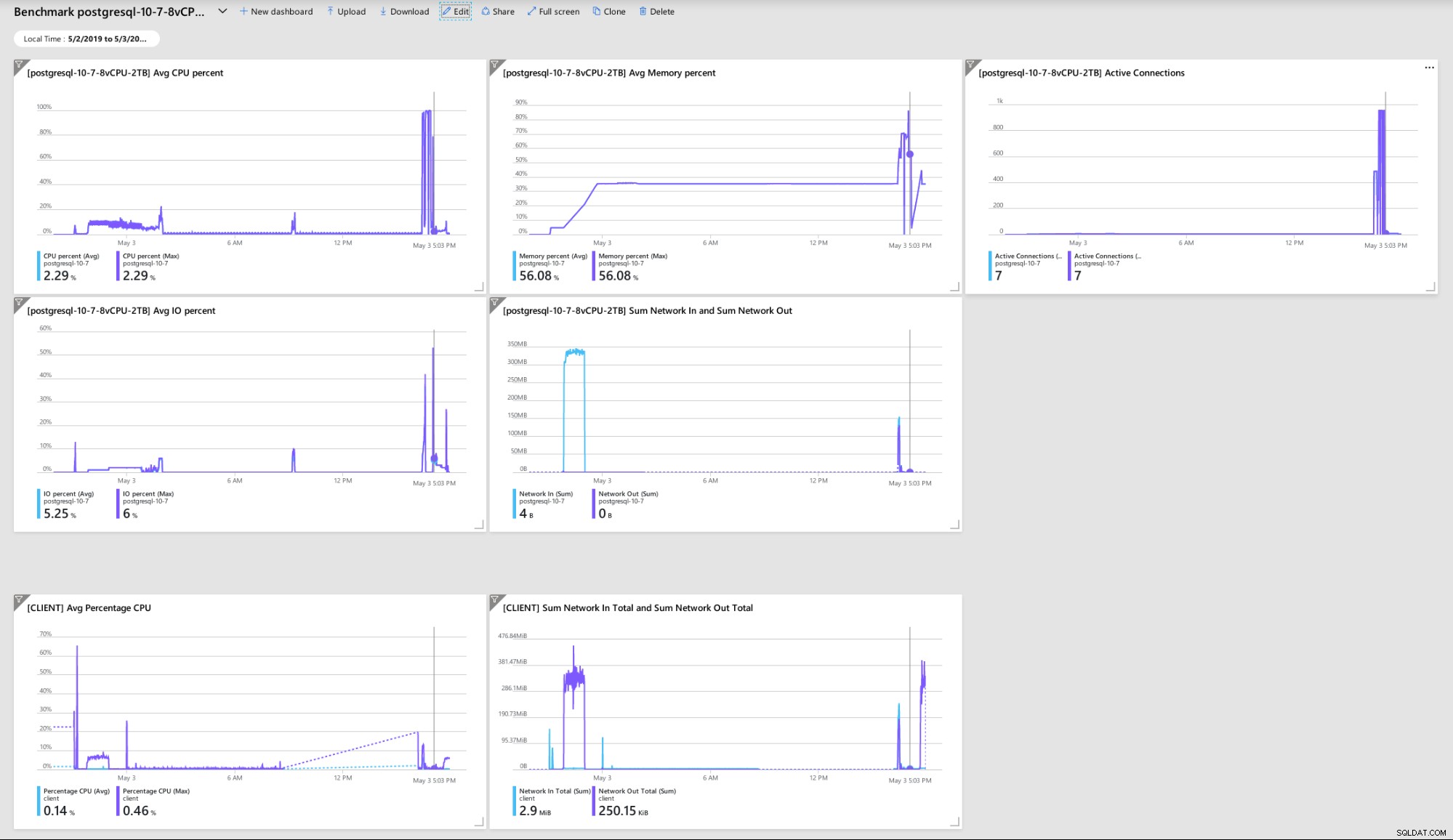 Tableau de bord du portail Azure - Métriques pour le client et le serveur
Tableau de bord du portail Azure - Métriques pour le client et le serveur Métriques PostgreSQL collectées à l'aide de Query Performance Insight :
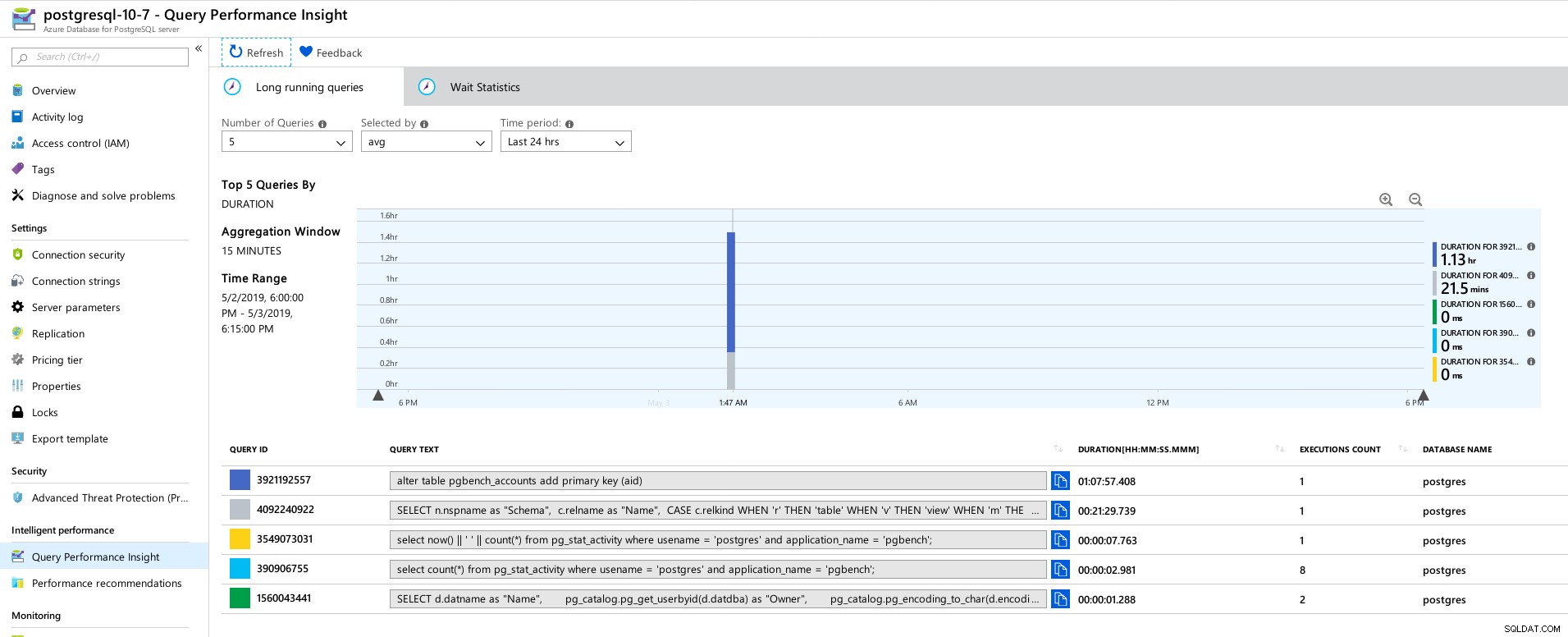 Azure PostgreSQL - Query Performance Insights :5 principales requêtes
Azure PostgreSQL - Query Performance Insights :5 principales requêtes 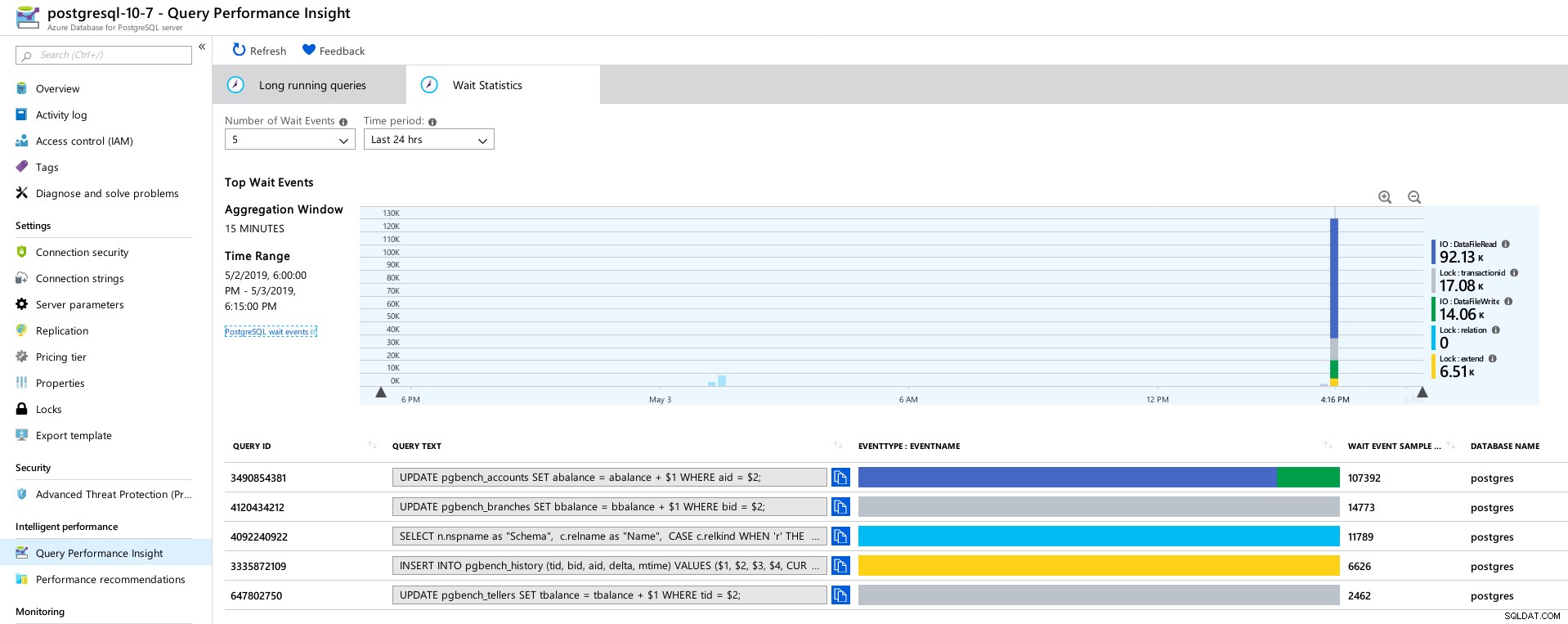 Azure PostgreSQL - Query Performance Insights :5 principaux temps d'attente
Azure PostgreSQL - Query Performance Insights :5 principaux temps d'attente Conclusion
Ressources associées Analyse comparative des solutions cloud PostgreSQL gérées – Partie 1 :Amazon Aurora Analyse comparative des solutions cloud PostgreSQL gérées – Partie 2 :Amazon RDS Analyse comparative des solutions cloud PostgreSQL gérées – Partie 3 :Google CloudTout d'abord, si vous êtes arrivé jusqu'ici, merci d'avoir lu, et s'il vous arrivait de repérer des erreurs qui auraient pu entraîner un mauvais comportement de l'environnement, j'apprécierais beaucoup les commentaires. À condition que j'ai raté quelque chose d'évident, je suis prêt à répéter les tests.
Le crash du moteur de base de données conduisant au vidage hexadécimal "NT HARD ERROR" indique que quelque chose hors du contrôle de l'utilisateur s'est produit et qu'un bon service géré se rétablirait au moyen d'une automatisation ou en alertant les SRE en charge. Si j'avais attendu plus de temps, cela aurait pu être le cas, bien que cela soulève la question de savoir combien de temps les utilisateurs doivent attendre jusqu'à ce que le service soit rétabli.
Verrouiller max_connections sur une valeur basée sur le niveau tarifaire et les vCores m'a pris par surprise, surtout après avoir testé les trois autres services gérés, avec Google Cloud permettant au paramètre d'être configuré par l'utilisateur, même si la valeur par défaut était bien inférieure (600 sur G Cloud contre 960 sur Azure).
Un test avec l'instance de base de données dans la gamme 16 cœurs peut être nécessaire afin d'éviter de modifier les valeurs par défaut, bien qu'à ce moment-là, je préférerais tester en utilisant de meilleurs outils, tels que HammerDB (voir la partie 1 pour une discussion sur les outils) .