Dans un article précédent, nous avons discuté du modèle de schéma en étoile. Le schéma en flocon de neige est à côté du schéma en étoile en termes d'importance dans la modélisation de l'entrepôt de données. Il a été développé à partir du schéma en étoile et offre certains avantages par rapport à son prédécesseur. Mais ces avantages ont un coût. Dans cet article, nous verrons quand et comment utiliser le schéma en flocon de neige.
Le schéma du flocon de neige
Le nom du schéma en flocon de neige vient du fait que les tables de dimension se ramifient et ressemblent à un flocon de neige. Lorsque nous examinons le modèle ci-dessus, nous remarquons qu'il s'agit d'une table de faits entourée de quelques tables de dimensions, dont certaines font la ramification susmentionnée. Contrairement au schéma en étoile, les tables de dimensions du schéma en flocon peuvent avoir leurs propres catégories.
L'idée dominante derrière le schéma en flocon de neige est que les tables de dimension sont complètement normalisées. Chaque table de dimension peut être décrite par une ou plusieurs tables de recherche. Chaque table de consultation peut être décrite par une ou plusieurs tables de consultation supplémentaires. Ceci est répété jusqu'à ce que le modèle soit complètement normalisé. Le processus de normalisation des tables de dimension du schéma en étoile est appelé snowflaking.
Vous entendrez beaucoup parler de normalisation dans cet article. Qu'est-ce que la normalisation ? Fondamentalement, il s'agit d'organiser une base de données de manière à minimiser les redondances et à protéger l'intégrité des données. Consultez cet article pour en savoir plus sur la normalisation et la dénormalisation.
Exemple de schéma en flocon :modèle de vente
Auparavant, nous utilisions un schéma en étoile pour modéliser un service commercial fictif - cela s'apparenterait à un data mart utilisé pour suivre les activités et les résultats des ventes. Le modèle a cinq dimensions :produit , heure , magasin , ventes type et employé . Dans le fact_sales tableau, prix et quantité sont stockés et regroupés en fonction des valeurs des tables de dimensions. Pour un rappel, jetez un œil au modèle de vente du schéma en étoile ci-dessous :
Voici le même modèle organisé en schéma en flocon :
Le dim_employee et dim_sales_type les tables de dimension sont exactement les mêmes que dans le modèle de schéma en étoile car elles sont déjà normalisées.
D'autre part, nous avons appliqué des règles de normalisation au reste des tables de dimension.


Le dim_product La table de dimension du schéma en étoile est divisée en deux tables dans le modèle en flocon de neige. Le dim_product_type table a été ajoutée pour référencer le type correspondant dans le dim_product table. Grâce à cela, nous avons évité certains problèmes d'intégrité des données.
Il est logique de supposer que nous aurons déjà tous les noms de produits et leurs types associés insérés dans le cadre du processus ETL, mais supposons que nous devions ajouter plus de noms et de types de produits. Dans un schéma en étoile, nous pourrions entrer par erreur le mauvais type de produit dans la table. Dans le schéma en flocon :
- Si nous rencontrons un nouveau nom de type de produit, nous pouvons ajouter un nouveau type de produit, puis associer ce type à un enregistrement nouvellement ajouté. Cependant, cela pourrait amener l'utilisateur à entrer des informations erronées, comme dans le schéma en étoile.
- Nous pourrions vérifier si le nom du produit que nous voulons ajouter existe déjà. Si c'est le cas, nous pouvons obtenir son ID ; sinon, un avertissement apparaîtra nous demandant si nous voulons ajouter un nouveau produit et un type connexe.

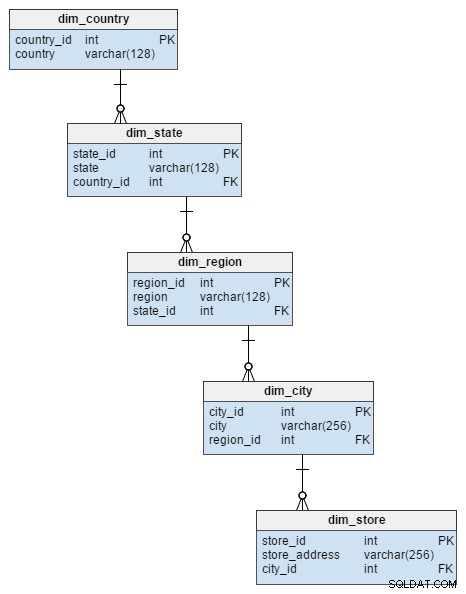
Le dim_store La table de dimension du schéma en étoile est représentée par 5 tables dans le schéma en flocon. Ceux-ci divisent les attributs de ville, de région, d'état et de pays qui étaient stockés dans le dim_store table. La normalisation de cette table a non seulement évité le risque d'intégrité des données, mais a également économisé de l'espace disque.
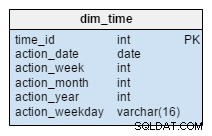
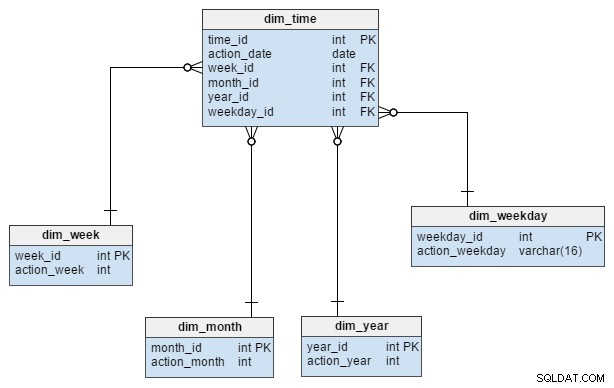
Le dim_time dimension est représentée par cinq tableaux. On peut penser à dim_week , dim_month , dim_year et le dim_weekday tables sous forme de dictionnaires décrivant le dim_time table.
La dim_week , dim_month , dim_year et dim_weekday les tableaux sont quatre hiérarchies différentes utilisées pour décrire notre dimension temporelle. Nous pourrions ajouter plus de dimensions comme des trimestres ou d'autres tables connexes si nous en avions besoin. Dans cet exemple, dim_month est un dictionnaire contenant 12 mois; à partir de cette seule dimension, nous n'avons aucun moyen de savoir à quelle année appartient ce mois; c'est la fonction du dim_year table.
Exemple de schéma en flocon :modèle de commandes d'approvisionnement
L'autre magasin de données dont nous avons discuté concernait les commandes de fournitures. L'idée est de stocker et d'agréger toutes les données de commande d'approvisionnement pour les quatre dimensions suivantes :produit , heure , fournisseur et employé . Encore une fois, nous allons jeter un œil au schéma en étoile pertinent :
En convertissant ceci en schéma de flocon de neige, nous obtenons le modèle suivant :
Les mêmes règles de normalisation que celles décrites pour le modèle de vente ont été utilisées sur le dim_product , dim_time et dim_supplier tableaux de dimensions.
Avantages et inconvénients du schéma en flocon
Il y a deux avantages principaux au schéma en flocon :
- Meilleure qualité des données (les données sont plus structurées, ce qui réduit les problèmes d'intégrité des données)
- Moins d'espace disque est utilisé que dans un modèle dénormalisé
Le désavantage le plus notable pour le modèle en flocon de neige est qu'il nécessite des requêtes plus complexes. Ces requêtes, avec leur nombre accru de jointures, pourraient réduire considérablement les performances.
Nous allons réécrire la même requête utilisée dans l'article sur le schéma en étoile pour le modèle de vente du schéma en flocon de neige. Voici la requête nécessaire pour renvoyer la quantité de tous les types de produits de type téléphone vendus dans les magasins de Berlin en 2016 :
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
Le schéma Starflake
Un schéma en étoile est une combinaison des schémas en flocon et en étoile. Nous pouvons le voir comme un schéma en flocon de neige dont certaines tables de dimensions sont dénormalisées. Lorsqu'il est utilisé correctement, le schéma starflake peut donner une approche du meilleur des deux mondes. De toute évidence, la partie flocon de neige du modèle devrait économiser de l'espace disque, tandis que la partie étoile devrait améliorer les performances.
Le modèle ci-dessus est essentiellement un modèle de flocon de neige avec un dim_time table. Étant donné que ce schéma réduit le nombre de jointures de requête nécessaires, il peut améliorer les performances. D'autre part, nous ne perdrons pas une quantité notable d'espace disque, car la plupart des attributs de table et des attributs de clé étrangère partagent le int saisir.
Le Schéma Galactique
Dans l'entreposage de données, un schéma de galaxie se produit lorsque deux ou plusieurs tables de faits partagent une ou plusieurs tables de dimension. L'une des raisons d'utiliser ce schéma est d'économiser de l'espace disque. Nous avons créé un exemple de schéma de galaxie ci-dessous :
Ici, nous avons deux tables de faits, fact_sales et fact_supply_order , qui partagent directement trois tables de dimension :dim_product , dim_employee et dim_time . Notez que même dim_store et dim_supplier partager la même table de recherche, dim_city .
Nous allons économiser de l'espace de cette façon, mais nous devons garder certaines choses à l'esprit avant de joindre deux magasins de données (dans ce cas, les commandes de vente et d'approvisionnement) dans un schéma de galaxie :
- Y a-t-il une logique à les rejoindre ? Par exemple Les deux magasins de données seraient-ils utilisés par le même service ?
- Sommes-nous sûrs d'avoir besoin précisément de la même dimension et de la même granulation ? pour les deux magasins de données ?
Le schéma en flocon de neige est souvent utilisé dans la modélisation des données. Cela peut être le bon choix dans les situations où l'espace disque est plus important que les performances. Si nous voulons un équilibre entre gain de place et performances, nous pouvons utiliser le schéma starflake. Pourtant, le bon ajustement pour tout problème spécifique dépend de nombreux paramètres. C'est l'un des domaines de l'informatique où nous pouvons «jouer» avec des facteurs pour trouver la meilleure solution.