L'une des nombreuses améliorations du plan d'exécution dans SQL Server 2012 a été l'ajout d'informations sur la réservation et l'utilisation des threads pour les plans d'exécution parallèles. Cet article examine exactement la signification de ces chiffres et fournit des informations supplémentaires sur la compréhension de l'exécution parallèle.
Considérez la requête suivante exécutée sur une version agrandie de la base de données AdventureWorks :
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; L'optimiseur de requête choisit un plan d'exécution parallèle :
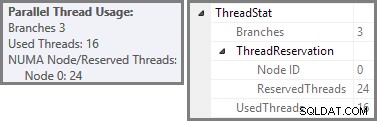
Plan Explorer affiche les détails d'utilisation des threads parallèles dans l'info-bulle du nœud racine. Pour voir les mêmes informations dans SSMS, cliquez sur le nœud racine du plan, ouvrez la fenêtre Propriétés et développez ThreadStat nœud. En utilisant une machine avec huit processeurs logiques disponibles pour SQL Server, les informations d'utilisation des threads d'une exécution typique de cette requête sont affichées ci-dessous, Plan Explorer à gauche, vue SSMS à droite :
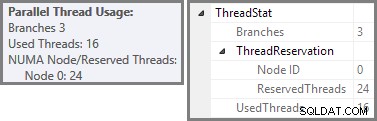
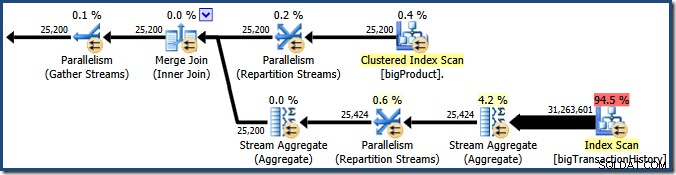
La capture d'écran montre que le moteur d'exécution a réservé 24 threads pour cette requête et a fini par en utiliser 16. Cela montre également que le plan de requête a trois branches , bien qu'il ne dise pas exactement ce qu'est une branche. Si vous avez lu mon article Simple Talk sur l'exécution de requêtes parallèles, vous saurez que les branches sont des sections d'un plan de requêtes parallèles délimitées par des opérateurs d'échange. Le schéma ci-dessous dessine les limites, et numérote les branches (cliquez pour agrandir) :

Branche Deux (Orange)
Regardons d'abord la branche 2 un peu plus en détail :
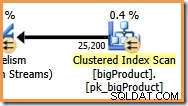
À un degré de parallélisme (DOP) de huit, huit threads exécutent cette branche du plan de requête. Il est important de comprendre que il s'agit de l'ensemble du plan d'exécution en ce qui concerne ces huit fils, ils n'ont aucune connaissance du plan plus large.
Dans un plan d'exécution en série, un seul thread lit les données d'une source de données, traite les lignes via un certain nombre d'opérateurs de plan et renvoie les résultats à la destination (qui peut être une fenêtre de résultats de requête SSMS ou une table de base de données, par exemple).
Dans une agence d'un plan d'exécution parallèle, la situation est très similaire :chaque thread lit les données d'une source, traite les lignes via un certain nombre d'opérateurs de plan et renvoie les résultats à la destination. Les différences sont que la destination est un opérateur d'échange (parallélisme) et que la source de données peut également être un échange.
Dans la branche orange, la source de données est un balayage d'index clusterisé et la destination est le côté droit d'un échange de flux de répartition. Le côté droit d'un échange est appelé côté producteur , car il se connecte à une branche qui ajoute des données à l'échange.
Les huit threads de la branche orange coopèrent pour parcourir la table et ajouter des lignes à l'échange. L'échange assemble les lignes en paquets de la taille d'une page. Une fois qu'un paquet est plein, il est poussé à travers l'échange vers l'autre côté. Si l'échange a un autre paquet vide disponible à remplir, le processus se poursuit jusqu'à ce que toutes les lignes de la source de données aient été traitées (ou que l'échange soit à court de paquets vides).
Nous pouvons voir le nombre de lignes traitées sur chaque thread à l'aide de l'arborescence du plan dans Plan Explorer :
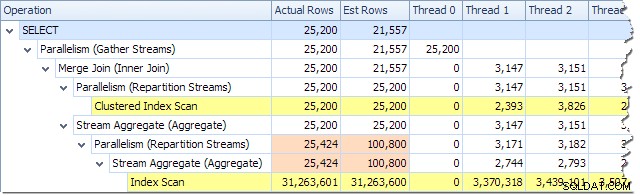
Plan Explorer permet de voir facilement comment les lignes sont réparties sur les threads pour tous les opérations physiques du plan. Dans SSMS, vous êtes limité à voir la distribution des lignes pour un seul opérateur de plan. Pour ce faire, cliquez sur une icône d'opérateur, ouvrez la fenêtre Propriétés, puis développez le nœud Nombre réel de lignes. Le graphique ci-dessous montre les informations SSMS pour le nœud Repartition Streams à la frontière entre les branches orange et violet :
Branche trois (verte)
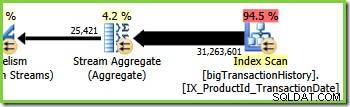
La branche trois est similaire à la branche deux, mais elle contient un opérateur Stream Aggregate supplémentaire. La branche verte a également huit fils, soit un total de seize vus jusqu'à présent. Les huit threads de la branche verte lisent les données d'un balayage d'index non clusterisé, effectuent une sorte d'agrégation et transmettent les résultats au côté producteur d'un autre échange de flux de répartition.
L'info-bulle Plan Explorer pour Stream Aggregate indique qu'il regroupe par ID de produit et calcule une expression intitulée partialagg1005 :
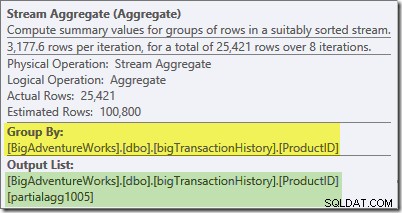
L'onglet Expressions indique que l'expression est le résultat du comptage des lignes dans chaque groupe :

Le Stream Aggregate calcule un partiel (également connu sous le nom d'agrégat "local"). Le qualificateur partiel (ou local) signifie simplement que chaque thread calcule l'agrégat sur les lignes qu'il voit. Les lignes du balayage d'index sont distribuées entre les threads en utilisant un schéma basé sur la demande :il n'y a pas de distribution fixe des lignes à l'avance ; les threads reçoivent une plage de lignes de l'analyse lorsqu'ils les demandent. Les lignes qui aboutissent sur les threads sont essentiellement aléatoires, car cela dépend de problèmes de synchronisation et d'autres facteurs.
Chaque fil voit des lignes différentes de l'analyse, mais des lignes avec le même ID de produit peut être vu par plus d'un thread. L'agrégat est "partiel" car les sous-totaux d'un groupe d'ID de produit particulier peuvent apparaître sur plusieurs fils de discussion ; il est "local" car chaque thread calcule son résultat en se basant uniquement sur les lignes qu'il reçoit. Par exemple, supposons qu'il y ait 1 000 lignes pour l'ID de produit n° 1 dans le tableau. Un thread peut arriver à voir 432 de ces lignes, tandis qu'un autre peut en voir 568. Les deux threads auront un partiel nombre de lignes pour l'ID de produit n° 1 (432 dans un fil, 568 dans l'autre).
L'agrégation partielle est une optimisation des performances, car elle réduit le nombre de lignes plus tôt qu'il ne serait autrement possible. Dans la branche verte, l'agrégation précoce réduit le nombre de lignes assemblées en paquets et transmises à travers l'échange de flux de répartition.
Branche 1 (Violet)

La branche violette a huit autres fils, soit vingt-quatre jusqu'à présent. Chaque thread de cette branche lit les lignes des deux échanges Repartition Streams et écrit des lignes dans un échange Gather Streams. Cette branche peut sembler compliquée et peu familière, mais elle ne fait que lire les lignes d'une source de données et envoyer les résultats vers une destination, comme n'importe quel autre plan de requête.
Le côté droit du plan montre les données lues de l'autre côté des deux échanges de flux de répartition vus dans les branches orange et verte. Ce côté (à gauche) de l'échange est connu sous le nom de consommateur côté, car les threads attachés ici lisent (consomment) des lignes. Les huit fils de branche violets sont des consommateurs de données aux deux échanges de flux de répartition.
Le côté gauche de la branche violette montre les lignes en cours d'écriture pour le producteur côté d'un échange Gather Streams. Les huit fils identiques (qui sont des consommateurs aux échanges des flux de répartition) effectuent un producteur rôle ici.
Chaque thread de la branche violette exécute chaque opérateur de la branche, tout comme un seul thread exécute chaque opération dans un plan d'exécution en série. La principale différence est qu'il y a huit threads exécutés simultanément, chacun travaillant sur une ligne différente à un moment donné, en utilisant différentes instances des opérateurs du plan de requête.
Le Stream Aggregate dans cette branche est un global agrégat. Il combine les agrégats partiels (locaux) calculés dans la branche verte (rappelez-vous l'exemple d'un nombre de 432 dans un thread et de 568 dans l'autre) pour produire un total combiné pour chaque ID de produit. L'info-bulle de Plan Explorer affiche l'expression de résultat globale, intitulée Expr1004 :
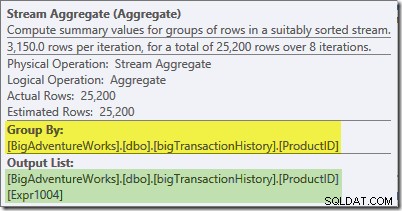
Le résultat global correct par ID de produit est calculé en additionnant les agrégats partiels, comme l'illustre l'onglet Expressions :
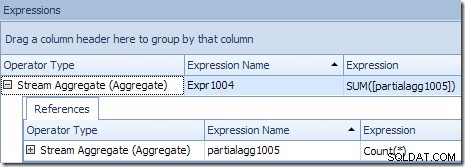
Pour continuer notre exemple (imaginaire), le résultat correct de 1 000 lignes pour l'ID de produit n° 1 est obtenu en additionnant les deux sous-totaux de 432 et 568.
Chacun des huit threads de branche violets lit les données du côté consommateur des deux échanges Gather Streams, calcule les agrégats globaux, effectue la jointure de fusion sur l'ID de produit et ajoute des lignes à l'échange Gather Streams à l'extrême gauche de la branche violette. Le processus de base n'est pas très différent d'un plan de série ordinaire; les différences résident dans l'endroit où les lignes sont lues, où elles sont envoyées et comment les lignes sont réparties entre les threads…
Répartition des lignes d'échange
Le lecteur averti s'interrogera sur quelques détails à ce stade. Comment la branche violette parvient-elle à calculer des résultats corrects par ID de produit mais la branche verte ne pouvait pas (les résultats pour le même identifiant de produit étaient répartis sur plusieurs fils) ? De plus, s'il y a huit jointures de fusion distinctes (une par thread), comment SQL Server garantit-il que les lignes qui se joindront se retrouveront sur la même instance de la jointure ?
Il est possible de répondre à ces deux questions en examinant la manière dont les deux échanges de flux de répartition acheminent les lignes du côté producteur (dans les branches verte et orange) au côté consommateur (dans la branche violette). Nous examinerons d'abord l'échange de flux de répartition bordant les branches orange et violet :
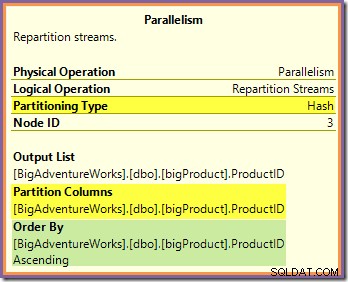
Cet échange achemine les lignes entrantes (depuis la branche orange) à l'aide d'une fonction de hachage appliquée à la colonne ID produit. L'effet est que toutes les lignes d'un ID de produit particulier sont garanties être acheminé vers le même thread de branche violette. Les fils orange et violet ne savent rien de ce routage; tout cela est géré en interne par la bourse.
Tout ce que les threads orange savent, c'est qu'ils renvoient des lignes à l'itérateur parent qui les a demandées (le côté producteur de l'échange). De même, tous les threads violets "savent" qu'ils lisent des lignes à partir d'une source de données. L'échange détermine dans quel paquet une ligne de thread orange entrante ira, et il peut s'agir de l'un des huit paquets candidats. De même, l'échange détermine à partir de quel paquet lire une ligne pour satisfaire une demande de lecture d'un thread violet.
Veillez à ne pas acquérir une image mentale d'un fil orange particulier (producteur) étant directement lié à un fil violet particulier (consommateur). Ce n'est pas ainsi que fonctionne ce plan de requête. Un producteur d'oranges peut finissent par envoyer des lignes à tous les consommateurs violets - le routage dépend entièrement de la valeur de la colonne d'ID de produit dans chaque ligne qu'il traite.
Notez également qu'un paquet de lignes à l'échange n'est transféré que lorsqu'il est plein (ou lorsque le côté producteur manque de données). Imaginez que l'échange remplisse les paquets une ligne à la fois, où les lignes d'un paquet particulier peuvent provenir de n'importe lequel des threads côté producteur (orange). Une fois qu'un paquet est plein, il est transmis au côté consommateur, où un thread consommateur particulier (violet) peut commencer à le lire.
L'échange de flux de répartition bordant les branches vertes et violettes fonctionne de manière très similaire :
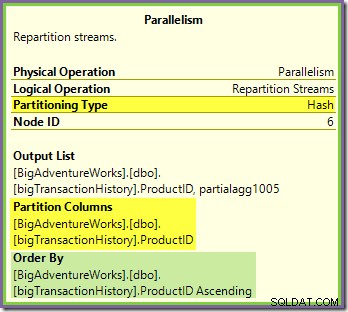
Les lignes sont routées vers les paquets dans cet échange en utilisant la même fonction de hachage sur la même colonne de partitionnement comme pour l'échange orange-violet vu précédemment. Cela signifie que les deux Repartition Streams échange les lignes de routage avec le même ID de produit vers le même thread de branche violette.
Cela explique comment le Stream Aggregate dans la branche violette est capable de calculer des agrégats globaux - si une ligne avec un ID de produit particulier est vue sur un fil de branche violet particulier, ce fil est assuré de voir toutes les lignes pour cet ID de produit (et non l'autre fil le fera).
La colonne de partitionnement d'échange commun est également la clé de jointure pour la jointure de fusion, de sorte que toutes les lignes qui peuvent éventuellement se joindre sont garanties d'être traitées par le même thread (violet).
Une dernière chose à noter est que les deux échanges sont préservant l'ordre (alias « fusionner »), comme indiqué dans l'attribut Trier par dans les info-bulles. Cela répond à l'exigence de jointure de fusion selon laquelle les lignes d'entrée doivent être triées sur les clés de jointure. Notez que les échanges ne trient jamais les lignes eux-mêmes, ils peuvent simplement être configurés pour préserver commande existante.
Fil Zéro
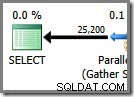
La dernière partie du plan d'exécution se trouve à gauche de l'échange Gather Streams. Il s'exécute toujours sur un seul thread - le même que celui utilisé pour exécuter l'ensemble d'un plan série régulier. Ce thread est toujours étiqueté "Thread 0" dans les plans d'exécution et est parfois appelé le thread "coordinateur" (une désignation que je ne trouve pas particulièrement utile).
Le thread zéro lit les lignes du côté consommateur (gauche) de l'échange Gather Streams et les renvoie au client. Il n'y a pas d'itérateurs de thread zéro en dehors de l'échange dans cet exemple, mais s'il y en avait, ils s'exécuteraient tous sur le même thread unique. Notez que Gather Streams est également un échange de fusion (il a un attribut Order By) :

Des plans parallèles plus complexes peuvent inclure des zones d'exécution en série autres que celle située à gauche de l'échange final Gather Streams. Ces zones série ne sont pas exécutées dans le thread zéro, mais c'est un détail à explorer une autre fois.
Les fils réservés et utilisés revisités
Nous avons vu que ce plan parallèle comporte trois branches. Cela explique pourquoi SQL Server réservé 24 fils (trois branches à DOP 8). La question est de savoir pourquoi seuls 16 threads sont signalés comme "utilisés" dans la capture d'écran ci-dessus.
Il y a deux parties à la réponse. La première partie ne s'applique pas à ce plan, mais il est important de savoir quand même. Le nombre de branches signalées est le nombre maximum pouvant être exécuté simultanément .
Comme vous le savez peut-être, certains opérateurs de plan sont « bloquants », ce qui signifie qu'ils doivent consommer toutes leurs lignes d'entrée avant de pouvoir produire la première ligne de sortie. L'exemple le plus clair d'un opérateur de blocage (également appelé stop-and-go) est Sort. Un tri ne peut pas renvoyer la première ligne d'une séquence triée avant d'avoir vu toutes les lignes d'entrée, car la dernière ligne d'entrée peut être triée en premier.
Les opérateurs avec plusieurs entrées (jointures et unions, par exemple) peuvent être bloquants par rapport à une entrée, mais non bloquants ("en pipeline") par rapport à l'autre. Un exemple de ceci est la jointure par hachage - l'entrée de construction est bloquante, mais l'entrée de sonde est pipelinée. L'entrée de construction est bloquante car elle crée la table de hachage par rapport à laquelle les lignes de sonde sont testées.
La présence d'opérateurs bloquants signifie qu'une ou plusieurs branches parallèles pourraient être assuré de terminer avant que d'autres puissent commencer. Lorsque cela se produit, SQL Server peut réutiliser les threads utilisés pour traiter une branche terminée pour une branche ultérieure dans la séquence. SQL Server est très conservateur en matière de réservation de threads, donc seules les branches qui sont garanties à terminer avant qu'un autre ne commence, utilisez cette optimisation de réservation de threads. Notre plan de requête ne contient aucun opérateur de blocage, de sorte que le nombre de succursales signalé correspond uniquement au nombre total de succursales.
La deuxième partie de la réponse est que les threads peuvent toujours être réutilisés s'ils se produisent à terminer avant qu'un thread d'une autre branche ne démarre. Le nombre total de threads est toujours réservé dans ce cas, mais l'utilisation réelle peut être inférieure. Le nombre de threads qu'un plan parallèle utilise réellement dépend, entre autres, de problèmes de synchronisation et peut varier d'une exécution à l'autre.
Les threads parallèles ne commencent pas tous à s'exécuter en même temps, mais encore une fois, les détails de cela devront attendre une autre occasion. Examinons à nouveau le plan de requête pour voir comment les threads pourraient être réutilisés, malgré l'absence d'opérateurs bloquants :
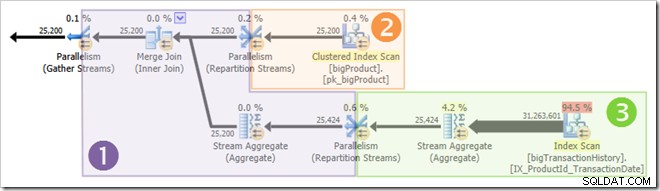
Il est clair que les threads de la branche un ne peuvent pas se terminer avant que les threads des branches deux ou trois ne démarrent, il n'y a donc aucune chance de réutilisation des threads à cet endroit. La branche 3 est également improbable à terminer avant le démarrage de la branche 1 ou de la branche 2, car elle a beaucoup de travail à faire (près de 32 millions de lignes à agréger).
La deuxième branche est une autre affaire. La taille relativement petite de la table des produits signifie qu'il y a de bonnes chances que la branche puisse terminer son travail avant la branche trois démarre. Si la lecture de la table des produits n'entraîne aucune E/S physique, huit threads ne mettront pas longtemps à lire les 25 200 lignes et à les soumettre à l'échange de flux de répartition à la limite orange-violet.
C'est exactement ce qui s'est passé lors des tests utilisés pour les captures d'écran vues jusqu'à présent dans ce post :les huit threads de branche orange se sont terminés assez rapidement pour pouvoir être réutilisés pour la branche verte. Au total, seize threads uniques ont été utilisés, c'est donc ce que rapporte le plan d'exécution.
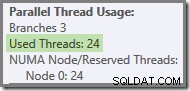
Si la requête est réexécutée avec un cache à froid, le délai introduit par l'E/S physique est suffisant pour garantir que les threads de branche verts démarrent avant que les threads de branche orange ne soient terminés. Aucun thread n'est réutilisé, donc le plan d'exécution signale que les 24 threads réservés ont en fait été utilisés :
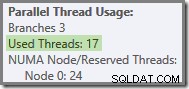
Plus généralement, n'importe quel nombre de 'threads utilisés' entre les deux extrêmes (16 et 24 pour ce plan de requête) est possible :
Enfin, notez que le fil qui exécute la partie série du plan à gauche du dernier Gather Streams n'est pas compté dans les totaux de threads parallèles. Il ne s'agit pas d'un thread supplémentaire ajouté pour permettre une exécution parallèle.
Réflexions finales
La beauté du modèle d'échange utilisé par SQL Server pour implémenter l'exécution parallèle est que toute la complexité de la mise en mémoire tampon et du déplacement des lignes entre les threads est cachée à l'intérieur des opérateurs d'échange (parallélisme). Le reste du plan est divisé en « branches » nettes, délimitées par des échanges. Au sein d'une branche, chaque opérateur se comporte de la même manière que dans un plan en série - dans presque tous les cas, les opérateurs de branche ne savent pas du tout que le plan plus large utilise une exécution parallèle.
La clé pour comprendre l'exécution parallèle est de séparer (mentalement) le plan parallèle aux limites de l'échange et d'imaginer chaque branche comme une série distincte de DOP plans, tous exécutant la simultanéité sur un sous-ensemble distinct de lignes. N'oubliez pas en particulier que chacun de ces plans en série exécute tous les opérateurs de cette branche - SQL Server ne le fait pas exécutez chaque opérateur sur son propre thread !
Comprendre le comportement le plus détaillé nécessite un peu de réflexion, en particulier sur la manière dont les lignes sont routées dans les échanges et sur la manière dont le moteur garantit des résultats corrects, mais la plupart des choses à savoir nécessitent un peu de réflexion, n'est-ce pas ?