Cet article décrit les curseurs SQL et comment les utiliser à des fins particulières. Il met en évidence l'importance des curseurs SQL ainsi que leurs inconvénients.
Ce n'est pas toujours le cas que vous utilisez le curseur SQL dans la programmation de base de données, mais leur compréhension conceptuelle et leur apprentissage de leur utilisation aident beaucoup à comprendre comment effectuer des tâches exceptionnelles dans la programmation T-SQL.
Présentation des curseurs SQL
Passons en revue quelques notions de base sur les curseurs SQL si vous ne les connaissez pas.
Définition simple
Un curseur SQL permet d'accéder aux données une ligne à la fois, vous donnant ainsi plus de contrôle (ligne par ligne) sur le jeu de résultats.
Définition Microsoft
Selon la documentation Microsoft, les instructions Microsoft SQL Server produisent un jeu de résultats complet, mais il arrive parfois que les résultats soient mieux traités une ligne à la fois. L'ouverture d'un curseur sur un jeu de résultats permet de traiter le jeu de résultats une ligne à la fois.
T-SQL et jeu de résultats
Étant donné que les définitions simples et Microsoft du curseur SQL mentionnent un jeu de résultats, essayons de comprendre quel est exactement le jeu de résultats dans le contexte de la programmation de base de données. Créons et remplissons rapidement la table Students dans un exemple de base de données UniversityV3 comme suit :
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
-- (5) Populate Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Sam', N'Database Management System', 85, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (4, N'Adil', N'Database Management System', 85, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (5, N'Naveed', N'Database Management System', 90, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Maintenant, sélectionnez toutes les lignes du Student tableau :
-- View Student table data SELECT [StudentId], [Name], [Course], [Marks], [ExamDate] FROM dbo.Student
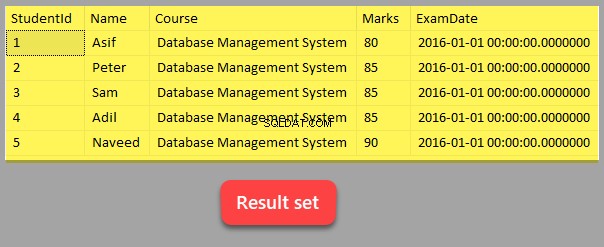
Il s'agit du jeu de résultats renvoyé à la suite de la sélection de tous les enregistrements de l'Étudiant tableau.
T-SQL et théorie des ensembles
T-SQL est purement basé sur les deux concepts mathématiques suivants :
- Théorie des ensembles
- Logique des prédicats
La théorie des ensembles, comme son nom l'indique, est une branche des mathématiques sur les ensembles qui peuvent aussi être appelés collections d'objets distincts définis.
En bref, dans la théorie des ensembles, nous pensons aux choses ou aux objets dans leur ensemble de la même manière que nous pensons à un élément individuel.
Par exemple, l'étudiant est un ensemble de tous les étudiants distincts définis, donc nous prenons un étudiant dans son ensemble, ce qui est suffisant pour obtenir des détails sur tous les étudiants de cet ensemble (tableau).
Veuillez vous référer à mon article The Art of Aggregating Data in SQL from Simple to Sliding Aggregations pour plus de détails.
Curseurs et opérations basées sur les lignes
T-SQL est principalement conçu pour effectuer des opérations basées sur des ensembles telles que la sélection de tous les enregistrements d'une table ou la suppression de toutes les lignes d'une table.
En bref, T-SQL est spécialement conçu pour fonctionner avec des tables d'une manière basée sur des ensembles, ce qui signifie que nous pensons à une table dans son ensemble, et toute opération telle que sélectionner, mettre à jour ou supprimer est appliquée dans son ensemble à la table ou à certains lignes qui satisfont aux critères.
Cependant, il existe des cas où les tables doivent être accessibles ligne par ligne plutôt que comme un seul ensemble de résultats, et c'est à ce moment que les curseurs entrent en action.
Selon Vaidehi Pandere, la logique d'application doit parfois fonctionner avec une ligne à la fois plutôt que toutes les lignes à la fois, ce qui revient à boucler (utiliser des boucles pour itérer) dans l'ensemble du résultat.
Les bases des curseurs SQL avec des exemples
Parlons maintenant plus des curseurs SQL.
Tout d'abord, apprenons ou révisons (ceux qui sont déjà familiarisés avec l'utilisation des curseurs dans T-SQL) comment utiliser le curseur dans T-SQL.
L'utilisation du curseur SQL est un processus en cinq étapes exprimé comme suit :
- Déclarer le curseur
- Ouvrir le curseur
- Récupérer les lignes
- Fermer le curseur
- Désallouer le curseur
Étape 1 :Déclarer le curseur
La première étape consiste à déclarer le curseur SQL afin qu'il puisse être utilisé par la suite.
Le curseur SQL peut être déclaré comme suit :
DECLARE Cursor <Cursor_Name> for <SQL statement>
Étape 2 :Ouvrir le curseur
L'étape suivante après la déclaration consiste à ouvrir le curseur, ce qui signifie remplir le curseur avec le jeu de résultats exprimé comme suit :
Open <Cursor_Name>
Étape 3 :Récupérer les lignes
Une fois le curseur déclaré et ouvert, l'étape suivante consiste à commencer à récupérer les lignes du curseur SQL une par une afin que les lignes récupérées obtiennent la prochaine ligne disponible à partir du curseur SQL :
Fetch Next from <Cursor_Name>
Étape 4 :Fermer le curseur
Une fois les lignes extraites une par une et manipulées selon les besoins, l'étape suivante consiste à fermer le curseur SQL.
La fermeture du curseur SQL effectue trois tâches :
- Libère le jeu de résultats actuellement détenu par le curseur
- Libère tous les verrous de curseur sur les lignes par le curseur
- Ferme le curseur ouvert
La syntaxe simple pour fermer le curseur est la suivante :
Close <Cursor_Name>
Étape 5 :Libérer le curseur
La dernière étape à cet égard consiste à libérer le curseur, ce qui supprime la référence du curseur.
La syntaxe est la suivante :
DEALLOCATE <Cursor_Name>
Compatibilité du curseur SQL
Selon la documentation Microsoft, les curseurs SQL sont compatibles avec les versions suivantes :
- SQL Server 2008 et versions ultérieures
- Base de données SQL Azure
Exemple de curseur SQL 1 :
Maintenant que nous connaissons les étapes nécessaires à l'implémentation du curseur SQL, examinons un exemple simple d'utilisation du curseur SQL :
-- Declare Student cursor example 1 USE UniversityV3 GO DECLARE Student_Cursor CURSOR FOR SELECT StudentId ,[Name] FROM dbo.Student; OPEN Student_Cursor FETCH NEXT FROM Student_Cursor WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM Student_Cursor END CLOSE Student_Cursor DEALLOCATE Student_Cursor
Le résultat est le suivant :

Exemple de curseur SQL 2 :
Dans cet exemple, nous allons utiliser deux variables pour stocker les données détenues par le curseur lorsqu'il se déplace de ligne en ligne afin que nous puissions afficher le jeu de résultats une ligne à la fois en affichant les valeurs des variables.
-- Declare Student cursor with variables example 2
USE UniversityV3
GO
DECLARE @StudentId INT
,@StudentName VARCHAR(40) -- Declare variables to hold row data held by cursor
DECLARE Student_Cursor CURSOR FOR SELECT
StudentId
,[Name]
FROM dbo.Student;
OPEN Student_Cursor
FETCH NEXT FROM Student_Cursor INTO @StudentId, @StudentName -- Fetch first row and store it into variables
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT CONCAT(@StudentId,'--', @StudentName) -- Show variables data
FETCH NEXT FROM Student_Cursor -- Get next row data into cursor and store it into variables
INTO @StudentId, @StudentName
END
CLOSE Student_Cursor -- Close cursor locks on the rows
DEALLOCATE Student_Cursor -- Release cursor reference
Le résultat du code SQL ci-dessus est le suivant :
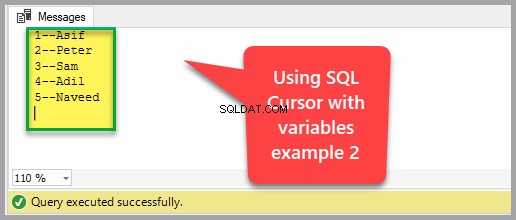
On pourrait dire que nous pouvons obtenir le même résultat en utilisant un simple script SQL comme suit :
-- Viewing student id and name without SQL cursor SELECT StudentId,Name FROM dbo.Student order by StudentId
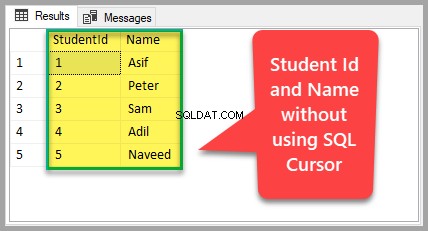
En fait, il existe un certain nombre de tâches qui nécessitent l'utilisation de curseurs SQL malgré le fait qu'il est déconseillé d'utiliser des curseurs SQL en raison de leur impact direct sur la mémoire.
Remarque importante
Veuillez garder à l'esprit que selon Vaidehi Pandere, les curseurs sont un ensemble de pointeurs résidents en mémoire, ils occupent donc la mémoire de votre système qui serait autrement utilisée par d'autres processus importants ; c'est pourquoi parcourir un grand ensemble de résultats à travers des curseurs n'est jamais une bonne idée à moins qu'il n'y ait une raison légitime à cela.
Utilisation des curseurs SQL à des fins spéciales
Nous passerons en revue quelques objectifs particuliers pour lesquels les curseurs SQL peuvent être utilisés.
Test de la mémoire du serveur de base de données
Étant donné que les curseurs SQL ont un impact élevé sur la mémoire système, ils sont de bons candidats pour répliquer des scénarios dans lesquels une utilisation excessive de la mémoire par différentes procédures stockées ou des scripts SQL ad hoc doit être étudiée.
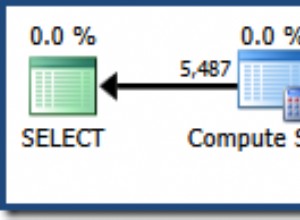
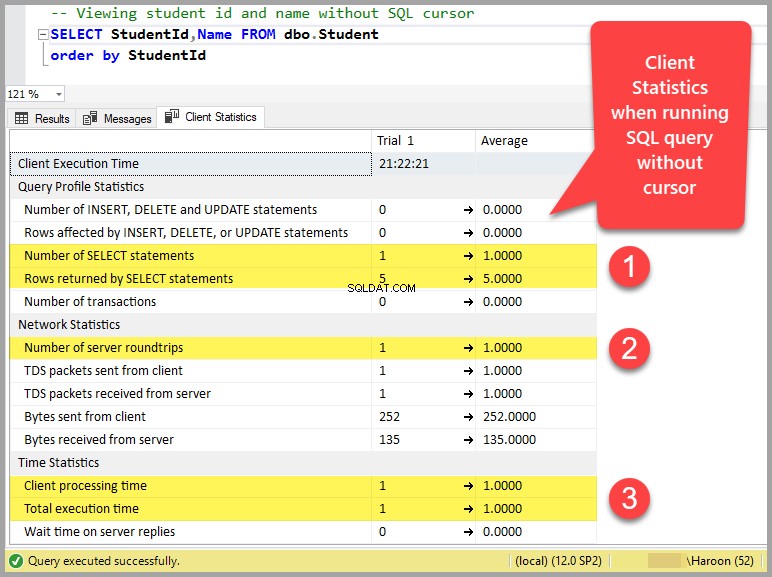
Une façon simple de comprendre cela est de cliquer sur le bouton des statistiques du client dans la barre d'outils (ou d'appuyer sur Maj+Alt+S) dans SSMS (SQL Server Management Studio) et d'exécuter une simple requête sans curseur :
Exécutez maintenant la requête avec le curseur en utilisant des variables (SQL Cursor Example 2):
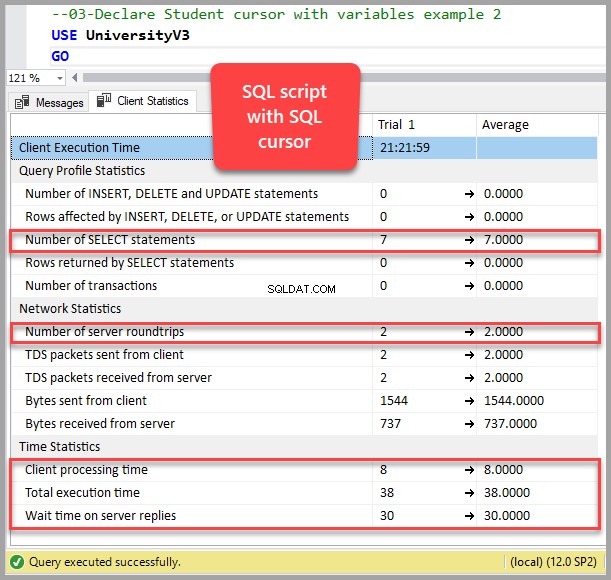
Veuillez maintenant noter les différences :
Nombre d'instructions SELECT sans curseur :1
Nombre d'instructions SELECT avec curseur :7
Nombre d'allers-retours serveur sans curseur :1
Nombre d'allers-retours de serveur avec curseur :2
Temps de traitement client sans curseur :1
Temps de traitement client avec curseur :8
Temps total d'exécution sans curseur :1
Durée totale d'exécution avec le curseur :38
Temps d'attente sur les réponses du serveur sans curseur :0
Temps d'attente sur les réponses du serveur avec le curseur :30
En bref, exécuter la requête sans le curseur qui ne renvoie que 5 lignes équivaut à exécuter la même requête 6 à 7 fois avec le curseur.
Vous pouvez maintenant imaginer à quel point il est facile de reproduire l'impact sur la mémoire à l'aide de curseurs, mais ce n'est pas toujours la meilleure chose à faire.
Tâches de manipulation d'objets de base de données en masse
Il existe un autre domaine où les curseurs SQL peuvent être utiles et c'est lorsque nous devons effectuer une opération en bloc sur des bases de données ou des objets de base de données.
Pour comprendre cela, nous devons d'abord créer la table Course et la remplir dans la UniversityV3 base de données comme suit :
-- Create Course table
CREATE TABLE [dbo].[Course] (
[CourseId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
CONSTRAINT [PK_Course] PRIMARY KEY CLUSTERED ([CourseId] ASC)
);
-- Populate Course table
SET IDENTITY_INSERT [dbo].[Course] ON
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'DevOps for Databases', N'This is about DevOps for Databases')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Power BI Fundamentals', N'This is about Power BI Fundamentals')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (4, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (5, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
SET IDENTITY_INSERT [dbo].[Course] OFF
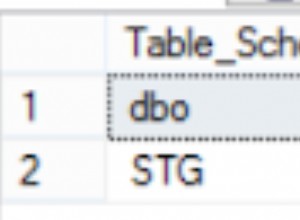
Supposons maintenant que nous voulions renommer toutes les tables existantes dans UniversityV3 base de données sous forme d'ANCIENNES tables.
Cela nécessite une itération du curseur sur toutes les tables une par une afin qu'elles puissent être renommées.
Le code suivant fait le travail :
-- Declare Student cursor to rename all the tables as old
USE UniversityV3
GO
DECLARE @TableName VARCHAR(50) -- Existing table name
,@NewTableName VARCHAR(50) -- New table name
DECLARE Student_Cursor CURSOR FOR SELECT T.TABLE_NAME FROM INFORMATION_SCHEMA.TABLES T;
OPEN Student_Cursor
FETCH NEXT FROM Student_Cursor INTO @TableName
WHILE @@FETCH_STATUS = 0
BEGIN
SET @example@sqldat.com+'_OLD' -- Add _OLD to exsiting name of the table
EXEC sp_rename @TableName,@NewTableName -- Rename table as OLD table
FETCH NEXT FROM Student_Cursor -- Get next row data into cursor and store it into variables
INTO @TableName
END
CLOSE Student_Cursor -- Close cursor locks on the rows
DEALLOCATE Student_Cursor -- Release cursor reference

Félicitations, vous avez renommé avec succès toutes les tables existantes à l'aide du curseur SQL.
Choses à faire
Maintenant que vous êtes familiarisé avec l'utilisation du curseur SQL, essayez les choses suivantes :
- Veuillez essayer de créer et de renommer les index de toutes les tables d'un exemple de base de données via le curseur.
- Veuillez essayer de rétablir les tables renommées dans cet article aux noms d'origine à l'aide du curseur.
- Veuillez essayer de remplir les tableaux avec un grand nombre de lignes et mesurer les statistiques et la durée des requêtes avec et sans le curseur.