L'un des moyens les plus populaires d'obtenir une haute disponibilité pour MySQL est la réplication. La réplication existe depuis de nombreuses années et est devenue beaucoup plus stable avec l'introduction des GTID. Mais même avec ces améliorations, le processus de réplication peut s'interrompre pour diverses raisons - par exemple, lorsque le maître et l'esclave ne sont pas synchronisés parce que les écritures ont été envoyées directement à l'esclave. Comment résolvez-vous les problèmes de réplication et comment les résolvez-vous ?
Dans cet article de blog, nous aborderons certains des problèmes courants liés à la réplication et comment les résoudre avec ClusterControl. Commençons par le premier.
La réplication s'est arrêtée avec une erreur
La plupart des administrateurs de base de données MySQL rencontreront généralement ce type de problème au moins une fois dans leur carrière. Pour diverses raisons, un esclave peut être corrompu ou peut-être arrêter de se synchroniser avec le maître. Lorsque cela se produit, la première chose à faire pour démarrer le dépannage est de vérifier le journal des erreurs pour les messages. La plupart du temps, le message d'erreur est facilement traçable dans le journal des erreurs ou en exécutant la requête SHOW SLAVE STATUS.
Regardons l'exemple suivant de SHOW STATUS SLAVE :
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Nous pouvons clairement voir que l'erreur est liée à l'erreur fatale 1236 du maître lors de la lecture des données du journal binaire :'Impossible de trouver l'état GTID demandé par l'esclave dans les fichiers binlog. L'état de l'esclave est probablement trop ancien et les fichiers binlog requis ont été purgés.'. En d'autres termes, ce que l'erreur nous dit essentiellement, c'est qu'il y a une incohérence dans les données et que les fichiers journaux binaires requis ont déjà été supprimés.
C'est un bon exemple où le processus de réplication cesse de fonctionner. Outre SHOW SLAVE STATUS, vous pouvez également suivre l'état dans l'onglet "Aperçu" du cluster dans ClusterControl. Alors, comment résoudre ce problème avec ClusterControl ? Vous avez deux options à essayer :
-
Vous pouvez essayer de redémarrer l'esclave à partir de "Node Action"
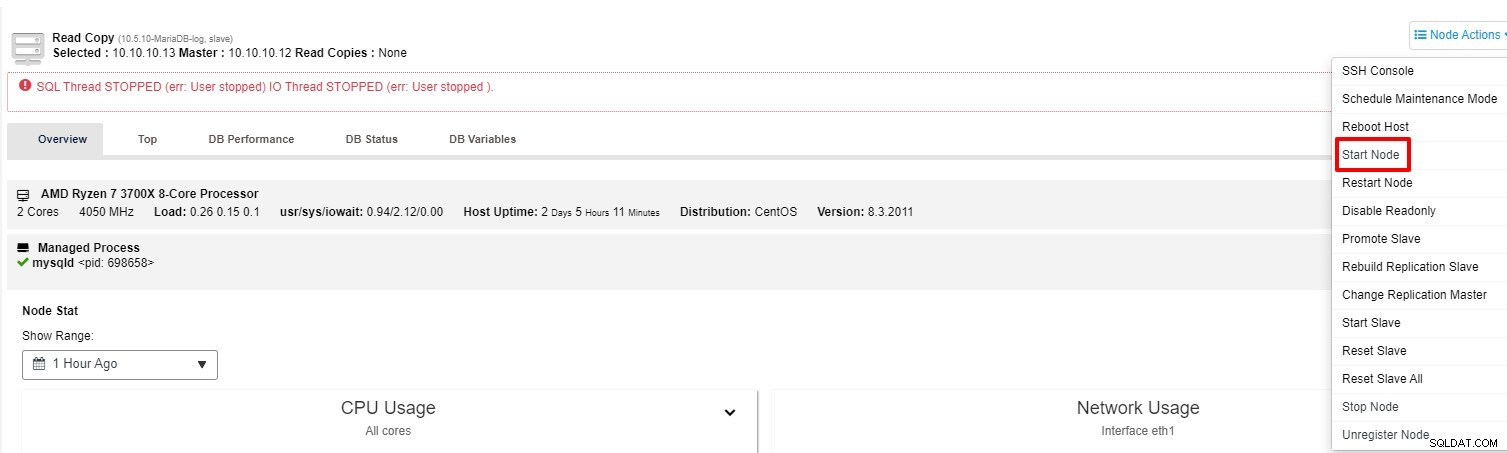
-
Si l'esclave ne fonctionne toujours pas, vous pouvez exécuter la tâche "Rebuild Replication Slave" depuis le "Nœud d'action"
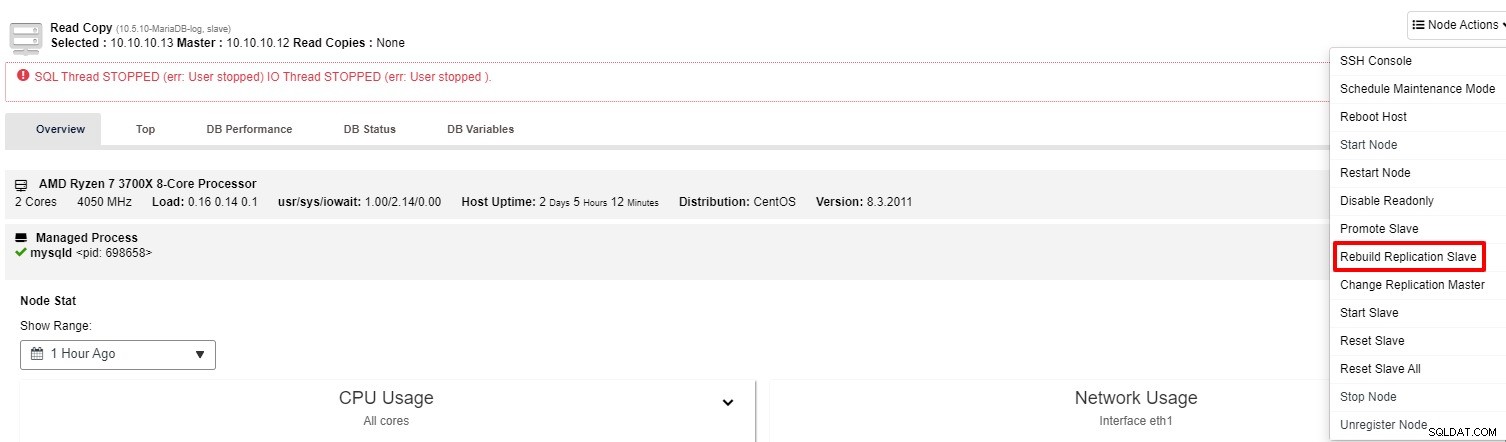
La plupart du temps, la deuxième option résoudra le problème. ClusterControl effectuera une sauvegarde du maître et reconstruira l'esclave défectueux en restaurant les données. Une fois les données restaurées, l'esclave est connecté au maître afin qu'il puisse rattraper son retard.
Il existe également plusieurs façons manuelles de reconstruire l'esclave comme indiqué ci-dessous, vous pouvez également vous référer à ce lien pour plus de détails :
-
Utilisation de Mysqldump pour reconstruire un esclave MySQL incohérent
-
Utiliser Mydumper pour reconstruire un esclave MySQL incohérent
-
Utilisation d'un instantané pour reconstruire un esclave MySQL incohérent
-
Utiliser un Xtrabackup ou Mariabackup pour reconstruire un esclave MySQL incohérent
Promouvoir un esclave pour qu'il devienne un maître
Au fil du temps, le système d'exploitation ou la base de données doit être corrigé ou mis à niveau pour maintenir la stabilité et la sécurité. L'une des meilleures pratiques pour minimiser les temps d'arrêt, en particulier pour une mise à niveau majeure, consiste à promouvoir l'un des esclaves en tant que maître après la réussite de la mise à niveau sur ce nœud particulier.
En effectuant cela, vous pouvez faire pointer votre application vers le nouveau maître et la réplication maître-esclave continuera à fonctionner. En attendant, vous pouvez également procéder à la mise à niveau sur l'ancien maître en toute tranquillité d'esprit. Avec ClusterControl, cela peut être exécuté en quelques clics uniquement en supposant que la réplication est configurée en tant que Global Transaction ID ou GTID en abrégé. Pour éviter toute perte de données, il vaut la peine d'arrêter toute requête d'application au cas où l'ancien maître fonctionnerait correctement. Ce n'est pas la seule situation que vous pourriez promouvoir l'esclave. Dans le cas où le nœud maître est en panne, vous pouvez également effectuer cette action.
Sans ClusterControl, il y a quelques étapes pour promouvoir l'esclave. Chacune des étapes nécessite également l'exécution de quelques requêtes :
-
Désactiver manuellement le maître
-
Sélectionnez l'esclave le plus avancé pour être un maître et préparez-le
-
Reconnecter les autres esclaves au nouveau maître
-
Changer l'ancien maître en esclave
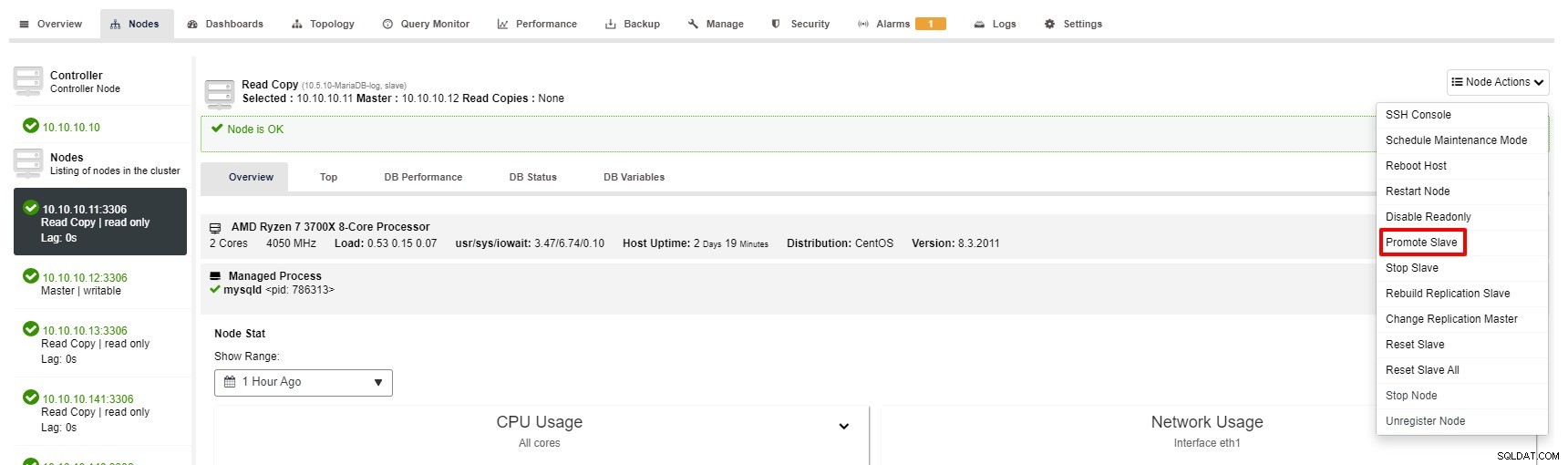
Néanmoins, les étapes pour Promouvoir l'Esclave avec ClusterControl ne sont que quelques clics :Cluster> Nœuds> choisissez le nœud esclave> Promouvoir l'Esclave selon la capture d'écran ci-dessous :
Le maître devient indisponible
Imaginez que vous avez de grosses transactions à exécuter mais que la base de données est en panne. Peu importe à quel point vous êtes prudent, c'est probablement la situation la plus grave ou la plus critique pour une configuration de réplication. Lorsque cela se produit, votre base de données n'est pas en mesure d'accepter une seule écriture, ce qui est mauvais. De plus, vos applications ne fonctionneront bien sûr pas correctement.
Il y a quelques raisons ou causes qui conduisent à ce problème. Certains des exemples sont les pannes matérielles, la corruption du système d'exploitation, la corruption de la base de données, etc. En tant que DBA, vous devez agir rapidement pour restaurer la base de données principale.
Grâce à la fonction de cluster "Auto Recovery" disponible dans ClusterControl, le processus de basculement peut être automatisé. Il peut être activé ou désactivé en un seul clic. Comme son nom l'indique, ce qu'il fera, c'est afficher toute la topologie du cluster si nécessaire. Par exemple, une réplication maître-esclave doit avoir au moins un maître actif à tout moment, quel que soit le nombre d'esclaves disponibles. Lorsque le maître n'est pas disponible, il promeut automatiquement l'un des esclaves.
Regardons la capture d'écran ci-dessous :
Dans la capture d'écran ci-dessus, nous pouvons voir que la "récupération automatique" est activée pour le cluster et le nœud. Dans la topologie, notez que l'adresse IP principale actuelle est 10.10.10.11. Que se passera-t-il si nous supprimons le nœud maître à des fins de test ?
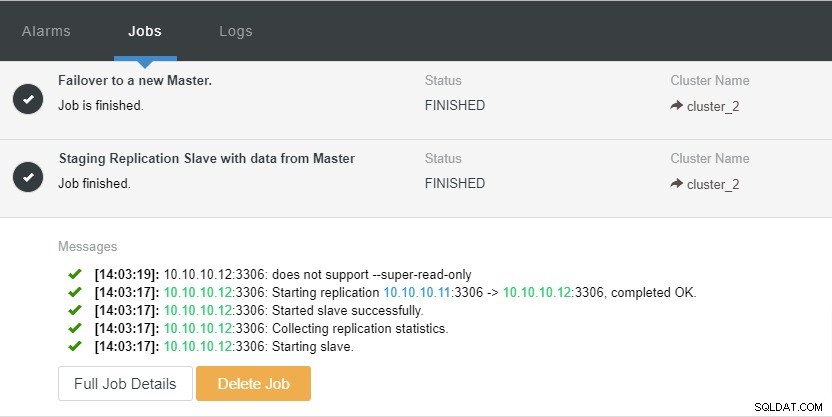
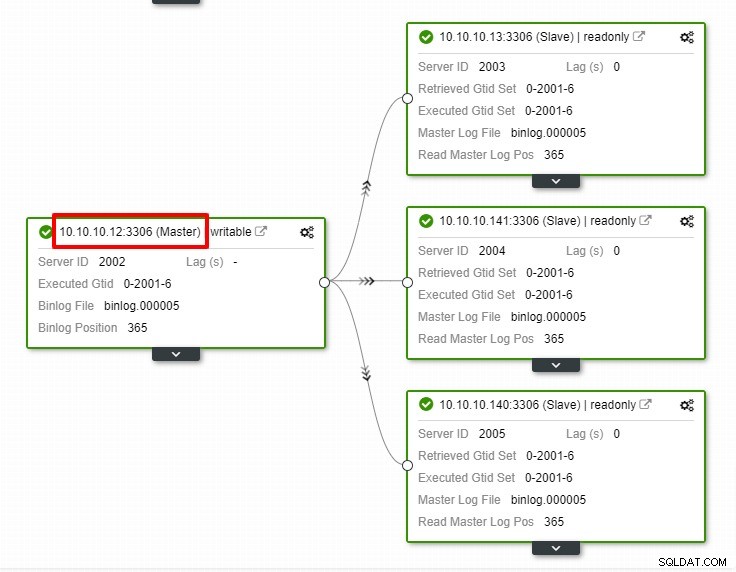
Comme vous pouvez le voir, le nœud esclave avec IP 10.10.10.12 est automatiquement promu maître, afin que la topologie de réplication soit reconfigurée. Au lieu de le faire manuellement, ce qui, bien sûr, impliquera de nombreuses étapes, ClusterControl vous aide à maintenir votre configuration de réplication en vous évitant les tracas.
Conclusion
Dans tout événement malheureux avec votre réplication, le correctif est très simple et moins compliqué avec ClusterControl. ClusterControl vous aide à résoudre rapidement vos problèmes de réplication, ce qui augmente la disponibilité de vos bases de données.