FILESTREAM a été introduit par Microsoft en 2008. Le but était de stocker et de gérer plus efficacement les fichiers non structurés. Avant l'introduction de FILESTREAM, les approches suivantes étaient utilisées pour stocker les données dans le serveur SQL :
- Les fichiers non structurés peuvent être stockés dans la colonne VARBINARY ou IMAGE d'une table SQL Server. Cette approche est efficace pour maintenir la cohérence transactionnelle et réduit la complexité de la gestion des fichiers, mais lorsque l'application cliente lit les données de la table SQL, elle utilise la mémoire SQL, ce qui entraîne de mauvaises performances.
- Au lieu de stocker le fichier entier dans la table SQL, stockez l'emplacement physique du fichier non structuré dans la table SQL. Cette approche améliore considérablement les performances, mais ne garantit pas la cohérence transactionnelle. En outre, la gestion des fichiers était également difficile.
La fonctionnalité FILESTREAM est très efficace car elle permet de stocker des fichiers BLOB dans le système de fichiers NT et maintient la cohérence transactionnelle. Lorsqu'une application cliente lit les données du conteneur FILESTREAM, au lieu d'utiliser la mémoire du tampon SQL Server, elle utilise le cache système Nthe T, ce qui améliore les performances.
FILESTREAM n'est pas un type de données. C'est un attribut qui peut être affecté à la colonne VARBINARY(MAX). Lorsque la colonne VARBINARY(MAX) est affectée à l'attribut FILESTREAM, elle est appelée colonne FILESTREAM. Les données stockées dans la colonne FILESTREAM seront stockées dans le système NT en tant que fichier disque et le pointeur du fichier est stocké dans la table. La colonne VARBINARY(max) avec l'attribut FILESTREAM affecté n'a pas de limite de stockage de 2 Go dans la table. Par conséquent, nous pouvons également stocker des fichiers volumineux.
Dans cet article, je vais démontrer comme suit :
- Comment activer la fonctionnalité FILESTREAM.
- Comment créer et configurer des groupes de fichiers FILESTREAM et un conteneur de données FILESTREAM.
- Comment stocker et accéder aux données des tables compatibles FILESTREAM.
Démo :
Dans cette démo, je vais utiliser :
- Serveur de base de données :SQL Server 2017
- Logiciel :SQL Server Management Studio
- Base de données :FileStream_Demo
Configurer l'accès FILESTREAM dans la base de données SQL Server
Pour configurer FileStream dans SQL Server, apportez les modifications suivantes à SQL Server.
- Activez la fonctionnalité FILESTREAM à partir du gestionnaire de configuration SQL Server.
- Activer le niveau d'accès FILESTREAM sur l'instance SQL Server
- Créez un groupe de fichiers FILESTREAM et un conteneur FileStream pour stocker les données BLOB.
Activer la fonctionnalité FILESTREAM
Pour activer FileStream sur n'importe quelle base de données, activez d'abord la fonctionnalité FileStream sur l'instance SQL Server. Pour ce faire, ouvrez le gestionnaire de configuration SQL Server, cliquez avec le bouton droit sur Instance SQL, sélectionnez Propriétés , comme illustré dans l'image suivante :
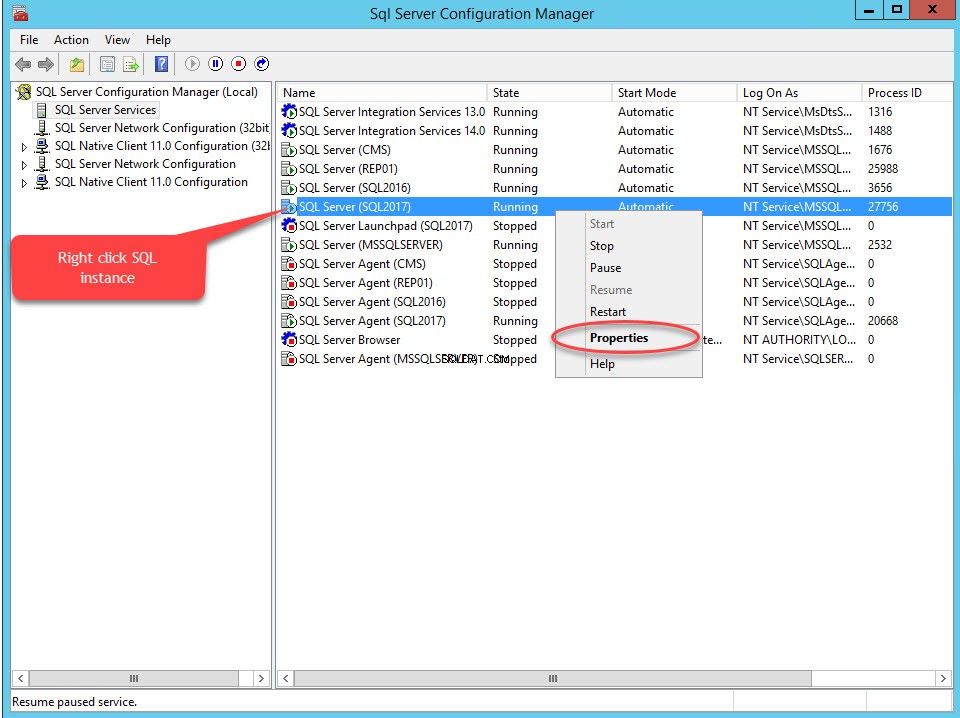
Une boîte de dialogue permettant de configurer les propriétés du serveur s'ouvre. Passer au FILESTREAM languette. Sélectionnez Activer FILESTREAM pour l'accès T-SQL . Sélectionnez Activer FILESTREAM pour l'accès aux E/S puis sélectionnez Autoriser l'accès client distant aux données FILESTREAM . Dans le nom de partage Windows zone de texte, indiquez le nom du répertoire dans lequel stocker les fichiers. Voir l'image suivante :
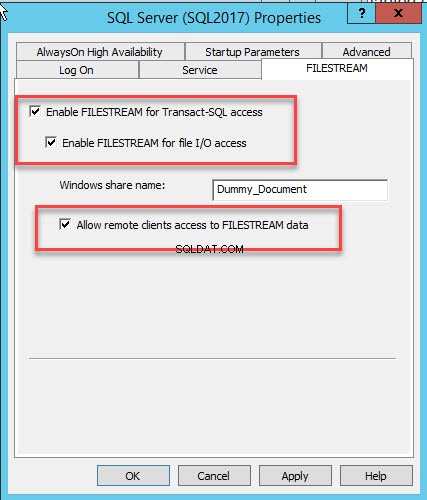
Cliquez sur OK et redémarrez le service SQL.
Activer le niveau d'accès FILESTREAM sur l'instance SQL Server
Une fois la fonction FILESTREAM activée, modifiez le niveau d'accès FILESTREAM. Pour modifier le niveau d'accès FileStream, exécutez la requête suivante :
EXEC sp_configure filestream_access_level, 2 RECONFIGURE
Dans la requête ci-dessus, les paramètres ci-dessous sont des valeurs valides :
0 signifie la prise en charge de FILESTREAM pour l'instance SQL est désactivée.
1 signifie la prise en charge de FILESTREAM pour T-SQL est activée.
2 signifie la prise en charge de FILESTREAM pour l'accès en continu T-SQL et Win32 est activée.
Vous pouvez modifier le niveau d'accès FILESTREAM à l'aide de SQL Server Management Studio. Pour ce faire, faites un clic droit sur une connexion SQL Server>> sélectionnez Propriétés>> Dans la boîte de dialogue des propriétés du serveur, sélectionnez Niveau d'accès FileStream dans la liste déroulante, puis sélectionnez Accès complet activé , comme illustré dans l'image suivante :
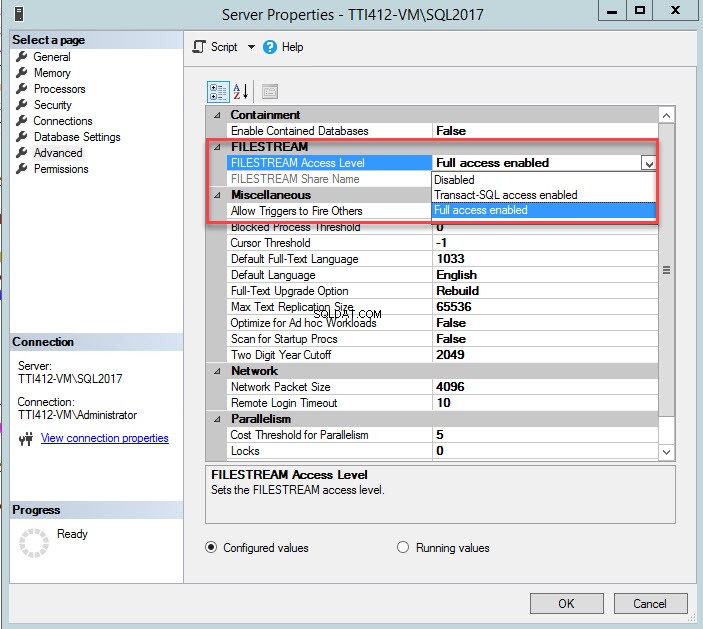
Une fois le paramètre modifié, redémarrez les services SQL Server.
Ajouter un groupe de fichiers FILESTREAM et des fichiers de données
Une fois FILESTREAM activé, ajoutez le groupe de fichiers FILESTREAM et le conteneur FILESTREAM.
Pour ce faire, cliquez avec le bouton droit sur FileStream-Demo base de données>> sélectionnez Propriétés>> Dans un volet de gauche des Propriétés de la base de données boîte de dialogue, sélectionnez Groupes de fichiers>> Dans la grille FILESTREAM, cliquez sur Ajouter un groupe de fichiers bouton>> Nommez le groupe de fichiers en tant que Dummy Document . Voir l'image suivante :
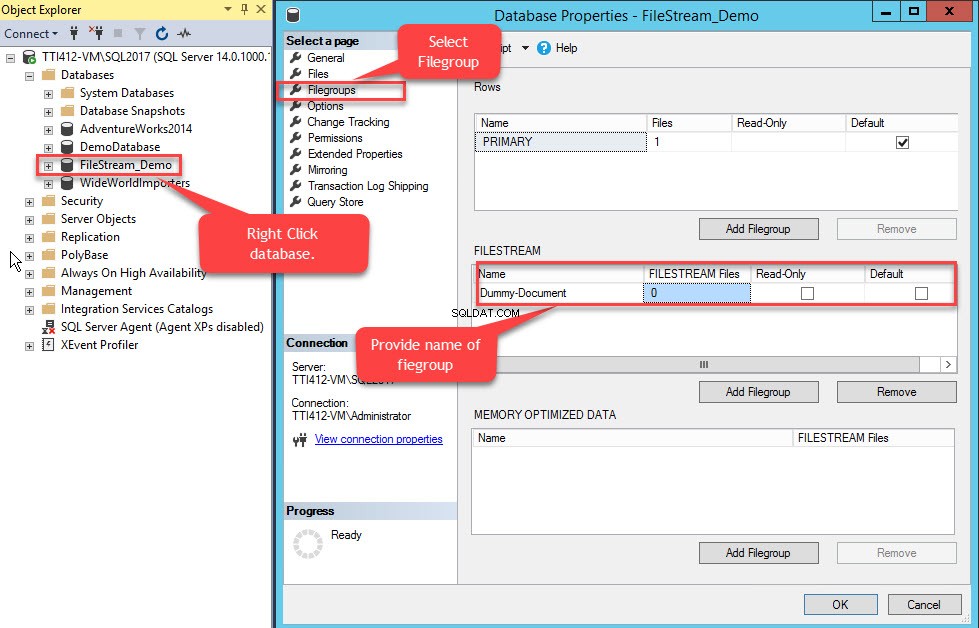
Une fois le groupe de fichiers créé, dans la boîte de dialogue Propriétés de la base de données, sélectionnez fichiers et cliquez sur le bouton Ajouter. La grille Fichiers de base de données active. Dans la colonne Nom logique, indiquez le nom, – Dummy-Document . Sélectionnez Données FILESTREAM dans le Type de fichier boîte déroulante. Sélectionnez Dummy-Document dans le groupe de fichiers colonne. Dans le Chemin colonne, indiquez l'emplacement du répertoire où les fichiers seront stockés (E:\Dummy-Documents). Voir l'image suivante :
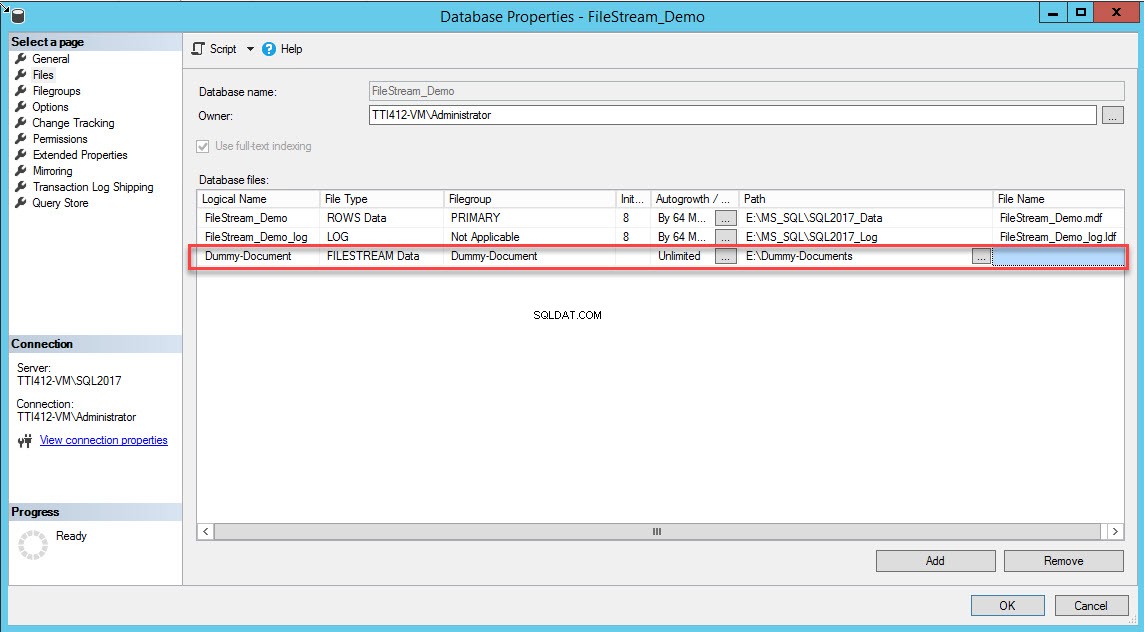
Vous pouvez également ajouter le groupe de fichiers FILESTREAM et les conteneurs en exécutant la requête T-SQL suivante :
USE [master] GO ALTER DATABASE [FileStream_Demo] ADD FILEGROUP [Dummy-Documents] CONTAINS FILESTREAM GO ALTER DATABASE [FileStream_Demo] ADD FILE ( NAME = N'Dummy-Documents', FILENAME = N'E:\Dummy-Documents' ) TO FILEGROUP [Dummy-Documents] GO
Pour vérifier que le conteneur FileStream a été créé, ouvrez l'Explorateur Windows et accédez au répertoire "E:\Dummy-Document".
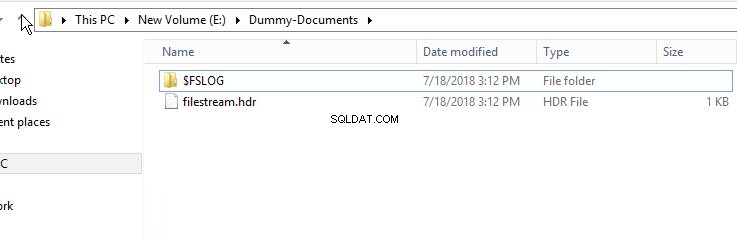
Comme indiqué dans l'image ci-dessus, le répertoire $FSLOG et le fichier filestream.hdr fichier ont été créés. $FSLOG est comme le serveur SQL T-Log et filestream.hdr contient les métadonnées de FILESTREAM. Assurez-vous de ne pas modifier ou modifier ces fichiers.
Stocker les fichiers dans la table SQL
Dans cette démo, nous allons créer une table pour stocker divers fichiers de l'ordinateur. Le tableau comporte les colonnes suivantes :
- Le "RootDirectory ” colonne pour stocker l'emplacement du fichier.
- Le "nom de fichier ” colonne pour stocker le nom du fichier.
- Le "FileAttribute ” pour stocker l'attribut File (Raw/Directory.
- La "FileCreateDate ” pour stocker l'heure de création du fichier.
- La valeur "FileSize ” pour stocker la taille du fichier.
- Le "FileStreamCol ” colonne pour stocker le contenu du fichier au format binaire.
Créer une table SQL avec une colonne FILESTREAM
Une fois FILESTREAM configuré, créez une table SQL avec les colonnes FILESTREAM pour stocker divers fichiers dans la table du serveur SQL. Comme je l'ai mentionné ci-dessus, FILESTREAM n'est pas un type de données. C'est un attribut que nous ajoutons à la colonne varbinary(max) dans la table compatible FILESTREAM. Lorsque vous créez une table compatible FILESTREAM, assurez-vous d'ajouter un UNIQUEIDENTIFIER colonne contenant le ROWGUIDCOL et UNIQUES attributs.
Exécutez le script suivant pour créer une table compatible FILESTREAM :
Use [FileStream_Demo]
go
Create Table [DummyDocuments]
(
ID uniqueidentifier ROWGUIDCOL unique NOT NULL,
RootDirectory varchar(max),
FileName varchar(max),
FileAttribute varchar(150),
FileCreateDate datetime,
FileSize numeric(10,5),
FileStreamCol varbinary (max) FILESTREAM
) Insérer des données dans le tableau
J'ai le WorldWide_Importors.xls document stocké sur l'ordinateur à l'emplacement « E:\Documents ». Utilisez OPENROWSET (en vrac) pour charger son contenu du disque vers le VARBINARY(max) variable. Stockez ensuite la variable dans FileStreamCol (VARBINARY(max)) colonne du DummyDocumen t table. Pour ce faire, exécutez le script suivant :
Use [FileStream-Demo]
Go
DECLARE @Document AS VARBINARY(MAX)
-- Load the image data
SELECT @Document = CAST(bulkcolumn AS VARBINARY(MAX))
FROM OPENROWSET(
BULK
'E:\Documents\WorldWide_Importors.xls',
SINGLE_BLOB ) AS Doc
-- Insert the data to the table
INSERT INTO [DummyDocuments] (ID, RootDirectory,FileName, FileAttribute, FileCreateDate,FileSize,FileStreamCol)
SELECT NEWID(), 'E:\Documents','WorldWide_Importors.xls','Raw',getdate(),10, @Document Accéder aux données FILESTREAM
Les données FILESTREAM sont accessibles à l'aide de T-SQL et de l'API gérée. Lorsque la colonne FILESTREAM est accédée à l'aide d'une requête T-SQL, elle utilise la mémoire SQL pour lire le contenu du fichier de données et envoyer les données à l'application cliente. Lorsque la colonne FILESTREAM est accessible à l'aide de l'API managée Win32, elle n'utilise pas la mémoire SQL Server. Il utilise la capacité de diffusion en continu du système de fichiers NT, ce qui améliore les performances.
Accéder aux données FILESTREAM à l'aide de T-SQL
Comme je l'ai mentionné au début de l'article, FILESTREAM est un attribut affecté à une colonne de table qui a le type de données varbinary(max), par conséquent, il est accessible comme n'importe quelle autre colonne de la table. Pour récupérer les données FILESTREAM avec toutes les informations de la table, exécutez la requête ci-dessous
Use [FileStream-Demo] go select RootDirectory,FileName,FileAttribute,FileCreateDate,FileSize,FileStreamCol from DummyDocuments
Ci-dessous le résultat de la requête :

Comme le montre l'image ci-dessus, le document "WorldWide_Importors.xls" a été converti en un BLOB stocké dans la colonne "FileStreamCol".
Accéder aux données FILESTREAM à l'aide de l'API gérée
Bien que l'accès à FILESTREAM à l'aide de l'API Win32 offre des performances et d'autres avantages, il a des syntaxes différentes et difficiles que les syntaxes T-SQL, ce qui rend difficile l'accès aux données. Premièrement, pour localiser le fichier sur le magasin de données FILESTREAM, nous devons identifier le chemin logique pour identifier le fichier dans le magasin de données FILESTREAM de manière unique. Nous pouvons le faire en utilisant le Pathname() méthode de la colonne FILESTREAM. Il est sensible à la casse.
Après avoir récupéré le chemin du fichier, pour y accéder, nous devons obtenir le contexte de la transaction en utilisant le Begin Transaction méthode. Une fois le contexte de la transaction obtenu, nous pouvons y accéder en utilisant le SQLFileStream classe.
Le code ci-dessous obtient le chemin local vers WorldWide_Importors.xls document dans le magasin de données FILESTREAM.
SELECT
RootDirectory,
FileName,
FileAttribute,
FileCreateDate,
FileSize,
FileStreamCol.PathName() AS FilePath
FROM DummyDocuments Résultat de la requête :

Supprimer les fichiers du conteneur FILESTREAM
La suppression de fichiers est simple. Vous devez exécuter la requête de suppression pour supprimer le fichier de la table SQL compatible FILESTREAM. Même si l'enregistrement a été supprimé des tables, le fichier sera physiquement disponible dans le magasin de données FILSTREAM. Il sera supprimé par Garbage Collector. Le processus Garbage Collector s'exécute lorsque l'événement de point de contrôle se produit. En donnant un point de contrôle explicite, vous pouvez le supprimer immédiatement après l'avoir supprimé du tableau.
Requête pour supprimer des fichiers de la table SQL :
Use [FileStream_Demo] go delete from DummyDocuments where ID='0D640ABC-8CF1-41E0-9FA8-28171047129F'
Résumé
Dans cet article, j'ai couvert :
- Présentation de FILESTREAM et quels en sont les avantages.
- Comment activer la fonctionnalité FILESTREAM sur une instance de serveur SQL.
- Créer et configurer le magasin de données FILESTREAM et les groupes de fichiers.
- Effectuez l'insertion et la suppression de fichiers à partir du magasin de données FILESTREAM.
Dans de prochains articles, je vais vous expliquer :
- Comment sauvegarder et restaurer une base de données compatible FILESTREAM.
- Configuration de la réplication et de la répartition des tables dans les tables FILESTREAM
Restez à l'écoute !