Pensez-vous à quelque chose lorsque vous créez une nouvelle base de données ? Je suppose que la plupart d'entre vous diraient non, puisque nous utilisons tous des paramètres par défaut, bien qu'ils soient loin d'être optimaux. Cependant, il existe un tas de paramètres de disque, et ils aident vraiment à augmenter la fiabilité et les performances du système.
Nous ne parlerons pas de l'importance du système de fichiers NTFS pour la fiabilité des données, bien que ce système de fichiers permette à MS SQL Server d'utiliser le disque de la manière la plus efficace.
Si vous manquez de ressources et que quelque chose commence à fonctionner lentement, la première chose qui vous vient à l'esprit est la mise à niveau. Mais la mise à niveau n'est pas nécessaire dans tous les cas. Vous pouvez vous en sortir avec le réglage, même si cela ne doit pas être fait lorsque le serveur commence à fonctionner lentement, mais au stade de la conception et de l'installation.
L'optimisation est un processus complexe et est souvent liée non seulement à un certain programme (dans notre cas, à une certaine base de données), mais également au système d'exploitation et au matériel. Bien que nous parlions principalement de bases de données, nous ne pouvons pas ignorer les choses extérieures.
Architecture des données
SQL Server stocke, lit et écrit des données par blocs de 8 Ko chacun. Ces blocs sont appelés pages. Une base de données peut stocker 128 pages par mégaoctet (1 mégaoctet ou 1048576 octets divisé par 8 kilooctets ou 8192 octets). Toutes les pages sont stockées dans une extension. Une extension correspond aux 8 dernières pages séquentielles ou 64 Ko. Ainsi, 1 mégaoctet stocke 16 extensions.
Les pages et les extensions constituent la base de la structure physique de la base de données SQL Server. MS SQL Server utilise différents types de pages, certains d'entre eux suivent l'espace alloué, certains contiennent des données utilisateur et des index. Les pages qui suivent l'espace alloué contiennent les données densément compressées. Il permet à MS SQL Server de les stocker efficacement en mémoire pour une lecture facile.
SQL Server utilise deux types d'extensions :
- Les étendues qui stockent des pages de deux à plusieurs objets sont appelées étendues mixtes. Chaque table commence par une étendue mixte. Vous utilisez une étendue mixte principalement pour les pages qui stockent de l'espace et contiennent de petits objets.
- Les étendues dont les 8 pages sont attribuées à un seul objet sont appelées étendues uniformes. Ils sont utilisés lorsqu'une table ou un index nécessite plus de 64 Ko.
La première étendue de chaque fichier est uniforme et contient les pages de l'en-tête du fichier, les étendues suivantes contiennent chacune 3 pages allouées. Le serveur alloue ces étendues mixtes lorsque vous créez un fichier de données de base et utilise ces pages pour ses tâches internes. La page d'en-tête de fichier contient des attributs de fichier, tels que le nom de la base de données stockée dans le fichier, le groupe de fichiers, la taille minimale, la taille d'incrément. Il s'agit de la première page de chaque fichier (page 0).
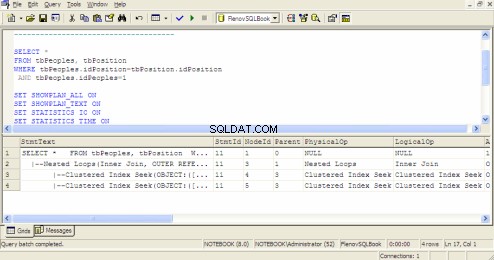
Plan d'exécution des requêtes dans l'Analyseur de requêtes SQL
Espace libre de la page (PFS ) dans une page allouée qui contient des informations sur l'espace libre disponible dans le fichier. Ces informations sont stockées sur la page 1. Chacune de ces pages peut s'étendre jusqu'à 8 000 pages contiguës, soit environ 64 Mo de données.
Le journal des transactions collecte toutes les informations sur les changements qui ont lieu sur le serveur pour restaurer une base de données au moment d'une erreur système et pour assurer l'intégrité des données.
Notez que tous les nombres sont des multiples de 8 ou 16. En effet, le contrôleur de disque dur lit plus facilement les données de cette taille. Les données sont lues à partir du disque par pages, c'est-à-dire par 8 kilo-octets, ce qui est une valeur tout à fait optimale.
Protection des pages
Depuis MS SQL Server 2005, le serveur de base de données propose une nouvelle option :le contrôle des données au niveau de la page. Si le AGE_VERIFY_CHECKSUM est activé (il est activé par défaut), le serveur contrôlera les sommes de contrôle des pages. Si nous examinons le manuel de ce paramètre, nous verrons que la somme de contrôle permet de suivre les erreurs d'entrée/sortie que le système d'exploitation est incapable de suivre. De quel genre d'erreurs s'agit-il ? Il semble qu'il s'agisse de problèmes internes au serveur de base de données.
La vérification de l'intégrité des données ne va jamais mal, il est donc préférable de l'activer. Pour cela, nous devons exécuter la commande suivante :
ALTER DATABASE имя базы SET PAGE_VERIFY
S'il y a une erreur sur la page, le serveur nous en informera. Mais comment y remédier rapidement ? Il existe une option pour restaurer les données au niveau de la page pour cela.
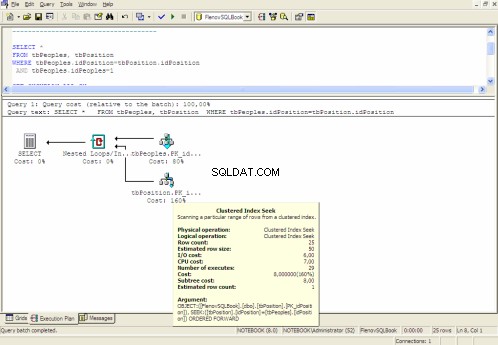
Plan d'exécution graphique
Croissance des fichiers
Lorsque nous créons une base de données, nous sommes invités à sélectionner la taille initiale et la méthode d'incrémentation. Lorsque nous manquons d'espace actuel, le serveur l'étend en correspondance avec la méthode d'incrémentation prédéfinie.
Il existe trois méthodes d'incrémentation pour les fichiers :
- Croissance en mégaoctets.
- Croissance en pourcentage
- Croissance manuelle.
Les deux premières méthodes sont exécutées automatiquement, mais elles ne sont recommandées que pour les bases de données de test car un administrateur n'a aucun contrôle sur la taille du fichier.
Si un fichier est incrémenté d'un certain nombre de mégaoctets, à un moment donné, la vitesse d'insertion des données peut augmenter et la croissance du fichier peut devenir trop fréquente, ce qui entraîne des coûts supplémentaires. La croissance des fichiers en pourcentage n'est pas non plus rentable. Il est recommandé d'utiliser une croissance de fichier de 10 % et cela convient aux petites et moyennes bases de données. Mais lorsqu'il atteint 1000 gigaoctets, il faudra 100 gigaoctets à chaque croissance. Cela conduira à un gaspillage inutile d'espace disque.
Contrôlez toujours les modifications de la taille des fichiers et des journaux de transactions. Cela vous permettra d'utiliser les ressources du disque de la manière la plus efficace.
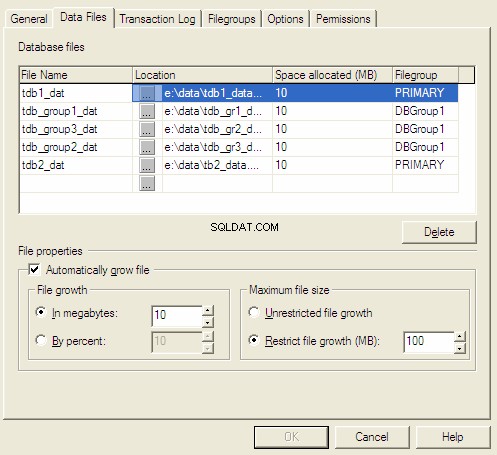
Propriétés de la base de données MS SQL Server
Compression des données
Le disque dur reste un endroit sensible d'un ordinateur. Les performances des processeurs augmentent de manière vertigineuse, tandis que les disques durs ne peuvent pas offrir quelque chose de nouveau. Pour économiser le nombre d'opérations d'entrée/sortie et réduire les données stockées sur le disque dur, vous pouvez utiliser des disques avec compression. Seuls ces disques conviennent au stockage de groupes de fichiers en lecture seule. C'est peut-être parce que la compression est nécessaire pour les écritures, et cela nécessite des coûts de processeur supplémentaires.
La compression des données et l'état en lecture seule sont bons pour les données d'archivage. Par exemple, les données comptables des années passées ne sont pas nécessaires à l'écriture et peuvent prendre trop de place. En plaçant les données dans la section d'archivage du disque, vous gagnerez beaucoup d'espace.
Des disques pour la fiabilité
La méthode suivante permet d'augmenter la fiabilité et les performances en même temps, et encore une fois, elle est liée aux disques durs. Eh bien, voilà, la mécanique n'est pas seulement la plus lente mais la moins fiable. Quant à la fiabilité, je n'ai pas collecté les statistiques, mais à la maison comme au travail, je m'occupe surtout de disques durs.
Ainsi, pour augmenter les performances et la fiabilité, vous pouvez simplement utiliser deux disques durs ou plus au lieu d'un. Ce sera encore mieux s'ils seront connectés à des contrôleurs séparés. Vous pouvez stocker la base de données sur un disque et les journaux de transactions sur un autre. S'il y a un troisième disque, il peut stocker le système.
Stocker des données et un journal sur des disques séparés vous permet d'augmenter considérablement la fiabilité. Supposons que vous ayez tout sur un disque et qu'il tombe en panne. Que faire? Vous pouvez contacter une entreprise qui essaiera de tout récupérer ou essayer de faire la même chose par vous-même, mais les chances de récupération sont loin d'être de 100 %. En outre, le retour du serveur au travail peut prendre un temps considérable. La récupération rapide ne peut être effectuée qu'au moment de la dernière copie de sauvegarde. Le reste est discutable.
Et maintenant, supposons que vous ayez des données et un journal des transactions sur différents disques. Si le disque avec le journal s'éteint, les données seront toujours là. La seule chose est que vous ne pouvez pas ajouter de nouvelles données, mais si vous créez un nouveau journal, vous pouvez continuer à travailler.
Si le disque contenant les données s'éteint, nous pouvons toujours réserver le journal des transactions pour éviter la moindre perte de données. Après cela, nous récupérons les données de la sauvegarde complète (cela doit toujours être fait au préalable, un bon administrateur le fait au moins une fois par jour) et ajoutons des modifications à partir de la copie de sauvegarde du journal.
Disques pour la performance
Si les données et un journal sont situés sur des disques séparés, cela signifie non seulement la sécurité mais aussi la croissance des performances. Le fait est que le serveur de base de données peut écrire simultanément des données dans le journal et le fichier de données.
Nous pouvons aller plus loin et allouer un disque dur au journal des transactions et plusieurs disques durs aux données. Le serveur travaille plus souvent avec des données, c'est pourquoi il nécessite plusieurs stockages avec lesquels vous pouvez travailler en même temps. Et si ces stockages sont connectés à différents contrôleurs, le travail simultané est garanti.
La variante la plus rapide et la plus fiable consiste à utiliser RAID . Cependant, tous les RAID est fiable et rapide à la fois. Pour les groupes de fichiers, il est recommandé de choisir RAID10 , car il contient des fonctionnalités bien équilibrées, mais en fonction des données de la base de données, vous pouvez choisir une autre variante.
Vous pouvez utiliser une solution logicielle ou matérielle comme RAID . Une solution logicielle est moins chère, mais elle nécessite des ressources CPU supplémentaires. Et un processeur n'a pas de ressources de réserve. C'est pourquoi il est préférable d'utiliser des solutions matérielles où une puce dédiée est responsable du RAID .
Index
Tout le monde sait que les index aident à augmenter la vitesse de recherche des données. La plupart d'entre nous comprennent que les index affectent négativement l'insertion et la mise à jour des données, donc plus vous avez d'index, plus il est difficile pour le serveur de les maintenir. À cela, peu de gens pensent même que les index nécessitent une maintenance. Les pages de base de données contenant des données d'index peuvent déborder et éventuellement devenir déséquilibrées.
Oui, nous pouvons ignorer divers paramètres et simplement recréer des index une fois par mois, ce qui est similaire à la maintenance. SQL Server inclut deux paramètres qui empêchent les index d'être obsolètes une demi-heure après leur création :FILLFACTOR et PAD_INDEX .
Vous pouvez utiliser l'option FILLFACTOR pour optimiser les performances des opérations d'insertion et de mise à jour qui contiennent un index cluster ou non cluster. Les données d'index peuvent être stockées dans de nombreuses pages de données. Comme je l'ai mentionné ci-dessus, chaque page se compose de 8 Ko. Lorsqu'une page d'index est pleine, le serveur crée une nouvelle page et divise la page d'insertion de données en deux.
Le serveur a besoin de temps pour la division de la page et la création d'une nouvelle page. Pour optimiser la division de la page, utilisez le FILLFACTOR option pour déterminer le pourcentage d'espace libre sur toutes les feuilles de la page d'index. Plus l'espace disque des pages de niveau feuille est grand, moins vous aurez à diviser les pages d'index fréquemment. À cela, l'arborescence d'index sera trop grande et son contournement prendra plus de temps.
Le PAD_INDEX L'option indique le pourcentage de remplissage des pages non-feuilles. Vous pouvez utiliser PAD_INDEX uniquement lorsque le FILLFACTOR l'option est spécifiée depuis la valeur en pourcentage de PAD_INDEX dépend du pourcentage spécifié dans FILLFACTOR .
Statistiques
Les statistiques permettent au serveur de prendre la bonne décision entre l'utilisation de l'index et l'analyse complète de la table. Supposons que vous ayez une liste d'employés d'un atelier de fonderie. Cette liste sera composée d'environ 90 % d'hommes.
Maintenant, supposons que nous ayons besoin de trouver toutes les femmes. Comme il n'y en a pas beaucoup, l'option la plus efficace sera d'utiliser l'index. Mais si nous devons trouver tous les hommes, l'efficacité de l'indice ralentit. Le nombre d'enregistrements sélectionnés est trop grand et le contournement de l'arborescence d'index pour chacun d'eux sera une surcharge. Il est beaucoup plus simple de parcourir toute la table entière - l'exécution sera beaucoup plus rapide car le serveur devra lire toutes les feuilles de bas niveau de l'index une fois sans avoir besoin de plusieurs lectures de tous les niveaux.
SQL Server collecte des statistiques en lisant toutes les valeurs de champ ou avec un modèle pour la création de la liste de valeurs distribuées et triées uniformément. SQL Server détecte dynamiquement le pourcentage de lignes qui doivent être testées sur la base du nombre de lignes dans la table. Lors de la collecte de statistiques, l'optimiseur de requêtes exécutera soit une analyse complète, soit des modèles de ligne.
Pour que les statistiques fonctionnent, elles doivent être créées. En cas de mise à jour massive des données, les statistiques peuvent contenir des données incorrectes et le serveur prendra une mauvaise décision. Mais tout peut être corrigé, – vous devez surveiller les statistiques. Pour plus d'informations, reportez-vous aux livres sur Transact-SQL ou MS SQL Server.
Résumé
Les paramètres par défaut ne permettent pas d'utiliser tout le potentiel du matériel et de travailler avec toute la variété des serveurs. La responsabilité des paramètres incombe aux administrateurs. Le fait que les produits Microsoft disposent de programmes d'installation simples, d'utilitaires d'administration graphiques et de la possibilité de travailler hors ligne ne signifie pas qu'il s'agit d'une variante optimale.
Nous ne considérons pas ces options de réglage de base de données comme une accélération matérielle. Si toutes les options de réglage sont épuisées, il est préférable de penser à la mise à niveau, car l'accélération matérielle affecte négativement la fiabilité du système.
La chose la plus importante est que toute optimisation du serveur de base de données ou toute mise à niveau n'aidera pas si les requêtes ne sont pas optimisées.



