Une configuration de cluster de réplication maître/esclave est un cas d'utilisation courant dans la plupart des organisations. L'utilisation de la réplication MySQL permet à vos données d'être répliquées dans différents environnements et garantit que les informations seront copiées. Il est asynchrone et monothread (par défaut), mais la réplication vous permet également de le configurer pour qu'il soit synchrone (ou en fait "semi-synchrone") et peut exécuter un thread esclave sur plusieurs threads ou en parallèle.
Cette idée est très courante et arrive généralement avec une configuration simple, faisant de son esclave sa fonction de récupération ou de solutions de sauvegarde. Cependant, cela a toujours un prix, en particulier lorsque de mauvaises requêtes (telles que le manque de clés primaires ou uniques) sont répliquées ou des problèmes avec le matériel (tels que des problèmes de réseau ou d'E/S de disque). Lorsque ces problèmes surviennent, le problème le plus courant auquel il faut faire face est le décalage de réplication.
Un décalage de réplication est le coût du retard pour les transactions ou les opérations calculé par sa différence de temps d'exécution entre le nœud principal/maître et le nœud de secours/esclave. Les cas les plus certains dans MySQL reposent sur la réplication de mauvaises requêtes, telles que le manque de clés primaires ou de mauvais index, un matériel réseau médiocre ou une carte réseau défectueuse, un emplacement distant entre différentes régions ou zones, ou certains processus tels que l'exécution de sauvegardes physiques peuvent causer votre base de données MySQL pour retarder l'application de la transaction répliquée en cours. C'est un cas très courant lors du diagnostic de ces problèmes. Dans ce blog, nous verrons comment traiter ces cas et ce qu'il faut rechercher si vous rencontrez un retard de réplication MySQL.
Le "SHOW SLAVE STATUS" :le mantra du DBA MySQL
Dans certains cas, c'est la solution miracle lorsqu'il s'agit de retard de réplication et cela révèle principalement tout ce qui cause un problème dans votre base de données MySQL. Exécutez simplement cette instruction SQL dans votre nœud esclave suspecté d'avoir un retard de réplication.
Les champs initiaux qui sont communs à tracer pour les problèmes sont,
- Slave_IO_State - Il vous indique ce que fait le fil. Ce champ vous fournira de bonnes informations si la santé de la réplication fonctionne normalement, si vous rencontrez des problèmes de réseau tels que la reconnexion à un maître ou si vous prenez trop de temps pour valider les données, ce qui peut indiquer des problèmes de disque lors de la synchronisation des données sur le disque. Vous pouvez également déterminer cette valeur d'état lors de l'exécution de SHOW PROCESSLIST.
- Master_Log_File - Nom du fichier binlog du maître dans lequel le thread d'E/S est actuellement récupéré.
- Read_Master_Log_Pos - position du fichier binlog à partir du maître où le thread d'E/S de réplication a déjà lu.
- Relay_Log_File - le nom du fichier journal de relais pour lequel le thread SQL exécute actuellement les événements
- Relay_Log_Pos - position binlog du fichier spécifié dans Relay_Log_File pour lequel le thread SQL a déjà été exécuté.
- Relay_Master_Log_File - Le fichier binlog du maître que le thread SQL a déjà exécuté et qui correspond à la valeur Read_Master_Log_Pos.
- Seconds_Behind_Master - ce champ affiche une approximation de la différence entre l'horodatage actuel sur l'esclave et l'horodatage sur le maître pour l'événement en cours de traitement sur l'esclave. Cependant, ce champ peut ne pas être en mesure de vous indiquer le décalage exact si le réseau est lent car la différence en secondes est prise entre le thread SQL esclave et le thread d'E/S esclave. Il peut donc y avoir des cas où il peut être rattrapé par un thread d'E/S esclave à lecture lente, mais je maîtrise que c'est déjà différent.
- Slave_SQL_Running_State - état du thread SQL et la valeur est identique à la valeur d'état affichée dans SHOW PROCESSLIST.
- Retrieved_Gtid_Set - Disponible lors de l'utilisation de la réplication GTID. Il s'agit de l'ensemble des GTID correspondant à toutes les transactions reçues par cet esclave.
- Executed_Gtid_Set - Disponible lors de l'utilisation de la réplication GTID. C'est l'ensemble des GTID écrits dans le journal binaire.
Par exemple, prenons l'exemple ci-dessous qui utilise une réplication GTID et connaît un décalage de réplication :
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.10.70
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000038
Read_Master_Log_Pos: 826608419
Relay_Log_File: relay-bin.000004
Relay_Log_Pos: 468413927
Relay_Master_Log_File: binlog.000038
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 826608206
Relay_Log_Space: 826607743
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 251
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 45003
Master_UUID: 36272880-a7b0-11e9-9ca6-525400cae48b
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: copy to tmp table
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:7631-9192
Executed_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:1-9191,
864dd532-a7af-11e9-85f2-525400cae48b:1-173,
df68c807-a7af-11e9-9b56-525400cae48b:1-4
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Diagnostiquer des problèmes comme celui-ci, mysqlbinlog peut également être votre outil pour identifier quelle requête a été exécutée sur une position binlog x &y spécifique. Pour le déterminer, prenons Retrieved_Gtid_Set, Relay_Log_Pos et Relay_Log_File. Voir la commande ci-dessous :
[example@sqldat.com mysql]# mysqlbinlog --base64-output=DECODE-ROWS --include-gtids="36272880-a7b0-11e9-9ca6-525400cae48b:9192" --start-position=468413927 -vvv relay-bin.000004
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 468413927
#200206 4:36:14 server id 45003 end_log_pos 826608271 CRC32 0xc702eb4c GTID last_committed=1562 sequence_number=1563 rbr_only=no
SET @@SESSION.GTID_NEXT= '36272880-a7b0-11e9-9ca6-525400cae48b:9192'/*!*/;
# at 468413992
#200206 4:36:14 server id 45003 end_log_pos 826608419 CRC32 0xe041ec2c Query thread_id=24 exec_time=31 error_code=0
use `jbmrcd_date`/*!*/;
SET TIMESTAMP=1580963774/*!*/;
SET @@session.pseudo_thread_id=24/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
ALTER TABLE NewAddressCode ADD INDEX PostalCode(PostalCode)
/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
/*!50003 SET example@sqldat.com_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;Il nous indique qu'il essayait de répliquer et d'exécuter une instruction DML qui tente d'être la source du décalage. Cette table est une immense table contenant 13M de lignes.
Vérifiez SHOW PROCESSLIST, SHOW ENGINE INNODB STATUS, avec la combinaison de commandes ps, top, iostat
Dans certains cas, SHOW SLAVE STATUS n'est pas suffisant pour nous dire le coupable. Il est possible que les instructions répliquées soient affectées par des processus internes exécutés dans l'esclave de la base de données MySQL. L'exécution des instructions SHOW [FULL] PROCESSLIST et SHOW ENGINE INNODB STATUS fournit également des données informatives qui vous donnent un aperçu de la source du problème.
Par exemple, disons qu'un outil d'analyse comparative est en cours d'exécution, provoquant la saturation des E/S et du processeur du disque. Vous pouvez vérifier en exécutant les deux instructions SQL. Combinez-le avec les commandes ps et top.
Vous pouvez également déterminer les goulots d'étranglement avec votre stockage sur disque en exécutant iostat qui fournit des statistiques sur le volume actuel que vous essayez de diagnostiquer. L'exécution d'iostat peut montrer à quel point votre serveur est occupé ou chargé. Par exemple, pris par un esclave qui est en retard mais qui connaît également une utilisation élevée des E/S en même temps,
[example@sqldat.com ~]# iostat -d -x 10 10
Linux 3.10.0-693.5.2.el7.x86_64 (testnode5) 02/06/2020 _x86_64_ (2 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.42 3.71 60.65 218.92 568.39 24.47 0.15 2.31 13.79 1.61 0.12 0.76
dm-0 0.00 0.00 3.70 60.48 218.73 568.33 24.53 0.15 2.36 13.85 1.66 0.12 0.76
dm-1 0.00 0.00 0.00 0.00 0.04 0.01 21.92 0.00 63.29 2.37 96.59 22.64 0.01
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.20 392.30 7983.60 2135.60 49801.55 12.40 36.70 3.84 13.01 3.39 0.08 69.02
dm-0 0.00 0.00 392.30 7950.20 2135.60 50655.15 12.66 36.93 3.87 13.05 3.42 0.08 69.34
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.06 183.67 0.00 183.67 61.67 1.85
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.40 370.93 6775.42 2557.04 46184.22 13.64 43.43 6.12 11.60 5.82 0.10 73.25
dm-0 0.00 0.00 370.93 6738.76 2557.04 47029.62 13.95 43.77 6.20 11.64 5.90 0.10 73.41
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.03 107.00 0.00 107.00 35.67 1.07
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 299.80 7253.35 1916.88 52766.38 14.48 30.44 4.59 15.62 4.14 0.10 72.09
dm-0 0.00 0.00 299.80 7198.60 1916.88 51064.24 14.13 30.68 4.66 15.70 4.20 0.10 72.57
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.10 215.50 8939.60 1027.60 67497.10 14.97 59.65 6.52 27.98 6.00 0.08 72.50
dm-0 0.00 0.00 215.50 8889.20 1027.60 67495.90 15.05 60.07 6.60 28.09 6.08 0.08 72.75
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 32.33 0.00 32.33 30.33 0.91
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.90 140.40 8922.10 625.20 54709.80 12.21 11.29 1.25 9.88 1.11 0.08 68.60
dm-0 0.00 0.00 140.40 8871.50 625.20 54708.60 12.28 11.39 1.26 9.92 1.13 0.08 68.83
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 27.33 0.00 27.33 9.33 0.28
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.70 284.50 8621.30 24228.40 51535.75 17.01 34.14 3.27 8.19 3.11 0.08 72.78
dm-0 0.00 0.00 290.90 8587.10 25047.60 53434.95 17.68 34.28 3.29 8.02 3.13 0.08 73.47
dm-1 0.00 0.00 0.00 2.00 0.00 8.00 8.00 0.83 416.45 0.00 416.45 63.60 12.72
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.30 851.60 11018.80 17723.60 85165.90 17.34 142.59 12.44 7.61 12.81 0.08 99.75
dm-0 0.00 0.00 845.20 10938.90 16904.40 83258.70 17.00 143.44 12.61 7.67 12.99 0.08 99.75
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.10 24.60 12965.40 420.80 51114.45 7.93 39.44 3.04 0.33 3.04 0.07 93.39
dm-0 0.00 0.00 24.60 12890.20 420.80 51114.45 7.98 40.23 3.12 0.33 3.12 0.07 93.35
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 3.60 13420.70 57.60 51942.00 7.75 0.95 0.07 0.33 0.07 0.07 92.11
dm-0 0.00 0.00 3.60 13341.10 57.60 51942.00 7.79 0.95 0.07 0.33 0.07 0.07 92.08
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00Le résultat ci-dessus affiche l'utilisation élevée des E/S et un nombre élevé d'écritures. Il révèle également que la taille moyenne de la file d'attente et la taille moyenne des requêtes évoluent, ce qui indique une charge de travail élevée. Dans ces cas, vous devez déterminer s'il existe des processus externes qui amènent MySQL à étouffer les threads de réplication.
Comment ClusterControl peut-il vous aider ?
Avec ClusterControl, gérer le retard de l'esclave et déterminer le coupable est très simple et efficace. Il vous le dit directement dans l'interface utilisateur Web, voir ci-dessous :
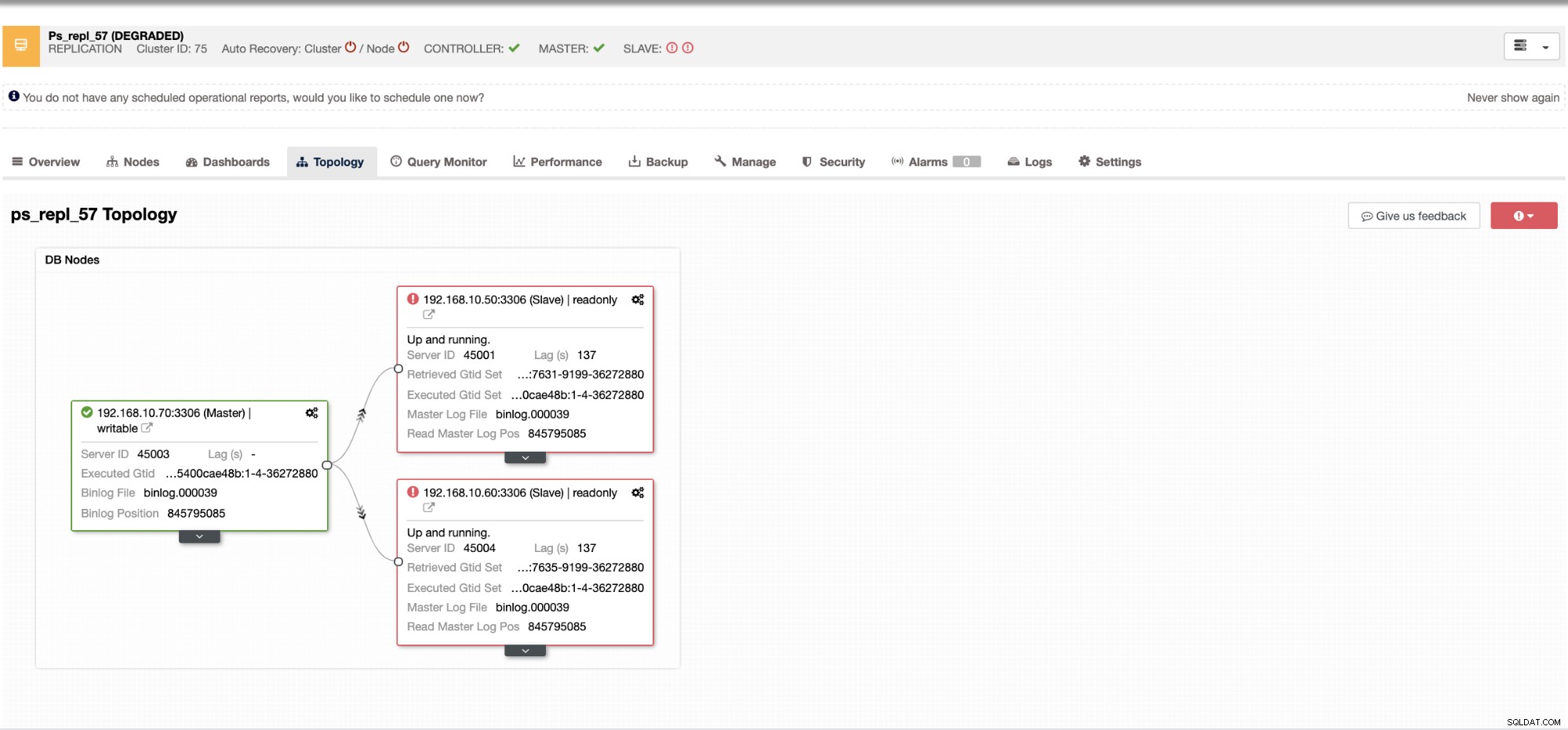
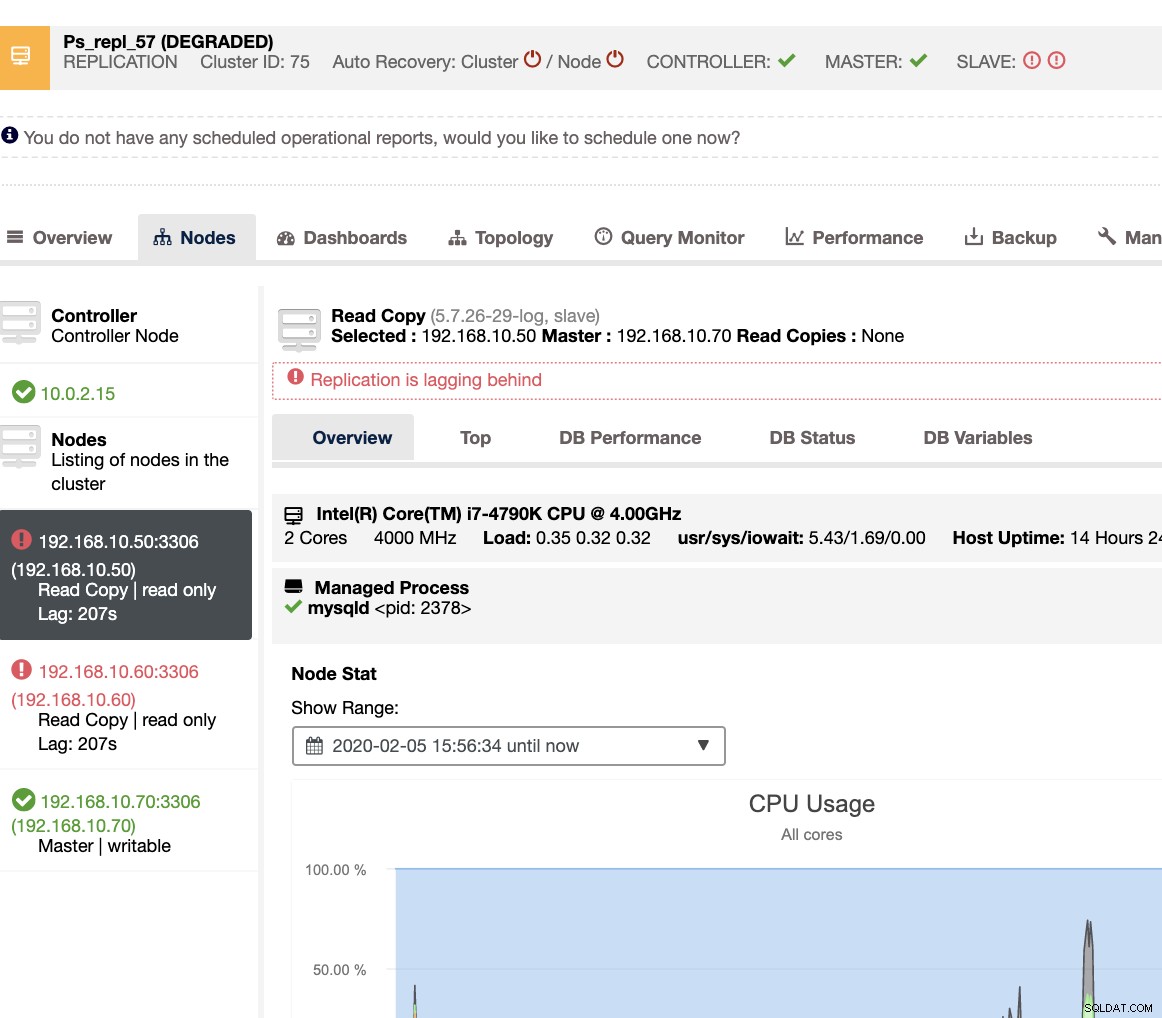
Il vous révèle le décalage actuel de vos nœuds esclaves. De plus, les tableaux de bord SCUMM, s'ils sont activés, vous fournissent plus d'informations sur l'état de santé de votre nœud esclave ou même sur l'ensemble du cluster :
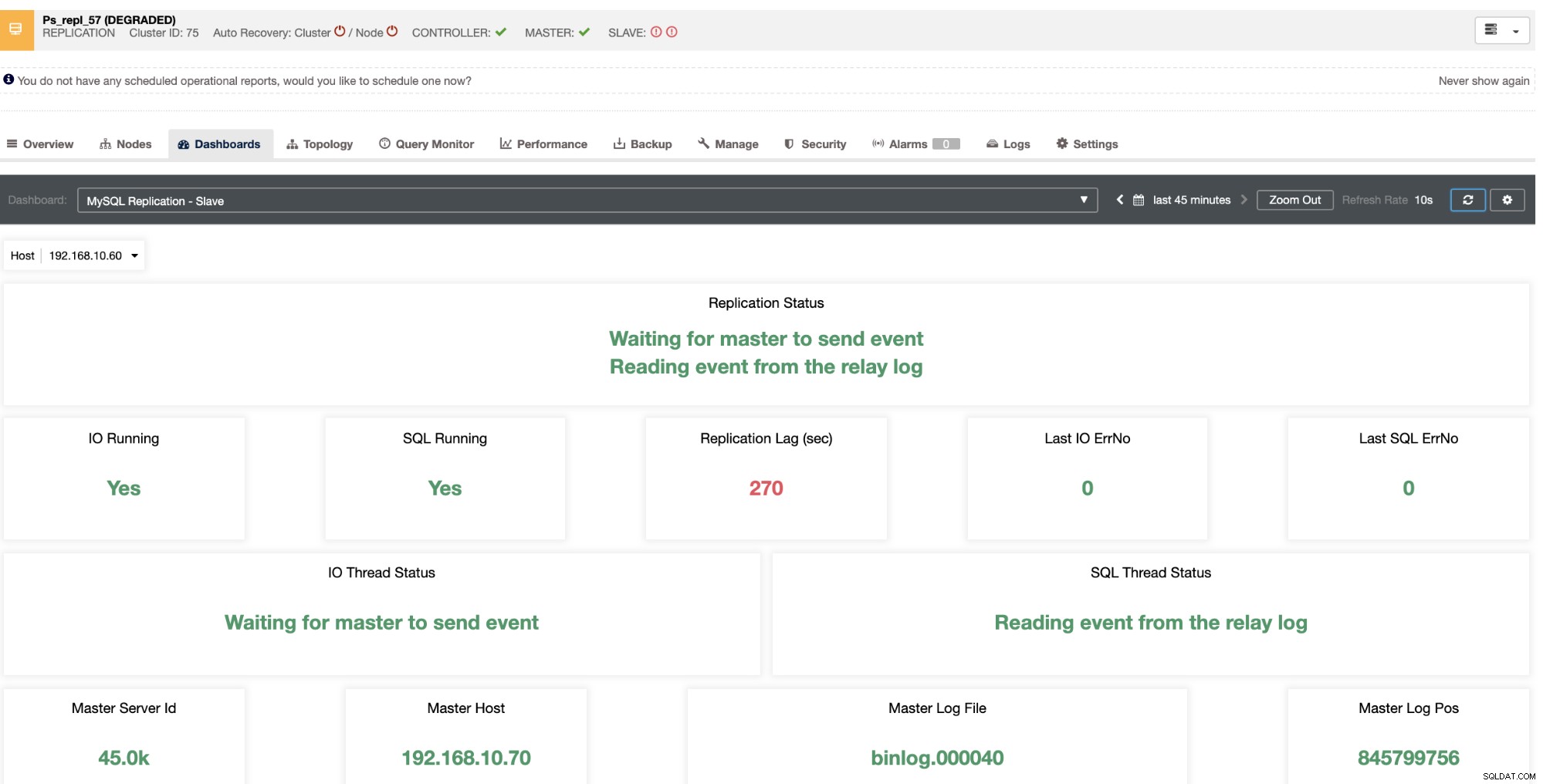


Non seulement ces éléments sont disponibles dans ClusterControl, mais ils vous fournissent également la possibilité d'éviter les mauvaises requêtes avec ces fonctionnalités, comme indiqué ci-dessous,
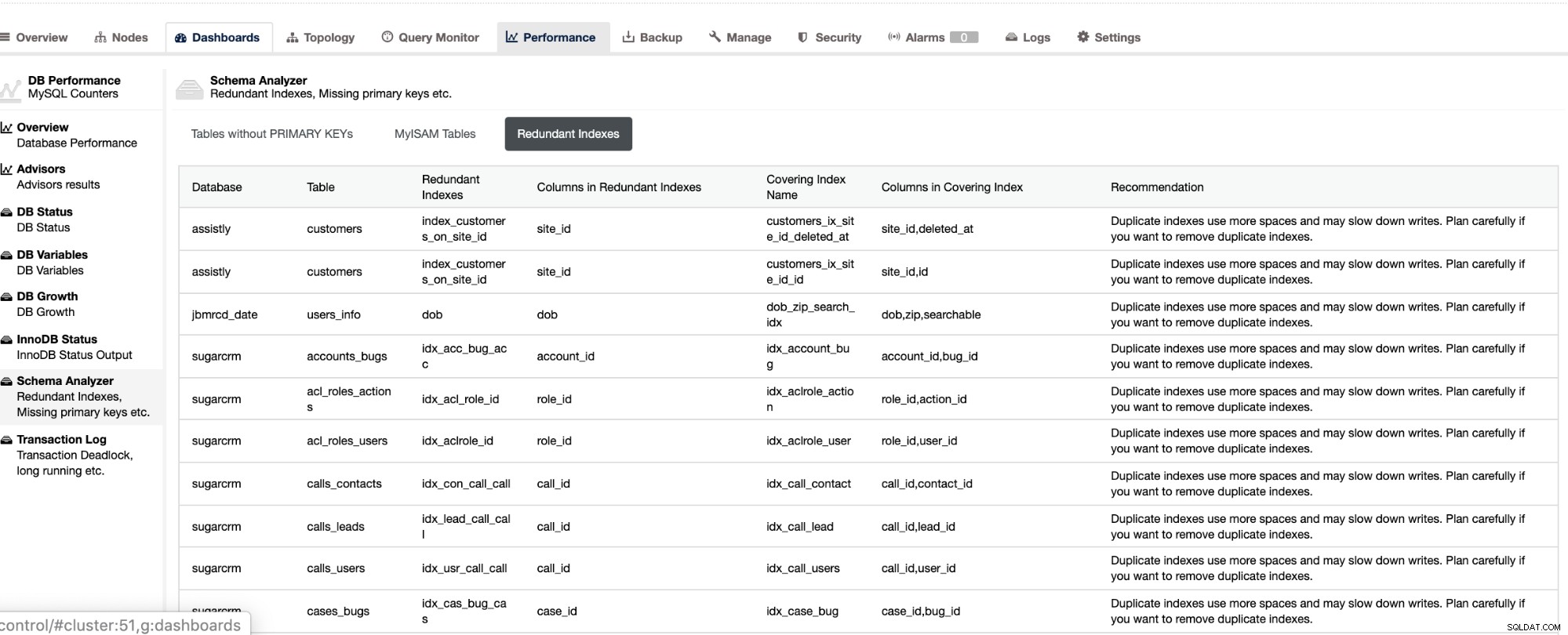
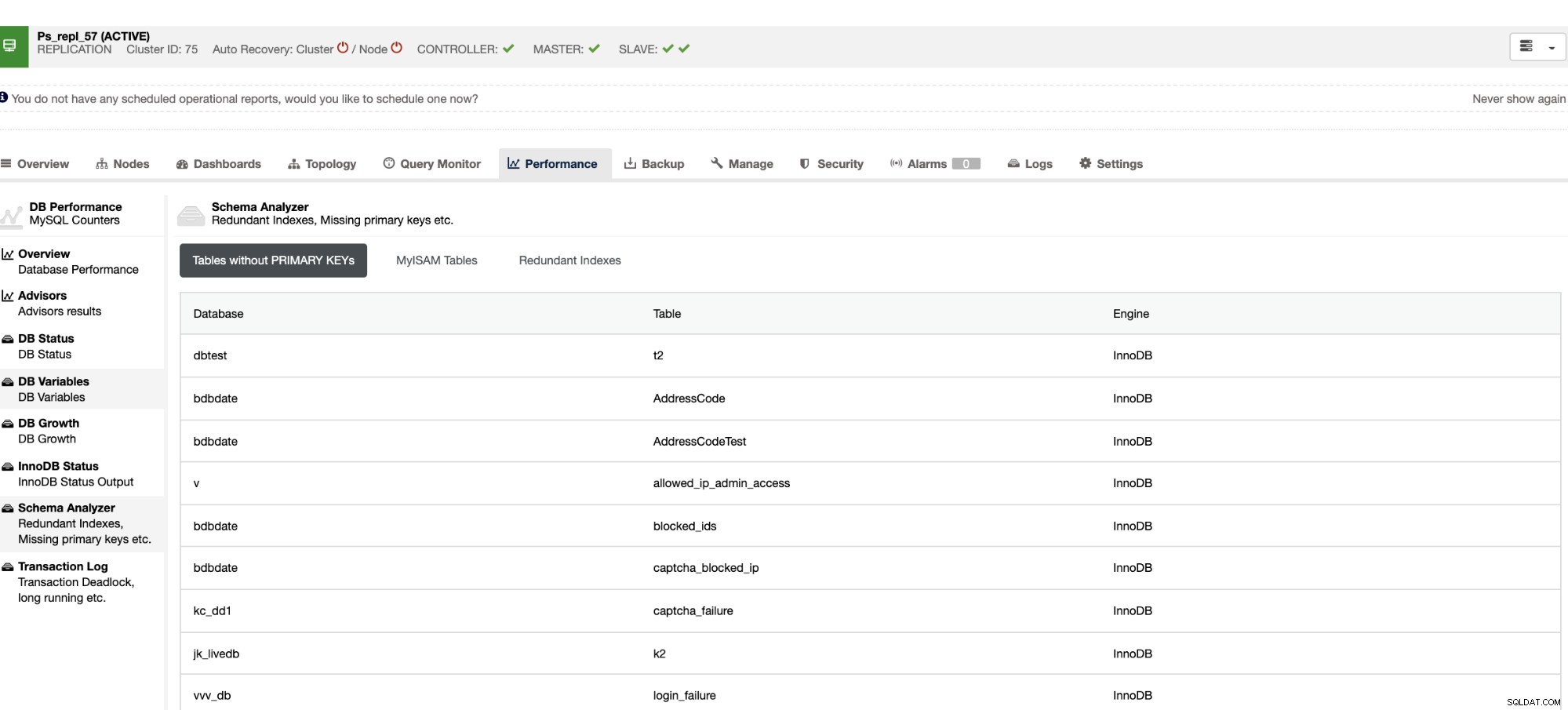
Les index redondants vous permettent de déterminer que ces index peuvent entraîner des problèmes de performances pour requêtes entrantes qui référencent les index en double. Il vous indique également les tables qui n'ont pas de clés primaires, ce qui est généralement un problème courant de décalage d'esclave lorsqu'une certaine requête SQL ou des transactions qui référencent de grandes tables sans clés primaires ou uniques lorsqu'elles sont répliquées sur les esclaves.
Conclusion
La gestion du décalage de réplication MySQL est un problème fréquent dans une configuration de réplication maître-esclave. Il peut être facile à diagnostiquer, mais difficile à résoudre. Assurez-vous que vos tables contiennent une clé primaire ou une clé unique, et déterminez les étapes et les outils permettant de dépanner et de diagnostiquer la cause du décalage de l'esclave. L'efficacité est toujours la clé lors de la résolution de problèmes.