Il y a beaucoup à garder à l'esprit lorsque vous concevez une base de données, et très peu d'entre nous peuvent se souvenir de tous les trucs et astuces précieux que nous avons appris. Alors, jetons un coup d'œil à certaines ressources en ligne qui proposent des conseils de conception de base de données et les meilleures pratiques. Au fur et à mesure, je partagerai mes propres opinions sur les idées présentées, basées sur mon expérience dans la conception de bases de données.
Évidemment, cet article n'est pas une liste exhaustive, mais j'ai essayé de passer en revue et de commenter un échantillon représentatif de sources. J'espère que vous trouverez les informations qui correspondent le mieux à vos besoins et à vos objectifs.
En passant, j'ai été surpris de constater que de nombreux articles liés aux pratiques de conception de bases de données contenaient très peu d'exemples; les ressources en ligne que j'ai examinées pour l'article sur les erreurs et les erreurs en avaient un pourcentage plus élevé. Ce manque est un inconvénient, car les exemples sont extrêmement importants pour faire passer le message.
Conseils de base de données pour les concepteurs expérimentés
Tout d'abord, commençons par des sources contenant des conseils de conception de base de données avancés et les meilleures pratiques. Ceux-ci sont destinés aux concepteurs qui travaillent déjà dans la modélisation de données et ce depuis un certain temps. Certains articles sont destinés à un niveau plus intermédiaire, mais s'ils traitent de concepts avancés, je les ai inclus dans cette liste.
Directives de base de données (RDBMS/SQL)
par Steve Djajasaputra | SOA, Java, développement logiciel – BlogSpot | 16 janvier 2013
Cet article de M. Djajasaputra est assez impressionnant :il énumère de nombreuses astuces pour le schéma, les index et les vues; il fournit également une convention de dénomination assez détaillée. Et ses conseils continuent (et continuent). L'ampleur est impressionnante, mais il n'y a presque pas d'exemples. Certains de ses points peuvent être considérés comme discutables, mais dans l'ensemble, il s'agit d'une présentation très solide.
En particulier, j'ai été impressionné qu'il donne une règle précise sur l'utilisation des clés primaires naturelles par rapport aux clés artificielles (c'est-à-dire, de substitution ou générées). Il garde cela agréable et simple, précisant que nous devrions préférer une clé naturelle car elle a du sens. Il fournit également des lignes directrices pour la meilleure utilisation d'une clé artificielle, en particulier lorsque la clé naturelle n'est pas unique ou lorsque vous devez modifier la valeur de la clé naturelle. Dans ses propres mots :
Préférez d'abord utiliser la clé naturelle car elle a plus de sens et pour éviter les doublons (réutiliser la colonne existante). Mais il existe des cas où vous avez besoin d'une clé artificielle :lorsque la clé naturelle n'est pas unique (par exemple, des noms) ou si vous devez modifier la valeur.Comme sa liste de conseils est si longue, je ne peux pas imaginer me souvenir de tous. Mais chaque section peut être référencée lorsque vous travaillez sur la conception, les performances, les procédures stockées et la gestion des versions de la base de données. Il existe également une section sur les points spécifiques à Oracle qui serait utile si vous travaillez avec ou prévoyez de prendre en charge Oracle.
Dans l'ensemble, il s'agit d'une ressource très utile et complète.
9 conseils pour une meilleure conception de base de données
par Jeffrey Edison | Blog Vertabélo | 22 septembre 2015
Je vais me livrer à une petite auto-promotion ici.
Cet article de 9 conseils pour une meilleure conception de base de données est basé sur mon expérience en tant que designer et architecte. J'ai également trouvé des informations supplémentaires en recherchant les meilleures pratiques d'autres personnes en matière de conception de bases de données.
Ma liste représente certains des principaux problèmes qui peuvent survenir lorsque vous travaillez avec des modèles de données. J'ai organisé les conseils dans l'ordre dans lequel ils se produisent au cours du cycle de vie du projet (plutôt que par importance ou à quelle fréquence ils surviennent) car ce serait le plus utile, du moins à mon avis. Les lecteurs peuvent suivre cette liste de contrôle des meilleures pratiques tout au long du cycle de vie d'un projet.
Extrait de l'article :
Pour paraphraser Al Capone (ou John Van Buren, fils du 8e président américain), « testez tôt, testez souvent ». De cette manière, vous suivez la voie de l'Intégration Continue. Tester à un stade précoce du développement permet d'économiser du temps et de l'argent. En testant la base de données, l'objectif doit être de simuler un environnement de production :"Une journée dans la vie de la base de données". A quels volumes peut-on s'attendre ? Quelles sont les interactions utilisateur probables ? Les cas limites sont-ils traités ?En prêtant attention à ces conseils, j'ai constaté que les bases de données deviennent mieux conçues et plus robustes. Bien qu'aucune de ces activités ne prenne énormément de temps, chacune peut avoir un impact énorme sur la qualité de votre modèle de données.
J'espère que ma liste de conseils sera utile aux concepteurs intermédiaires et avancés.
20 bonnes pratiques de conception de bases de données
par Cagdas Basaraner | Équilibre du code – BlogSpot | 24 juillet 2011
M. Basaraner nous présente une liste intéressante de 20 meilleures pratiques de conception de bases de données. J'aurais préféré qu'il en groupe quelques-unes; par exemple, les quatre premiers éléments pourraient tous être couverts sous "Utiliser de bonnes conventions de dénomination".
En outre, il déclare que l'utilisation d'un ID synthétique généré (entier) comme clé primaire de toutes les tables est une bonne pratique. En fait, c'est encore un sujet débattu, avec des arguments pour et contre. Certaines de ses meilleures pratiques sont assez génériques, comme « Pour… les systèmes de base de données critiques [sic], utilisez le service de récupération après sinistre et de sécurité… » Je ne suis pas en désaccord avec ce point, mais il est de très haut niveau.
Du côté positif, cet article était l'un des rares à mentionner l'utilisation d'un cadre de mappage objet-relationnel (ORM). Certains commentateurs n'étaient pas d'accord avec la formulation de l'astuce, mais au moins l'utilisation d'un cadre ORM est mentionné :
Utilisez un cadre ORM (object relational mapping) (c'est-à-dire Hibernate, iBatis ...) si le code de l'application est suffisamment volumineux. Les problèmes de performances des frameworks ORM peuvent être traités par des paramètres de configuration détaillés.Néanmoins, cette liste aurait pu être améliorée. Il doit clairement identifier les points qui ne sont spécifiques qu'à certains systèmes de gestion de bases de données (par exemple, SQL Server). Des statistiques précises concernant les performances, l'heuristique ou l'importance de consacrer du temps à la conception plutôt que sur la maintenance et re-conception aurait été bien. D'autres exemples étaient également nécessaires, mais c'est un problème pour la plupart de ces articles.
Si vous travaillez avec SQL Server, envisagez d'utiliser un framework ORM ou avez besoin d'une liste à puces de conseils plutôt qu'un article long et détaillé, alors cet article est pour vous.
(Remarque :cet article est également apparu sur plusieurs autres sites, notamment CodeBuild, Java Code Geeks et DZone.)
Les bases de la conception de bases de données. 10 choses que vous devez absolument faire
par Michelle A. Poolet | SQL Server Pro | 1 mars 2011
Une partie des conseils de Mme Poolet sont assez classiques et peuvent être trouvés dans de nombreuses autres ressources, mais il y a aussi quelques points plutôt rares. Parmi ses points génériques, elle promeut l'utilisation de sous-types et de super-types (avec lesquels je suis tout à fait d'accord) car cela reflète la conception orientée objet et peut être facilement compris par les développeurs. Extrait de son article :
N'ayez pas peur d'inclure des entités de supertype et de sous-type dans votre conception dans le CDM et au-delà. Les sous-types représentent des classifications ou des catégories du supertype… Les entités sont représentées comme des sous-types lorsqu'il faut plus d'un mot ou d'une phrase pour catégoriser l'entité.
Si une catégorie a sa propre vie, avec des attributs séparés qui décrivent l'apparence et le comportement de la catégorie et des relations séparées avec d'autres entités, alors il est temps d'invoquer la structure supertype/sous-type . Ne pas le faire empêchera une compréhension complète des données et des règles commerciales qui régissent la collecte de données.
Certains de ses commentaires font spécifiquement référence à MS SQL Server même si les commentaires sont en fait des problèmes génériques. L'un des principaux points soulevés par Mme Poolet est très spécifique à SQL Server :"Stockez le code qui touche les données d'une base de données en tant que procédure stockée".
C'est très bien si vous ne prévoyez de prendre en charge qu'un seul système de gestion de base de données, tel que SQL Server. Mais pour les implémentations portables, ce ne serait pas un bon conseil. Généralement, je conçois pour la portabilité vers au moins deux systèmes de gestion avec un support de langage de procédure stockée différent. Par conséquent, j'éviterais cette pratique.
Cet article est particulièrement utile aux personnes développant pour SQL Server et se concentrant sur le marché américain (plutôt que sur un système international). En tant qu'Américaine vivant à l'étranger, cependant, j'ai trouvé que certains de ses exemples étaient un peu trop « centrés sur les États-Unis ». Par exemple, un non-Américain peut ne pas comprendre ce qu'est un Zip+4 domaine est et ne comprendrait donc pas pourquoi ce domaine devrait avoir une caractéristique NOT NULL.
Pour illustrer cela, j'ai créé un modèle de données pour les deux adresses américaines non américaines. Nous supposerons que notre modèle de données peut exiger que les entités soient liées à plusieurs adresses :par exemple, une pour la facturation, une pour l'expédition. La première adresse serait associée à un moyen de paiement; dans ce cas, l'adresse sera utilisée pour vérifier votre droit d'autoriser ce paiement. L'adresse de livraison, évidemment, est celle où la commande sera livrée.
Créons une adresse américaine dans le cadre d'un modèle de base de données de commandes client. (Remarque :il ne s'agit pas d'un modèle complet, mais d'un exemple de stockage des commandes de produits.)
Wise Coders Solutions recommande de définir des champs séparés pour les numéros de maison et les noms de rue et de définir ces champs sur NOT NULL ; cela interdirait toute adresse qui n'a pas de numéro de maison et de nom de rue. Mais qu'en est-il des personnes qui utilisent des boîtes postales ? Leurs adresses sont généralement écrites sous la forme "PO Box 123". Devrions-nous les forcer à mettre le numéro de la boîte postale comme numéro de maison et « PO Box » comme nom de rue ? Je ne pense pas.
Au lieu de cela, nous utiliserons un formulaire avec "Ligne d'adresse 1" et "Ligne d'adresse 2". Plusieurs personnes se sont opposées à l'utilisation de nombres dans les noms de champs, mais pour moi, c'est une solution plutôt évidente. De plus, j'ai défini des longueurs de champ maximales (35 et 70 caractères) typiques des paiements internationaux.
Notez que les conceptions américaines et non américaines ont toutes deux un champ pour les régions d'un pays, mais la conception américaine nécessite qu'une abréviation d'état à 2 caractères soit incluse. Notez également que la conception américaine n'autorise pas les adresses dans d'autres pays.
Si vous avez des préoccupations concernant l'utilisation globale de votre base de données, vous devez penser globalement pendant la phase de conception. Nos bases de données sont-elles préparées pour l'utilisation multinationale de nos applications ?
Leçons tirées d'une mauvaise conception de l'entrepôt de données
par Michelle A. Poolet | SQL Server Pro | 15 juin 2009
Cet article examine le Data Warehouse (DWH) et certains de ses problèmes de conception et de mise en œuvre. L'accent est légèrement mis sur SQL Server, mais il s'agit d'un aperçu assez orthodoxe de la conception pour l'entreposage de données et l'informatique décisionnelle. Avoir l'adhésion et créer des interfaces conviviales ne sont peut-être pas les conseils les plus utiles, mais je ne suis pas en désaccord avec eux ; je ne pense tout simplement pas qu'ils fassent partie de la conception de DWH.
Mme Poolet déclare que le processus d'extraction-transformation-chargement (ETL) devrait effectuer des vérifications de la qualité des données et éventuellement « nettoyer » les données jusqu'à ce qu'il existe une norme acceptable de qualité des données. À mon avis, cela risque de créer un entrepôt de données qui ne reflète pas correctement les informations extraites du système source. Le nettoyage des données doit être effectué dans les systèmes sources. ETL ne doit transformer les données que pour qu'elles puissent être chargées dans l'entrepôt de données.
Sur une note positive, la recommandation de recycler ou de créer des routines ETL réutilisables est très pertinente. De plus, je suis d'accord avec Mme Poolet sur l'évolutivité. Ses commentaires sur la gestion des risques et la conformité, en particulier la loi Sarbanes-Oxley, semblent assez précis ; Je suppose que cela vient de son domaine d'activité.
Enfin, elle a une belle liste de contrôle de points relatifs aux dimensions, aux tables de faits et aux choix de schéma lors de la conception OLAP (traitement analytique en ligne). Celles-ci semblent être très pertinentes lors du processus de conception de la base de données. J'aurais aimé que cette liste soit plus longue, avec plus de détails ou d'exemples, mais j'étais contente que ces conseils pratiques soient inclus.
11 règles importantes de conception de bases de données que je suis
par Shivprasad Koirala | Projet Code | 25 février 2014
J'aime beaucoup les conseils sensés et clairs au début de cet article. Des concepts tels que "tenir compte de la nature de l'application" et "diviser vos données en éléments logiques" sont parfaits. Ce sont des aides importantes lors de la création de votre modèle de données. Comme le dit M. Koirala :
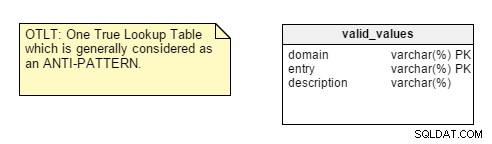
Lorsque vous démarrez la conception de votre base de données, la première chose à analyser est la nature de l'application pour laquelle vous concevez, est-elle transactionnelle ou analytique. Vous trouverez de nombreux développeurs qui appliquent par défaut des règles de normalisation sans penser à la nature de l'application, puis se lancent plus tard dans des problèmes de performances et de personnalisation.Cependant, il y a quelques points qui me laissent sceptique. Par exemple, prenez la centralisation des paires Nom-Valeur dans une seule table. Cette conception One True Lookup Table (OTLT) est débattue, mais elle est généralement considérée comme une mauvaise pratique ou du moins un anti-modèle de conception. Je me range du côté du groupe anti-OTLT ; ces tableaux présentent de nombreux problèmes. Nous pourrions utiliser l'analogie du développement logiciel consistant à utiliser un seul énumérateur pour représenter toutes les valeurs possibles de toutes les constantes possibles comme équivalent à cette pratique.
Pour vous rappeler, la table OTLT ressemble généralement à ceci, avec des entrées de plusieurs domaines jetées dans la même table. Je suis d'accord avec le groupe anti-OTLT ; ces tableaux présentent de nombreux problèmes.
De plus, certains points semblent un peu ésotériques, comme « attention aux données séparées par des séparateurs ». Bien que ce soit un point valable, ce n'est pas celui auquel je pense habituellement lors de la création d'un nouveau modèle de données.
M. Koirala a quelques éléments de conception OLAP qui ne sont généralement pas mentionnés dans d'autres listes de meilleures pratiques. Son inclusion d'une dimension et d'un design factuel peut être utile, mais cela pourrait aussi être dangereux pour les concepteurs débutants.
Cet article est intéressant si vous passez du début à une modélisation de données plus avancée. Cela vous aidera à considérer la nature analytique par rapport à la nature transactionnelle de vos futurs modèles.
Big Data :cinq astuces simples pour la conception de bases de données
par Dave Beulke | davebeulke.com | 19 mars 2013

L'article de M. Beulke examine les conseils de conception axés sur les performances. Il montre comment vérifier la bonne normalisation :ni trop ni trop peu. (Une sur-normalisation aura un impact négatif sur les performances de la base de données.)
En outre, l'utilisation de clés métier naturelles plutôt que de clés primaires générées est un bon conseil lorsque vous souhaitez éviter de convertir une clé métier en un ID de ligne généré pour chaque accès à la base de données.
L'utilisation de normes de dénomination et de types de colonnes appropriés est également un bon conseil. Le point sur la surutilisation des colonnes nullables est valable :créer toutes les colonnes comme nullables est une erreur, mais définir une colonne comme nullable peut être nécessaire pour une fonction métier particulière. Dans les propres mots de l'auteur :
Toutes les colonnes sont-elles NULLables ? Dans les définitions des colonnes de la base de données, les bons domaines de données, plages et valeurs doivent être analysés, évalués et prototypés pour l'application métier. Avoir de bonnes valeurs par défaut, une portée limitée de valeurs et toujours une valeur sont les meilleurs pour les performances et la logique d'application. Les colonnes NULLables ne sont bonnes que lorsque les données sont inconnues ou n'ont pas encore de valeur. Les données de date de décès de quelqu'un sont l'exemple classique d'une colonne NULLable car elles sont inconnues à moins qu'elles ne soient déjà décédées. Assurez-vous que la conception de votre base de données représente des données connues et n'utilise qu'un minimum de colonnes NULLables.Les astuces de M. Beulke sont toutes très solides, même si peu originales. J'aurais aimé plus d'éléments Big Data - c'est après tout le titre de l'article. En fin de compte, j'ai senti que l'article manquait à la fois de profondeur et d'ampleur, et n'avait pas d'exemples pour clarifier les points. Cependant, il offre de précieux conseils liés à la normalisation et aux clés naturelles.
10 bonnes pratiques de conception de bases de données
par Ann All | Applications d'entreprise aujourd'hui | 15 juillet 2014
Ten Database Design Best Practices est en fait présenté sous la forme d'une série de diapositives. Mme All comprend des informations de développeurs chevronnés, tels que Michael Blaha. Il encourage la réutilisation de vos meilleures pratiques et modèles. Ceux-ci sont compris et éprouvés, et à cet égard préférables aux modèles de données qui doivent être créés à partir de zéro. Extrait de l'article de Mme All :
Par exemple, je procède souvent à l'ingénierie inverse de bases de données – bases de données d'une application à remplacer ainsi que bases de données d'applications connexes. Ces bases de données existantes n'ont souvent pas de modèle de données disponible. Mais un modèle de données est implicite dans le schéma de base de données et peut être au moins partiellement extrait avec des techniques de rétro-ingénierie de base de données. … Il existe des représentations de données éprouvées qui se produisent souvent et n'ont pas besoin d'être recréées à partir de zéro.Il s'agit d'un court diaporama que les concepteurs de modèles de données peuvent parcourir rapidement et glaner les conseils qui les concernent. Pour moi, l'astuce de réutilisation est l'une de mes préférées.
Bonnes pratiques de base de données
par Cunningham &Cunningham, Inc.
Ces meilleures pratiques ont bien commencé, mais se sont ensuite heurtées à des problèmes délicats. Je ne suis pas convaincu que les conseils proposés soient toujours pertinents.
Du côté positif, il existe de très belles descriptions de «meilleures pratiques» controversées, comme toujours utiliser des clés de substitution générées automatiquement et utiliser ou éviter les procédures stockées. Par exemple :
Un auteur précédent a écrit :"Généralement, évitez les clés primaires qui ont une signification. Les noms ne sont pas uniques, et de nombreux identifiants apparemment uniques tels que les numéros de sécurité sociale ne le sont pas, en raison de problèmes de fiabilité des données dans le monde réel." En bref, il s'agit d'une recommandation de toujours avoir une SurrogateKey générée automatiquement (généralement numérique) au lieu d'une LogicalKey basée sur le domaine. Il s'agit d'une réponse plutôt simple à un problème complexe, même si c'est une réponse qui suffira dans un certain nombre de cas et est au moins préférable à l'absence de PrimaryKey du tout.(Note de l'auteur :je n'ai pas trouvé cet "auteur précédent" lors de la recherche de ces deux phrases sur Google.)
Et un lien vers un article récapitulatif sur les principaux arguments de chaque côté du débat sur les clés automatiques contre les clés de domaine est fourni.
D'un autre côté, j'ai trouvé les astuces pour "diviser le système d'exploitation, les données et la connexion sur différents disques physiques" et "utiliser RAID" un peu obscures. Ne vous méprenez pas - c'est probablement un bon conseil dans certaines circonstances, mais je ne l'inclurais pas dans ma liste des 20 meilleurs.
Conseils de conception de base de données
par Wise Coders
Il y a quelques conseils uniques et intéressants dans cette collection, comme une recommandation de clôturer les transactions dès que possible.
Cependant, je ne suis pas entièrement d'accord avec tous les conseils de conception ici. Par exemple :
Supposons un champ 'Status' avec les valeurs 'Active', 'Inactive' et 'Idle'. Vous pouvez enregistrer la valeur sous le nom complet, mais cela peut être inefficace. Stocker une énumération ou un char(1) avec des valeurs possibles 'a', 'i', 'd', par exemple, utilisera moins d'espace dans la base de données.C'est pour le moins controversé - d'autres sources recommandent de ne pas utiliser de «codes secrets» comme celui-ci. Utilisez plutôt une table séparée pour stocker ces codes d'état.
De plus, les statistiques associées aux indices de performances sont discutables et il n'y a pas d'exemples dans l'article.
Sur une note positive, il s'agit d'une belle courte liste de conseils qui devraient être accessibles aux modélisateurs de bases de données intermédiaires.
Ressources pour les concepteurs de bases de données débutants
Examinons maintenant quelques articles pour ceux qui débutent dans la conception de bases de données.
Les bases d'une bonne conception de base de données dans le développement Web
par Kayla Knight | Onextrapixel.com | 17 mars 2011
Ici, nous allons un peu plus loin, avec des conseils allant des fonctionnalités aux outils de modélisation.
Mme Knight nous présente une introduction à la conception de bases de données. Son article est intéressant car il met l'accent sur les bases de données pour le développement web. Même ainsi, ses points sont assez universels et peuvent être appliqués à la conception de bases de données dans de nombreuses situations.
L'article commence par nous demander de réfléchir globalement à la fonctionnalité, pas seulement à la base de données :
Pensez en dehors de la base de données. Essayez de réfléchir à ce que le site Web devra faire. Par exemple, si un site Web d'adhésion est nécessaire, le premier réflexe peut être de commencer à penser à toutes les données que chaque utilisateur devra stocker. Oublie ça, c'est pour plus tard. Notez plutôt que les utilisateurs et leurs informations devront être stockés dans la base de données, et quoi d'autre ? Que devront faire ces membres sur le site ? Feront-ils des publications, téléchargeront-ils des fichiers ou des photos, ou enverront-ils des messages ? Ensuite, la base de données aura besoin d'un emplacement pour les fichiers/photos, les publications et les messages.À partir de là, Mme Knight emmène le lecteur dans les outils de conception de bases de données et les étapes impliquées dans le processus. Son article donne des exemples et des liens vers d'autres ressources.
Je pense que cet article serait une excellente introduction pour les concepteurs de bases de données débutants, et il devrait bien fonctionner avec les Geek Girl's série.
Exploration des astuces de conception de base de données
par Doug Lowe | Pour les nuls
La liste des "nuls" de M. Lowe est une large série de conseils de conception de base. Vous pouvez en trouver beaucoup ailleurs, mais il est utile de les avoir au même endroit. Vous ne trouverez rien d'unique ou de très controversé, à l'exception d'une recommandation d'utiliser des procédures stockées. Je remets toujours en question cette affirmation forte, car je suis très préoccupé par la portabilité du modèle de données pour plusieurs systèmes DBM.
Voici l'un des conseils de bon sens de M. Lowe :
Évitez les champs avec des noms tels que CustomerType, où la valeur du champ est l'une des nombreuses constantes qui ne sont pas définies ailleurs dans la base de données, telles que R pour Retail ou W pour Wholesale. Vous n'avez peut-être que ces deux types de clients aujourd'hui, mais les besoins de l'application peuvent changer à l'avenir, nécessitant un troisième type de client.Ces recommandations sont plus appropriées lorsque vous travaillez avec SQL Server.
Cinq conseils de conception de base de données simples
par Lamont Adams | TechRepublic | 25 juin 2001
Le mot clé de cette ressource est « simple ». Vous pouvez trouver ces informations, avec plus d'explications et d'exemples, dans d'autres articles.
Cependant, le conseil de M. Adams de «retirer les clés de l'utilisateur» est un point intéressant, rarement mentionné ailleurs. Il continue :
Lorsque vous décidez du ou des champs à utiliser comme clés dans une table, tenez toujours compte des champs que les utilisateurs modifieront. C'est généralement une mauvaise idée de choisir un champ modifiable par l'utilisateur comme clé.Le sens de M. Adams est que vous devez tenir compte de l'exigence potentielle de l'utilisateur de modifier les champs lors du choix des champs à utiliser comme clés. J'aurais aimé plus d'explications concernant les alternatives, telles que les clés synthétiques/générées, mais le concept est bon.
Je ne suis pas d'accord avec le dernier point. Il recommande un "fudge factor" pour chaque table que vous concevez :
Il n'y a rien de pire que de découvrir ou d'être informé qu'il manque un champ à votre base de données "terminée" pour une information cruciale. Dans une entreprise pour laquelle je travaillais, c'était un phénomène si courant que nous avons commencé à qualifier les « gels de bases de données » de « slush de bases de données ».Dans mon esprit, il s'agit essentiellement "d'ajouter quelques champs de texte supplémentaires à la fin". Cela semble contredire certains des autres conseils de M. Adams, en particulier ceux concernant la compréhension des besoins de l'entreprise et l'utilisation de noms significatifs. Ces champs de fudge supplémentaires seraient simplement appelés quelque chose comme "extra1" ou "extra2". Quel est leur besoin commercial ? Et comment sont ces noms significatifs? Bien que j'aime la plupart de ses conseils de conception, ce "fudge factor" n'est pas quelque chose auquel j'adhère.
Conception de la base de données :mentions honorables
Évidemment, il existe d'autres articles qui décrivent des conseils de conception de base de données et les meilleures pratiques. Vous pouvez trouver du matériel supplémentaire dans les liens suivants :
Conception de bases de données relationnelles :une introduction aux meilleures pratiques | de Digital Ethos | 24 décembre 2012
Meilleures pratiques pour la conception de schémas de base de données (débutants) | de Jim Murphy | 28 mars 2011
Meilleures pratiques informatiques :conception de bases de données | par l'Université du Nebraska–Lincoln
Ressources de conception de bases de données en ligne :où iriez-vous ?
Comme mentionné, cette liste n'est certainement pas destinée à être un examen exhaustif de chaque article de conception de base de données sur Internet. Au lieu de cela, nous avons identifié plusieurs articles que nous pensons utiles ou qui ont un objectif particulier que vous pourriez trouver utile.
N'hésitez pas à recommander des articles supplémentaires.